 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrung Le
Text-Enhanced Data-free Approach for Federated Class-Incremental Learning
Mar 21, 2024
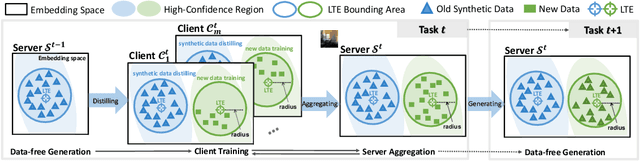
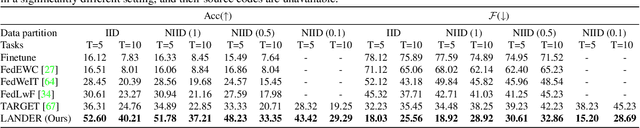
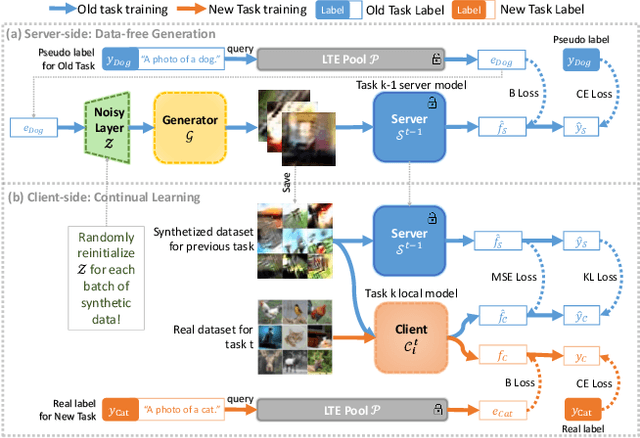

Federated Class-Incremental Learning (FCIL) is an underexplored yet pivotal issue, involving the dynamic addition of new classes in the context of federated learning. In this field, Data-Free Knowledge Transfer (DFKT) plays a crucial role in addressing catastrophic forgetting and data privacy problems. However, prior approaches lack the crucial synergy between DFKT and the model training phases, causing DFKT to encounter difficulties in generating high-quality data from a non-anchored latent space of the old task model. In this paper, we introduce LANDER (Label Text Centered Data-Free Knowledge Transfer) to address this issue by utilizing label text embeddings (LTE) produced by pretrained language models. Specifically, during the model training phase, our approach treats LTE as anchor points and constrains the feature embeddings of corresponding training samples around them, enriching the surrounding area with more meaningful information. In the DFKT phase, by using these LTE anchors, LANDER can synthesize more meaningful samples, thereby effectively addressing the forgetting problem. Additionally, instead of tightly constraining embeddings toward the anchor, the Bounding Loss is introduced to encourage sample embeddings to remain flexible within a defined radius. This approach preserves the natural differences in sample embeddings and mitigates the embedding overlap caused by heterogeneous federated settings. Extensive experiments conducted on CIFAR100, Tiny-ImageNet, and ImageNet demonstrate that LANDER significantly outperforms previous methods and achieves state-of-the-art performance in FCIL. The code is available at https://github.com/tmtuan1307/lander.
Diversity-Aware Agnostic Ensemble of Sharpness Minimizers
Mar 19, 2024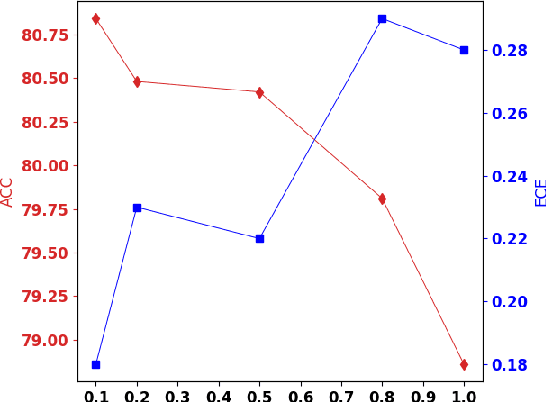
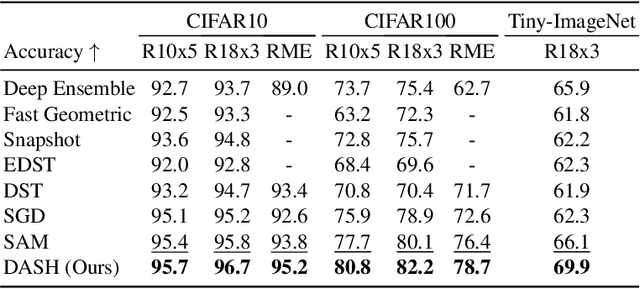
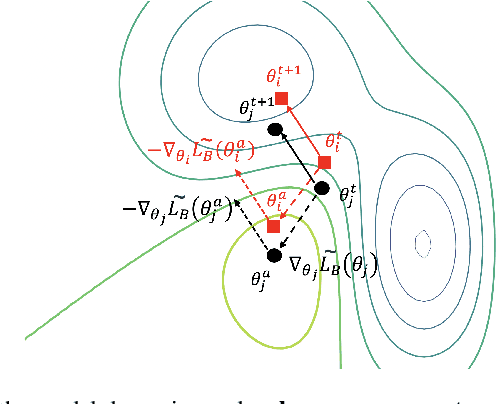
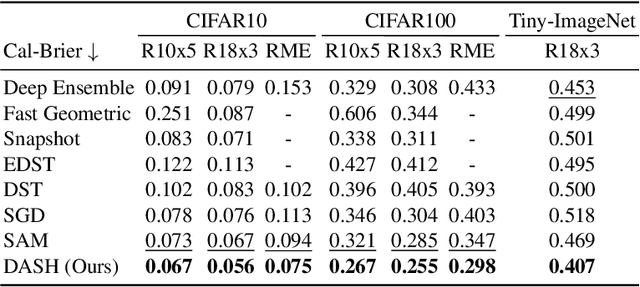
There has long been plenty of theoretical and empirical evidence supporting the success of ensemble learning. Deep ensembles in particular take advantage of training randomness and expressivity of individual neural networks to gain prediction diversity, ultimately leading to better generalization, robustness and uncertainty estimation. In respect of generalization, it is found that pursuing wider local minima result in models being more robust to shifts between training and testing sets. A natural research question arises out of these two approaches as to whether a boost in generalization ability can be achieved if ensemble learning and loss sharpness minimization are integrated. Our work investigates this connection and proposes DASH - a learning algorithm that promotes diversity and flatness within deep ensembles. More concretely, DASH encourages base learners to move divergently towards low-loss regions of minimal sharpness. We provide a theoretical backbone for our method along with extensive empirical evidence demonstrating an improvement in ensemble generalizability.
Removing Undesirable Concepts in Text-to-Image Generative Models with Learnable Prompts
Mar 18, 2024


Generative models have demonstrated remarkable potential in generating visually impressive content from textual descriptions. However, training these models on unfiltered internet data poses the risk of learning and subsequently propagating undesirable concepts, such as copyrighted or unethical content. In this paper, we propose a novel method to remove undesirable concepts from text-to-image generative models by incorporating a learnable prompt into the cross-attention module. This learnable prompt acts as additional memory to transfer the knowledge of undesirable concepts into it and reduce the dependency of these concepts on the model parameters and corresponding textual inputs. Because of this knowledge transfer into the prompt, erasing these undesirable concepts is more stable and has minimal negative impact on other concepts. We demonstrate the effectiveness of our method on the Stable Diffusion model, showcasing its superiority over state-of-the-art erasure methods in terms of removing undesirable content while preserving other unrelated elements.
Frequency Attention for Knowledge Distillation
Mar 09, 2024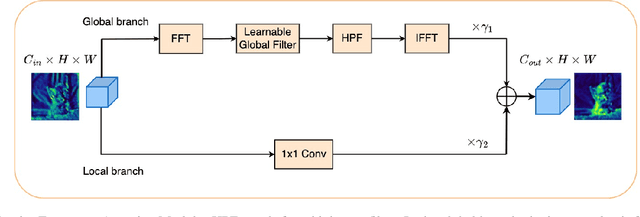
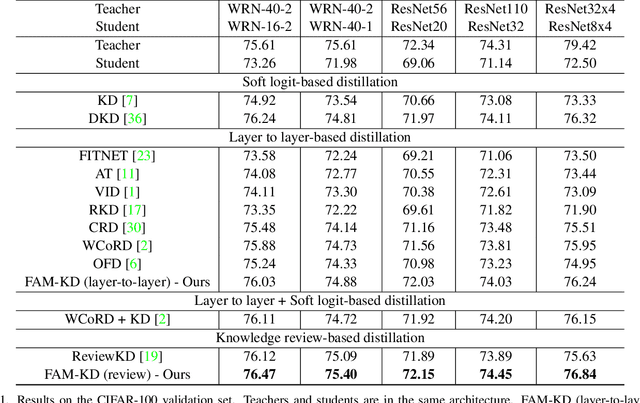


Knowledge distillation is an attractive approach for learning compact deep neural networks, which learns a lightweight student model by distilling knowledge from a complex teacher model. Attention-based knowledge distillation is a specific form of intermediate feature-based knowledge distillation that uses attention mechanisms to encourage the student to better mimic the teacher. However, most of the previous attention-based distillation approaches perform attention in the spatial domain, which primarily affects local regions in the input image. This may not be sufficient when we need to capture the broader context or global information necessary for effective knowledge transfer. In frequency domain, since each frequency is determined from all pixels of the image in spatial domain, it can contain global information about the image. Inspired by the benefits of the frequency domain, we propose a novel module that functions as an attention mechanism in the frequency domain. The module consists of a learnable global filter that can adjust the frequencies of student's features under the guidance of the teacher's features, which encourages the student's features to have patterns similar to the teacher's features. We then propose an enhanced knowledge review-based distillation model by leveraging the proposed frequency attention module. The extensive experiments with various teacher and student architectures on image classification and object detection benchmark datasets show that the proposed approach outperforms other knowledge distillation methods.
Optimal Transport for Structure Learning Under Missing Data
Feb 23, 2024Causal discovery in the presence of missing data introduces a chicken-and-egg dilemma. While the goal is to recover the true causal structure, robust imputation requires considering the dependencies or preferably causal relations among variables. Merely filling in missing values with existing imputation methods and subsequently applying structure learning on the complete data is empirical shown to be sub-optimal. To this end, we propose in this paper a score-based algorithm, based on optimal transport, for learning causal structure from missing data. This optimal transport viewpoint diverges from existing score-based approaches that are dominantly based on EM. We project structure learning as a density fitting problem, where the goal is to find the causal model that induces a distribution of minimum Wasserstein distance with the distribution over the observed data. Through extensive simulations and real-data experiments, our framework is shown to recover the true causal graphs more effectively than the baselines in various simulations and real-data experiments. Empirical evidences also demonstrate the superior scalability of our approach, along with the flexibility to incorporate any off-the-shelf causal discovery methods for complete data.
A Class-aware Optimal Transport Approach with Higher-Order Moment Matching for Unsupervised Domain Adaptation
Jan 29, 2024Unsupervised domain adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain. In this paper, we introduce a novel approach called class-aware optimal transport (OT), which measures the OT distance between a distribution over the source class-conditional distributions and a mixture of source and target data distribution. Our class-aware OT leverages a cost function that determines the matching extent between a given data example and a source class-conditional distribution. By optimizing this cost function, we find the optimal matching between target examples and source class-conditional distributions, effectively addressing the data and label shifts that occur between the two domains. To handle the class-aware OT efficiently, we propose an amortization solution that employs deep neural networks to formulate the transportation probabilities and the cost function. Additionally, we propose minimizing class-aware Higher-order Moment Matching (HMM) to align the corresponding class regions on the source and target domains. The class-aware HMM component offers an economical computational approach for accurately evaluating the HMM distance between the two distributions. Extensive experiments on benchmark datasets demonstrate that our proposed method significantly outperforms existing state-of-the-art baselines.
EraseDiff: Erasing Data Influence in Diffusion Models
Jan 11, 2024In response to data protection regulations and the ``right to be forgotten'', in this work, we introduce an unlearning algorithm for diffusion models. Our algorithm equips a diffusion model with a mechanism to mitigate the concerns related to data memorization. To achieve this, we formulate the unlearning problem as a bi-level optimization problem, wherein the outer objective is to preserve the utility of the diffusion model on the remaining data. The inner objective aims to scrub the information associated with forgetting data by deviating the learnable generative process from the ground-truth denoising procedure. To solve the resulting bi-level problem, we adopt a first-order method, having superior practical performance while being vigilant about the diffusion process and solving a bi-level problem therein. Empirically, we demonstrate that our algorithm can preserve the model utility, effectiveness, and efficiency while removing across two widely-used diffusion models and in both conditional and unconditional image generation scenarios. In our experiments, we demonstrate the unlearning of classes, attributes, and even a race from face and object datasets such as UTKFace, CelebA, CelebA-HQ, and CIFAR10.
DiffAugment: Diffusion based Long-Tailed Visual Relationship Recognition
Jan 01, 2024The task of Visual Relationship Recognition (VRR) aims to identify relationships between two interacting objects in an image and is particularly challenging due to the widely-spread and highly imbalanced distribution of <subject, relation, object> triplets. To overcome the resultant performance bias in existing VRR approaches, we introduce DiffAugment -- a method which first augments the tail classes in the linguistic space by making use of WordNet and then utilizes the generative prowess of Diffusion Models to expand the visual space for minority classes. We propose a novel hardness-aware component in diffusion which is based upon the hardness of each <S,R,O> triplet and demonstrate the effectiveness of hardness-aware diffusion in generating visual embeddings for the tail classes. We also propose a novel subject and object based seeding strategy for diffusion sampling which improves the discriminative capability of the generated visual embeddings. Extensive experimentation on the GQA-LT dataset shows favorable gains in the subject/object and relation average per-class accuracy using Diffusion augmented samples.
Class-Prototype Conditional Diffusion Model for Continual Learning with Generative Replay
Dec 10, 2023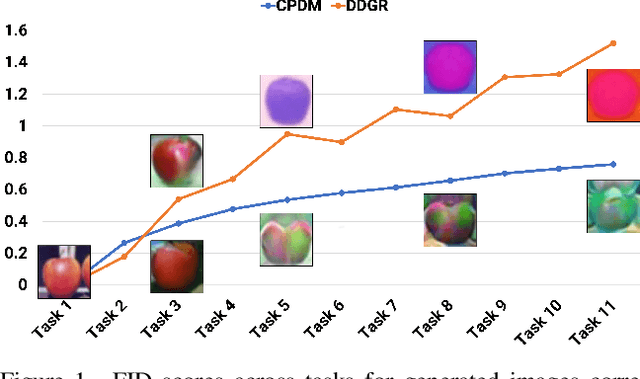
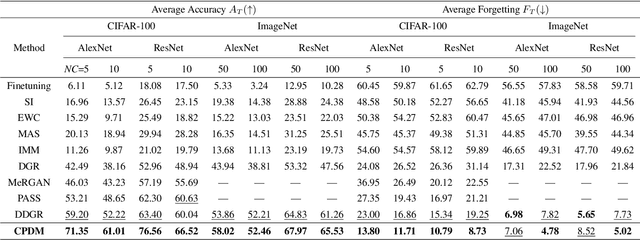

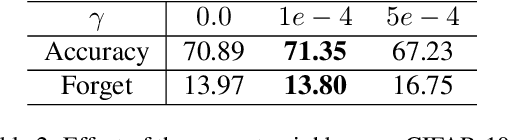
Mitigating catastrophic forgetting is a key hurdle in continual learning. Deep Generative Replay (GR) provides techniques focused on generating samples from prior tasks to enhance the model's memory capabilities. With the progression in generative AI, generative models have advanced from Generative Adversarial Networks (GANs) to the more recent Diffusion Models (DMs). A major issue is the deterioration in the quality of generated data compared to the original, as the generator continuously self-learns from its outputs. This degradation can lead to the potential risk of catastrophic forgetting occurring in the classifier. To address this, we propose the Class-Prototype Conditional Diffusion Model (CPDM), a GR-based approach for continual learning that enhances image quality in generators and thus reduces catastrophic forgetting in classifiers. The cornerstone of CPDM is a learnable class-prototype that captures the core characteristics of images in a given class. This prototype, integrated into the diffusion model's denoising process, ensures the generation of high-quality images. It maintains its effectiveness for old tasks even when new tasks are introduced, preserving image generation quality and reducing the risk of catastrophic forgetting in classifiers. Our empirical studies on diverse datasets demonstrate that our proposed method significantly outperforms existing state-of-the-art models, highlighting its exceptional ability to preserve image quality and enhance the model's memory retention.
KOPPA: Improving Prompt-based Continual Learning with Key-Query Orthogonal Projection and Prototype-based One-Versus-All
Nov 30, 2023Drawing inspiration from prompt tuning techniques applied to Large Language Models, recent methods based on pre-trained ViT networks have achieved remarkable results in the field of Continual Learning. Specifically, these approaches propose to maintain a set of prompts and allocate a subset of them to learn each task using a key-query matching strategy. However, they may encounter limitations when lacking control over the correlations between old task queries and keys of future tasks, the shift of features in the latent space, and the relative separation of latent vectors learned in independent tasks. In this work, we introduce a novel key-query learning strategy based on orthogonal projection, inspired by model-agnostic meta-learning, to enhance prompt matching efficiency and address the challenge of shifting features. Furthermore, we introduce a One-Versus-All (OVA) prototype-based component that enhances the classification head distinction. Experimental results on benchmark datasets demonstrate that our method empowers the model to achieve results surpassing those of current state-of-the-art approaches by a large margin of up to 20%.