 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZan Wang
Move as You Say, Interact as You Can: Language-guided Human Motion Generation with Scene Affordance
Mar 26, 2024

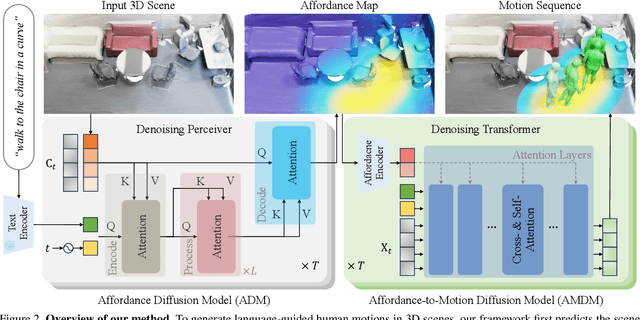


Despite significant advancements in text-to-motion synthesis, generating language-guided human motion within 3D environments poses substantial challenges. These challenges stem primarily from (i) the absence of powerful generative models capable of jointly modeling natural language, 3D scenes, and human motion, and (ii) the generative models' intensive data requirements contrasted with the scarcity of comprehensive, high-quality, language-scene-motion datasets. To tackle these issues, we introduce a novel two-stage framework that employs scene affordance as an intermediate representation, effectively linking 3D scene grounding and conditional motion generation. Our framework comprises an Affordance Diffusion Model (ADM) for predicting explicit affordance map and an Affordance-to-Motion Diffusion Model (AMDM) for generating plausible human motions. By leveraging scene affordance maps, our method overcomes the difficulty in generating human motion under multimodal condition signals, especially when training with limited data lacking extensive language-scene-motion pairs. Our extensive experiments demonstrate that our approach consistently outperforms all baselines on established benchmarks, including HumanML3D and HUMANISE. Additionally, we validate our model's exceptional generalization capabilities on a specially curated evaluation set featuring previously unseen descriptions and scenes.
Impart: An Imperceptible and Effective Label-Specific Backdoor Attack
Mar 18, 2024



Backdoor attacks have been shown to impose severe threats to real security-critical scenarios. Although previous works can achieve high attack success rates, they either require access to victim models which may significantly reduce their threats in practice, or perform visually noticeable in stealthiness. Besides, there is still room to improve the attack success rates in the scenario that different poisoned samples may have different target labels (a.k.a., the all-to-all setting). In this study, we propose a novel imperceptible backdoor attack framework, named Impart, in the scenario where the attacker has no access to the victim model. Specifically, in order to enhance the attack capability of the all-to-all setting, we first propose a label-specific attack. Different from previous works which try to find an imperceptible pattern and add it to the source image as the poisoned image, we then propose to generate perturbations that align with the target label in the image feature by a surrogate model. In this way, the generated poisoned images are attached with knowledge about the target class, which significantly enhances the attack capability.
Scaling Up Dynamic Human-Scene Interaction Modeling
Mar 13, 2024

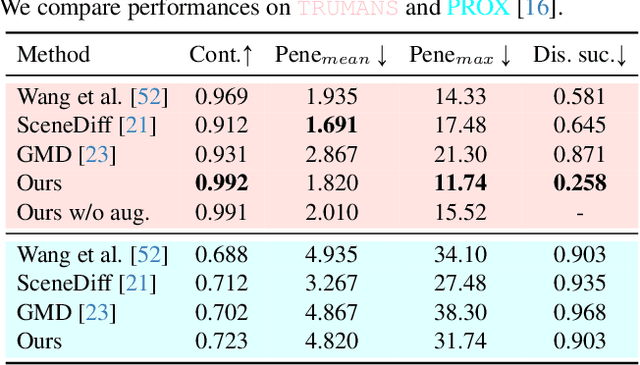
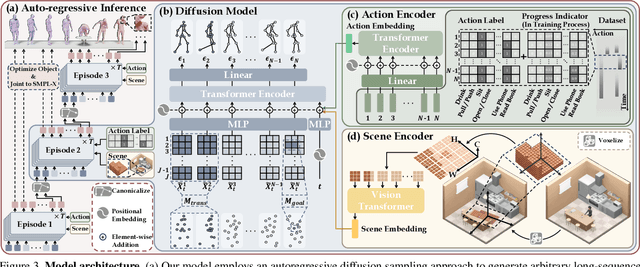
Confronting the challenges of data scarcity and advanced motion synthesis in human-scene interaction modeling, we introduce the TRUMANS dataset alongside a novel HSI motion synthesis method. TRUMANS stands as the most comprehensive motion-captured HSI dataset currently available, encompassing over 15 hours of human interactions across 100 indoor scenes. It intricately captures whole-body human motions and part-level object dynamics, focusing on the realism of contact. This dataset is further scaled up by transforming physical environments into exact virtual models and applying extensive augmentations to appearance and motion for both humans and objects while maintaining interaction fidelity. Utilizing TRUMANS, we devise a diffusion-based autoregressive model that efficiently generates HSI sequences of any length, taking into account both scene context and intended actions. In experiments, our approach shows remarkable zero-shot generalizability on a range of 3D scene datasets (e.g., PROX, Replica, ScanNet, ScanNet++), producing motions that closely mimic original motion-captured sequences, as confirmed by quantitative experiments and human studies.
LLMs as Bridges: Reformulating Grounded Multimodal Named Entity Recognition
Feb 17, 2024Grounded Multimodal Named Entity Recognition (GMNER) is a nascent multimodal task that aims to identify named entities, entity types and their corresponding visual regions. GMNER task exhibits two challenging properties: 1) The weak correlation between image-text pairs in social media results in a significant portion of named entities being ungroundable. 2) There exists a distinction between coarse-grained referring expressions commonly used in similar tasks (e.g., phrase localization, referring expression comprehension) and fine-grained named entities. In this paper, we propose RiVEG, a unified framework that reformulates GMNER into a joint MNER-VE-VG task by leveraging large language models (LLMs) as a connecting bridge. This reformulation brings two benefits: 1) It maintains the optimal MNER performance and eliminates the need for employing object detection methods to pre-extract regional features, thereby naturally addressing two major limitations of existing GMNER methods. 2) The introduction of entity expansion expression and Visual Entailment (VE) Module unifies Visual Grounding (VG) and Entity Grounding (EG). It enables RiVEG to effortlessly inherit the Visual Entailment and Visual Grounding capabilities of any current or prospective multimodal pretraining models. Extensive experiments demonstrate that RiVEG outperforms state-of-the-art methods on the existing GMNER dataset and achieves absolute leads of 10.65%, 6.21%, and 8.83% in all three subtasks.
TCM-GPT: Efficient Pre-training of Large Language Models for Domain Adaptation in Traditional Chinese Medicine
Nov 03, 2023Pre-training and fine-tuning have emerged as a promising paradigm across various natural language processing (NLP) tasks. The effectiveness of pretrained large language models (LLM) has witnessed further enhancement, holding potential for applications in the field of medicine, particularly in the context of Traditional Chinese Medicine (TCM). However, the application of these general models to specific domains often yields suboptimal results, primarily due to challenges like lack of domain knowledge, unique objectives, and computational efficiency. Furthermore, their effectiveness in specialized domains, such as Traditional Chinese Medicine, requires comprehensive evaluation. To address the above issues, we propose a novel domain specific TCMDA (TCM Domain Adaptation) approach, efficient pre-training with domain-specific corpus. Specifically, we first construct a large TCM-specific corpus, TCM-Corpus-1B, by identifying domain keywords and retreving from general corpus. Then, our TCMDA leverages the LoRA which freezes the pretrained model's weights and uses rank decomposition matrices to efficiently train specific dense layers for pre-training and fine-tuning, efficiently aligning the model with TCM-related tasks, namely TCM-GPT-7B. We further conducted extensive experiments on two TCM tasks, including TCM examination and TCM diagnosis. TCM-GPT-7B archived the best performance across both datasets, outperforming other models by relative increments of 17% and 12% in accuracy, respectively. To the best of our knowledge, our study represents the pioneering validation of domain adaptation of a large language model with 7 billion parameters in TCM domain. We will release both TCMCorpus-1B and TCM-GPT-7B model once accepted to facilitate interdisciplinary development in TCM and NLP, serving as the foundation for further study.
Diffusion-based Generation, Optimization, and Planning in 3D Scenes
Jan 15, 2023
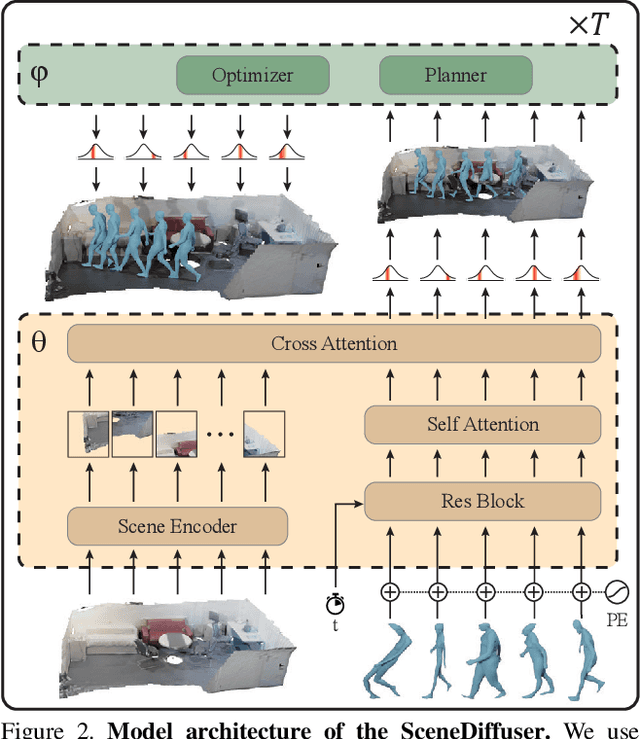


We introduce SceneDiffuser, a conditional generative model for 3D scene understanding. SceneDiffuser provides a unified model for solving scene-conditioned generation, optimization, and planning. In contrast to prior works, SceneDiffuser is intrinsically scene-aware, physics-based, and goal-oriented. With an iterative sampling strategy, SceneDiffuser jointly formulates the scene-aware generation, physics-based optimization, and goal-oriented planning via a diffusion-based denoising process in a fully differentiable fashion. Such a design alleviates the discrepancies among different modules and the posterior collapse of previous scene-conditioned generative models. We evaluate SceneDiffuser with various 3D scene understanding tasks, including human pose and motion generation, dexterous grasp generation, path planning for 3D navigation, and motion planning for robot arms. The results show significant improvements compared with previous models, demonstrating the tremendous potential of SceneDiffuser for the broad community of 3D scene understanding.
Perceive, Ground, Reason, and Act: A Benchmark for General-purpose Visual Representation
Nov 28, 2022



Current computer vision models, unlike the human visual system, cannot yet achieve general-purpose visual understanding. Existing efforts to create a general vision model are limited in the scope of assessed tasks and offer no overarching framework to perform them holistically. We present a new comprehensive benchmark, General-purpose Visual Understanding Evaluation (G-VUE), covering the full spectrum of visual cognitive abilities with four functional domains $\unicode{x2014}$ Perceive, Ground, Reason, and Act. The four domains are embodied in 11 carefully curated tasks, from 3D reconstruction to visual reasoning and manipulation. Along with the benchmark, we provide a general encoder-decoder framework to allow for the evaluation of arbitrary visual representation on all 11 tasks. We evaluate various pre-trained visual representations with our framework and observe that (1) Transformer-based visual backbone generally outperforms CNN-based backbone on G-VUE, (2) visual representations from vision-language pre-training are superior to those with vision-only pre-training across visual tasks. With G-VUE, we provide a holistic evaluation standard to motivate research toward building general-purpose visual systems via obtaining more general-purpose visual representations.
HUMANISE: Language-conditioned Human Motion Generation in 3D Scenes
Oct 18, 2022



Learning to generate diverse scene-aware and goal-oriented human motions in 3D scenes remains challenging due to the mediocre characteristics of the existing datasets on Human-Scene Interaction (HSI); they only have limited scale/quality and lack semantics. To fill in the gap, we propose a large-scale and semantic-rich synthetic HSI dataset, denoted as HUMANISE, by aligning the captured human motion sequences with various 3D indoor scenes. We automatically annotate the aligned motions with language descriptions that depict the action and the unique interacting objects in the scene; e.g., sit on the armchair near the desk. HUMANISE thus enables a new generation task, language-conditioned human motion generation in 3D scenes. The proposed task is challenging as it requires joint modeling of the 3D scene, human motion, and natural language. To tackle this task, we present a novel scene-and-language conditioned generative model that can produce 3D human motions of the desirable action interacting with the specified objects. Our experiments demonstrate that our model generates diverse and semantically consistent human motions in 3D scenes.
Targeted Data Poisoning Attack on News Recommendation System by Content Perturbation
Mar 10, 2022



News Recommendation System(NRS) has become a fundamental technology to many online news services. Meanwhile, several studies show that recommendation systems(RS) are vulnerable to data poisoning attacks, and the attackers have the ability to mislead the system to perform as their desires. A widely studied attack approach, injecting fake users, can be applied on the NRS when the NRS is treated the same as the other systems whose items are fixed. However, in the NRS, as each item (i.e. news) is more informative, we propose a novel approach to poison the NRS, which is to perturb contents of some browsed news that results in the manipulation of the rank of the target news. Intuitively, an attack is useless if it is highly likely to be caught, i.e., exposed. To address this, we introduce a notion of the exposure risk and propose a novel problem of attacking a history news dataset by means of perturbations where the goal is to maximize the manipulation of the target news rank while keeping the risk of exposure under a given budget. We design a reinforcement learning framework, called TDP-CP, which contains a two-stage hierarchical model to reduce the searching space. Meanwhile, influence estimation is also applied to save the time on retraining the NRS for rewards. We test the performance of TDP-CP under three NRSs and on different target news. Our experiments show that TDP-CP can increase the rank of the target news successfully with a limited exposure budget.
PEARL: Parallelized Expert-Assisted Reinforcement Learning for Scene Rearrangement Planning
May 10, 2021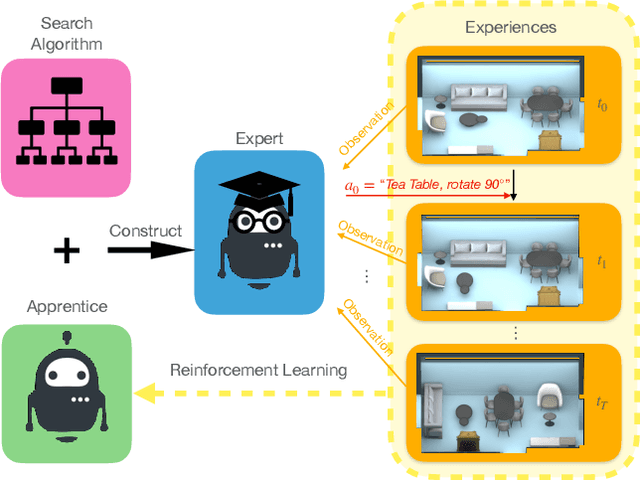

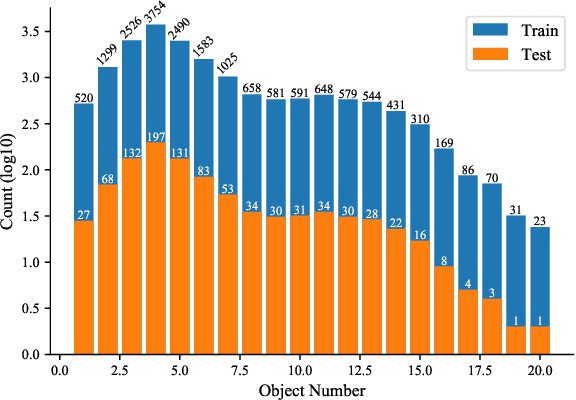
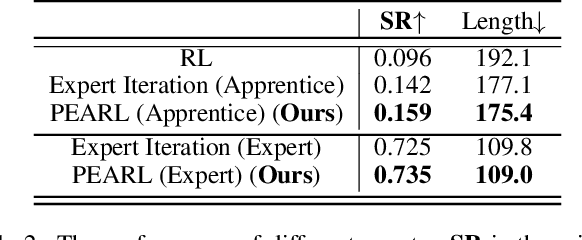
Scene Rearrangement Planning (SRP) is an interior task proposed recently. The previous work defines the action space of this task with handcrafted coarse-grained actions that are inflexible to be used for transforming scene arrangement and intractable to be deployed in practice. Additionally, this new task lacks realistic indoor scene rearrangement data to feed popular data-hungry learning approaches and meet the needs of quantitative evaluation. To address these problems, we propose a fine-grained action definition for SRP and introduce a large-scale scene rearrangement dataset. We also propose a novel learning paradigm to efficiently train an agent through self-playing, without any prior knowledge. The agent trained via our paradigm achieves superior performance on the introduced dataset compared to the baseline agents. We provide a detailed analysis of the design of our approach in our experiments.