 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhitian Li
Closed-Loop Open-Vocabulary Mobile Manipulation with GPT-4V
Apr 16, 2024
Autonomous robot navigation and manipulation in open environments require reasoning and replanning with closed-loop feedback. We present COME-robot, the first closed-loop framework utilizing the GPT-4V vision-language foundation model for open-ended reasoning and adaptive planning in real-world scenarios. We meticulously construct a library of action primitives for robot exploration, navigation, and manipulation, serving as callable execution modules for GPT-4V in task planning. On top of these modules, GPT-4V serves as the brain that can accomplish multimodal reasoning, generate action policy with code, verify the task progress, and provide feedback for replanning. Such design enables COME-robot to (i) actively perceive the environments, (ii) perform situated reasoning, and (iii) recover from failures. Through comprehensive experiments involving 8 challenging real-world tabletop and manipulation tasks, COME-robot demonstrates a significant improvement in task success rate (~25%) compared to state-of-the-art baseline methods. We further conduct comprehensive analyses to elucidate how COME-robot's design facilitates failure recovery, free-form instruction following, and long-horizon task planning.
Analysis on Multi-robot Relative 6-DOF Pose Estimation Error Based on UWB Range
Sep 27, 2023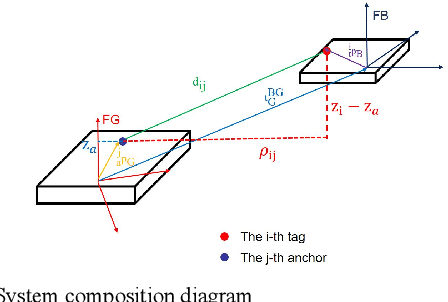
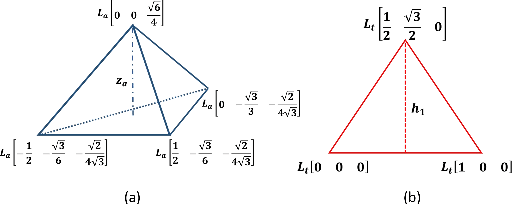
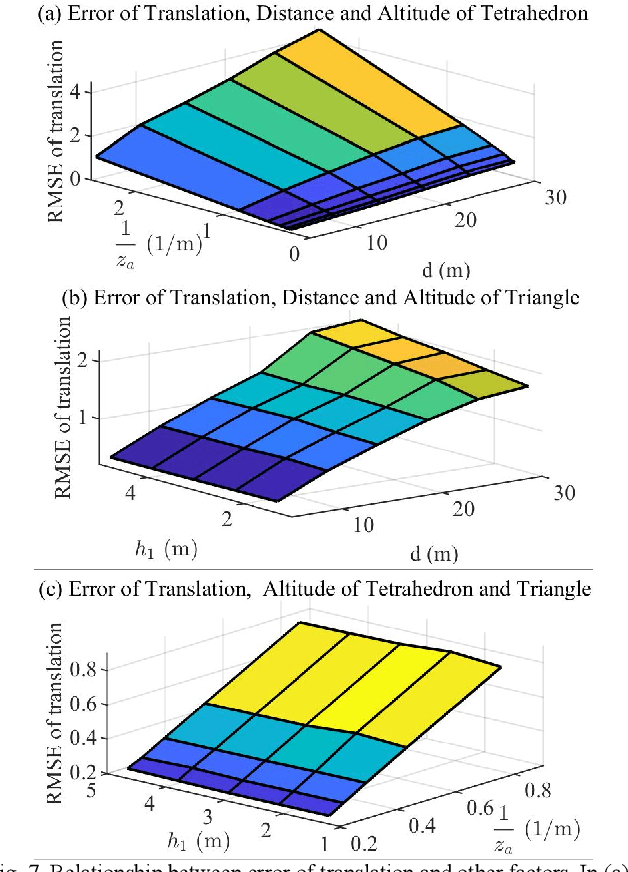
Relative pose estimation is the foundational requirement for multi-robot system, while it is a challenging research topic in infrastructure-free scenes. In this study, we analyze the relative 6-DOF pose estimation error of multi-robot system in GNSS-denied and anchor-free environment. An analytical lower bound of position and orientation estimation error is given under the assumption that distance between the nodes are far more than the size of robotic platform. Through simulation, impact of distance between nodes, altitudes and circumradius of tag simplex on pose estimation accuracy is discussed, which verifies the analysis results. Our analysis is expected to determine parameters (e.g. deployment of tags) of UWB based multi-robot systems.