 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiyuan Huang
Closed-Loop Open-Vocabulary Mobile Manipulation with GPT-4V
Apr 16, 2024
Autonomous robot navigation and manipulation in open environments require reasoning and replanning with closed-loop feedback. We present COME-robot, the first closed-loop framework utilizing the GPT-4V vision-language foundation model for open-ended reasoning and adaptive planning in real-world scenarios. We meticulously construct a library of action primitives for robot exploration, navigation, and manipulation, serving as callable execution modules for GPT-4V in task planning. On top of these modules, GPT-4V serves as the brain that can accomplish multimodal reasoning, generate action policy with code, verify the task progress, and provide feedback for replanning. Such design enables COME-robot to (i) actively perceive the environments, (ii) perform situated reasoning, and (iii) recover from failures. Through comprehensive experiments involving 8 challenging real-world tabletop and manipulation tasks, COME-robot demonstrates a significant improvement in task success rate (~25%) compared to state-of-the-art baseline methods. We further conduct comprehensive analyses to elucidate how COME-robot's design facilitates failure recovery, free-form instruction following, and long-horizon task planning.
PhyScene: Physically Interactable 3D Scene Synthesis for Embodied AI
Apr 15, 2024With recent developments in Embodied Artificial Intelligence (EAI) research, there has been a growing demand for high-quality, large-scale interactive scene generation. While prior methods in scene synthesis have prioritized the naturalness and realism of the generated scenes, the physical plausibility and interactivity of scenes have been largely left unexplored. To address this disparity, we introduce PhyScene, a novel method dedicated to generating interactive 3D scenes characterized by realistic layouts, articulated objects, and rich physical interactivity tailored for embodied agents. Based on a conditional diffusion model for capturing scene layouts, we devise novel physics- and interactivity-based guidance mechanisms that integrate constraints from object collision, room layout, and object reachability. Through extensive experiments, we demonstrate that PhyScene effectively leverages these guidance functions for physically interactable scene synthesis, outperforming existing state-of-the-art scene synthesis methods by a large margin. Our findings suggest that the scenes generated by PhyScene hold considerable potential for facilitating diverse skill acquisition among agents within interactive environments, thereby catalyzing further advancements in embodied AI research. Project website: http://physcene.github.io.
Draw-and-Understand: Leveraging Visual Prompts to Enable MLLMs to Comprehend What You Want
Apr 01, 2024
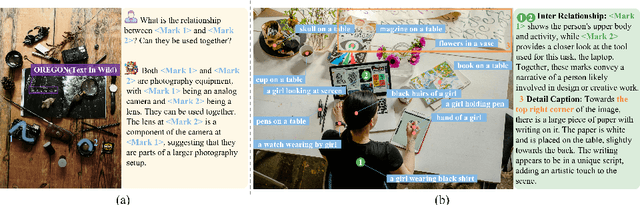
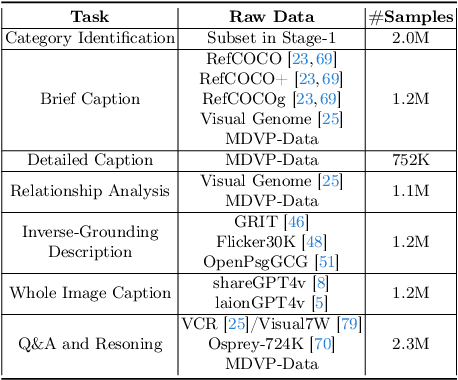
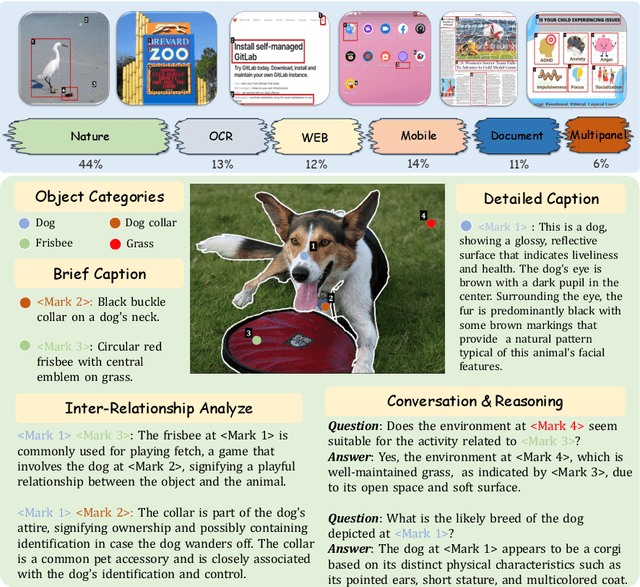
The interaction between humans and artificial intelligence (AI) is a crucial factor that reflects the effectiveness of multimodal large language models (MLLMs). However, current MLLMs primarily focus on image-level comprehension and limit interaction to textual instructions, thereby constraining their flexibility in usage and depth of response. In this paper, we introduce the Draw-and-Understand project: a new model, a multi-domain dataset, and a challenging benchmark for visual prompting. Specifically, we propose SPHINX-V, a new end-to-end trained Multimodal Large Language Model (MLLM) that connects a vision encoder, a visual prompt encoder and an LLM for various visual prompts (points, bounding boxes, and free-form shape) and language understanding. To advance visual prompting research for MLLMs, we introduce MDVP-Data and MDVP-Bench. MDVP-Data features a multi-domain dataset containing 1.6M unique image-visual prompt-text instruction-following samples, including natural images, document images, OCR images, mobile screenshots, web screenshots, and multi-panel images. Furthermore, we present MDVP-Bench, a comprehensive and challenging benchmark to assess a model's capability in understanding visual prompting instructions. Our experiments demonstrate SPHINX-V's impressive multimodal interaction capabilities through visual prompting, revealing significant improvements in detailed pixel-level description and question-answering abilities.
Move as You Say, Interact as You Can: Language-guided Human Motion Generation with Scene Affordance
Mar 26, 2024
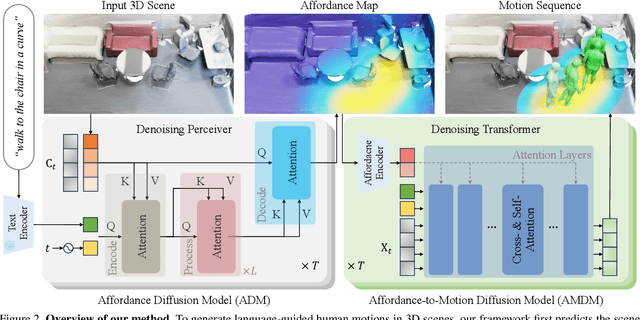


Despite significant advancements in text-to-motion synthesis, generating language-guided human motion within 3D environments poses substantial challenges. These challenges stem primarily from (i) the absence of powerful generative models capable of jointly modeling natural language, 3D scenes, and human motion, and (ii) the generative models' intensive data requirements contrasted with the scarcity of comprehensive, high-quality, language-scene-motion datasets. To tackle these issues, we introduce a novel two-stage framework that employs scene affordance as an intermediate representation, effectively linking 3D scene grounding and conditional motion generation. Our framework comprises an Affordance Diffusion Model (ADM) for predicting explicit affordance map and an Affordance-to-Motion Diffusion Model (AMDM) for generating plausible human motions. By leveraging scene affordance maps, our method overcomes the difficulty in generating human motion under multimodal condition signals, especially when training with limited data lacking extensive language-scene-motion pairs. Our extensive experiments demonstrate that our approach consistently outperforms all baselines on established benchmarks, including HumanML3D and HUMANISE. Additionally, we validate our model's exceptional generalization capabilities on a specially curated evaluation set featuring previously unseen descriptions and scenes.
AnySkill: Learning Open-Vocabulary Physical Skill for Interactive Agents
Mar 19, 2024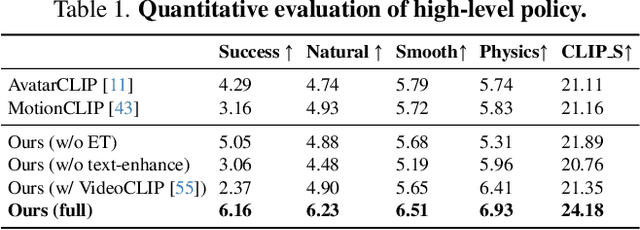
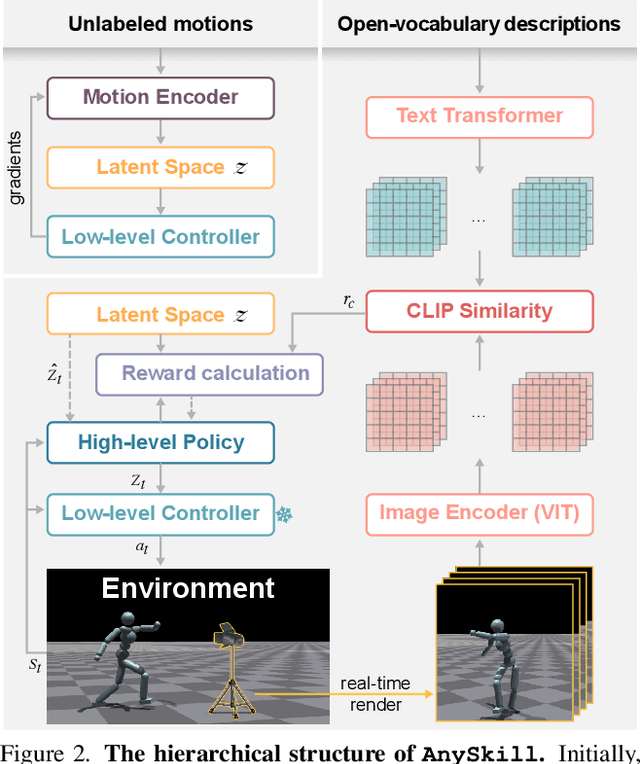


Traditional approaches in physics-based motion generation, centered around imitation learning and reward shaping, often struggle to adapt to new scenarios. To tackle this limitation, we propose AnySkill, a novel hierarchical method that learns physically plausible interactions following open-vocabulary instructions. Our approach begins by developing a set of atomic actions via a low-level controller trained via imitation learning. Upon receiving an open-vocabulary textual instruction, AnySkill employs a high-level policy that selects and integrates these atomic actions to maximize the CLIP similarity between the agent's rendered images and the text. An important feature of our method is the use of image-based rewards for the high-level policy, which allows the agent to learn interactions with objects without manual reward engineering. We demonstrate AnySkill's capability to generate realistic and natural motion sequences in response to unseen instructions of varying lengths, marking it the first method capable of open-vocabulary physical skill learning for interactive humanoid agents.
ManipVQA: Injecting Robotic Affordance and Physically Grounded Information into Multi-Modal Large Language Models
Mar 17, 2024
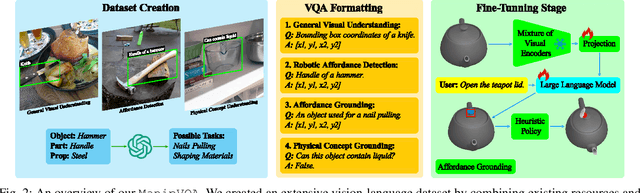


The integration of Multimodal Large Language Models (MLLMs) with robotic systems has significantly enhanced the ability of robots to interpret and act upon natural language instructions. Despite these advancements, conventional MLLMs are typically trained on generic image-text pairs, lacking essential robotics knowledge such as affordances and physical knowledge, which hampers their efficacy in manipulation tasks. To bridge this gap, we introduce ManipVQA, a novel framework designed to endow MLLMs with Manipulation-centric knowledge through a Visual Question-Answering format. This approach not only encompasses tool detection and affordance recognition but also extends to a comprehensive understanding of physical concepts. Our approach starts with collecting a varied set of images displaying interactive objects, which presents a broad range of challenges in tool object detection, affordance, and physical concept predictions. To seamlessly integrate this robotic-specific knowledge with the inherent vision-reasoning capabilities of MLLMs, we adopt a unified VQA format and devise a fine-tuning strategy that preserves the original vision-reasoning abilities while incorporating the new robotic insights. Empirical evaluations conducted in robotic simulators and across various vision task benchmarks demonstrate the robust performance of ManipVQA. Code and dataset will be made publicly available at https://github.com/SiyuanHuang95/ManipVQA.
Scaling Up Dynamic Human-Scene Interaction Modeling
Mar 13, 2024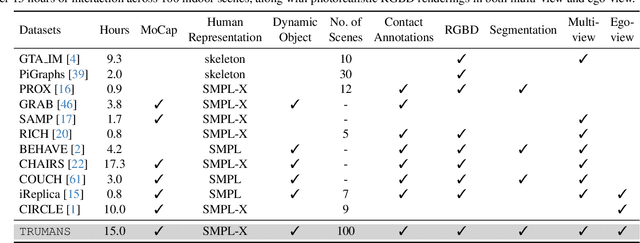

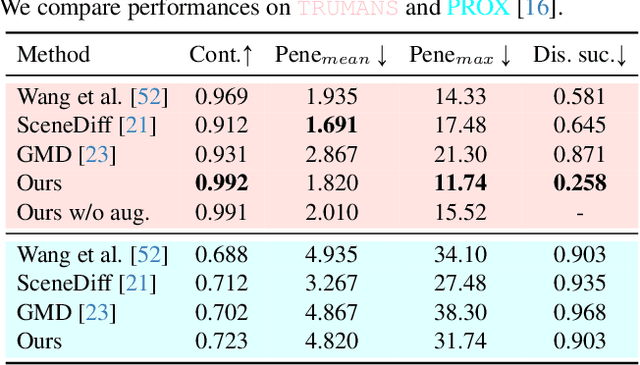
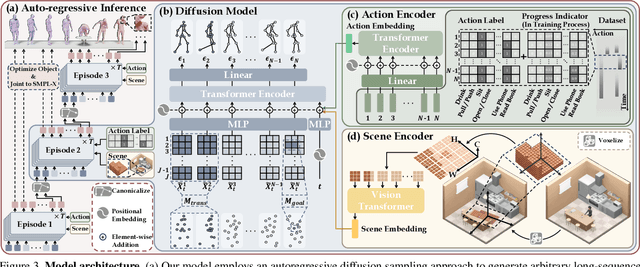
Confronting the challenges of data scarcity and advanced motion synthesis in human-scene interaction modeling, we introduce the TRUMANS dataset alongside a novel HSI motion synthesis method. TRUMANS stands as the most comprehensive motion-captured HSI dataset currently available, encompassing over 15 hours of human interactions across 100 indoor scenes. It intricately captures whole-body human motions and part-level object dynamics, focusing on the realism of contact. This dataset is further scaled up by transforming physical environments into exact virtual models and applying extensive augmentations to appearance and motion for both humans and objects while maintaining interaction fidelity. Utilizing TRUMANS, we devise a diffusion-based autoregressive model that efficiently generates HSI sequences of any length, taking into account both scene context and intended actions. In experiments, our approach shows remarkable zero-shot generalizability on a range of 3D scene datasets (e.g., PROX, Replica, ScanNet, ScanNet++), producing motions that closely mimic original motion-captured sequences, as confirmed by quantitative experiments and human studies.
Graph Parsing Networks
Feb 22, 2024Graph pooling compresses graph information into a compact representation. State-of-the-art graph pooling methods follow a hierarchical approach, which reduces the graph size step-by-step. These methods must balance memory efficiency with preserving node information, depending on whether they use node dropping or node clustering. Additionally, fixed pooling ratios or numbers of pooling layers are predefined for all graphs, which prevents personalized pooling structures from being captured for each individual graph. In this work, inspired by bottom-up grammar induction, we propose an efficient graph parsing algorithm to infer the pooling structure, which then drives graph pooling. The resulting Graph Parsing Network (GPN) adaptively learns personalized pooling structure for each individual graph. GPN benefits from the discrete assignments generated by the graph parsing algorithm, allowing good memory efficiency while preserving node information intact. Experimental results on standard benchmarks demonstrate that GPN outperforms state-of-the-art graph pooling methods in graph classification tasks while being able to achieve competitive performance in node classification tasks. We also conduct a graph reconstruction task to show GPN's ability to preserve node information and measure both memory and time efficiency through relevant tests.
Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
Feb 22, 2024A pivotal advancement in the progress of large language models (LLMs) is the emergence of the Mixture-of-Experts (MoE) LLMs. Compared to traditional LLMs, MoE LLMs can achieve higher performance with fewer parameters, but it is still hard to deploy them due to their immense parameter sizes. Different from previous weight pruning methods that rely on specifically designed hardware, this paper mainly aims to enhance the deployment efficiency of MoE LLMs by introducing plug-and-play expert-level sparsification techniques. Specifically, we propose, for the first time to our best knowledge, post-training approaches for task-agnostic and task-specific expert pruning and skipping of MoE LLMs, tailored to improve deployment efficiency while maintaining model performance across a wide range of tasks. Extensive experiments show that our proposed methods can simultaneously reduce model sizes and increase the inference speed, while maintaining satisfactory performance. Data and code will be available at https://github.com/Lucky-Lance/Expert_Sparsity.
SPHINX-X: Scaling Data and Parameters for a Family of Multi-modal Large Language Models
Feb 08, 2024We propose SPHINX-X, an extensive Multimodality Large Language Model (MLLM) series developed upon SPHINX. To improve the architecture and training efficiency, we modify the SPHINX framework by removing redundant visual encoders, bypassing fully-padded sub-images with skip tokens, and simplifying multi-stage training into a one-stage all-in-one paradigm. To fully unleash the potential of MLLMs, we assemble a comprehensive multi-domain and multimodal dataset covering publicly available resources in language, vision, and vision-language tasks. We further enrich this collection with our curated OCR intensive and Set-of-Mark datasets, extending the diversity and generality. By training over different base LLMs including TinyLlama1.1B, InternLM2-7B, LLaMA2-13B, and Mixtral8x7B, we obtain a spectrum of MLLMs that vary in parameter size and multilingual capabilities. Comprehensive benchmarking reveals a strong correlation between the multi-modal performance with the data and parameter scales. Code and models are released at https://github.com/Alpha-VLLM/LLaMA2-Accessory