 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeng Jin
LLMBind: A Unified Modality-Task Integration Framework
Mar 08, 2024
While recent progress in multimodal large language models tackles various modality tasks, they posses limited integration capabilities for complex multi-modality tasks, consequently constraining the development of the field. In this work, we take the initiative to explore and propose the LLMBind, a unified framework for modality task integration, which binds Large Language Models and corresponding pre-trained task models with task-specific tokens. Consequently, LLMBind can interpret inputs and produce outputs in versatile combinations of image, text, video, and audio. Specifically, we introduce a Mixture-of-Experts technique to enable effective learning for different multimodal tasks through collaboration among diverse experts. Furthermore, we create a multi-task dataset comprising 400k instruction data, which unlocks the ability for interactive visual generation and editing tasks. Extensive experiments show the effectiveness of our framework across various tasks, including image, video, audio generation, image segmentation, and image editing. More encouragingly, our framework can be easily extended to other modality tasks, showcasing the promising potential of creating a unified AI agent for modeling universal modalities.
SPHINX-X: Scaling Data and Parameters for a Family of Multi-modal Large Language Models
Feb 08, 2024We propose SPHINX-X, an extensive Multimodality Large Language Model (MLLM) series developed upon SPHINX. To improve the architecture and training efficiency, we modify the SPHINX framework by removing redundant visual encoders, bypassing fully-padded sub-images with skip tokens, and simplifying multi-stage training into a one-stage all-in-one paradigm. To fully unleash the potential of MLLMs, we assemble a comprehensive multi-domain and multimodal dataset covering publicly available resources in language, vision, and vision-language tasks. We further enrich this collection with our curated OCR intensive and Set-of-Mark datasets, extending the diversity and generality. By training over different base LLMs including TinyLlama1.1B, InternLM2-7B, LLaMA2-13B, and Mixtral8x7B, we obtain a spectrum of MLLMs that vary in parameter size and multilingual capabilities. Comprehensive benchmarking reveals a strong correlation between the multi-modal performance with the data and parameter scales. Code and models are released at https://github.com/Alpha-VLLM/LLaMA2-Accessory
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
Feb 04, 2024Recent advances demonstrate that scaling Large Vision-Language Models (LVLMs) effectively improves downstream task performances. However, existing scaling methods enable all model parameters to be active for each token in the calculation, which brings massive training and inferring costs. In this work, we propose a simple yet effective training strategy MoE-Tuning for LVLMs. This strategy innovatively addresses the common issue of performance degradation in multi-modal sparsity learning, consequently constructing a sparse model with an outrageous number of parameters but a constant computational cost. Furthermore, we present the MoE-LLaVA, a MoE-based sparse LVLM architecture, which uniquely activates only the top-k experts through routers during deployment, keeping the remaining experts inactive. Extensive experiments show the significant performance of MoE-LLaVA in a variety of visual understanding and object hallucination benchmarks. Remarkably, with only approximately 3B sparsely activated parameters, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmark. Through MoE-LLaVA, we aim to establish a baseline for sparse LVLMs and provide valuable insights for future research in developing more efficient and effective multi-modal learning systems. Code is released at \url{https://github.com/PKU-YuanGroup/MoE-LLaVA}.
Instance Brownian Bridge as Texts for Open-vocabulary Video Instance Segmentation
Jan 18, 2024Temporally locating objects with arbitrary class texts is the primary pursuit of open-vocabulary Video Instance Segmentation (VIS). Because of the insufficient vocabulary of video data, previous methods leverage image-text pretraining model for recognizing object instances by separately aligning each frame and class texts, ignoring the correlation between frames. As a result, the separation breaks the instance movement context of videos, causing inferior alignment between video and text. To tackle this issue, we propose to link frame-level instance representations as a Brownian Bridge to model instance dynamics and align bridge-level instance representation to class texts for more precisely open-vocabulary VIS (BriVIS). Specifically, we build our system upon a frozen video segmentor to generate frame-level instance queries, and design Temporal Instance Resampler (TIR) to generate queries with temporal context from frame queries. To mold instance queries to follow Brownian bridge and accomplish alignment with class texts, we design Bridge-Text Alignment (BTA) to learn discriminative bridge-level representations of instances via contrastive objectives. Setting MinVIS as the basic video segmentor, BriVIS surpasses the Open-vocabulary SOTA (OV2Seg) by a clear margin. For example, on the challenging large-vocabulary VIS dataset (BURST), BriVIS achieves 7.43 mAP and exhibits 49.49% improvement compared to OV2Seg (4.97 mAP).
Repaint123: Fast and High-quality One Image to 3D Generation with Progressive Controllable 2D Repainting
Dec 27, 2023Recent one image to 3D generation methods commonly adopt Score Distillation Sampling (SDS). Despite the impressive results, there are multiple deficiencies including multi-view inconsistency, over-saturated and over-smoothed textures, as well as the slow generation speed. To address these deficiencies, we present Repaint123 to alleviate multi-view bias as well as texture degradation and speed up the generation process. The core idea is to combine the powerful image generation capability of the 2D diffusion model and the texture alignment ability of the repainting strategy for generating high-quality multi-view images with consistency. We further propose visibility-aware adaptive repainting strength for overlap regions to enhance the generated image quality in the repainting process. The generated high-quality and multi-view consistent images enable the use of simple Mean Square Error (MSE) loss for fast 3D content generation. We conduct extensive experiments and show that our method has a superior ability to generate high-quality 3D content with multi-view consistency and fine textures in 2 minutes from scratch. Our project page is available at https://pku-yuangroup.github.io/repaint123/.
FreestyleRet: Retrieving Images from Style-Diversified Queries
Dec 08, 2023Image Retrieval aims to retrieve corresponding images based on a given query. In application scenarios, users intend to express their retrieval intent through various query styles. However, current retrieval tasks predominantly focus on text-query retrieval exploration, leading to limited retrieval query options and potential ambiguity or bias in user intention. In this paper, we propose the Style-Diversified Query-Based Image Retrieval task, which enables retrieval based on various query styles. To facilitate the novel setting, we propose the first Diverse-Style Retrieval dataset, encompassing diverse query styles including text, sketch, low-resolution, and art. We also propose a light-weighted style-diversified retrieval framework. For various query style inputs, we apply the Gram Matrix to extract the query's textural features and cluster them into a style space with style-specific bases. Then we employ the style-init prompt tuning module to enable the visual encoder to comprehend the texture and style information of the query. Experiments demonstrate that our model, employing the style-init prompt tuning strategy, outperforms existing retrieval models on the style-diversified retrieval task. Moreover, style-diversified queries~(sketch+text, art+text, etc) can be simultaneously retrieved in our model. The auxiliary information from other queries enhances the retrieval performance within the respective query.
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Nov 21, 2023The Large Vision-Language Model (LVLM) has enhanced the performance of various downstream tasks in visual-language understanding. Most existing approaches encode images and videos into separate feature spaces, which are then fed as inputs to large language models. However, due to the lack of unified tokenization for images and videos, namely misalignment before projection, it becomes challenging for a Large Language Model (LLM) to learn multi-modal interactions from several poor projection layers. In this work, we unify visual representation into the language feature space to advance the foundational LLM towards a unified LVLM. As a result, we establish a simple but robust LVLM baseline, Video-LLaVA, which learns from a mixed dataset of images and videos, mutually enhancing each other. Video-LLaVA achieves superior performances on a broad range of 9 image benchmarks across 5 image question-answering datasets and 4 image benchmark toolkits. Additionally, our Video-LLaVA also outperforms Video-ChatGPT by 5.8%, 9.9%, 18.6%, and 10.1% on MSRVTT, MSVD, TGIF, and ActivityNet, respectively. Notably, extensive experiments demonstrate that Video-LLaVA mutually benefits images and videos within a unified visual representation, outperforming models designed specifically for images or videos. We aim for this work to provide modest insights into the multi-modal inputs for the LLM.
Chat-UniVi: Unified Visual Representation Empowers Large Language Models with Image and Video Understanding
Nov 14, 2023Large language models have demonstrated impressive universal capabilities across a wide range of open-ended tasks and have extended their utility to encompass multimodal conversations. However, existing methods encounter challenges in effectively handling both image and video understanding, particularly with limited visual tokens. In this work, we introduce Chat-UniVi, a unified vision-language model capable of comprehending and engaging in conversations involving images and videos through a unified visual representation. Specifically, we employ a set of dynamic visual tokens to uniformly represent images and videos. This representation framework empowers the model to efficiently utilize a limited number of visual tokens to simultaneously capture the spatial details necessary for images and the comprehensive temporal relationship required for videos. Moreover, we leverage a multi-scale representation, enabling the model to perceive both high-level semantic concepts and low-level visual details. Notably, Chat-UniVi is trained on a mixed dataset containing both images and videos, allowing direct application to tasks involving both mediums without requiring any modifications. Extensive experimental results demonstrate that Chat-UniVi, as a unified model, consistently outperforms even existing methods exclusively designed for either images or videos.
Act As You Wish: Fine-Grained Control of Motion Diffusion Model with Hierarchical Semantic Graphs
Nov 02, 2023Most text-driven human motion generation methods employ sequential modeling approaches, e.g., transformer, to extract sentence-level text representations automatically and implicitly for human motion synthesis. However, these compact text representations may overemphasize the action names at the expense of other important properties and lack fine-grained details to guide the synthesis of subtly distinct motion. In this paper, we propose hierarchical semantic graphs for fine-grained control over motion generation. Specifically, we disentangle motion descriptions into hierarchical semantic graphs including three levels of motions, actions, and specifics. Such global-to-local structures facilitate a comprehensive understanding of motion description and fine-grained control of motion generation. Correspondingly, to leverage the coarse-to-fine topology of hierarchical semantic graphs, we decompose the text-to-motion diffusion process into three semantic levels, which correspond to capturing the overall motion, local actions, and action specifics. Extensive experiments on two benchmark human motion datasets, including HumanML3D and KIT, with superior performances, justify the efficacy of our method. More encouragingly, by modifying the edge weights of hierarchical semantic graphs, our method can continuously refine the generated motion, which may have a far-reaching impact on the community. Code and pre-training weights are available at https://github.com/jpthu17/GraphMotion.
Synthetic Augmentation with Large-scale Unconditional Pre-training
Aug 08, 2023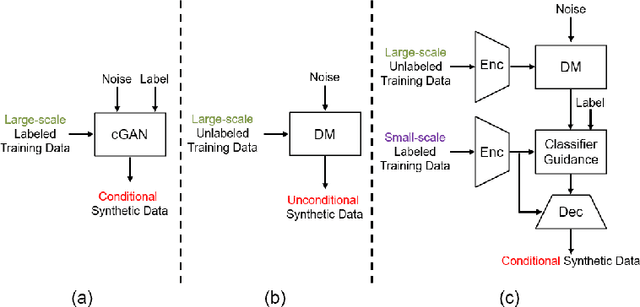
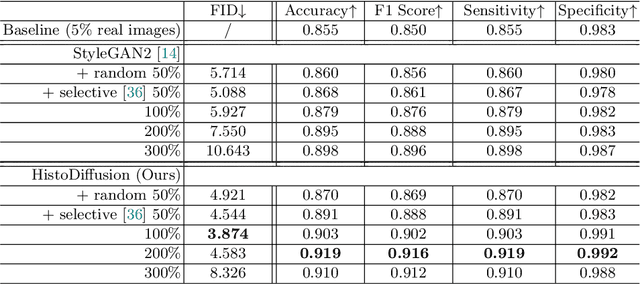

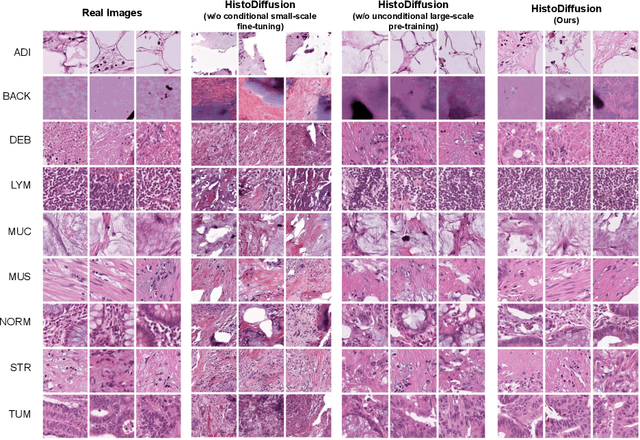
Deep learning based medical image recognition systems often require a substantial amount of training data with expert annotations, which can be expensive and time-consuming to obtain. Recently, synthetic augmentation techniques have been proposed to mitigate the issue by generating realistic images conditioned on class labels. However, the effectiveness of these methods heavily depends on the representation capability of the trained generative model, which cannot be guaranteed without sufficient labeled training data. To further reduce the dependency on annotated data, we propose a synthetic augmentation method called HistoDiffusion, which can be pre-trained on large-scale unlabeled datasets and later applied to a small-scale labeled dataset for augmented training. In particular, we train a latent diffusion model (LDM) on diverse unlabeled datasets to learn common features and generate realistic images without conditional inputs. Then, we fine-tune the model with classifier guidance in latent space on an unseen labeled dataset so that the model can synthesize images of specific categories. Additionally, we adopt a selective mechanism to only add synthetic samples with high confidence of matching to target labels. We evaluate our proposed method by pre-training on three histopathology datasets and testing on a histopathology dataset of colorectal cancer (CRC) excluded from the pre-training datasets. With HistoDiffusion augmentation, the classification accuracy of a backbone classifier is remarkably improved by 6.4% using a small set of the original labels. Our code is available at https://github.com/karenyyy/HistoDiffAug.