 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZixuan Li
Self-Improvement Programming for Temporal Knowledge Graph Question Answering
Apr 02, 2024
Temporal Knowledge Graph Question Answering (TKGQA) aims to answer questions with temporal intent over Temporal Knowledge Graphs (TKGs). The core challenge of this task lies in understanding the complex semantic information regarding multiple types of time constraints (e.g., before, first) in questions. Existing end-to-end methods implicitly model the time constraints by learning time-aware embeddings of questions and candidate answers, which is far from understanding the question comprehensively. Motivated by semantic-parsing-based approaches that explicitly model constraints in questions by generating logical forms with symbolic operators, we design fundamental temporal operators for time constraints and introduce a novel self-improvement Programming method for TKGQA (Prog-TQA). Specifically, Prog-TQA leverages the in-context learning ability of Large Language Models (LLMs) to understand the combinatory time constraints in the questions and generate corresponding program drafts with a few examples given. Then, it aligns these drafts to TKGs with the linking module and subsequently executes them to generate the answers. To enhance the ability to understand questions, Prog-TQA is further equipped with a self-improvement strategy to effectively bootstrap LLMs using high-quality self-generated drafts. Extensive experiments demonstrate the superiority of the proposed Prog-TQA on MultiTQ and CronQuestions datasets, especially in the Hits@1 metric.
Selective Temporal Knowledge Graph Reasoning
Apr 02, 2024Temporal Knowledge Graph (TKG), which characterizes temporally evolving facts in the form of (subject, relation, object, timestamp), has attracted much attention recently. TKG reasoning aims to predict future facts based on given historical ones. However, existing TKG reasoning models are unable to abstain from predictions they are uncertain, which will inevitably bring risks in real-world applications. Thus, in this paper, we propose an abstention mechanism for TKG reasoning, which helps the existing models make selective, instead of indiscriminate, predictions. Specifically, we develop a confidence estimator, called Confidence Estimator with History (CEHis), to enable the existing TKG reasoning models to first estimate their confidence in making predictions, and then abstain from those with low confidence. To do so, CEHis takes two kinds of information into consideration, namely, the certainty of the current prediction and the accuracy of historical predictions. Experiments with representative TKG reasoning models on two benchmark datasets demonstrate the effectiveness of the proposed CEHis.
KnowCoder: Coding Structured Knowledge into LLMs for Universal Information Extraction
Mar 14, 2024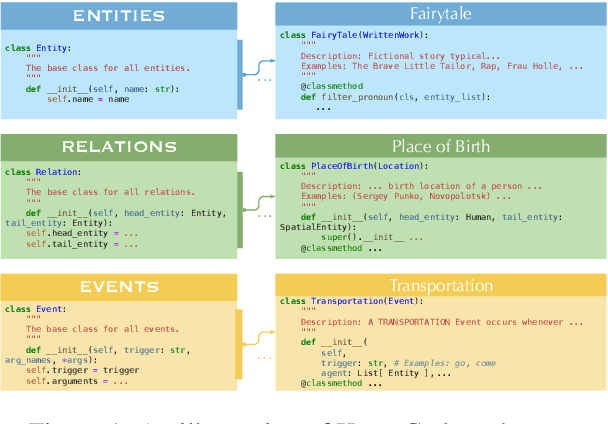
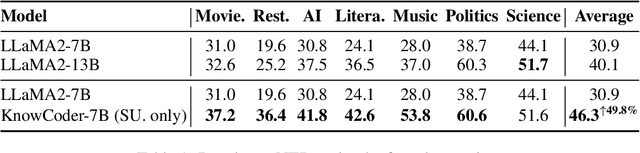
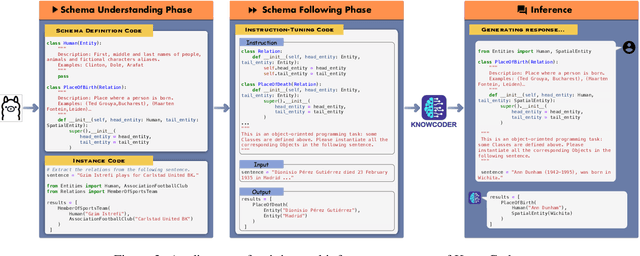
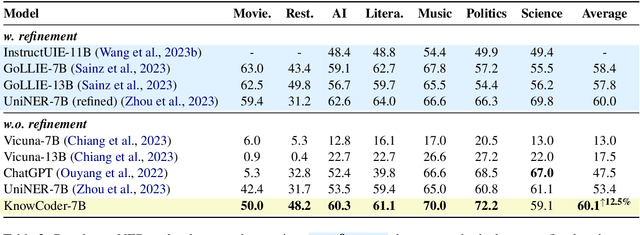
In this paper, we propose KnowCoder, a Large Language Model (LLM) to conduct Universal Information Extraction (UIE) via code generation. KnowCoder aims to develop a kind of unified schema representation that LLMs can easily understand and an effective learning framework that encourages LLMs to follow schemas and extract structured knowledge accurately. To achieve these, KnowCoder introduces a code-style schema representation method to uniformly transform different schemas into Python classes, with which complex schema information, such as constraints among tasks in UIE, can be captured in an LLM-friendly manner. We further construct a code-style schema library covering over $\textbf{30,000}$ types of knowledge, which is the largest one for UIE, to the best of our knowledge. To ease the learning process of LLMs, KnowCoder contains a two-phase learning framework that enhances its schema understanding ability via code pretraining and its schema following ability via instruction tuning. After code pretraining on around $1.5$B automatically constructed data, KnowCoder already attains remarkable generalization ability and achieves relative improvements by $\textbf{49.8%}$ F1, compared to LLaMA2, under the few-shot setting. After instruction tuning, KnowCoder further exhibits strong generalization ability on unseen schemas and achieves up to $\textbf{12.5%}$ and $\textbf{21.9%}$, compared to sota baselines, under the zero-shot setting and the low resource setting, respectively. Additionally, based on our unified schema representations, various human-annotated datasets can simultaneously be utilized to refine KnowCoder, which achieves significant improvements up to $\textbf{7.5%}$ under the supervised setting.
Contrastive Pre-training for Deep Session Data Understanding
Mar 05, 2024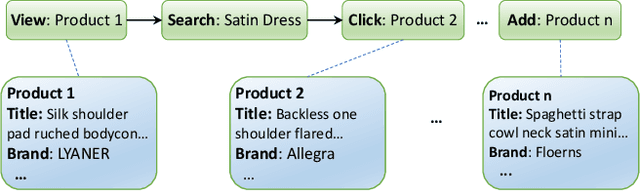
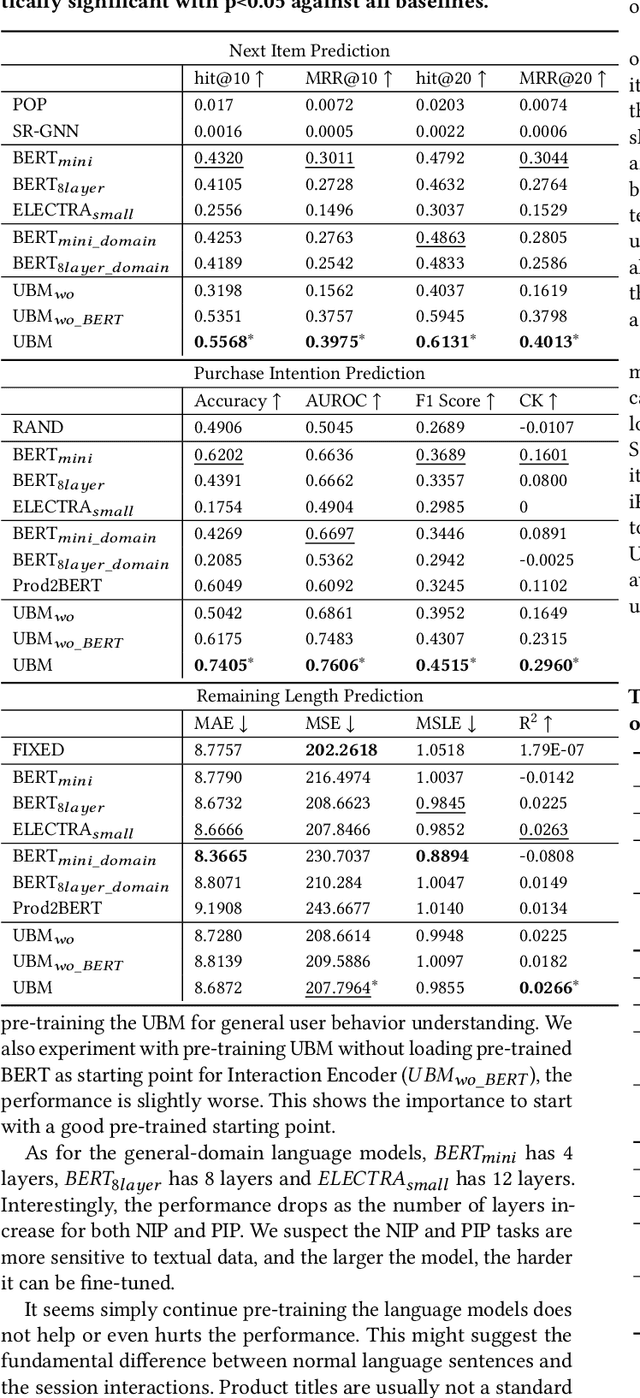
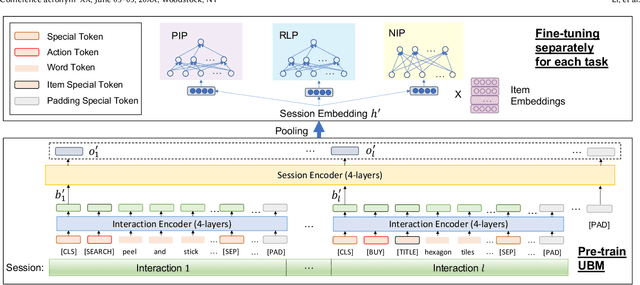
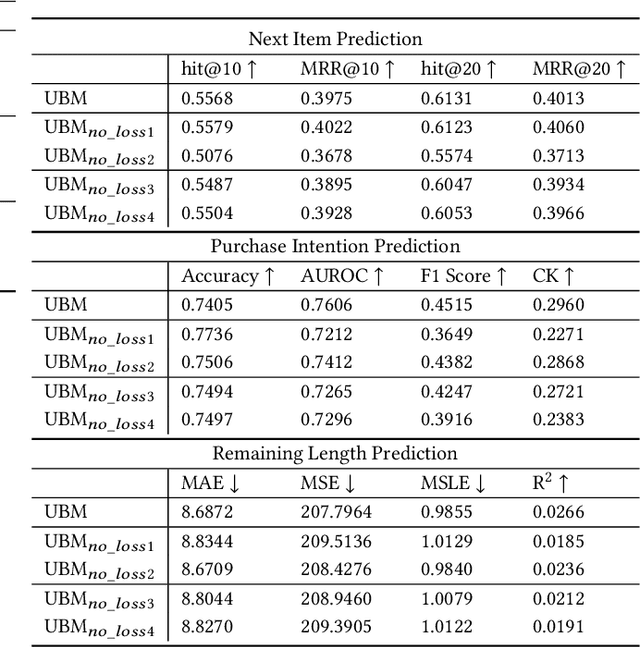
Session data has been widely used for understanding user's behavior in e-commerce. Researchers are trying to leverage session data for different tasks, such as purchase intention prediction, remaining length prediction, recommendation, etc., as it provides context clues about the user's dynamic interests. However, online shopping session data is semi-structured and complex in nature, which contains both unstructured textual data about the products, search queries, and structured user action sequences. Most existing works focus on leveraging the coarse-grained item sequences for specific tasks, while largely ignore the fine-grained information from text and user action details. In this work, we delve into deep session data understanding via scrutinizing the various clues inside the rich information in user sessions. Specifically, we propose to pre-train a general-purpose User Behavior Model (UBM) over large-scale session data with rich details, such as product title, attributes and various kinds of user actions. A two-stage pre-training scheme is introduced to encourage the model to self-learn from various augmentations with contrastive learning objectives, which spans different granularity levels of session data. Then the well-trained session understanding model can be easily fine-tuned for various downstream tasks. Extensive experiments show that UBM better captures the complex intra-item semantic relations, inter-item connections and inter-interaction dependencies, leading to large performance gains as compared to the baselines on several downstream tasks. And it also demonstrates strong robustness when data is sparse.
Learning to Ask Critical Questions for Assisting Product Search
Mar 05, 2024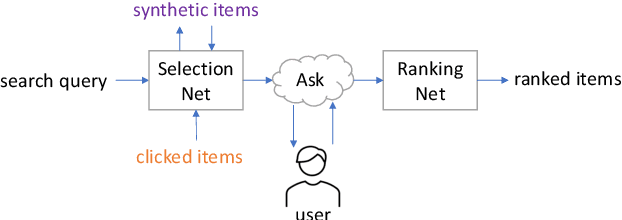
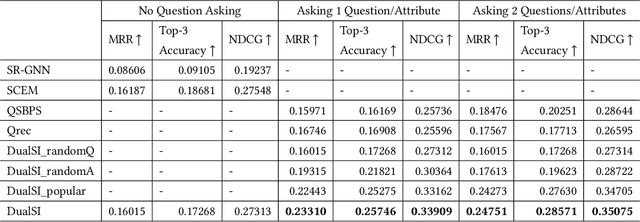

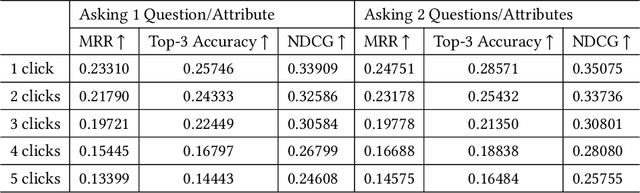
Product search plays an essential role in eCommerce. It was treated as a special type of information retrieval problem. Most existing works make use of historical data to improve the search performance, which do not take the opportunity to ask for user's current interest directly. Some session-aware methods take the user's clicks within the session as implicit feedback, but it is still just a guess on user's preference. To address this problem, recent conversational or question-based search models interact with users directly for understanding the user's interest explicitly. However, most users do not have a clear picture on what to buy at the initial stage. Asking critical attributes that the user is looking for after they explored for a while should be a more efficient way to help them searching for the target items. In this paper, we propose a dual-learning model that hybrids the best from both implicit session feedback and proactively clarifying with users on the most critical questions. We first establish a novel utility score to measure whether a clicked item provides useful information for finding the target. Then we develop the dual Selection Net and Ranking Net for choosing the critical questions and ranking the items. It innovatively links traditional click-stream data and text-based questions together. To verify our proposal, we did extensive experiments on a public dataset, and our model largely outperformed other state-of-the-art methods.
Unlocking the Power of Large Language Models for Entity Alignment
Feb 23, 2024Entity Alignment (EA) is vital for integrating diverse knowledge graph (KG) data, playing a crucial role in data-driven AI applications. Traditional EA methods primarily rely on comparing entity embeddings, but their effectiveness is constrained by the limited input KG data and the capabilities of the representation learning techniques. Against this backdrop, we introduce ChatEA, an innovative framework that incorporates large language models (LLMs) to improve EA. To address the constraints of limited input KG data, ChatEA introduces a KG-code translation module that translates KG structures into a format understandable by LLMs, thereby allowing LLMs to utilize their extensive background knowledge to improve EA accuracy. To overcome the over-reliance on entity embedding comparisons, ChatEA implements a two-stage EA strategy that capitalizes on LLMs' capability for multi-step reasoning in a dialogue format, thereby enhancing accuracy while preserving efficiency. Our experimental results affirm ChatEA's superior performance, highlighting LLMs' potential in facilitating EA tasks.
Retrieval-Augmented Code Generation for Universal Information Extraction
Nov 06, 2023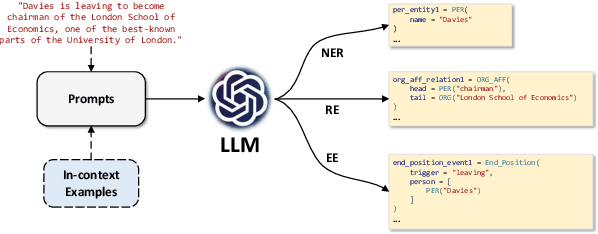
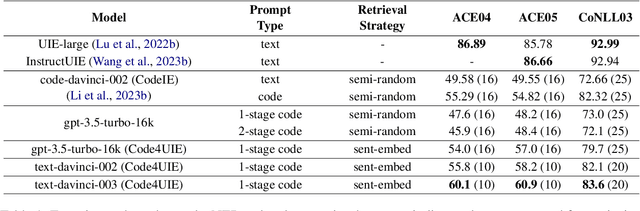

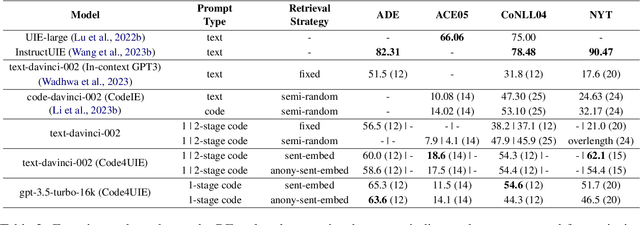
Information Extraction (IE) aims to extract structural knowledge (e.g., entities, relations, events) from natural language texts, which brings challenges to existing methods due to task-specific schemas and complex text expressions. Code, as a typical kind of formalized language, is capable of describing structural knowledge under various schemas in a universal way. On the other hand, Large Language Models (LLMs) trained on both codes and texts have demonstrated powerful capabilities of transforming texts into codes, which provides a feasible solution to IE tasks. Therefore, in this paper, we propose a universal retrieval-augmented code generation framework based on LLMs, called Code4UIE, for IE tasks. Specifically, Code4UIE adopts Python classes to define task-specific schemas of various structural knowledge in a universal way. By so doing, extracting knowledge under these schemas can be transformed into generating codes that instantiate the predefined Python classes with the information in texts. To generate these codes more precisely, Code4UIE adopts the in-context learning mechanism to instruct LLMs with examples. In order to obtain appropriate examples for different tasks, Code4UIE explores several example retrieval strategies, which can retrieve examples semantically similar to the given texts. Extensive experiments on five representative IE tasks across nine datasets demonstrate the effectiveness of the Code4UIE framework.
An In-Context Schema Understanding Method for Knowledge Base Question Answering
Oct 22, 2023
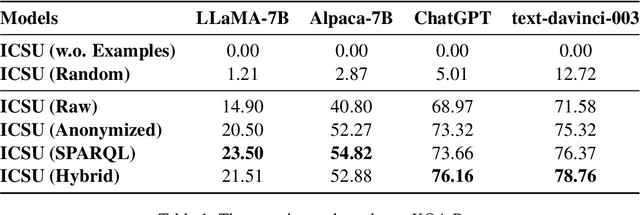
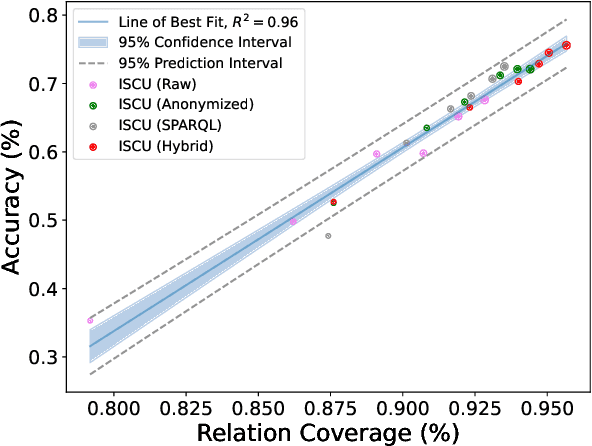
The Knowledge Base Question Answering (KBQA) task aims to answer natural language questions based on a given knowledge base. As a kind of common method for this task, semantic parsing-based ones first convert natural language questions to logical forms (e.g., SPARQL queries) and then execute them on knowledge bases to get answers. Recently, Large Language Models (LLMs) have shown strong abilities in language understanding and may be adopted as semantic parsers in such kinds of methods. However, in doing so, a great challenge for LLMs is to understand the schema of knowledge bases. Therefore, in this paper, we propose an In-Context Schema Understanding (ICSU) method for facilitating LLMs to be used as a semantic parser in KBQA. Specifically, ICSU adopts the In-context Learning mechanism to instruct LLMs to generate SPARQL queries with examples. In order to retrieve appropriate examples from annotated question-query pairs, which contain comprehensive schema information related to questions, ICSU explores four different retrieval strategies. Experimental results on the largest KBQA benchmark, KQA Pro, show that ICSU with all these strategies outperforms that with a random retrieval strategy significantly (from 12\% to 78.76\% in accuracy).
DQ-LoRe: Dual Queries with Low Rank Approximation Re-ranking for In-Context Learning
Oct 19, 2023



Recent advances in natural language processing, primarily propelled by Large Language Models (LLMs), have showcased their remarkable capabilities grounded in in-context learning. A promising avenue for guiding LLMs in intricate reasoning tasks involves the utilization of intermediate reasoning steps within the Chain-of-Thought (CoT) paradigm. Nevertheless, the central challenge lies in the effective selection of exemplars for facilitating in-context learning. In this study, we introduce a framework that leverages Dual Queries and Low-rank approximation Re-ranking (DQ-LoRe) to automatically select exemplars for in-context learning. Dual Queries first query LLM to obtain LLM-generated knowledge such as CoT, then query the retriever to obtain the final exemplars via both question and the knowledge. Moreover, for the second query, LoRe employs dimensionality reduction techniques to refine exemplar selection, ensuring close alignment with the input question's knowledge. Through extensive experiments, we demonstrate that DQ-LoRe significantly outperforms prior state-of-the-art methods in the automatic selection of exemplars for GPT-4, enhancing performance from 92.5% to 94.2%. Our comprehensive analysis further reveals that DQ-LoRe consistently outperforms retrieval-based approaches in terms of both performance and adaptability, especially in scenarios characterized by distribution shifts. DQ-LoRe pushes the boundaries of in-context learning and opens up new avenues for addressing complex reasoning challenges. We will release the code soon.