 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianqing Fang
Neuro-Inspired Information-Theoretic Hierarchical Perception for Multimodal Learning
Apr 15, 2024
Integrating and processing information from various sources or modalities are critical for obtaining a comprehensive and accurate perception of the real world in autonomous systems and cyber-physical systems. Drawing inspiration from neuroscience, we develop the Information-Theoretic Hierarchical Perception (ITHP) model, which utilizes the concept of information bottleneck. Different from most traditional fusion models that incorporate all modalities identically in neural networks, our model designates a prime modality and regards the remaining modalities as detectors in the information pathway, serving to distill the flow of information. Our proposed perception model focuses on constructing an effective and compact information flow by achieving a balance between the minimization of mutual information between the latent state and the input modal state, and the maximization of mutual information between the latent states and the remaining modal states. This approach leads to compact latent state representations that retain relevant information while minimizing redundancy, thereby substantially enhancing the performance of multimodal representation learning. Experimental evaluations on the MUStARD, CMU-MOSI, and CMU-MOSEI datasets demonstrate that our model consistently distills crucial information in multimodal learning scenarios, outperforming state-of-the-art benchmarks. Remarkably, on the CMU-MOSI dataset, ITHP surpasses human-level performance in the multimodal sentiment binary classification task across all evaluation metrics (i.e., Binary Accuracy, F1 Score, Mean Absolute Error, and Pearson Correlation).
Complex Reasoning over Logical Queries on Commonsense Knowledge Graphs
Mar 12, 2024
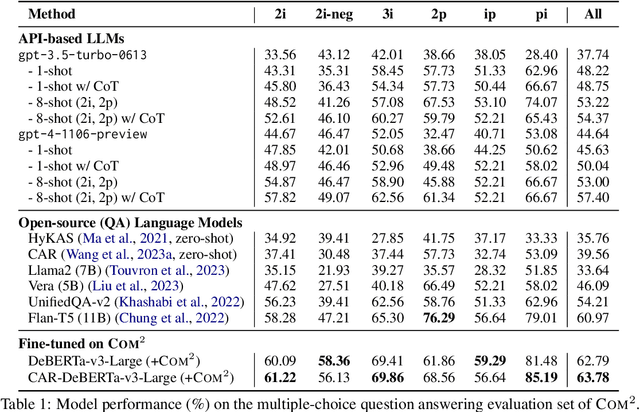
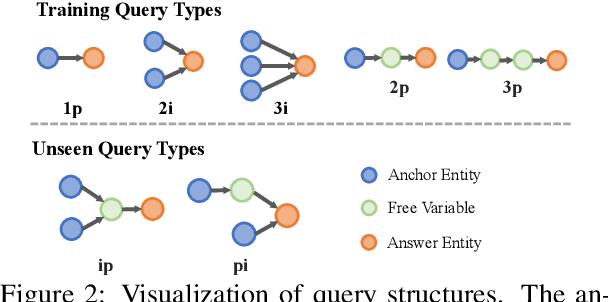
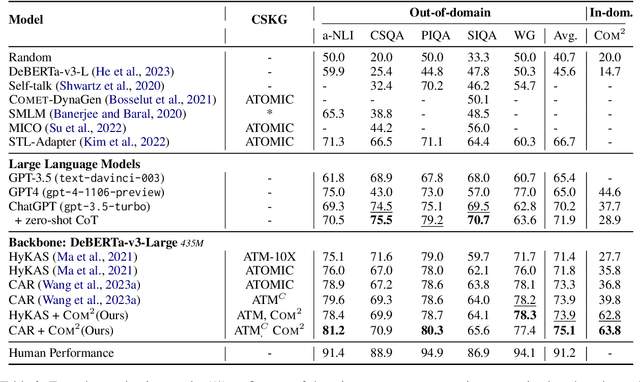
Event commonsense reasoning requires the ability to reason about the relationship between events, as well as infer implicit context underlying that relationship. However, data scarcity makes it challenging for language models to learn to generate commonsense inferences for contexts and questions involving interactions between complex events. To address this demand, we present COM2 (COMplex COMmonsense), a new dataset created by sampling multi-hop logical queries (e.g., the joint effect or cause of both event A and B, or the effect of the effect of event C) from an existing commonsense knowledge graph (CSKG), and verbalizing them using handcrafted rules and large language models into multiple-choice and text generation questions. Our experiments show that language models trained on COM2 exhibit significant improvements in complex reasoning ability, resulting in enhanced zero-shot performance in both in-domain and out-of-domain tasks for question answering and generative commonsense reasoning, without expensive human annotations.
AbsInstruct: Eliciting Abstraction Ability from LLMs through Explanation Tuning with Plausibility Estimation
Feb 16, 2024Abstraction ability is crucial in human intelligence, which can also benefit various tasks in NLP study. Existing work shows that LLMs are deficient in abstract ability, and how to improve it remains unexplored. In this work, we design the framework AbsInstruct to enhance LLMs' abstraction ability through instruction tuning. The framework builds instructions with in-depth explanations to assist LLMs in capturing the underlying rationale of abstraction. Meanwhile, we introduce a plausibility estimator to select instructions that are more consistent with the abstraction knowledge of LLMs to be aligned. Then, our framework combines abstraction instructions with general-purpose ones to build a hybrid dataset. Extensive experiments and analyses demonstrate that our framework can considerably enhance LLMs' abstraction ability with strong generalization performance while maintaining their general instruction-following abilities.
EntailE: Introducing Textual Entailment in Commonsense Knowledge Graph Completion
Feb 15, 2024Commonsense knowledge graph completion is a new challenge for commonsense knowledge graph construction and application. In contrast to factual knowledge graphs such as Freebase and YAGO, commonsense knowledge graphs (CSKGs; e.g., ConceptNet) utilize free-form text to represent named entities, short phrases, and events as their nodes. Such a loose structure results in large and sparse CSKGs, which makes the semantic understanding of these nodes more critical for learning rich commonsense knowledge graph embedding. While current methods leverage semantic similarities to increase the graph density, the semantic plausibility of the nodes and their relations are under-explored. Previous works adopt conceptual abstraction to improve the consistency of modeling (event) plausibility, but they are not scalable enough and still suffer from data sparsity. In this paper, we propose to adopt textual entailment to find implicit entailment relations between CSKG nodes, to effectively densify the subgraph connecting nodes within the same conceptual class, which indicates a similar level of plausibility. Each node in CSKG finds its top entailed nodes using a finetuned transformer over natural language inference (NLI) tasks, which sufficiently capture textual entailment signals. The entailment relation between these nodes are further utilized to: 1) build new connections between source triplets and entailed nodes to densify the sparse CSKGs; 2) enrich the generalization ability of node representations by comparing the node embeddings with a contrastive loss. Experiments on two standard CSKGs demonstrate that our proposed framework EntailE can improve the performance of CSKG completion tasks under both transductive and inductive settings.
ConstraintChecker: A Plugin for Large Language Models to Reason on Commonsense Knowledge Bases
Jan 25, 2024Reasoning over Commonsense Knowledge Bases (CSKB), i.e. CSKB reasoning, has been explored as a way to acquire new commonsense knowledge based on reference knowledge in the original CSKBs and external prior knowledge. Despite the advancement of Large Language Models (LLM) and prompt engineering techniques in various reasoning tasks, they still struggle to deal with CSKB reasoning. One of the problems is that it is hard for them to acquire explicit relational constraints in CSKBs from only in-context exemplars, due to a lack of symbolic reasoning capabilities (Bengio et al., 2021). To this end, we proposed **ConstraintChecker**, a plugin over prompting techniques to provide and check explicit constraints. When considering a new knowledge instance, ConstraintChecker employs a rule-based module to produce a list of constraints, then it uses a zero-shot learning module to check whether this knowledge instance satisfies all constraints. The acquired constraint-checking result is then aggregated with the output of the main prompting technique to produce the final output. Experimental results on CSKB Reasoning benchmarks demonstrate the effectiveness of our method by bringing consistent improvements over all prompting methods. Codes and data are available at \url{https://github.com/HKUST-KnowComp/ConstraintChecker}.
CANDLE: Iterative Conceptualization and Instantiation Distillation from Large Language Models for Commonsense Reasoning
Jan 14, 2024The sequential process of conceptualization and instantiation is essential to generalizable commonsense reasoning as it allows the application of existing knowledge to unfamiliar scenarios. However, existing works tend to undervalue the step of instantiation and heavily rely on pre-built concept taxonomies and human annotations to collect both types of knowledge, resulting in a lack of instantiated knowledge to complete reasoning, high cost, and limited scalability. To tackle these challenges, we introduce CANDLE, a distillation framework that iteratively performs contextualized conceptualization and instantiation over commonsense knowledge bases by instructing large language models to generate both types of knowledge with critic filtering. By applying CANDLE to ATOMIC, we construct a comprehensive knowledge base comprising six million conceptualizations and instantiated commonsense knowledge triples. Both types of knowledge are firmly rooted in the original ATOMIC dataset, and intrinsic evaluations demonstrate their exceptional quality and diversity. Empirical results indicate that distilling CANDLE on student models provides benefits across four downstream tasks. Our code, data, and models are publicly available at https://github.com/HKUST-KnowComp/CANDLE.
AbsPyramid: Benchmarking the Abstraction Ability of Language Models with a Unified Entailment Graph
Nov 16, 2023Cognitive research indicates that abstraction ability is essential in human intelligence, which remains under-explored in language models. In this paper, we present AbsPyramid, a unified entailment graph of 221K textual descriptions of abstraction knowledge. While existing resources only touch nouns or verbs within simplified events or specific domains, AbsPyramid collects abstract knowledge for three components of diverse events to comprehensively evaluate the abstraction ability of language models in the open domain. Experimental results demonstrate that current LLMs face challenges comprehending abstraction knowledge in zero-shot and few-shot settings. By training on our rich abstraction knowledge, we find LLMs can acquire basic abstraction abilities and generalize to unseen events. In the meantime, we empirically show that our benchmark is comprehensive to enhance LLMs across two previous abstraction tasks.
StoryAnalogy: Deriving Story-level Analogies from Large Language Models to Unlock Analogical Understanding
Oct 23, 2023Analogy-making between narratives is crucial for human reasoning. In this paper, we evaluate the ability to identify and generate analogies by constructing a first-of-its-kind large-scale story-level analogy corpus, \textsc{StoryAnalogy}, which contains 24K story pairs from diverse domains with human annotations on two similarities from the extended Structure-Mapping Theory. We design a set of tests on \textsc{StoryAnalogy}, presenting the first evaluation of story-level analogy identification and generation. Interestingly, we find that the analogy identification tasks are incredibly difficult not only for sentence embedding models but also for the recent large language models (LLMs) such as ChatGPT and LLaMa. ChatGPT, for example, only achieved around 30% accuracy in multiple-choice questions (compared to over 85% accuracy for humans). Furthermore, we observe that the data in \textsc{StoryAnalogy} can improve the quality of analogy generation in LLMs, where a fine-tuned FlanT5-xxl model achieves comparable performance to zero-shot ChatGPT.
QADYNAMICS: Training Dynamics-Driven Synthetic QA Diagnostic for Zero-Shot Commonsense Question Answering
Oct 17, 2023Zero-shot commonsense Question-Answering (QA) requires models to reason about general situations beyond specific benchmarks. State-of-the-art approaches fine-tune language models on QA pairs constructed from CommonSense Knowledge Bases (CSKBs) to equip the models with more commonsense knowledge in a QA context. However, current QA synthesis protocols may introduce noise from the CSKBs and generate ungrammatical questions and false negative options, which impede the model's ability to generalize. To address these issues, we propose QADYNAMICS, a training dynamics-driven framework for QA diagnostics and refinement. Our approach analyzes the training dynamics of each QA pair at both the question level and option level, discarding machine-detectable artifacts by removing uninformative QA pairs and mislabeled or false-negative options. Extensive experiments demonstrate the effectiveness of our approach, which outperforms all baselines while using only 33% of the synthetic data, even including LLMs such as ChatGPT. Moreover, expert evaluations confirm that our framework significantly improves the quality of QA synthesis. Our codes and model checkpoints are available at https://github.com/HKUST-KnowComp/QaDynamics.
KCTS: Knowledge-Constrained Tree Search Decoding with Token-Level Hallucination Detection
Oct 13, 2023Large Language Models (LLMs) have demonstrated remarkable human-level natural language generation capabilities. However, their potential to generate misinformation, often called the hallucination problem, poses a significant risk to their deployment. A common approach to address this issue is to retrieve relevant knowledge and fine-tune the LLM with the knowledge in its input. Unfortunately, this method incurs high training costs and may cause catastrophic forgetting for multi-tasking models. To overcome these limitations, we propose a knowledge-constrained decoding method called KCTS (Knowledge-Constrained Tree Search), which guides a frozen LM to generate text aligned with the reference knowledge at each decoding step using a knowledge classifier score and MCTS (Monte-Carlo Tree Search). To adapt the sequence-level knowledge classifier to token-level guidance, we also propose a novel token-level hallucination detection method called RIPA (Reward Inflection Point Approximation). Our empirical results on knowledge-grounded dialogue and abstractive summarization demonstrate the strength of KCTS as a plug-and-play, model-agnostic decoding method that can effectively reduce hallucinations in natural language generation.