 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYongwei Wang
CCDM: Continuous Conditional Diffusion Models for Image Generation
May 06, 2024
Continuous Conditional Generative Modeling (CCGM) aims to estimate the distribution of high-dimensional data, typically images, conditioned on scalar continuous variables known as regression labels. While Continuous conditional Generative Adversarial Networks (CcGANs) were initially designed for this task, their adversarial training mechanism remains vulnerable to extremely sparse or imbalanced data, resulting in suboptimal outcomes. To enhance the quality of generated images, a promising alternative is to replace CcGANs with Conditional Diffusion Models (CDMs), renowned for their stable training process and ability to produce more realistic images. However, existing CDMs encounter challenges when applied to CCGM tasks due to several limitations such as inadequate U-Net architectures and deficient model fitting mechanisms for handling regression labels. In this paper, we introduce Continuous Conditional Diffusion Models (CCDMs), the first CDM designed specifically for the CCGM task. CCDMs address the limitations of existing CDMs by introducing specially designed conditional diffusion processes, a modified denoising U-Net with a custom-made conditioning mechanism, a novel hard vicinal loss for model fitting, and an efficient conditional sampling procedure. With comprehensive experiments on four datasets with varying resolutions ranging from 64x64 to 192x192, we demonstrate the superiority of the proposed CCDM over state-of-the-art CCGM models, establishing new benchmarks in CCGM. Extensive ablation studies validate the model design and implementation configuration of the proposed CCDM. Our code is publicly available at https://github.com/UBCDingXin/CCDM.
Impart: An Imperceptible and Effective Label-Specific Backdoor Attack
Mar 18, 2024



Backdoor attacks have been shown to impose severe threats to real security-critical scenarios. Although previous works can achieve high attack success rates, they either require access to victim models which may significantly reduce their threats in practice, or perform visually noticeable in stealthiness. Besides, there is still room to improve the attack success rates in the scenario that different poisoned samples may have different target labels (a.k.a., the all-to-all setting). In this study, we propose a novel imperceptible backdoor attack framework, named Impart, in the scenario where the attacker has no access to the victim model. Specifically, in order to enhance the attack capability of the all-to-all setting, we first propose a label-specific attack. Different from previous works which try to find an imperceptible pattern and add it to the source image as the poisoned image, we then propose to generate perturbations that align with the target label in the image feature by a surrogate model. In this way, the generated poisoned images are attached with knowledge about the target class, which significantly enhances the attack capability.
HGAttack: Transferable Heterogeneous Graph Adversarial Attack
Jan 18, 2024Heterogeneous Graph Neural Networks (HGNNs) are increasingly recognized for their performance in areas like the web and e-commerce, where resilience against adversarial attacks is crucial. However, existing adversarial attack methods, which are primarily designed for homogeneous graphs, fall short when applied to HGNNs due to their limited ability to address the structural and semantic complexity of HGNNs. This paper introduces HGAttack, the first dedicated gray box evasion attack method for heterogeneous graphs. We design a novel surrogate model to closely resemble the behaviors of the target HGNN and utilize gradient-based methods for perturbation generation. Specifically, the proposed surrogate model effectively leverages heterogeneous information by extracting meta-path induced subgraphs and applying GNNs to learn node embeddings with distinct semantics from each subgraph. This approach improves the transferability of generated attacks on the target HGNN and significantly reduces memory costs. For perturbation generation, we introduce a semantics-aware mechanism that leverages subgraph gradient information to autonomously identify vulnerable edges across a wide range of relations within a constrained perturbation budget. We validate HGAttack's efficacy with comprehensive experiments on three datasets, providing empirical analyses of its generated perturbations. Outperforming baseline methods, HGAttack demonstrated significant efficacy in diminishing the performance of target HGNN models, affirming the effectiveness of our approach in evaluating the robustness of HGNNs against adversarial attacks.
Turning Waste into Wealth: Leveraging Low-Quality Samples for Enhancing Continuous Conditional Generative Adversarial Networks
Aug 20, 2023



Continuous Conditional Generative Adversarial Networks (CcGANs) enable generative modeling conditional on continuous scalar variables (termed regression labels). However, they can produce subpar fake images due to limited training data. Although Negative Data Augmentation (NDA) effectively enhances unconditional and class-conditional GANs by introducing anomalies into real training images, guiding the GANs away from low-quality outputs, its impact on CcGANs is limited, as it fails to replicate negative samples that may occur during the CcGAN sampling. We present a novel NDA approach called Dual-NDA specifically tailored for CcGANs to address this problem. Dual-NDA employs two types of negative samples: visually unrealistic images generated from a pre-trained CcGAN and label-inconsistent images created by manipulating real images' labels. Leveraging these negative samples, we introduce a novel discriminator objective alongside a modified CcGAN training algorithm. Empirical analysis on UTKFace and Steering Angle reveals that Dual-NDA consistently enhances the visual fidelity and label consistency of fake images generated by CcGANs, exhibiting a substantial performance gain over the vanilla NDA. Moreover, by applying Dual-NDA, CcGANs demonstrate a remarkable advancement beyond the capabilities of state-of-the-art conditional GANs and diffusion models, establishing a new pinnacle of performance.
Occlusion-Robust FAU Recognition by Mining Latent Space of Masked Autoencoders
Dec 08, 2022



Facial action units (FAUs) are critical for fine-grained facial expression analysis. Although FAU detection has been actively studied using ideally high quality images, it was not thoroughly studied under heavily occluded conditions. In this paper, we propose the first occlusion-robust FAU recognition method to maintain FAU detection performance under heavy occlusions. Our novel approach takes advantage of rich information from the latent space of masked autoencoder (MAE) and transforms it into FAU features. Bypassing the occlusion reconstruction step, our model efficiently extracts FAU features of occluded faces by mining the latent space of a pretrained masked autoencoder. Both node and edge-level knowledge distillation are also employed to guide our model to find a mapping between latent space vectors and FAU features. Facial occlusion conditions, including random small patches and large blocks, are thoroughly studied. Experimental results on BP4D and DISFA datasets show that our method can achieve state-of-the-art performances under the studied facial occlusion, significantly outperforming existing baseline methods. In particular, even under heavy occlusion, the proposed method can achieve comparable performance as state-of-the-art methods under normal conditions.
MetaNetwork: A Task-agnostic Network Parameters Generation Framework for Improving Device Model Generalization
Sep 12, 2022
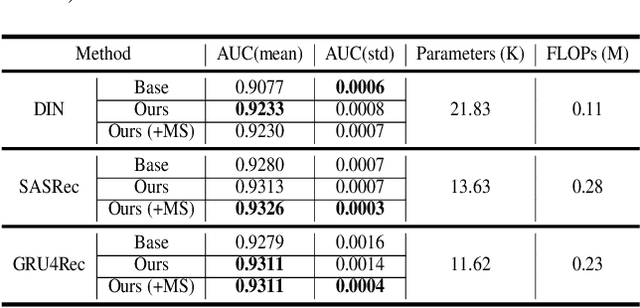
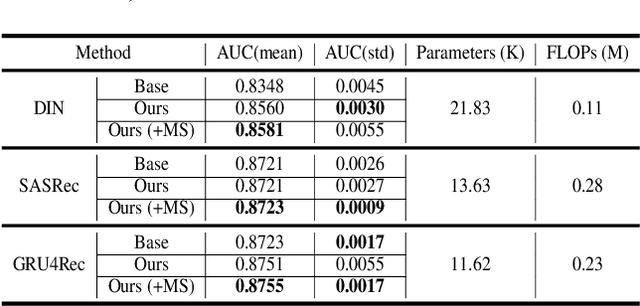

Deploying machine learning models on mobile devices has gained increasing attention. To tackle the model generalization problem with the limitations of hardware resources on the device, the device model needs to be lightweight by techniques such as model compression from the cloud model. However, the major obstacle to improve the device model generalization is the distribution shift between the data of cloud and device models, since the data distribution on device model often changes over time (e.g., users might have different preferences in recommendation system). Although real-time fine-tuning and distillation method take this situation into account, these methods require on-device training, which are practically infeasible due to the low computational power and a lack of real-time labeled samples on the device. In this paper, we propose a novel task-agnostic framework, named MetaNetwork, for generating adaptive device model parameters from cloud without on-device training. Specifically, our MetaNetwork is deployed on cloud and consists of MetaGenerator and MetaStabilizer modules. The MetaGenerator is designed to learn a mapping function from samples to model parameters, and it can generate and deliver the adaptive parameters to the device based on samples uploaded from the device to the cloud. The MetaStabilizer aims to reduce the oscillation of the MetaGenerator, accelerate the convergence and improve the model performance during both training and inference. We evaluate our method on two tasks with three datasets. Extensive experiments show that MetaNetwork can achieve competitive performances in different modalities.
Fight Fire With Fire: Reversing Skin Adversarial Examples by Multiscale Diffusive and Denoising Aggregation Mechanism
Aug 22, 2022



Reliable skin cancer diagnosis models play an essential role in early screening and medical intervention. Prevailing computer-aided skin cancer classification systems employ deep learning approaches. However, recent studies reveal their extreme vulnerability to adversarial attacks -- often imperceptible perturbations to significantly reduce performances of skin cancer diagnosis models. To mitigate these threats, this work presents a simple, effective and resource-efficient defense framework by reverse engineering adversarial perturbations in skin cancer images. Specifically, a multiscale image pyramid is first established to better preserve discriminative structures in medical imaging domain. To neutralize adversarial effects, skin images at different scales are then progressively diffused by injecting isotropic Gaussian noises to move the adversarial examples to the clean image manifold. Crucially, to further reverse adversarial noises and suppress redundant injected noises, a novel multiscale denoising mechanism is carefully designed that aggregates image information from neighboring scales. We evaluated the defensive effectiveness of our method on ISIC 2019, a largest skin cancer multiclass classification dataset. Experimental results demonstrate that the proposed method can successfully reverse adversarial perturbations from different attacks and significantly outperform some state-of-the-art methods in defending skin cancer diagnosis models.
Revisiting Item Promotion in GNN-based Collaborative Filtering: A Masked Targeted Topological Attack Perspective
Aug 21, 2022



Graph neural networks (GNN) based collaborative filtering (CF) have attracted increasing attention in e-commerce and social media platforms. However, there still lack efforts to evaluate the robustness of such CF systems in deployment. Fundamentally different from existing attacks, this work revisits the item promotion task and reformulates it from a targeted topological attack perspective for the first time. Specifically, we first develop a targeted attack formulation to maximally increase a target item's popularity. We then leverage gradient-based optimizations to find a solution. However, we observe the gradient estimates often appear noisy due to the discrete nature of a graph, which leads to a degradation of attack ability. To resolve noisy gradient effects, we then propose a masked attack objective that can remarkably enhance the topological attack ability. Furthermore, we design a computationally efficient approach to the proposed attack, thus making it feasible to evaluate large-large CF systems. Experiments on two real-world datasets show the effectiveness of our attack in analyzing the robustness of GNN-based CF more practically.
SSD-KD: A Self-supervised Diverse Knowledge Distillation Method for Lightweight Skin Lesion Classification Using Dermoscopic Images
Mar 30, 2022



Skin cancer is one of the most common types of malignancy, affecting a large population and causing a heavy economic burden worldwide. Over the last few years, computer-aided diagnosis has been rapidly developed and make great progress in healthcare and medical practices due to the advances in artificial intelligence. However, most studies in skin cancer detection keep pursuing high prediction accuracies without considering the limitation of computing resources on portable devices. In this case, knowledge distillation (KD) has been proven as an efficient tool to help improve the adaptability of lightweight models under limited resources, meanwhile keeping a high-level representation capability. To bridge the gap, this study specifically proposes a novel method, termed SSD-KD, that unifies diverse knowledge into a generic KD framework for skin diseases classification. Our method models an intra-instance relational feature representation and integrates it with existing KD research. A dual relational knowledge distillation architecture is self-supervisedly trained while the weighted softened outputs are also exploited to enable the student model to capture richer knowledge from the teacher model. To demonstrate the effectiveness of our method, we conduct experiments on ISIC 2019, a large-scale open-accessed benchmark of skin diseases dermoscopic images. Experiments show that our distilled lightweight model can achieve an accuracy as high as 85% for the classification tasks of 8 different skin diseases with minimal parameters and computing requirements. Ablation studies confirm the effectiveness of our intra- and inter-instance relational knowledge integration strategy. Compared with state-of-the-art knowledge distillation techniques, the proposed method demonstrates improved performances for multi-diseases classification on the large-scale dermoscopy database.
Delving into Deep Image Prior for Adversarial Defense: A Novel Reconstruction-based Defense Framework
Jul 31, 2021



Deep learning based image classification models are shown vulnerable to adversarial attacks by injecting deliberately crafted noises to clean images. To defend against adversarial attacks in a training-free and attack-agnostic manner, this work proposes a novel and effective reconstruction-based defense framework by delving into deep image prior (DIP). Fundamentally different from existing reconstruction-based defenses, the proposed method analyzes and explicitly incorporates the model decision process into our defense. Given an adversarial image, firstly we map its reconstructed images during DIP optimization to the model decision space, where cross-boundary images can be detected and on-boundary images can be further localized. Then, adversarial noise is purified by perturbing on-boundary images along the reverse direction to the adversarial image. Finally, on-manifold images are stitched to construct an image that can be correctly predicted by the victim classifier. Extensive experiments demonstrate that the proposed method outperforms existing state-of-the-art reconstruction-based methods both in defending white-box attacks and defense-aware attacks. Moreover, the proposed method can maintain a high visual quality during adversarial image reconstruction.