 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaoxiong Jia
Closed-Loop Open-Vocabulary Mobile Manipulation with GPT-4V
Apr 16, 2024
Autonomous robot navigation and manipulation in open environments require reasoning and replanning with closed-loop feedback. We present COME-robot, the first closed-loop framework utilizing the GPT-4V vision-language foundation model for open-ended reasoning and adaptive planning in real-world scenarios. We meticulously construct a library of action primitives for robot exploration, navigation, and manipulation, serving as callable execution modules for GPT-4V in task planning. On top of these modules, GPT-4V serves as the brain that can accomplish multimodal reasoning, generate action policy with code, verify the task progress, and provide feedback for replanning. Such design enables COME-robot to (i) actively perceive the environments, (ii) perform situated reasoning, and (iii) recover from failures. Through comprehensive experiments involving 8 challenging real-world tabletop and manipulation tasks, COME-robot demonstrates a significant improvement in task success rate (~25%) compared to state-of-the-art baseline methods. We further conduct comprehensive analyses to elucidate how COME-robot's design facilitates failure recovery, free-form instruction following, and long-horizon task planning.
PhyScene: Physically Interactable 3D Scene Synthesis for Embodied AI
Apr 15, 2024With recent developments in Embodied Artificial Intelligence (EAI) research, there has been a growing demand for high-quality, large-scale interactive scene generation. While prior methods in scene synthesis have prioritized the naturalness and realism of the generated scenes, the physical plausibility and interactivity of scenes have been largely left unexplored. To address this disparity, we introduce PhyScene, a novel method dedicated to generating interactive 3D scenes characterized by realistic layouts, articulated objects, and rich physical interactivity tailored for embodied agents. Based on a conditional diffusion model for capturing scene layouts, we devise novel physics- and interactivity-based guidance mechanisms that integrate constraints from object collision, room layout, and object reachability. Through extensive experiments, we demonstrate that PhyScene effectively leverages these guidance functions for physically interactable scene synthesis, outperforming existing state-of-the-art scene synthesis methods by a large margin. Our findings suggest that the scenes generated by PhyScene hold considerable potential for facilitating diverse skill acquisition among agents within interactive environments, thereby catalyzing further advancements in embodied AI research. Project website: http://physcene.github.io.
Move as You Say, Interact as You Can: Language-guided Human Motion Generation with Scene Affordance
Mar 26, 2024
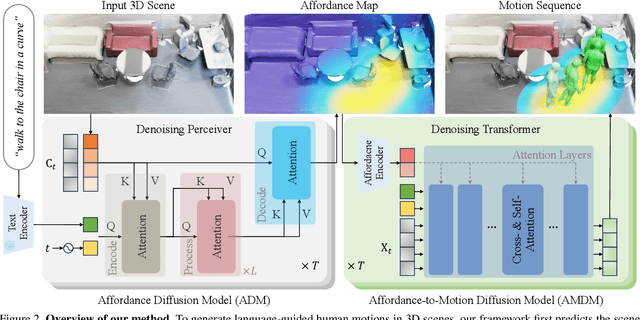


Despite significant advancements in text-to-motion synthesis, generating language-guided human motion within 3D environments poses substantial challenges. These challenges stem primarily from (i) the absence of powerful generative models capable of jointly modeling natural language, 3D scenes, and human motion, and (ii) the generative models' intensive data requirements contrasted with the scarcity of comprehensive, high-quality, language-scene-motion datasets. To tackle these issues, we introduce a novel two-stage framework that employs scene affordance as an intermediate representation, effectively linking 3D scene grounding and conditional motion generation. Our framework comprises an Affordance Diffusion Model (ADM) for predicting explicit affordance map and an Affordance-to-Motion Diffusion Model (AMDM) for generating plausible human motions. By leveraging scene affordance maps, our method overcomes the difficulty in generating human motion under multimodal condition signals, especially when training with limited data lacking extensive language-scene-motion pairs. Our extensive experiments demonstrate that our approach consistently outperforms all baselines on established benchmarks, including HumanML3D and HUMANISE. Additionally, we validate our model's exceptional generalization capabilities on a specially curated evaluation set featuring previously unseen descriptions and scenes.
SceneVerse: Scaling 3D Vision-Language Learning for Grounded Scene Understanding
Jan 17, 20243D vision-language grounding, which focuses on aligning language with the 3D physical environment, stands as a cornerstone in the development of embodied agents. In comparison to recent advancements in the 2D domain, grounding language in 3D scenes faces several significant challenges: (i) the inherent complexity of 3D scenes due to the diverse object configurations, their rich attributes, and intricate relationships; (ii) the scarcity of paired 3D vision-language data to support grounded learning; and (iii) the absence of a unified learning framework to distill knowledge from grounded 3D data. In this work, we aim to address these three major challenges in 3D vision-language by examining the potential of systematically upscaling 3D vision-language learning in indoor environments. We introduce the first million-scale 3D vision-language dataset, SceneVerse, encompassing about 68K 3D indoor scenes and comprising 2.5M vision-language pairs derived from both human annotations and our scalable scene-graph-based generation approach. We demonstrate that this scaling allows for a unified pre-training framework, Grounded Pre-training for Scenes (GPS), for 3D vision-language learning. Through extensive experiments, we showcase the effectiveness of GPS by achieving state-of-the-art performance on all existing 3D visual grounding benchmarks. The vast potential of SceneVerse and GPS is unveiled through zero-shot transfer experiments in the challenging 3D vision-language tasks. Project website: https://scene-verse.github.io .
An Embodied Generalist Agent in 3D World
Nov 18, 2023
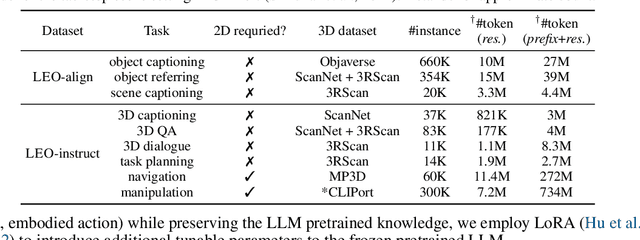
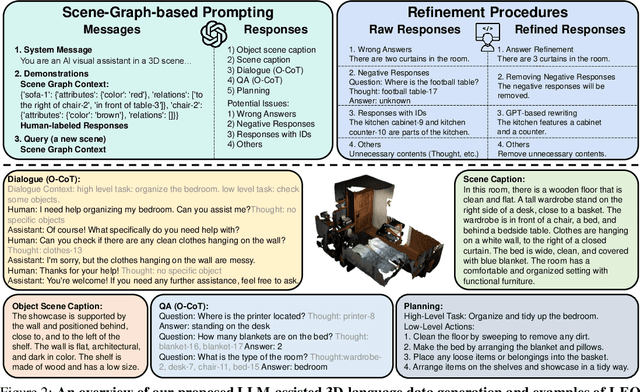
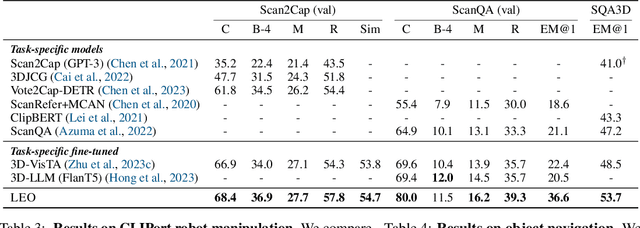
Leveraging massive knowledge and learning schemes from large language models (LLMs), recent machine learning models show notable successes in building generalist agents that exhibit the capability of general-purpose task solving in diverse domains, including natural language processing, computer vision, and robotics. However, a significant challenge remains as these models exhibit limited ability in understanding and interacting with the 3D world. We argue this limitation significantly hinders the current models from performing real-world tasks and further achieving general intelligence. To this end, we introduce an embodied multi-modal and multi-task generalist agent that excels in perceiving, grounding, reasoning, planning, and acting in the 3D world. Our proposed agent, referred to as LEO, is trained with shared LLM-based model architectures, objectives, and weights in two stages: (i) 3D vision-language alignment and (ii) 3D vision-language-action instruction tuning. To facilitate the training, we meticulously curate and generate an extensive dataset comprising object-level and scene-level multi-modal tasks with exceeding scale and complexity, necessitating a deep understanding of and interaction with the 3D world. Through rigorous experiments, we demonstrate LEO's remarkable proficiency across a wide spectrum of tasks, including 3D captioning, question answering, embodied reasoning, embodied navigation, and robotic manipulation. Our ablation results further provide valuable insights for the development of future embodied generalist agents.
ProBio: A Protocol-guided Multimodal Dataset for Molecular Biology Lab
Nov 01, 2023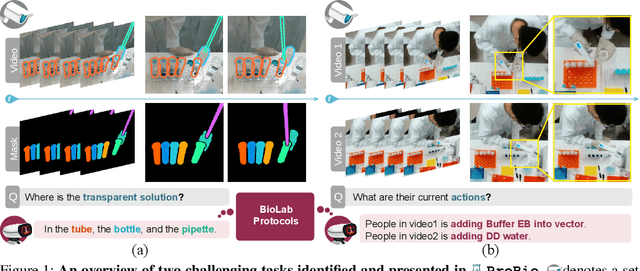
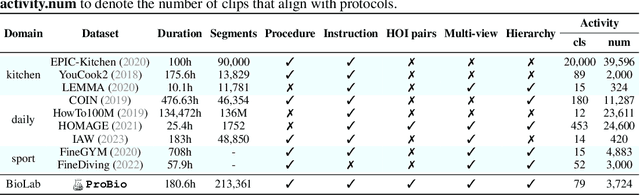

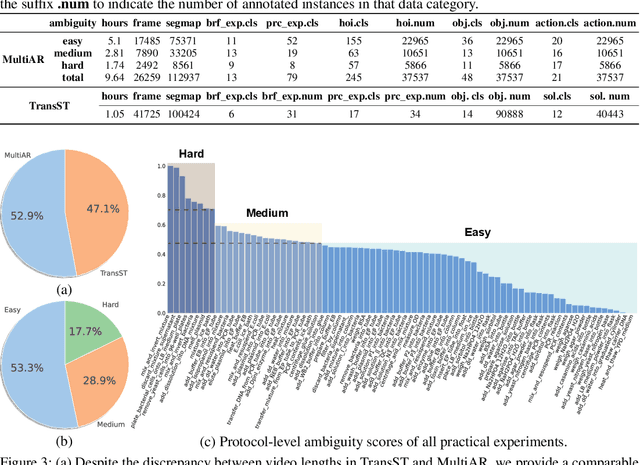
The challenge of replicating research results has posed a significant impediment to the field of molecular biology. The advent of modern intelligent systems has led to notable progress in various domains. Consequently, we embarked on an investigation of intelligent monitoring systems as a means of tackling the issue of the reproducibility crisis. Specifically, we first curate a comprehensive multimodal dataset, named ProBio, as an initial step towards this objective. This dataset comprises fine-grained hierarchical annotations intended for the purpose of studying activity understanding in BioLab. Next, we devise two challenging benchmarks, transparent solution tracking and multimodal action recognition, to emphasize the unique characteristics and difficulties associated with activity understanding in BioLab settings. Finally, we provide a thorough experimental evaluation of contemporary video understanding models and highlight their limitations in this specialized domain to identify potential avenues for future research. We hope ProBio with associated benchmarks may garner increased focus on modern AI techniques in the realm of molecular biology.
X-VoE: Measuring eXplanatory Violation of Expectation in Physical Events
Aug 21, 2023



Intuitive physics is pivotal for human understanding of the physical world, enabling prediction and interpretation of events even in infancy. Nonetheless, replicating this level of intuitive physics in artificial intelligence (AI) remains a formidable challenge. This study introduces X-VoE, a comprehensive benchmark dataset, to assess AI agents' grasp of intuitive physics. Built on the developmental psychology-rooted Violation of Expectation (VoE) paradigm, X-VoE establishes a higher bar for the explanatory capacities of intuitive physics models. Each VoE scenario within X-VoE encompasses three distinct settings, probing models' comprehension of events and their underlying explanations. Beyond model evaluation, we present an explanation-based learning system that captures physics dynamics and infers occluded object states solely from visual sequences, without explicit occlusion labels. Experimental outcomes highlight our model's alignment with human commonsense when tested against X-VoE. A remarkable feature is our model's ability to visually expound VoE events by reconstructing concealed scenes. Concluding, we discuss the findings' implications and outline future research directions. Through X-VoE, we catalyze the advancement of AI endowed with human-like intuitive physics capabilities.
ARNOLD: A Benchmark for Language-Grounded Task Learning With Continuous States in Realistic 3D Scenes
Apr 09, 2023
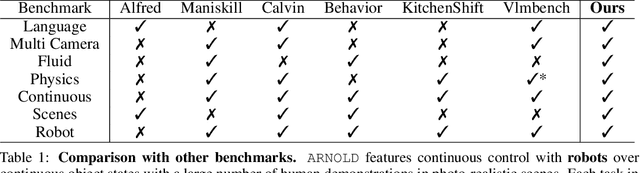
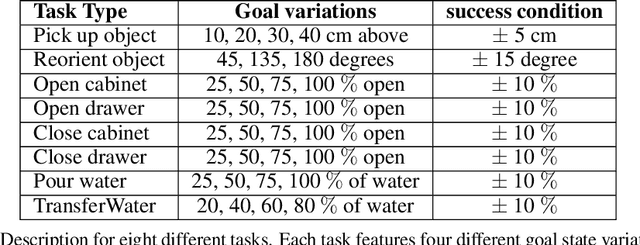

Understanding the continuous states of objects is essential for task learning and planning in the real world. However, most existing task learning benchmarks assume discrete(e.g., binary) object goal states, which poses challenges for the learning of complex tasks and transferring learned policy from simulated environments to the real world. Furthermore, state discretization limits a robot's ability to follow human instructions based on the grounding of actions and states. To tackle these challenges, we present ARNOLD, a benchmark that evaluates language-grounded task learning with continuous states in realistic 3D scenes. ARNOLD is comprised of 8 language-conditioned tasks that involve understanding object states and learning policies for continuous goals. To promote language-instructed learning, we provide expert demonstrations with template-generated language descriptions. We assess task performance by utilizing the latest language-conditioned policy learning models. Our results indicate that current models for language-conditioned manipulations continue to experience significant challenges in novel goal-state generalizations, scene generalizations, and object generalizations. These findings highlight the need to develop new algorithms that address this gap and underscore the potential for further research in this area. See our project page at: https://arnold-benchmark.github.io
Diffusion-based Generation, Optimization, and Planning in 3D Scenes
Jan 15, 2023
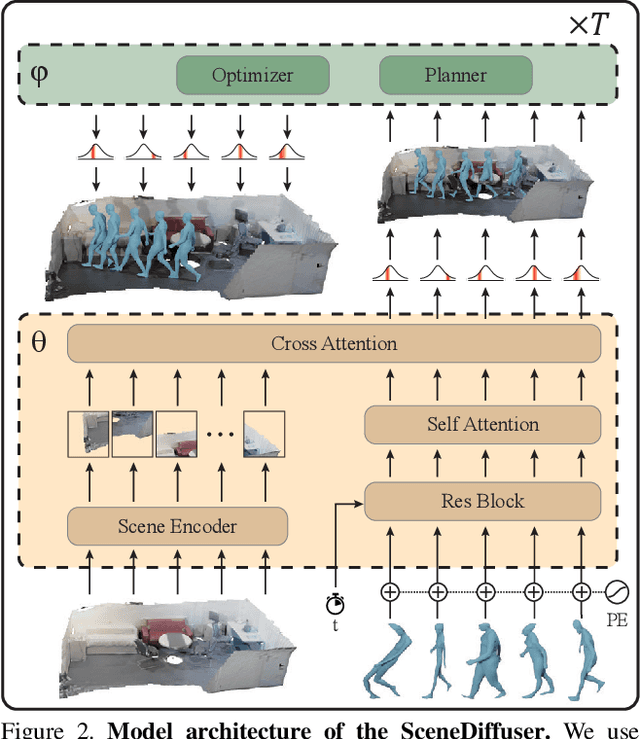


We introduce SceneDiffuser, a conditional generative model for 3D scene understanding. SceneDiffuser provides a unified model for solving scene-conditioned generation, optimization, and planning. In contrast to prior works, SceneDiffuser is intrinsically scene-aware, physics-based, and goal-oriented. With an iterative sampling strategy, SceneDiffuser jointly formulates the scene-aware generation, physics-based optimization, and goal-oriented planning via a diffusion-based denoising process in a fully differentiable fashion. Such a design alleviates the discrepancies among different modules and the posterior collapse of previous scene-conditioned generative models. We evaluate SceneDiffuser with various 3D scene understanding tasks, including human pose and motion generation, dexterous grasp generation, path planning for 3D navigation, and motion planning for robot arms. The results show significant improvements compared with previous models, demonstrating the tremendous potential of SceneDiffuser for the broad community of 3D scene understanding.
Perceive, Ground, Reason, and Act: A Benchmark for General-purpose Visual Representation
Nov 28, 2022



Current computer vision models, unlike the human visual system, cannot yet achieve general-purpose visual understanding. Existing efforts to create a general vision model are limited in the scope of assessed tasks and offer no overarching framework to perform them holistically. We present a new comprehensive benchmark, General-purpose Visual Understanding Evaluation (G-VUE), covering the full spectrum of visual cognitive abilities with four functional domains $\unicode{x2014}$ Perceive, Ground, Reason, and Act. The four domains are embodied in 11 carefully curated tasks, from 3D reconstruction to visual reasoning and manipulation. Along with the benchmark, we provide a general encoder-decoder framework to allow for the evaluation of arbitrary visual representation on all 11 tasks. We evaluate various pre-trained visual representations with our framework and observe that (1) Transformer-based visual backbone generally outperforms CNN-based backbone on G-VUE, (2) visual representations from vision-language pre-training are superior to those with vision-only pre-training across visual tasks. With G-VUE, we provide a holistic evaluation standard to motivate research toward building general-purpose visual systems via obtaining more general-purpose visual representations.