 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHe Zhao
Extracting Clean and Balanced Subset for Noisy Long-tailed Classification
Apr 10, 2024




Real-world datasets usually are class-imbalanced and corrupted by label noise. To solve the joint issue of long-tailed distribution and label noise, most previous works usually aim to design a noise detector to distinguish the noisy and clean samples. Despite their effectiveness, they may be limited in handling the joint issue effectively in a unified way. In this work, we develop a novel pseudo labeling method using class prototypes from the perspective of distribution matching, which can be solved with optimal transport (OT). By setting a manually-specific probability measure and using a learned transport plan to pseudo-label the training samples, the proposed method can reduce the side-effects of noisy and long-tailed data simultaneously. Then we introduce a simple yet effective filter criteria by combining the observed labels and pseudo labels to obtain a more balanced and less noisy subset for a robust model training. Extensive experiments demonstrate that our method can extract this class-balanced subset with clean labels, which brings effective performance gains for long-tailed classification with label noise.
Selective, Interpretable, and Motion Consistent Privacy Attribute Obfuscation for Action Recognition
Mar 19, 2024



Concerns for the privacy of individuals captured in public imagery have led to privacy-preserving action recognition. Existing approaches often suffer from issues arising through obfuscation being applied globally and a lack of interpretability. Global obfuscation hides privacy sensitive regions, but also contextual regions important for action recognition. Lack of interpretability erodes trust in these new technologies. We highlight the limitations of current paradigms and propose a solution: Human selected privacy templates that yield interpretability by design, an obfuscation scheme that selectively hides attributes and also induces temporal consistency, which is important in action recognition. Our approach is architecture agnostic and directly modifies input imagery, while existing approaches generally require architecture training. Our approach offers more flexibility, as no retraining is required, and outperforms alternatives on three widely used datasets.
Optimal Transport for Structure Learning Under Missing Data
Feb 23, 2024Causal discovery in the presence of missing data introduces a chicken-and-egg dilemma. While the goal is to recover the true causal structure, robust imputation requires considering the dependencies or preferably causal relations among variables. Merely filling in missing values with existing imputation methods and subsequently applying structure learning on the complete data is empirical shown to be sub-optimal. To this end, we propose in this paper a score-based algorithm, based on optimal transport, for learning causal structure from missing data. This optimal transport viewpoint diverges from existing score-based approaches that are dominantly based on EM. We project structure learning as a density fitting problem, where the goal is to find the causal model that induces a distribution of minimum Wasserstein distance with the distribution over the observed data. Through extensive simulations and real-data experiments, our framework is shown to recover the true causal graphs more effectively than the baselines in various simulations and real-data experiments. Empirical evidences also demonstrate the superior scalability of our approach, along with the flexibility to incorporate any off-the-shelf causal discovery methods for complete data.
Pretext Training Algorithms for Event Sequence Data
Feb 16, 2024Pretext training followed by task-specific fine-tuning has been a successful approach in vision and language domains. This paper proposes a self-supervised pretext training framework tailored to event sequence data. We introduce a novel alignment verification task that is specialized to event sequences, building on good practices in masked reconstruction and contrastive learning. Our pretext tasks unlock foundational representations that are generalizable across different down-stream tasks, including next-event prediction for temporal point process models, event sequence classification, and missing event interpolation. Experiments on popular public benchmarks demonstrate the potential of the proposed method across different tasks and data domains.
Bayesian Factorised Granger-Causal Graphs For Multivariate Time-series Data
Feb 06, 2024We study the problem of automatically discovering Granger causal relations from observational multivariate time-series data. Vector autoregressive (VAR) models have been time-tested for this problem, including Bayesian variants and more recent developments using deep neural networks. Most existing VAR methods for Granger causality use sparsity-inducing penalties/priors or post-hoc thresholds to interpret their coefficients as Granger causal graphs. Instead, we propose a new Bayesian VAR model with a hierarchical graph prior over binary Granger causal graphs, separately from the VAR coefficients. We develop an efficient algorithm to infer the posterior over binary Granger causal graphs. Our method provides better uncertainty quantification, has less hyperparameters, and achieves better performance than competing approaches, especially on sparse multivariate time-series data.
Variational DAG Estimation via State Augmentation With Stochastic Permutations
Feb 04, 2024



Estimating the structure of a Bayesian network, in the form of a directed acyclic graph (DAG), from observational data is a statistically and computationally hard problem with essential applications in areas such as causal discovery. Bayesian approaches are a promising direction for solving this task, as they allow for uncertainty quantification and deal with well-known identifiability issues. From a probabilistic inference perspective, the main challenges are (i) representing distributions over graphs that satisfy the DAG constraint and (ii) estimating a posterior over the underlying combinatorial space. We propose an approach that addresses these challenges by formulating a joint distribution on an augmented space of DAGs and permutations. We carry out posterior estimation via variational inference, where we exploit continuous relaxations of discrete distributions. We show that our approach can outperform competitive Bayesian and non-Bayesian benchmarks on a range of synthetic and real datasets.
Continuous Target Speech Extraction: Enhancing Personalized Diarization and Extraction on Complex Recordings
Jan 29, 2024Target speaker extraction (TSE) aims to extract the target speaker's voice from the input mixture. Previous studies have concentrated on high-overlapping scenarios. However, real-world applications usually meet more complex scenarios like variable speaker overlapping and target speaker absence. In this paper, we introduces a framework to perform continuous TSE (C-TSE), comprising a target speaker voice activation detection (TSVAD) and a TSE model. This framework significantly improves TSE performance on similar speakers and enhances personalization, which is lacking in traditional diarization methods. In detail, unlike conventional TSVAD deployed to refine the diarization results, the proposed Attention-target speaker voice activation detection (A-TSVAD) directly generates timestamps of the target speaker. We also explore some different integration methods of A-TSVAD and TSE by comparing the cascaded and parallel methods. The framework's effectiveness is assessed using a range of metrics, including diarization and enhancement metrics. Our experiments demonstrate that A-TSVAD outperforms conventional methods in reducing diarization errors. Furthermore, the integration of A-TSVAD and TSE in a sequential cascaded manner further enhances extraction accuracy.
A Class-aware Optimal Transport Approach with Higher-Order Moment Matching for Unsupervised Domain Adaptation
Jan 29, 2024Unsupervised domain adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain. In this paper, we introduce a novel approach called class-aware optimal transport (OT), which measures the OT distance between a distribution over the source class-conditional distributions and a mixture of source and target data distribution. Our class-aware OT leverages a cost function that determines the matching extent between a given data example and a source class-conditional distribution. By optimizing this cost function, we find the optimal matching between target examples and source class-conditional distributions, effectively addressing the data and label shifts that occur between the two domains. To handle the class-aware OT efficiently, we propose an amortization solution that employs deep neural networks to formulate the transportation probabilities and the cost function. Additionally, we propose minimizing class-aware Higher-order Moment Matching (HMM) to align the corresponding class regions on the source and target domains. The class-aware HMM component offers an economical computational approach for accurately evaluating the HMM distance between the two distributions. Extensive experiments on benchmark datasets demonstrate that our proposed method significantly outperforms existing state-of-the-art baselines.
HGAttack: Transferable Heterogeneous Graph Adversarial Attack
Jan 18, 2024Heterogeneous Graph Neural Networks (HGNNs) are increasingly recognized for their performance in areas like the web and e-commerce, where resilience against adversarial attacks is crucial. However, existing adversarial attack methods, which are primarily designed for homogeneous graphs, fall short when applied to HGNNs due to their limited ability to address the structural and semantic complexity of HGNNs. This paper introduces HGAttack, the first dedicated gray box evasion attack method for heterogeneous graphs. We design a novel surrogate model to closely resemble the behaviors of the target HGNN and utilize gradient-based methods for perturbation generation. Specifically, the proposed surrogate model effectively leverages heterogeneous information by extracting meta-path induced subgraphs and applying GNNs to learn node embeddings with distinct semantics from each subgraph. This approach improves the transferability of generated attacks on the target HGNN and significantly reduces memory costs. For perturbation generation, we introduce a semantics-aware mechanism that leverages subgraph gradient information to autonomously identify vulnerable edges across a wide range of relations within a constrained perturbation budget. We validate HGAttack's efficacy with comprehensive experiments on three datasets, providing empirical analyses of its generated perturbations. Outperforming baseline methods, HGAttack demonstrated significant efficacy in diminishing the performance of target HGNN models, affirming the effectiveness of our approach in evaluating the robustness of HGNNs against adversarial attacks.
Audio Deepfake Detection with Self-Supervised WavLM and Multi-Fusion Attentive Classifier
Dec 13, 2023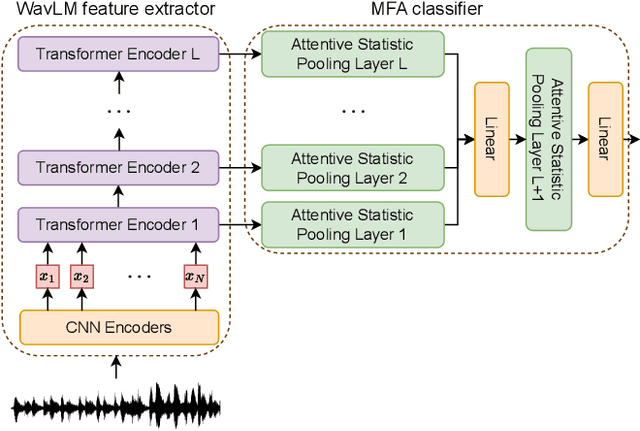
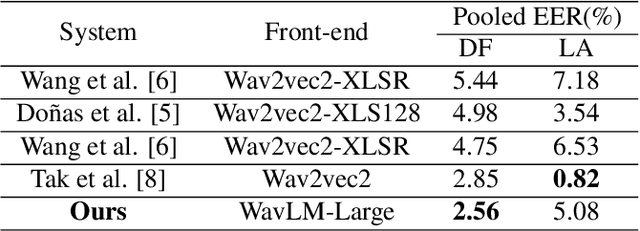


With the rapid development of speech synthesis and voice conversion technologies, Audio Deepfake has become a serious threat to the Automatic Speaker Verification (ASV) system. Numerous countermeasures are proposed to detect this type of attack. In this paper, we report our efforts to combine the self-supervised WavLM model and Multi-Fusion Attentive classifier for audio deepfake detection. Our method exploits the WavLM model to extract features that are more conducive to spoofing detection for the first time. Then, we propose a novel Multi-Fusion Attentive (MFA) classifier based on the Attentive Statistics Pooling (ASP) layer. The MFA captures the complementary information of audio features at both time and layer levels. Experiments demonstrate that our methods achieve state-of-the-art results on the ASVspoof 2021 DF set and provide competitive results on the ASVspoof 2019 and 2021 LA set.