 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuxin Zuo
KnowCoder: Coding Structured Knowledge into LLMs for Universal Information Extraction
Mar 14, 2024
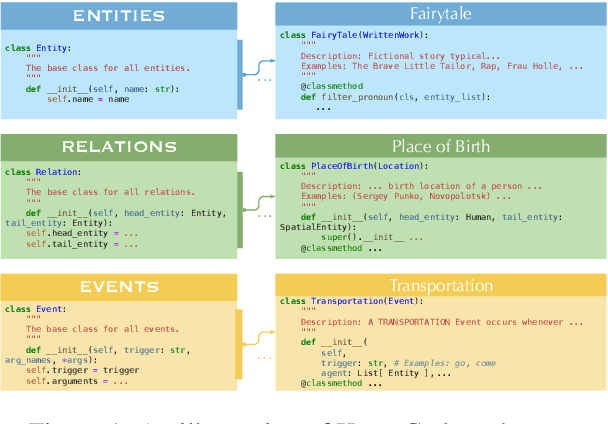
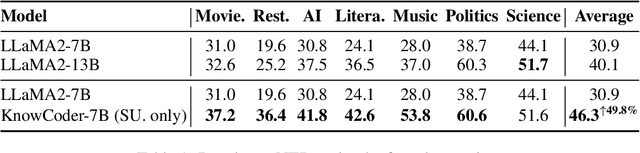
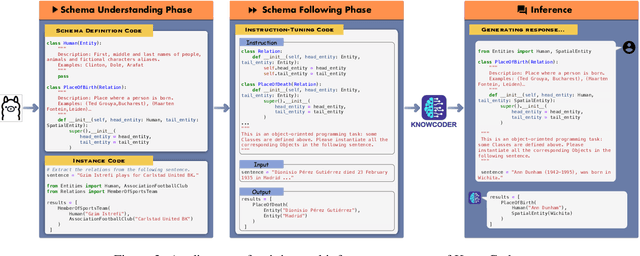
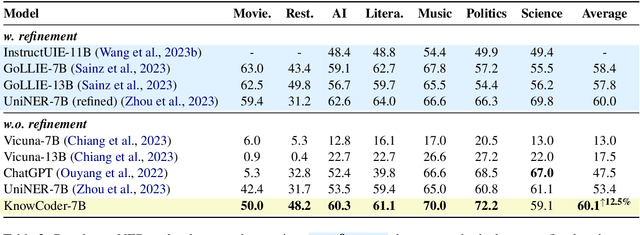
In this paper, we propose KnowCoder, a Large Language Model (LLM) to conduct Universal Information Extraction (UIE) via code generation. KnowCoder aims to develop a kind of unified schema representation that LLMs can easily understand and an effective learning framework that encourages LLMs to follow schemas and extract structured knowledge accurately. To achieve these, KnowCoder introduces a code-style schema representation method to uniformly transform different schemas into Python classes, with which complex schema information, such as constraints among tasks in UIE, can be captured in an LLM-friendly manner. We further construct a code-style schema library covering over $\textbf{30,000}$ types of knowledge, which is the largest one for UIE, to the best of our knowledge. To ease the learning process of LLMs, KnowCoder contains a two-phase learning framework that enhances its schema understanding ability via code pretraining and its schema following ability via instruction tuning. After code pretraining on around $1.5$B automatically constructed data, KnowCoder already attains remarkable generalization ability and achieves relative improvements by $\textbf{49.8%}$ F1, compared to LLaMA2, under the few-shot setting. After instruction tuning, KnowCoder further exhibits strong generalization ability on unseen schemas and achieves up to $\textbf{12.5%}$ and $\textbf{21.9%}$, compared to sota baselines, under the zero-shot setting and the low resource setting, respectively. Additionally, based on our unified schema representations, various human-annotated datasets can simultaneously be utilized to refine KnowCoder, which achieves significant improvements up to $\textbf{7.5%}$ under the supervised setting.
DSCom: A Data-Driven Self-Adaptive Community-Based Framework for Influence Maximization in Social Networks
Nov 18, 2023Influence maximization aims to find a subset of seeds that maximize the influence spread under a given budget. In this paper, we mainly address the data-driven version of this problem, where the diffusion model is not given but needs to be inferred from the history cascades. Several previous works have addressed this topic in a statistical way and provided efficient algorithms with theoretical guarantee. However, in their settings, though the diffusion parameters are inferred, they still need users to preset the diffusion model, which can be an intractable problem in real-world practices. In this paper, we reformulate the problem on the attributed network and leverage the node attributes to estimate the closeness between the connected nodes. Specifically, we propose a machine learning-based framework, named DSCom, to address this problem in a heuristic way. Under this framework, we first infer the users' relationship from the diffusion dataset through attention mechanism and then leverage spectral clustering to overcome the influence overlap problem in the lack of exact diffusion formula. Compared to the previous theoretical works, we carefully designed empirical experiments with parameterized diffusion models based on real-world social networks, which prove the efficiency and effectiveness of our algorithm.
Incorporating Probing Signals into Multimodal Machine Translation via Visual Question-Answering Pairs
Oct 26, 2023This paper presents an in-depth study of multimodal machine translation (MMT), examining the prevailing understanding that MMT systems exhibit decreased sensitivity to visual information when text inputs are complete. Instead, we attribute this phenomenon to insufficient cross-modal interaction, rather than image information redundancy. A novel approach is proposed to generate parallel Visual Question-Answering (VQA) style pairs from the source text, fostering more robust cross-modal interaction. Using Large Language Models (LLMs), we explicitly model the probing signal in MMT to convert it into VQA-style data to create the Multi30K-VQA dataset. An MMT-VQA multitask learning framework is introduced to incorporate explicit probing signals from the dataset into the MMT training process. Experimental results on two widely-used benchmarks demonstrate the effectiveness of this novel approach. Our code and data would be available at: \url{https://github.com/libeineu/MMT-VQA}.