 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhao Zhang
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024
This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Self-Improvement Programming for Temporal Knowledge Graph Question Answering
Apr 02, 2024Temporal Knowledge Graph Question Answering (TKGQA) aims to answer questions with temporal intent over Temporal Knowledge Graphs (TKGs). The core challenge of this task lies in understanding the complex semantic information regarding multiple types of time constraints (e.g., before, first) in questions. Existing end-to-end methods implicitly model the time constraints by learning time-aware embeddings of questions and candidate answers, which is far from understanding the question comprehensively. Motivated by semantic-parsing-based approaches that explicitly model constraints in questions by generating logical forms with symbolic operators, we design fundamental temporal operators for time constraints and introduce a novel self-improvement Programming method for TKGQA (Prog-TQA). Specifically, Prog-TQA leverages the in-context learning ability of Large Language Models (LLMs) to understand the combinatory time constraints in the questions and generate corresponding program drafts with a few examples given. Then, it aligns these drafts to TKGs with the linking module and subsequently executes them to generate the answers. To enhance the ability to understand questions, Prog-TQA is further equipped with a self-improvement strategy to effectively bootstrap LLMs using high-quality self-generated drafts. Extensive experiments demonstrate the superiority of the proposed Prog-TQA on MultiTQ and CronQuestions datasets, especially in the Hits@1 metric.
GT-Rain Single Image Deraining Challenge Report
Mar 18, 2024
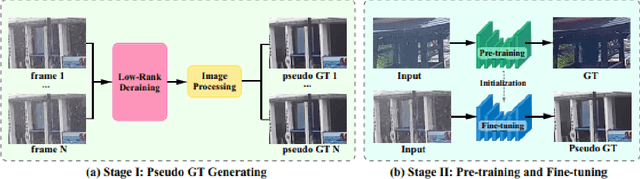
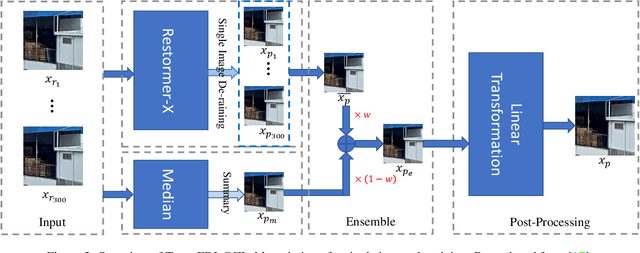
This report reviews the results of the GT-Rain challenge on single image deraining at the UG2+ workshop at CVPR 2023. The aim of this competition is to study the rainy weather phenomenon in real world scenarios, provide a novel real world rainy image dataset, and to spark innovative ideas that will further the development of single image deraining methods on real images. Submissions were trained on the GT-Rain dataset and evaluated on an extension of the dataset consisting of 15 additional scenes. Scenes in GT-Rain are comprised of real rainy image and ground truth image captured moments after the rain had stopped. 275 participants were registered in the challenge and 55 competed in the final testing phase.
The First Place Solution of WSDM Cup 2024: Leveraging Large Language Models for Conversational Multi-Doc QA
Feb 28, 2024Conversational multi-doc question answering aims to answer specific questions based on the retrieved documents as well as the contextual conversations. In this paper, we introduce our winning approach for the "Conversational Multi-Doc QA" challenge in WSDM Cup 2024, which exploits the superior natural language understanding and generation capability of Large Language Models (LLMs). We first adapt LLMs to the task, then devise a hybrid training strategy to make the most of in-domain unlabeled data. Moreover, an advanced text embedding model is adopted to filter out potentially irrelevant documents and several approaches are designed and compared for the model ensemble. Equipped with all these techniques, our solution finally ranked 1st place in WSDM Cup 2024, surpassing its rivals to a large extent. The source codes have been released at https://github.com/zhangzhao219/WSDM-Cup-2024.
Diving Deep into Regions: Exploiting Regional Information Transformer for Single Image Deraining
Feb 25, 2024Transformer-based Single Image Deraining (SID) methods have achieved remarkable success, primarily attributed to their robust capability in capturing long-range interactions. However, we've noticed that current methods handle rain-affected and unaffected regions concurrently, overlooking the disparities between these areas, resulting in confusion between rain streaks and background parts, and inabilities to obtain effective interactions, ultimately resulting in suboptimal deraining outcomes. To address the above issue, we introduce the Region Transformer (Regformer), a novel SID method that underlines the importance of independently processing rain-affected and unaffected regions while considering their combined impact for high-quality image reconstruction. The crux of our method is the innovative Region Transformer Block (RTB), which integrates a Region Masked Attention (RMA) mechanism and a Mixed Gate Forward Block (MGFB). Our RTB is used for attention selection of rain-affected and unaffected regions and local modeling of mixed scales. The RMA generates attention maps tailored to these two regions and their interactions, enabling our model to capture comprehensive features essential for rain removal. To better recover high-frequency textures and capture more local details, we develop the MGFB as a compensation module to complete local mixed scale modeling. Extensive experiments demonstrate that our model reaches state-of-the-art performance, significantly improving the image deraining quality. Our code and trained models are publicly available.
Audio-Infused Automatic Image Colorization by Exploiting Audio Scene Semantics
Jan 24, 2024Automatic image colorization is inherently an ill-posed problem with uncertainty, which requires an accurate semantic understanding of scenes to estimate reasonable colors for grayscale images. Although recent interaction-based methods have achieved impressive performance, it is still a very difficult task to infer realistic and accurate colors for automatic colorization. To reduce the difficulty of semantic understanding of grayscale scenes, this paper tries to utilize corresponding audio, which naturally contains extra semantic information about the same scene. Specifically, a novel audio-infused automatic image colorization (AIAIC) network is proposed, which consists of three stages. First, we take color image semantics as a bridge and pretrain a colorization network guided by color image semantics. Second, the natural co-occurrence of audio and video is utilized to learn the color semantic correlations between audio and visual scenes. Third, the implicit audio semantic representation is fed into the pretrained network to finally realize the audio-guided colorization. The whole process is trained in a self-supervised manner without human annotation. In addition, an audiovisual colorization dataset is established for training and testing. Experiments demonstrate that audio guidance can effectively improve the performance of automatic colorization, especially for some scenes that are difficult to understand only from visual modality.
Quantification of cardiac capillarization in single-immunostained myocardial slices using weakly supervised instance segmentation
Nov 30, 2023Decreased myocardial capillary density has been reported as an important histopathological feature associated with various heart disorders. Quantitative assessment of cardiac capillarization typically involves double immunostaining of cardiomyocytes (CMs) and capillaries in myocardial slices. In contrast, single immunostaining of basement membrane components is a straightforward approach to simultaneously label CMs and capillaries, presenting fewer challenges in background staining. However, subsequent image analysis always requires manual work in identifying and segmenting CMs and capillaries. Here, we developed an image analysis tool, AutoQC, to automatically identify and segment CMs and capillaries in immunofluorescence images of collagen type IV, a predominant basement membrane protein within the myocardium. In addition, commonly used capillarization-related measurements can be derived from segmentation masks. AutoQC features a weakly supervised instance segmentation algorithm by leveraging the power of a pre-trained segmentation model via prompt engineering. AutoQC outperformed YOLOv8-Seg, a state-of-the-art instance segmentation model, in both instance segmentation and capillarization assessment. Furthermore, the training of AutoQC required only a small dataset with bounding box annotations instead of pixel-wise annotations, leading to a reduced workload during network training. AutoQC provides an automated solution for quantifying cardiac capillarization in basement-membrane-immunostained myocardial slices, eliminating the need for manual image analysis once it is trained.
All in One: RGB, RGB-D, and RGB-T Salient Object Detection
Nov 23, 2023Salient object detection (SOD) aims to identify the most attractive objects within an image. Depending on the type of data being detected, SOD can be categorized into various forms, including RGB, RGB-D (Depth), RGB-T (Thermal) and light field SOD. Previous researches have focused on saliency detection with individual data type. If the RGB-D SOD model is forced to detect RGB-T data it will perform poorly. We propose an innovative model framework that provides a unified solution for the salient object detection task of three types of data (RGB, RGB-D, and RGB-T). The three types of data can be handled in one model (all in one) with the same weight parameters. In this framework, the three types of data are concatenated in an ordered manner within a single input batch, and features are extracted using a transformer network. Based on this framework, we propose an efficient lightweight SOD model, namely AiOSOD, which can detect any RGB, RGB-D, and RGB-T data with high speed (780FPS for RGB data, 485FPS for RGB-D or RGB-T data). Notably, with only 6.25M parameters, AiOSOD achieves excellent performance on RGB, RGB-D, and RGB-T datasets.
Cut-and-Paste: Subject-Driven Video Editing with Attention Control
Nov 20, 2023
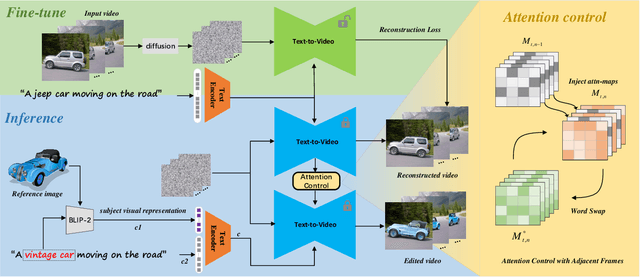


This paper presents a novel framework termed Cut-and-Paste for real-word semantic video editing under the guidance of text prompt and additional reference image. While the text-driven video editing has demonstrated remarkable ability to generate highly diverse videos following given text prompts, the fine-grained semantic edits are hard to control by plain textual prompt only in terms of object details and edited region, and cumbersome long text descriptions are usually needed for the task. We therefore investigate subject-driven video editing for more precise control of both edited regions and background preservation, and fine-grained semantic generation. We achieve this goal by introducing an reference image as supplementary input to the text-driven video editing, which avoids racking your brain to come up with a cumbersome text prompt describing the detailed appearance of the object. To limit the editing area, we refer to a method of cross attention control in image editing and successfully extend it to video editing by fusing the attention map of adjacent frames, which strikes a balance between maintaining video background and spatio-temporal consistency. Compared with current methods, the whole process of our method is like ``cut" the source object to be edited and then ``paste" the target object provided by reference image. We demonstrate that our method performs favorably over prior arts for video editing under the guidance of text prompt and extra reference image, as measured by both quantitative and subjective evaluations.