 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShijie Zhao
PromptCIR: Blind Compressed Image Restoration with Prompt Learning
Apr 26, 2024
Blind Compressed Image Restoration (CIR) has garnered significant attention due to its practical applications. It aims to mitigate compression artifacts caused by unknown quality factors, particularly with JPEG codecs. Existing works on blind CIR often seek assistance from a quality factor prediction network to facilitate their network to restore compressed images. However, the predicted numerical quality factor lacks spatial information, preventing network adaptability toward image contents. Recent studies in prompt-learning-based image restoration have showcased the potential of prompts to generalize across varied degradation types and degrees. This motivated us to design a prompt-learning-based compressed image restoration network, dubbed PromptCIR, which can effectively restore images from various compress levels. Specifically, PromptCIR exploits prompts to encode compression information implicitly, where prompts directly interact with soft weights generated from image features, thus providing dynamic content-aware and distortion-aware guidance for the restoration process. The light-weight prompts enable our method to adapt to different compression levels, while introducing minimal parameter overhead. Overall, PromptCIR leverages the powerful transformer-based backbone with the dynamic prompt module to proficiently handle blind CIR tasks, winning first place in the NTIRE 2024 challenge of blind compressed image enhancement track. Extensive experiments have validated the effectiveness of our proposed PromptCIR. The code is available at https://github.com/lbc12345/PromptCIR-NTIRE24.
ResVR: Joint Rescaling and Viewport Rendering of Omnidirectional Images
Apr 25, 2024With the advent of virtual reality technology, omnidirectional image (ODI) rescaling techniques are increasingly embraced for reducing transmitted and stored file sizes while preserving high image quality. Despite this progress, current ODI rescaling methods predominantly focus on enhancing the quality of images in equirectangular projection (ERP) format, which overlooks the fact that the content viewed on head mounted displays (HMDs) is actually a rendered viewport instead of an ERP image. In this work, we emphasize that focusing solely on ERP quality results in inferior viewport visual experiences for users. Thus, we propose ResVR, which is the first comprehensive framework for the joint Rescaling and Viewport Rendering of ODIs. ResVR allows obtaining LR ERP images for transmission while rendering high-quality viewports for users to watch on HMDs. In our ResVR, a novel discrete pixel sampling strategy is developed to tackle the complex mapping between the viewport and ERP, enabling end-to-end training of ResVR pipeline. Furthermore, a spherical pixel shape representation technique is innovatively derived from spherical differentiation to significantly improve the visual quality of rendered viewports. Extensive experiments demonstrate that our ResVR outperforms existing methods in viewport rendering tasks across different fields of view, resolutions, and view directions while keeping a low transmission overhead.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Invertible Diffusion Models for Compressed Sensing
Mar 25, 2024While deep neural networks (NN) significantly advance image compressed sensing (CS) by improving reconstruction quality, the necessity of training current CS NNs from scratch constrains their effectiveness and hampers rapid deployment. Although recent methods utilize pre-trained diffusion models for image reconstruction, they struggle with slow inference and restricted adaptability to CS. To tackle these challenges, this paper proposes Invertible Diffusion Models (IDM), a novel efficient, end-to-end diffusion-based CS method. IDM repurposes a large-scale diffusion sampling process as a reconstruction model, and finetunes it end-to-end to recover original images directly from CS measurements, moving beyond the traditional paradigm of one-step noise estimation learning. To enable such memory-intensive end-to-end finetuning, we propose a novel two-level invertible design to transform both (1) the multi-step sampling process and (2) the noise estimation U-Net in each step into invertible networks. As a result, most intermediate features are cleared during training to reduce up to 93.8% GPU memory. In addition, we develop a set of lightweight modules to inject measurements into noise estimator to further facilitate reconstruction. Experiments demonstrate that IDM outperforms existing state-of-the-art CS networks by up to 2.64dB in PSNR. Compared to the recent diffusion model-based approach DDNM, our IDM achieves up to 10.09dB PSNR gain and 14.54 times faster inference.
CAMixerSR: Only Details Need More "Attention"
Mar 15, 2024To satisfy the rapidly increasing demands on the large image (2K-8K) super-resolution (SR), prevailing methods follow two independent tracks: 1) accelerate existing networks by content-aware routing, and 2) design better super-resolution networks via token mixer refining. Despite directness, they encounter unavoidable defects (e.g., inflexible route or non-discriminative processing) limiting further improvements of quality-complexity trade-off. To erase the drawbacks, we integrate these schemes by proposing a content-aware mixer (CAMixer), which assigns convolution for simple contexts and additional deformable window-attention for sparse textures. Specifically, the CAMixer uses a learnable predictor to generate multiple bootstraps, including offsets for windows warping, a mask for classifying windows, and convolutional attentions for endowing convolution with the dynamic property, which modulates attention to include more useful textures self-adaptively and improves the representation capability of convolution. We further introduce a global classification loss to improve the accuracy of predictors. By simply stacking CAMixers, we obtain CAMixerSR which achieves superior performance on large-image SR, lightweight SR, and omnidirectional-image SR.
Optimal Transcoding Resolution Prediction for Efficient Per-Title Bitrate Ladder Estimation
Jan 09, 2024Adaptive video streaming requires efficient bitrate ladder construction to meet heterogeneous network conditions and end-user demands. Per-title optimized encoding typically traverses numerous encoding parameters to search the Pareto-optimal operating points for each video. Recently, researchers have attempted to predict the content-optimized bitrate ladder for pre-encoding overhead reduction. However, existing methods commonly estimate the encoding parameters on the Pareto front and still require subsequent pre-encodings. In this paper, we propose to directly predict the optimal transcoding resolution at each preset bitrate for efficient bitrate ladder construction. We adopt a Temporal Attentive Gated Recurrent Network to capture spatial-temporal features and predict transcoding resolutions as a multi-task classification problem. We demonstrate that content-optimized bitrate ladders can thus be efficiently determined without any pre-encoding. Our method well approximates the ground-truth bitrate-resolution pairs with a slight Bj{\o}ntegaard Delta rate loss of 1.21% and significantly outperforms the state-of-the-art fixed ladder.
Joint State Estimation and Noise Identification Based on Variational Optimization
Dec 15, 2023In this article, the state estimation problems with unknown process noise and measurement noise covariances for both linear and nonlinear systems are considered. By formulating the joint estimation of system state and noise parameters into an optimization problem, a novel adaptive Kalman filter method based on conjugate-computation variational inference, referred to as CVIAKF, is proposed to approximate the joint posterior probability density function of the latent variables. Unlike the existing adaptive Kalman filter methods utilizing variational inference in natural-parameter space, CVIAKF performs optimization in expectation-parameter space, resulting in a faster and simpler solution. Meanwhile, CVIAKF divides optimization objectives into conjugate and non-conjugate parts of nonlinear dynamical models, whereas conjugate computations and stochastic mirror-descent are applied, respectively. Remarkably, the reparameterization trick is used to reduce the variance of stochastic gradients of the non-conjugate parts. The effectiveness of CVIAKF is validated through synthetic and real-world datasets of maneuvering target tracking.
ChatRadio-Valuer: A Chat Large Language Model for Generalizable Radiology Report Generation Based on Multi-institution and Multi-system Data
Oct 10, 2023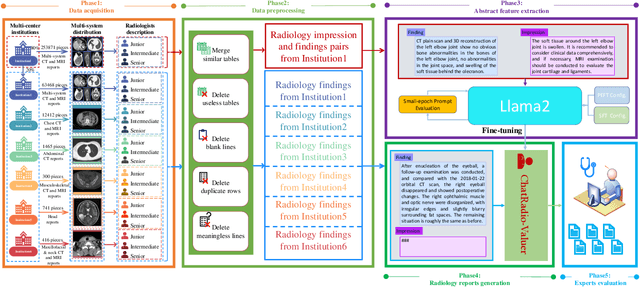
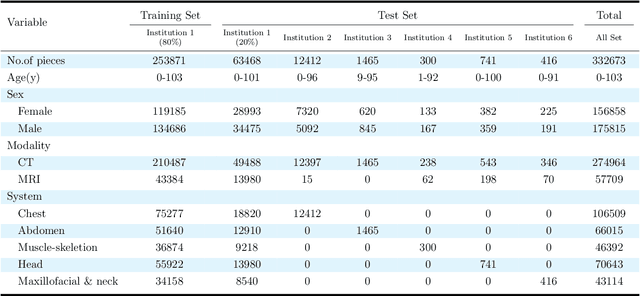
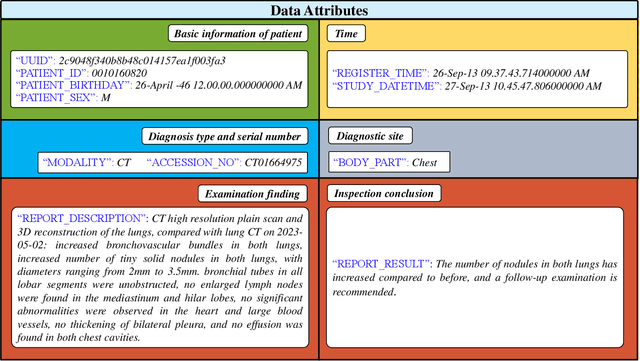
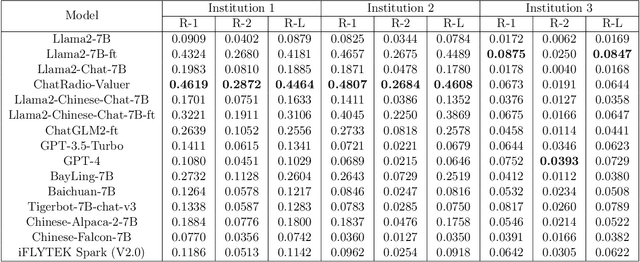
Radiology report generation, as a key step in medical image analysis, is critical to the quantitative analysis of clinically informed decision-making levels. However, complex and diverse radiology reports with cross-source heterogeneity pose a huge generalizability challenge to the current methods under massive data volume, mainly because the style and normativity of radiology reports are obviously distinctive among institutions, body regions inspected and radiologists. Recently, the advent of large language models (LLM) offers great potential for recognizing signs of health conditions. To resolve the above problem, we collaborate with the Second Xiangya Hospital in China and propose ChatRadio-Valuer based on the LLM, a tailored model for automatic radiology report generation that learns generalizable representations and provides a basis pattern for model adaptation in sophisticated analysts' cases. Specifically, ChatRadio-Valuer is trained based on the radiology reports from a single institution by means of supervised fine-tuning, and then adapted to disease diagnosis tasks for human multi-system evaluation (i.e., chest, abdomen, muscle-skeleton, head, and maxillofacial $\&$ neck) from six different institutions in clinical-level events. The clinical dataset utilized in this study encompasses a remarkable total of \textbf{332,673} observations. From the comprehensive results on engineering indicators, clinical efficacy and deployment cost metrics, it can be shown that ChatRadio-Valuer consistently outperforms state-of-the-art models, especially ChatGPT (GPT-3.5-Turbo) and GPT-4 et al., in terms of the diseases diagnosis from radiology reports. ChatRadio-Valuer provides an effective avenue to boost model generalization performance and alleviate the annotation workload of experts to enable the promotion of clinical AI applications in radiology reports.
Evaluating Large Language Models for Radiology Natural Language Processing
Jul 27, 2023
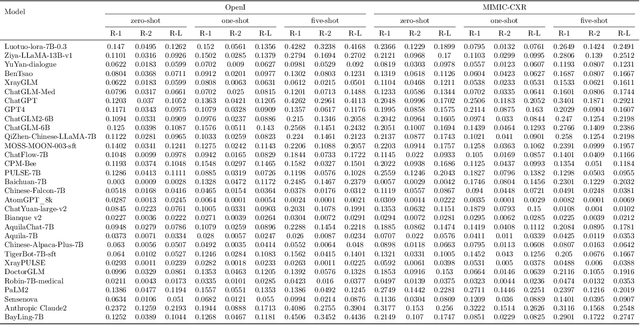
The rise of large language models (LLMs) has marked a pivotal shift in the field of natural language processing (NLP). LLMs have revolutionized a multitude of domains, and they have made a significant impact in the medical field. Large language models are now more abundant than ever, and many of these models exhibit bilingual capabilities, proficient in both English and Chinese. However, a comprehensive evaluation of these models remains to be conducted. This lack of assessment is especially apparent within the context of radiology NLP. This study seeks to bridge this gap by critically evaluating thirty two LLMs in interpreting radiology reports, a crucial component of radiology NLP. Specifically, the ability to derive impressions from radiologic findings is assessed. The outcomes of this evaluation provide key insights into the performance, strengths, and weaknesses of these LLMs, informing their practical applications within the medical domain.
Video Compression with Arbitrary Rescaling Network
Jun 07, 2023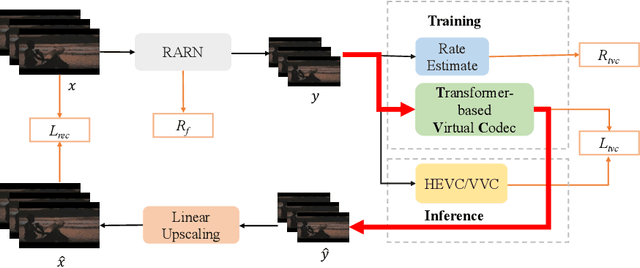
Most video platforms provide video streaming services with different qualities, and the quality of the services is usually adjusted by the resolution of the videos. So high-resolution videos need to be downsampled for compression. In order to solve the problem of video coding at different resolutions, we propose a rate-guided arbitrary rescaling network (RARN) for video resizing before encoding. To help the RARN be compatible with standard codecs and generate compression-friendly results, an iteratively optimized transformer-based virtual codec (TVC) is introduced to simulate the key components of video encoding and perform bitrate estimation. By iteratively training the TVC and the RARN, we achieved 5%-29% BD-Rate reduction anchored by linear interpolation under different encoding configurations and resolutions, exceeding the previous methods on most test videos. Furthermore, the lightweight RARN structure can process FHD (1080p) content at real-time speed (91 FPS) and obtain a considerable rate reduction.