 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhijiang Guo
Learning From Correctness Without Prompting Makes LLM Efficient Reasoner
Mar 28, 2024
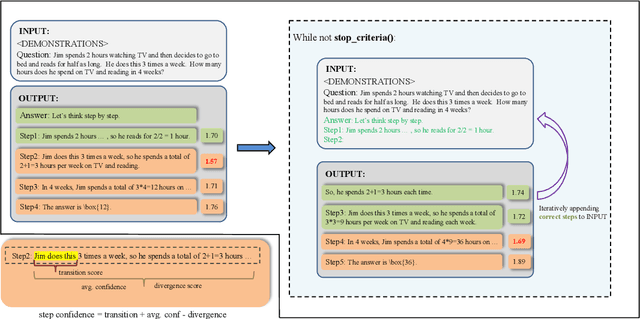
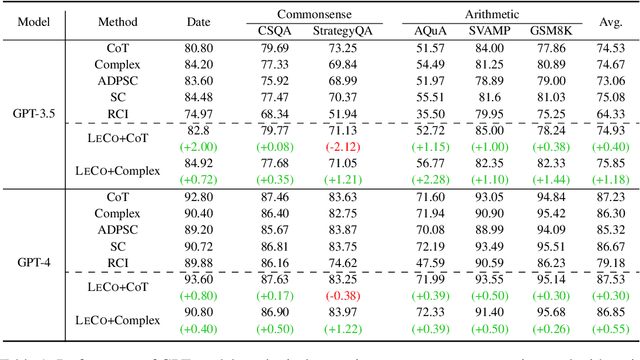
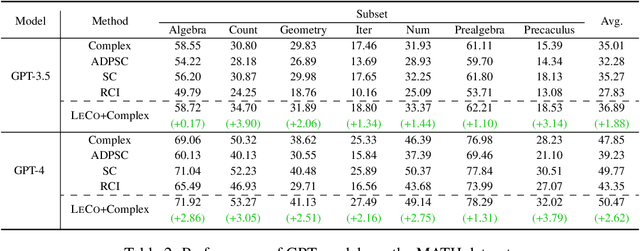
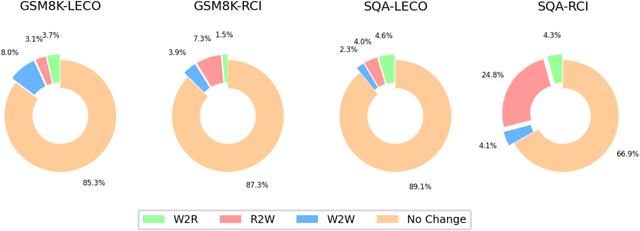
Large language models (LLMs) have demonstrated outstanding performance across various tasks, yet they still exhibit limitations such as hallucination, unfaithful reasoning, and toxic content. One potential approach to mitigate these issues is learning from human or external feedback (e.g. tools). In this paper, we introduce an intrinsic self-correct reasoning framework for LLMs that eliminates the need for human feedback, external tools, and handcraft prompts. The proposed framework, based on a multi-step reasoning paradigm \textbf{Le}arning from \textbf{Co}rrectness (\textsc{LeCo}), improves reasoning performance without needing to learn from errors. This paradigm prioritizes learning from correct reasoning steps, and a unique method to measure confidence for each reasoning step based on generation logits. Experimental results across various multi-step reasoning tasks demonstrate the effectiveness of the framework in improving reasoning performance with reduced token consumption.
Aligning with Human Judgement: The Role of Pairwise Preference in Large Language Model Evaluators
Mar 26, 2024Large Language Models (LLMs) have demonstrated promising capabilities as automatic evaluators in assessing the quality of generated natural language. However, LLMs still exhibit biases in evaluation and often struggle to generate coherent evaluations that align with human assessments. In this work, we first conduct a systematic study of the misalignment between LLM evaluators and human judgement, revealing that existing calibration methods aimed at mitigating biases are insufficient for effectively aligning LLM evaluators. Inspired by the use of preference data in RLHF, we formulate the evaluation as a ranking problem and introduce Pairwise-preference Search (PairS), an uncertainty-guided search method that employs LLMs to conduct pairwise comparisons and efficiently ranks candidate texts. PairS achieves state-of-the-art performance on representative evaluation tasks and demonstrates significant improvements over direct scoring. Furthermore, we provide insights into the role of pairwise preference in quantifying the transitivity of LLMs and demonstrate how PairS benefits from calibration.
YODA: Teacher-Student Progressive Learning for Language Models
Jan 28, 2024Although large language models (LLMs) have demonstrated adeptness in a range of tasks, they still lag behind human learning efficiency. This disparity is often linked to the inherent human capacity to learn from basic examples, gradually generalize and handle more complex problems, and refine their skills with continuous feedback. Inspired by this, this paper introduces YODA, a novel teacher-student progressive learning framework that emulates the teacher-student education process to improve the efficacy of model fine-tuning. The framework operates on an interactive \textit{basic-generalized-harder} loop. The teacher agent provides tailored feedback on the student's answers, and systematically organizes the education process. This process unfolds by teaching the student basic examples, reinforcing understanding through generalized questions, and then enhancing learning by posing questions with progressively enhanced complexity. With the teacher's guidance, the student learns to iteratively refine its answer with feedback, and forms a robust and comprehensive understanding of the posed questions. The systematic procedural data, which reflects the progressive learning process of humans, is then utilized for model training. Taking math reasoning as a testbed, experiments show that training LLaMA2 with data from YODA improves SFT with significant performance gain (+17.01\% on GSM8K and +9.98\% on MATH). In addition, we find that training with curriculum learning further improves learning robustness.
Do We Need Language-Specific Fact-Checking Models? The Case of Chinese
Jan 27, 2024This paper investigates the potential benefits of language-specific fact-checking models, focusing on the case of Chinese. We demonstrate the limitations of methods such as translating Chinese claims and evidence into English or directly using multilingual large language models (e.g. GPT4), highlighting the need for language-specific systems. We further develop a state-of-the-art Chinese fact-checking system that, in contrast to previous approaches which treat evidence selection as a pairwise sentence classification task, considers the context of sentences. We also create an adversarial dataset to identify biases in our model, and while they are present as in English language datasets and models, they are often specific to the Chinese culture. Our study emphasizes the importance of language-specific fact-checking models to effectively combat misinformation.
PROXYQA: An Alternative Framework for Evaluating Long-Form Text Generation with Large Language Models
Jan 26, 2024Large Language Models (LLMs) have exhibited remarkable success in long-form context comprehension tasks. However, their capacity to generate long contents, such as reports and articles, remains insufficiently explored. Current benchmarks do not adequately assess LLMs' ability to produce informative and comprehensive content, necessitating a more rigorous evaluation approach. In this study, we introduce \textsc{ProxyQA}, a framework for evaluating long-form text generation, comprising in-depth human-curated \textit{meta-questions} spanning various domains. Each meta-question contains corresponding \textit{proxy-questions} with annotated answers. LLMs are prompted to generate extensive content in response to these meta-questions. Utilizing an evaluator and incorporating generated content as background context, \textsc{ProxyQA} evaluates the quality of generated content based on the evaluator's performance in answering the \textit{proxy-questions}. We examine multiple LLMs, emphasizing \textsc{ProxyQA}'s demanding nature as a high-quality assessment tool. Human evaluation demonstrates that evaluating through \textit{proxy-questions} is a highly self-consistent and human-criteria-correlated validation method. The dataset and leaderboard will be available at \url{https://github.com/Namco0816/ProxyQA}.
Are LLMs Rigorous Logical Reasoner? Empowering Natural Language Proof Generation with Contrastive Stepwise Decoding
Nov 12, 2023Logical reasoning remains a pivotal component within the realm of artificial intelligence. The recent evolution of large language models (LLMs) has marked significant progress in this domain. The adoption of strategies like chain-of-thought (CoT) has enhanced the performance of LLMs across diverse reasoning tasks. Nonetheless, logical reasoning that involves proof planning, specifically those that necessitate the validation of explanation accuracy, continues to present stumbling blocks. In this study, we first evaluate the efficacy of LLMs with advanced CoT strategies concerning such tasks. Our analysis reveals that LLMs still struggle to navigate complex reasoning chains, which demand the meticulous linkage of premises to derive a cogent conclusion. To address this issue, we finetune a smaller-scale language model, equipping it to decompose proof objectives into more manageable subgoals. We also introduce contrastive decoding to stepwise proof generation, making use of negative reasoning paths to strengthen the model's capacity for logical deduction. Experiments on EntailmentBank underscore the success of our method in augmenting the proof planning abilities of language models.
TRIGO: Benchmarking Formal Mathematical Proof Reduction for Generative Language Models
Oct 24, 2023

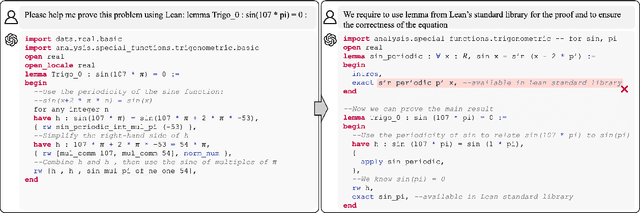
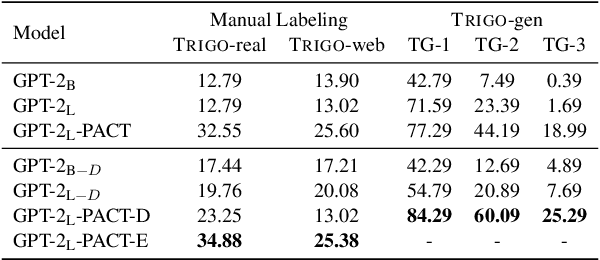
Automated theorem proving (ATP) has become an appealing domain for exploring the reasoning ability of the recent successful generative language models. However, current ATP benchmarks mainly focus on symbolic inference, but rarely involve the understanding of complex number combination reasoning. In this work, we propose TRIGO, an ATP benchmark that not only requires a model to reduce a trigonometric expression with step-by-step proofs but also evaluates a generative LM's reasoning ability on formulas and its capability to manipulate, group, and factor number terms. We gather trigonometric expressions and their reduced forms from the web, annotate the simplification process manually, and translate it into the Lean formal language system. We then automatically generate additional examples from the annotated samples to expand the dataset. Furthermore, we develop an automatic generator based on Lean-Gym to create dataset splits of varying difficulties and distributions in order to thoroughly analyze the model's generalization ability. Our extensive experiments show our proposed TRIGO poses a new challenge for advanced generative LM's including GPT-4 which is pre-trained on a considerable amount of open-source formal theorem-proving language data, and provide a new tool to study the generative LM's ability on both formal and mathematical reasoning.
DQ-LoRe: Dual Queries with Low Rank Approximation Re-ranking for In-Context Learning
Oct 19, 2023



Recent advances in natural language processing, primarily propelled by Large Language Models (LLMs), have showcased their remarkable capabilities grounded in in-context learning. A promising avenue for guiding LLMs in intricate reasoning tasks involves the utilization of intermediate reasoning steps within the Chain-of-Thought (CoT) paradigm. Nevertheless, the central challenge lies in the effective selection of exemplars for facilitating in-context learning. In this study, we introduce a framework that leverages Dual Queries and Low-rank approximation Re-ranking (DQ-LoRe) to automatically select exemplars for in-context learning. Dual Queries first query LLM to obtain LLM-generated knowledge such as CoT, then query the retriever to obtain the final exemplars via both question and the knowledge. Moreover, for the second query, LoRe employs dimensionality reduction techniques to refine exemplar selection, ensuring close alignment with the input question's knowledge. Through extensive experiments, we demonstrate that DQ-LoRe significantly outperforms prior state-of-the-art methods in the automatic selection of exemplars for GPT-4, enhancing performance from 92.5% to 94.2%. Our comprehensive analysis further reveals that DQ-LoRe consistently outperforms retrieval-based approaches in terms of both performance and adaptability, especially in scenarios characterized by distribution shifts. DQ-LoRe pushes the boundaries of in-context learning and opens up new avenues for addressing complex reasoning challenges. We will release the code soon.
Do Large Language Models Know about Facts?
Oct 08, 2023Large language models (LLMs) have recently driven striking performance improvements across a range of natural language processing tasks. The factual knowledge acquired during pretraining and instruction tuning can be useful in various downstream tasks, such as question answering, and language generation. Unlike conventional Knowledge Bases (KBs) that explicitly store factual knowledge, LLMs implicitly store facts in their parameters. Content generated by the LLMs can often exhibit inaccuracies or deviations from the truth, due to facts that can be incorrectly induced or become obsolete over time. To this end, we aim to comprehensively evaluate the extent and scope of factual knowledge within LLMs by designing the benchmark Pinocchio. Pinocchio contains 20K diverse factual questions that span different sources, timelines, domains, regions, and languages. Furthermore, we investigate whether LLMs are able to compose multiple facts, update factual knowledge temporally, reason over multiple pieces of facts, identify subtle factual differences, and resist adversarial examples. Extensive experiments on different sizes and types of LLMs show that existing LLMs still lack factual knowledge and suffer from various spurious correlations. We believe this is a critical bottleneck for realizing trustworthy artificial intelligence. The dataset Pinocchio and our codes will be publicly available.
Give Me More Details: Improving Fact-Checking with Latent Retrieval
May 25, 2023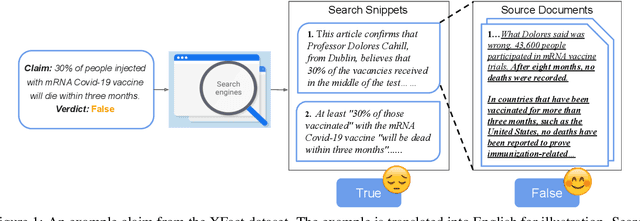
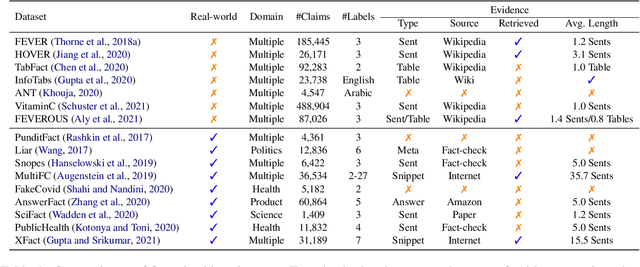
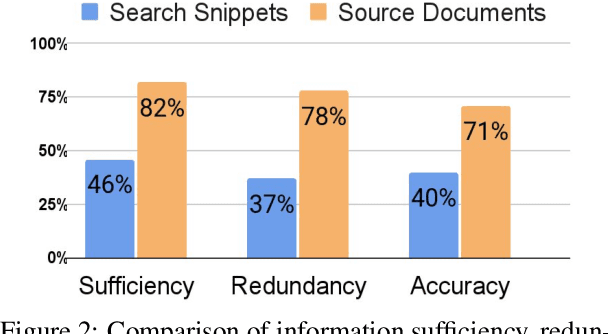
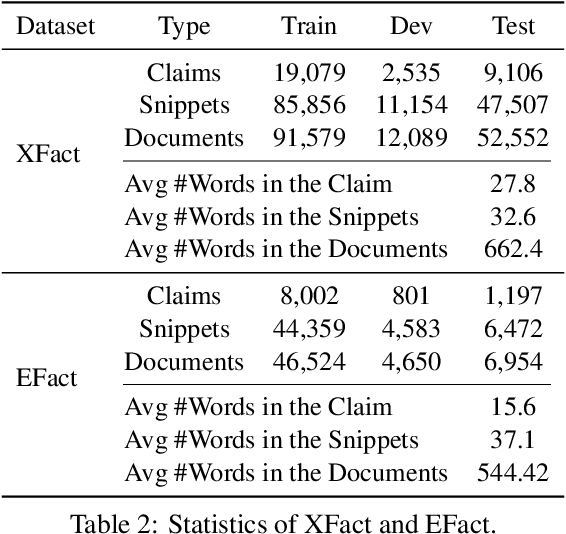
Evidence plays a crucial role in automated fact-checking. When verifying real-world claims, existing fact-checking systems either assume the evidence sentences are given or use the search snippets returned by the search engine. Such methods ignore the challenges of collecting evidence and may not provide sufficient information to verify real-world claims. Aiming at building a better fact-checking system, we propose to incorporate full text from source documents as evidence and introduce two enriched datasets. The first one is a multilingual dataset, while the second one is monolingual (English). We further develop a latent variable model to jointly extract evidence sentences from documents and perform claim verification. Experiments indicate that including source documents can provide sufficient contextual clues even when gold evidence sentences are not annotated. The proposed system is able to achieve significant improvements upon best-reported models under different settings.