 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinhua Cheng
ResVR: Joint Rescaling and Viewport Rendering of Omnidirectional Images
Apr 25, 2024
With the advent of virtual reality technology, omnidirectional image (ODI) rescaling techniques are increasingly embraced for reducing transmitted and stored file sizes while preserving high image quality. Despite this progress, current ODI rescaling methods predominantly focus on enhancing the quality of images in equirectangular projection (ERP) format, which overlooks the fact that the content viewed on head mounted displays (HMDs) is actually a rendered viewport instead of an ERP image. In this work, we emphasize that focusing solely on ERP quality results in inferior viewport visual experiences for users. Thus, we propose ResVR, which is the first comprehensive framework for the joint Rescaling and Viewport Rendering of ODIs. ResVR allows obtaining LR ERP images for transmission while rendering high-quality viewports for users to watch on HMDs. In our ResVR, a novel discrete pixel sampling strategy is developed to tackle the complex mapping between the viewport and ERP, enabling end-to-end training of ResVR pipeline. Furthermore, a spherical pixel shape representation technique is innovatively derived from spherical differentiation to significantly improve the visual quality of rendered viewports. Extensive experiments demonstrate that our ResVR outperforms existing methods in viewport rendering tasks across different fields of view, resolutions, and view directions while keeping a low transmission overhead.
MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators
Apr 07, 2024Recent advances in Text-to-Video generation (T2V) have achieved remarkable success in synthesizing high-quality general videos from textual descriptions. A largely overlooked problem in T2V is that existing models have not adequately encoded physical knowledge of the real world, thus generated videos tend to have limited motion and poor variations. In this paper, we propose \textbf{MagicTime}, a metamorphic time-lapse video generation model, which learns real-world physics knowledge from time-lapse videos and implements metamorphic generation. First, we design a MagicAdapter scheme to decouple spatial and temporal training, encode more physical knowledge from metamorphic videos, and transform pre-trained T2V models to generate metamorphic videos. Second, we introduce a Dynamic Frames Extraction strategy to adapt to metamorphic time-lapse videos, which have a wider variation range and cover dramatic object metamorphic processes, thus embodying more physical knowledge than general videos. Finally, we introduce a Magic Text-Encoder to improve the understanding of metamorphic video prompts. Furthermore, we create a time-lapse video-text dataset called \textbf{ChronoMagic}, specifically curated to unlock the metamorphic video generation ability. Extensive experiments demonstrate the superiority and effectiveness of MagicTime for generating high-quality and dynamic metamorphic videos, suggesting time-lapse video generation is a promising path toward building metamorphic simulators of the physical world.
Envision3D: One Image to 3D with Anchor Views Interpolation
Mar 13, 2024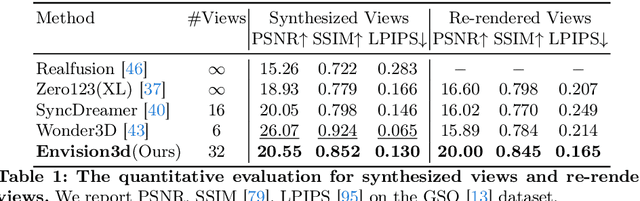
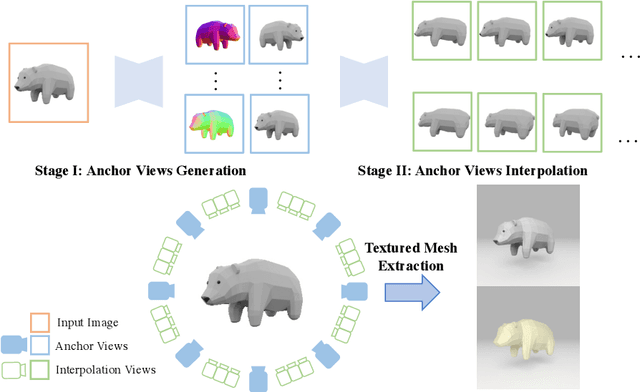

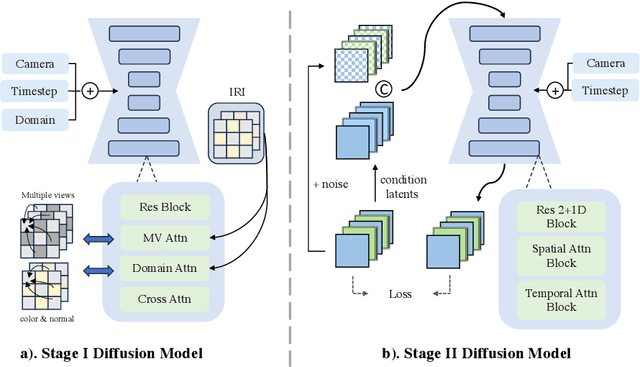
We present Envision3D, a novel method for efficiently generating high-quality 3D content from a single image. Recent methods that extract 3D content from multi-view images generated by diffusion models show great potential. However, it is still challenging for diffusion models to generate dense multi-view consistent images, which is crucial for the quality of 3D content extraction. To address this issue, we propose a novel cascade diffusion framework, which decomposes the challenging dense views generation task into two tractable stages, namely anchor views generation and anchor views interpolation. In the first stage, we train the image diffusion model to generate global consistent anchor views conditioning on image-normal pairs. Subsequently, leveraging our video diffusion model fine-tuned on consecutive multi-view images, we conduct interpolation on the previous anchor views to generate extra dense views. This framework yields dense, multi-view consistent images, providing comprehensive 3D information. To further enhance the overall generation quality, we introduce a coarse-to-fine sampling strategy for the reconstruction algorithm to robustly extract textured meshes from the generated dense images. Extensive experiments demonstrate that our method is capable of generating high-quality 3D content in terms of texture and geometry, surpassing previous image-to-3D baseline methods.
360DVD: Controllable Panorama Video Generation with 360-Degree Video Diffusion Model
Jan 12, 2024360-degree panoramic videos recently attract more interest in both studies and applications, courtesy of the heightened immersive experiences they engender. Due to the expensive cost of capturing 360-degree panoramic videos, generating desirable panoramic videos by given prompts is urgently required. Recently, the emerging text-to-video (T2V) diffusion methods demonstrate notable effectiveness in standard video generation. However, due to the significant gap in content and motion patterns between panoramic and standard videos, these methods encounter challenges in yielding satisfactory 360-degree panoramic videos. In this paper, we propose a controllable panorama video generation pipeline named 360-Degree Video Diffusion model (360DVD) for generating panoramic videos based on the given prompts and motion conditions. Concretely, we introduce a lightweight module dubbed 360-Adapter and assisted 360 Enhancement Techniques to transform pre-trained T2V models for 360-degree video generation. We further propose a new panorama dataset named WEB360 consisting of 360-degree video-text pairs for training 360DVD, addressing the absence of captioned panoramic video datasets. Extensive experiments demonstrate the superiority and effectiveness of 360DVD for panorama video generation. The code and dataset will be released soon.
Repaint123: Fast and High-quality One Image to 3D Generation with Progressive Controllable 2D Repainting
Dec 27, 2023Recent one image to 3D generation methods commonly adopt Score Distillation Sampling (SDS). Despite the impressive results, there are multiple deficiencies including multi-view inconsistency, over-saturated and over-smoothed textures, as well as the slow generation speed. To address these deficiencies, we present Repaint123 to alleviate multi-view bias as well as texture degradation and speed up the generation process. The core idea is to combine the powerful image generation capability of the 2D diffusion model and the texture alignment ability of the repainting strategy for generating high-quality multi-view images with consistency. We further propose visibility-aware adaptive repainting strength for overlap regions to enhance the generated image quality in the repainting process. The generated high-quality and multi-view consistent images enable the use of simple Mean Square Error (MSE) loss for fast 3D content generation. We conduct extensive experiments and show that our method has a superior ability to generate high-quality 3D content with multi-view consistency and fine textures in 2 minutes from scratch. Our project page is available at https://pku-yuangroup.github.io/repaint123/.
Progressive3D: Progressively Local Editing for Text-to-3D Content Creation with Complex Semantic Prompts
Oct 18, 2023Recent text-to-3D generation methods achieve impressive 3D content creation capacity thanks to the advances in image diffusion models and optimizing strategies. However, current methods struggle to generate correct 3D content for a complex prompt in semantics, i.e., a prompt describing multiple interacted objects binding with different attributes. In this work, we propose a general framework named Progressive3D, which decomposes the entire generation into a series of locally progressive editing steps to create precise 3D content for complex prompts, and we constrain the content change to only occur in regions determined by user-defined region prompts in each editing step. Furthermore, we propose an overlapped semantic component suppression technique to encourage the optimization process to focus more on the semantic differences between prompts. Extensive experiments demonstrate that the proposed Progressive3D framework generates precise 3D content for prompts with complex semantics and is general for various text-to-3D methods driven by different 3D representations.
EDA: Explicit Text-Decoupling and Dense Alignment for 3D Visual and Language Learning
Sep 29, 2022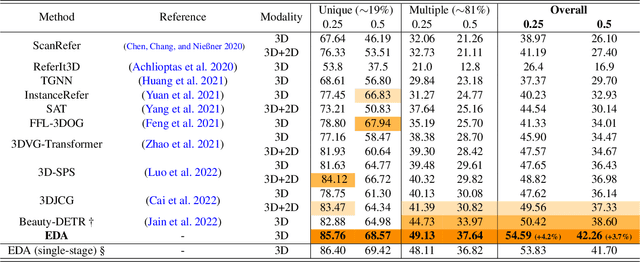
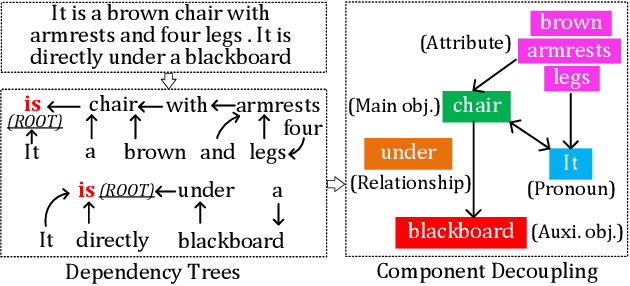
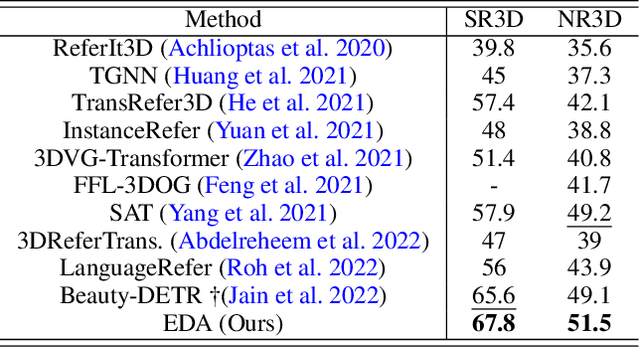
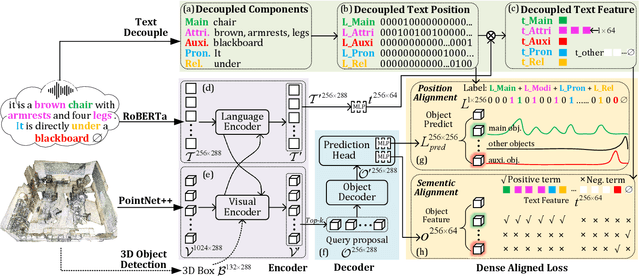
3D visual grounding aims to find the objects within point clouds mentioned by free-form natural language descriptions with rich semantic components. However, existing methods either extract the sentence-level features coupling all words, or focus more on object names, which would lose the word-level information or neglect other attributes. To alleviate this issue, we present EDA that Explicitly Decouples the textual attributes in a sentence and conducts Dense Alignment between such fine-grained language and point cloud objects. Specifically, we first propose a text decoupling module to produce textual features for every semantic component. Then, we design two losses to supervise the dense matching between two modalities: the textual position alignment and object semantic alignment. On top of that, we further introduce two new visual grounding tasks, locating objects without object names and locating auxiliary objects referenced in the descriptions, both of which can thoroughly evaluate the model's dense alignment capacity. Through experiments, we achieve state-of-the-art performance on two widely-adopted visual grounding datasets , ScanRefer and SR3D/NR3D, and obtain absolute leadership on our two newly-proposed tasks. The code will be available at https://github.com/yanmin-wu/EDA.
Learning Disentangled Representation Implicitly via Transformer for Occluded Person Re-Identification
Jul 06, 2021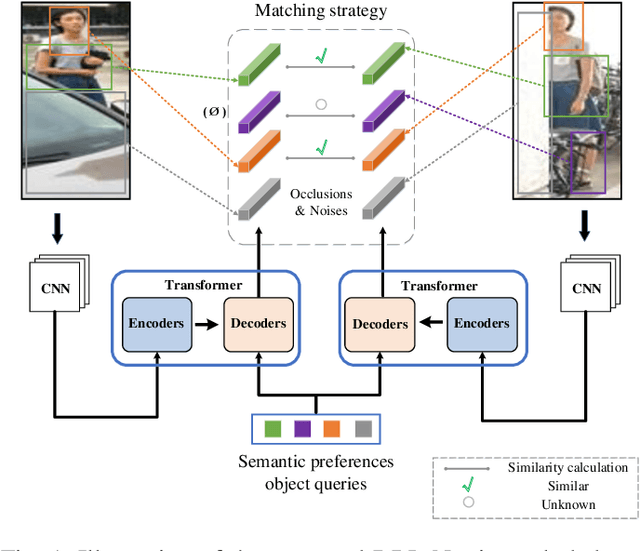
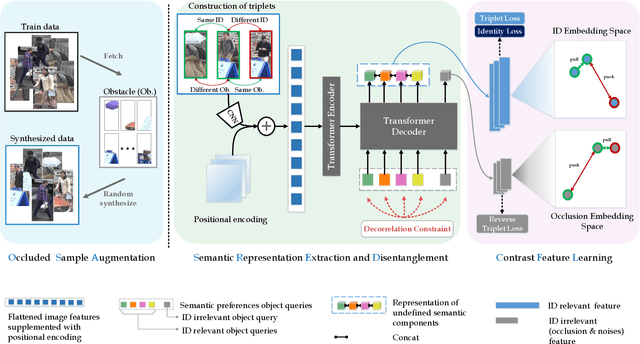

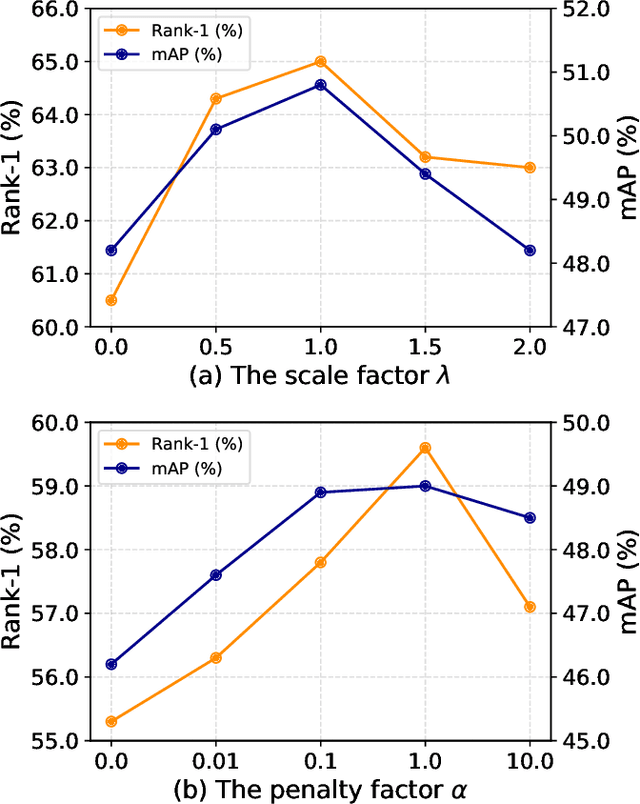
Person re-identification (re-ID) under various occlusions has been a long-standing challenge as person images with different types of occlusions often suffer from misalignment in image matching and ranking. Most existing methods tackle this challenge by aligning spatial features of body parts according to external semantic cues or feature similarities but this alignment approach is complicated and sensitive to noises. We design DRL-Net, a disentangled representation learning network that handles occluded re-ID without requiring strict person image alignment or any additional supervision. Leveraging transformer architectures, DRL-Net achieves alignment-free re-ID via global reasoning of local features of occluded person images. It measures image similarity by automatically disentangling the representation of undefined semantic components, e.g., human body parts or obstacles, under the guidance of semantic preference object queries in the transformer. In addition, we design a decorrelation constraint in the transformer decoder and impose it over object queries for better focus on different semantic components. To better eliminate interference from occlusions, we design a contrast feature learning technique (CFL) for better separation of occlusion features and discriminative ID features. Extensive experiments over occluded and holistic re-ID benchmarks (Occluded-DukeMTMC, Market1501 and DukeMTMC) show that the DRL-Net achieves superior re-ID performance consistently and outperforms the state-of-the-art by large margins for Occluded-DukeMTMC.