 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYing Su
DPER: Diffusion Prior Driven Neural Representation for Limited Angle and Sparse View CT Reconstruction
Apr 27, 2024
Limited-angle and sparse-view computed tomography (LACT and SVCT) are crucial for expanding the scope of X-ray CT applications. However, they face challenges due to incomplete data acquisition, resulting in diverse artifacts in the reconstructed CT images. Emerging implicit neural representation (INR) techniques, such as NeRF, NeAT, and NeRP, have shown promise in under-determined CT imaging reconstruction tasks. However, the unsupervised nature of INR architecture imposes limited constraints on the solution space, particularly for the highly ill-posed reconstruction task posed by LACT and ultra-SVCT. In this study, we introduce the Diffusion Prior Driven Neural Representation (DPER), an advanced unsupervised framework designed to address the exceptionally ill-posed CT reconstruction inverse problems. DPER adopts the Half Quadratic Splitting (HQS) algorithm to decompose the inverse problem into data fidelity and distribution prior sub-problems. The two sub-problems are respectively addressed by INR reconstruction scheme and pre-trained score-based diffusion model. This combination initially preserves the implicit image local consistency prior from INR. Additionally, it effectively augments the feasibility of the solution space for the inverse problem through the generative diffusion model, resulting in increased stability and precision in the solutions. We conduct comprehensive experiments to evaluate the performance of DPER on LACT and ultra-SVCT reconstruction with two public datasets (AAPM and LIDC). The results show that our method outperforms the state-of-the-art reconstruction methods on in-domain datasets, while achieving significant performance improvements on out-of-domain datasets.
Rethinking the Bounds of LLM Reasoning: Are Multi-Agent Discussions the Key?
Feb 28, 2024Recent progress in LLMs discussion suggests that multi-agent discussion improves the reasoning abilities of LLMs. In this work, we reevaluate this claim through systematic experiments, where we propose a novel group discussion framework to enrich the set of discussion mechanisms. Interestingly, our results show that a single-agent LLM with strong prompts can achieve almost the same performance as the best existing discussion approach on a wide range of reasoning tasks and backbone LLMs. We observe that the multi-agent discussion performs better than a single agent only when there is no demonstration in the prompt. Further study reveals the common interaction mechanisms of LLMs during the discussion.
EntailE: Introducing Textual Entailment in Commonsense Knowledge Graph Completion
Feb 15, 2024Commonsense knowledge graph completion is a new challenge for commonsense knowledge graph construction and application. In contrast to factual knowledge graphs such as Freebase and YAGO, commonsense knowledge graphs (CSKGs; e.g., ConceptNet) utilize free-form text to represent named entities, short phrases, and events as their nodes. Such a loose structure results in large and sparse CSKGs, which makes the semantic understanding of these nodes more critical for learning rich commonsense knowledge graph embedding. While current methods leverage semantic similarities to increase the graph density, the semantic plausibility of the nodes and their relations are under-explored. Previous works adopt conceptual abstraction to improve the consistency of modeling (event) plausibility, but they are not scalable enough and still suffer from data sparsity. In this paper, we propose to adopt textual entailment to find implicit entailment relations between CSKG nodes, to effectively densify the subgraph connecting nodes within the same conceptual class, which indicates a similar level of plausibility. Each node in CSKG finds its top entailed nodes using a finetuned transformer over natural language inference (NLI) tasks, which sufficiently capture textual entailment signals. The entailment relation between these nodes are further utilized to: 1) build new connections between source triplets and entailed nodes to densify the sparse CSKGs; 2) enrich the generalization ability of node representations by comparing the node embeddings with a contrastive loss. Experiments on two standard CSKGs demonstrate that our proposed framework EntailE can improve the performance of CSKG completion tasks under both transductive and inductive settings.
PipeNet: Question Answering with Semantic Pruning over Knowledge Graphs
Jan 31, 2024It is well acknowledged that incorporating explicit knowledge graphs (KGs) can benefit question answering. Existing approaches typically follow a grounding-reasoning pipeline in which entity nodes are first grounded for the query (question and candidate answers), and then a reasoning module reasons over the matched multi-hop subgraph for answer prediction. Although the pipeline largely alleviates the issue of extracting essential information from giant KGs, efficiency is still an open challenge when scaling up hops in grounding the subgraphs. In this paper, we target at finding semantically related entity nodes in the subgraph to improve the efficiency of graph reasoning with KG. We propose a grounding-pruning-reasoning pipeline to prune noisy nodes, remarkably reducing the computation cost and memory usage while also obtaining decent subgraph representation. In detail, the pruning module first scores concept nodes based on the dependency distance between matched spans and then prunes the nodes according to score ranks. To facilitate the evaluation of pruned subgraphs, we also propose a graph attention network (GAT) based module to reason with the subgraph data. Experimental results on CommonsenseQA and OpenBookQA demonstrate the effectiveness of our method.
On the Discussion of Large Language Models: Symmetry of Agents and Interplay with Prompts
Nov 13, 2023Two ways has been discussed to unlock the reasoning capability of a large language model. The first one is prompt engineering and the second one is to combine the multiple inferences of large language models, or the multi-agent discussion. Theoretically, this paper justifies the multi-agent discussion mechanisms from the symmetry of agents. Empirically, this paper reports the empirical results of the interplay of prompts and discussion mechanisms, revealing the empirical state-of-the-art performance of complex multi-agent mechanisms can be approached by carefully developed prompt engineering. This paper also proposes a scalable discussion mechanism based on conquer and merge, providing a simple multi-agent discussion solution with simple prompts but state-of-the-art performance.
Are LLMs Rigorous Logical Reasoner? Empowering Natural Language Proof Generation with Contrastive Stepwise Decoding
Nov 12, 2023
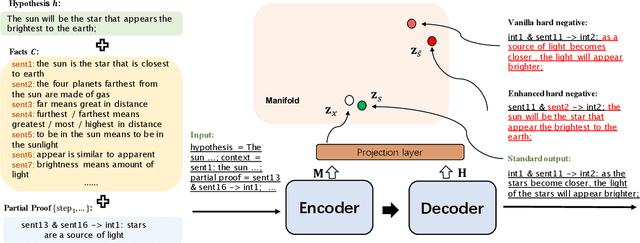
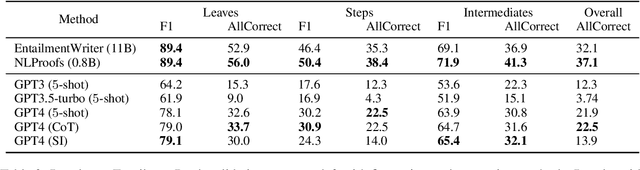
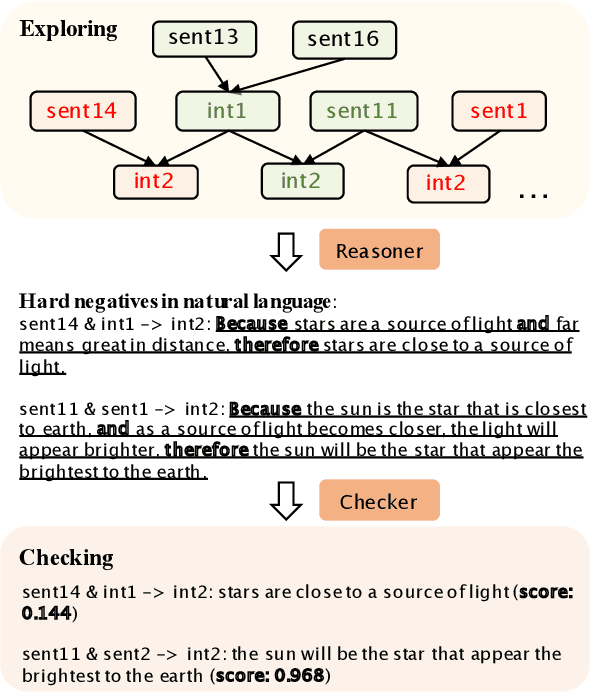
Logical reasoning remains a pivotal component within the realm of artificial intelligence. The recent evolution of large language models (LLMs) has marked significant progress in this domain. The adoption of strategies like chain-of-thought (CoT) has enhanced the performance of LLMs across diverse reasoning tasks. Nonetheless, logical reasoning that involves proof planning, specifically those that necessitate the validation of explanation accuracy, continues to present stumbling blocks. In this study, we first evaluate the efficacy of LLMs with advanced CoT strategies concerning such tasks. Our analysis reveals that LLMs still struggle to navigate complex reasoning chains, which demand the meticulous linkage of premises to derive a cogent conclusion. To address this issue, we finetune a smaller-scale language model, equipping it to decompose proof objectives into more manageable subgoals. We also introduce contrastive decoding to stepwise proof generation, making use of negative reasoning paths to strengthen the model's capacity for logical deduction. Experiments on EntailmentBank underscore the success of our method in augmenting the proof planning abilities of language models.
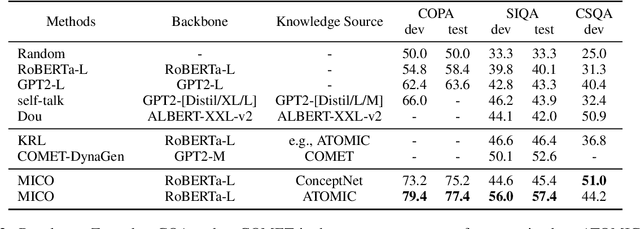
MICO: A Multi-alternative Contrastive Learning Framework for Commonsense Knowledge Representation
Oct 14, 2022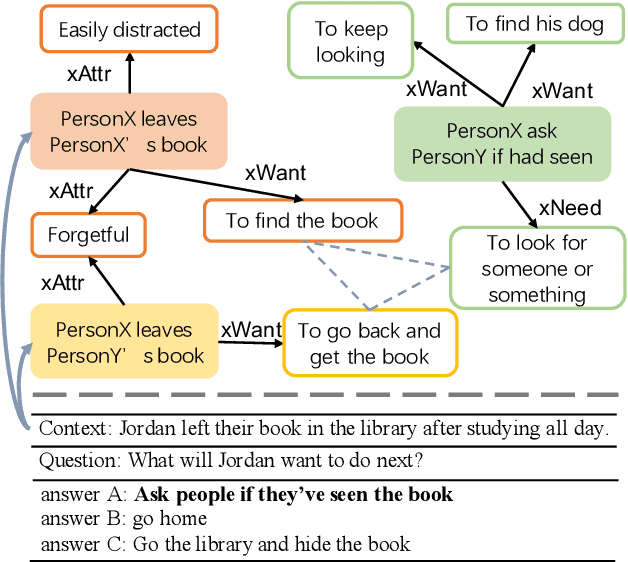

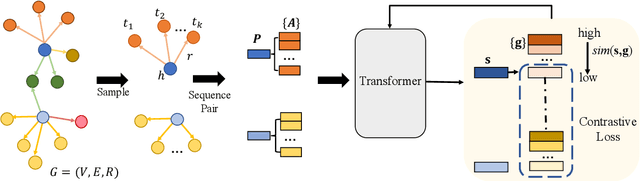
Commonsense reasoning tasks such as commonsense knowledge graph completion and commonsense question answering require powerful representation learning. In this paper, we propose to learn commonsense knowledge representation by MICO, a Multi-alternative contrastve learning framework on COmmonsense knowledge graphs (MICO). MICO generates the commonsense knowledge representation by contextual interaction between entity nodes and relations with multi-alternative contrastive learning. In MICO, the head and tail entities in an $(h,r,t)$ knowledge triple are converted to two relation-aware sequence pairs (a premise and an alternative) in the form of natural language. Semantic representations generated by MICO can benefit the following two tasks by simply comparing the distance score between the representations: 1) zero-shot commonsense question answering task; 2) inductive commonsense knowledge graph completion task. Extensive experiments show the effectiveness of our method.
* 9 pages, 2 figures
Multilingual Word Sense Disambiguation with Unified Sense Representation
Oct 14, 2022
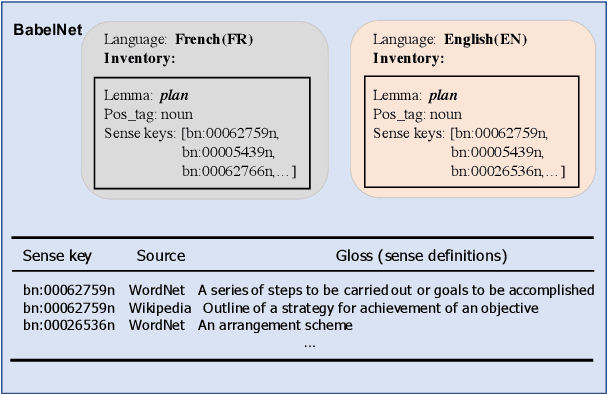

As a key natural language processing (NLP) task, word sense disambiguation (WSD) evaluates how well NLP models can understand the lexical semantics of words under specific contexts. Benefited from the large-scale annotation, current WSD systems have achieved impressive performances in English by combining supervised learning with lexical knowledge. However, such success is hard to be replicated in other languages, where we only have limited annotations.In this paper, based on the multilingual lexicon BabelNet describing the same set of concepts across languages, we propose building knowledge and supervised-based Multilingual Word Sense Disambiguation (MWSD) systems. We build unified sense representations for multiple languages and address the annotation scarcity problem for MWSD by transferring annotations from rich-sourced languages to poorer ones. With the unified sense representations, annotations from multiple languages can be jointly trained to benefit the MWSD tasks. Evaluations of SemEval-13 and SemEval-15 datasets demonstrate the effectiveness of our methodology.
* 8 pages, 5 figures
NaMemo: Enhancing Lecturers' Interpersonal Competence of Remembering Students' Names
Nov 21, 2019

Addressing students by their names helps a teacher to start building rapport with students and thus facilitate their classroom participation. However, this basic yet effective skill has become rather challenging for university lecturers (especially in Asian universities), who have to handle large-sized (sometimes exceeding 100) groups in their daily teaching. To enhance lecturers' competence in delivering interpersonal interaction, we develop NaMemo, a real-time name-indicating system based on a dedicated computer vision algorithm. This paper presents its design and feasibility study, which showed a plausible acceptance level from the participating teachers and students. We also reveal students' concerns on the abuse or misuse of this system: e.g., for checking attendance. Taken together, we discuss the opportunities and risks in design, and elaborate on the plan of a follow-up, in-depth implementation to further evaluate NaMemo's impacts on learning and teaching, as well as to probe design implications including privacy considerations.
Learning from Large-scale Noisy Web Data with Ubiquitous Reweighting for Image Classification
Nov 02, 2018
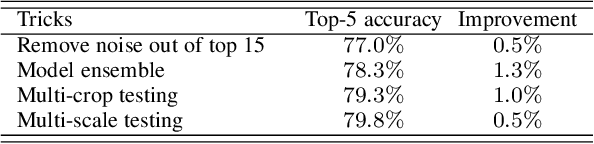


Many advances of deep learning techniques originate from the efforts of addressing the image classification task on large-scale datasets. However, the construction of such clean datasets is costly and time-consuming since the Internet is overwhelmed by noisy images with inadequate and inaccurate tags. In this paper, we propose a Ubiquitous Reweighting Network (URNet) that learns an image classification model from large-scale noisy data. By observing the web data, we find that there are five key challenges, \ie, imbalanced class sizes, high intra-classes diversity and inter-class similarity, imprecise instances, insufficient representative instances, and ambiguous class labels. To alleviate these challenges, we assume that every training instance has the potential to contribute positively by alleviating the data bias and noise via reweighting the influence of each instance according to different class sizes, large instance clusters, its confidence, small instance bags and the labels. In this manner, the influence of bias and noise in the web data can be gradually alleviated, leading to the steadily improving performance of URNet. Experimental results in the WebVision 2018 challenge with 16 million noisy training images from 5000 classes show that our approach outperforms state-of-the-art models and ranks the first place in the image classification task.