 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaul Bogdan
Neuro-Inspired Information-Theoretic Hierarchical Perception for Multimodal Learning
Apr 15, 2024
Integrating and processing information from various sources or modalities are critical for obtaining a comprehensive and accurate perception of the real world in autonomous systems and cyber-physical systems. Drawing inspiration from neuroscience, we develop the Information-Theoretic Hierarchical Perception (ITHP) model, which utilizes the concept of information bottleneck. Different from most traditional fusion models that incorporate all modalities identically in neural networks, our model designates a prime modality and regards the remaining modalities as detectors in the information pathway, serving to distill the flow of information. Our proposed perception model focuses on constructing an effective and compact information flow by achieving a balance between the minimization of mutual information between the latent state and the input modal state, and the maximization of mutual information between the latent states and the remaining modal states. This approach leads to compact latent state representations that retain relevant information while minimizing redundancy, thereby substantially enhancing the performance of multimodal representation learning. Experimental evaluations on the MUStARD, CMU-MOSI, and CMU-MOSEI datasets demonstrate that our model consistently distills crucial information in multimodal learning scenarios, outperforming state-of-the-art benchmarks. Remarkably, on the CMU-MOSI dataset, ITHP surpasses human-level performance in the multimodal sentiment binary classification task across all evaluation metrics (i.e., Binary Accuracy, F1 Score, Mean Absolute Error, and Pearson Correlation).
Exploring Neuron Interactions and Emergence in LLMs: From the Multifractal Analysis Perspective
Feb 14, 2024Prior studies on the emergence in large models have primarily focused on how the functional capabilities of large language models (LLMs) scale with model size. Our research, however, transcends this traditional paradigm, aiming to deepen our understanding of the emergence within LLMs by placing a special emphasis not just on the model size but more significantly on the complex behavior of neuron interactions during the training process. By introducing the concepts of "self-organization" and "multifractal analysis," we explore how neuron interactions dynamically evolve during training, leading to "emergence," mirroring the phenomenon in natural systems where simple micro-level interactions give rise to complex macro-level behaviors. To quantitatively analyze the continuously evolving interactions among neurons in large models during training, we propose the Neuron-based Multifractal Analysis (NeuroMFA). Utilizing NeuroMFA, we conduct a comprehensive examination of the emergent behavior in LLMs through the lens of both model size and training process, paving new avenues for research into the emergence in large models.
Unlocking Deep Learning: A BP-Free Approach for Parallel Block-Wise Training of Neural Networks
Dec 20, 2023Backpropagation (BP) has been a successful optimization technique for deep learning models. However, its limitations, such as backward- and update-locking, and its biological implausibility, hinder the concurrent updating of layers and do not mimic the local learning processes observed in the human brain. To address these issues, recent research has suggested using local error signals to asynchronously train network blocks. However, this approach often involves extensive trial-and-error iterations to determine the best configuration for local training. This includes decisions on how to decouple network blocks and which auxiliary networks to use for each block. In our work, we introduce a novel BP-free approach: a block-wise BP-free (BWBPF) neural network that leverages local error signals to optimize distinct sub-neural networks separately, where the global loss is only responsible for updating the output layer. The local error signals used in the BP-free model can be computed in parallel, enabling a potential speed-up in the weight update process through parallel implementation. Our experimental results consistently show that this approach can identify transferable decoupled architectures for VGG and ResNet variations, outperforming models trained with end-to-end backpropagation and other state-of-the-art block-wise learning techniques on datasets such as CIFAR-10 and Tiny-ImageNet. The code is released at https://github.com/Belis0811/BWBPF.
Discovering Malicious Signatures in Software from Structural Interactions
Dec 19, 2023Malware represents a significant security concern in today's digital landscape, as it can destroy or disable operating systems, steal sensitive user information, and occupy valuable disk space. However, current malware detection methods, such as static-based and dynamic-based approaches, struggle to identify newly developed (``zero-day") malware and are limited by customized virtual machine (VM) environments. To overcome these limitations, we propose a novel malware detection approach that leverages deep learning, mathematical techniques, and network science. Our approach focuses on static and dynamic analysis and utilizes the Low-Level Virtual Machine (LLVM) to profile applications within a complex network. The generated network topologies are input into the GraphSAGE architecture to efficiently distinguish between benign and malicious software applications, with the operation names denoted as node features. Importantly, the GraphSAGE models analyze the network's topological geometry to make predictions, enabling them to detect state-of-the-art malware and prevent potential damage during execution in a VM. To evaluate our approach, we conduct a study on a dataset comprising source code from 24,376 applications, specifically written in C/C++, sourced directly from widely-recognized malware and various types of benign software. The results show a high detection performance with an Area Under the Receiver Operating Characteristic Curve (AUROC) of 99.85%. Our approach marks a substantial improvement in malware detection, providing a notably more accurate and efficient solution when compared to current state-of-the-art malware detection methods.
Leveraging Reinforcement Learning and Large Language Models for Code Optimization
Dec 09, 2023Code optimization is a daunting task that requires a significant level of expertise from experienced programmers. This level of expertise is not sufficient when compared to the rapid development of new hardware architectures. Towards advancing the whole code optimization process, recent approaches rely on machine learning and artificial intelligence techniques. This paper introduces a new framework to decrease the complexity of code optimization. The proposed framework builds on large language models (LLMs) and reinforcement learning (RL) and enables LLMs to receive feedback from their environment (i.e., unit tests) during the fine-tuning process. We compare our framework with existing state-of-the-art models and show that it is more efficient with respect to speed and computational usage, as a result of the decrement in training steps and its applicability to models with fewer parameters. Additionally, our framework reduces the possibility of logical and syntactical errors. Toward evaluating our approach, we run several experiments on the PIE dataset using a CodeT5 language model and RRHF, a new reinforcement learning algorithm. We adopt a variety of evaluation metrics with regards to optimization quality, and speedup. The evaluation results demonstrate that the proposed framework has similar results in comparison with existing models using shorter training times and smaller pre-trained models. In particular, we accomplish an increase of 5.6% and 2.2 over the baseline models concerning the %OP T and SP metrics.
Leader-Follower Neural Networks with Local Error Signals Inspired by Complex Collectives
Oct 11, 2023



The collective behavior of a network with heterogeneous, resource-limited information processing units (e.g., group of fish, flock of birds, or network of neurons) demonstrates high self-organization and complexity. These emergent properties arise from simple interaction rules where certain individuals can exhibit leadership-like behavior and influence the collective activity of the group. Motivated by the intricacy of these collectives, we propose a neural network (NN) architecture inspired by the rules observed in nature's collective ensembles. This NN structure contains workers that encompass one or more information processing units (e.g., neurons, filters, layers, or blocks of layers). Workers are either leaders or followers, and we train a leader-follower neural network (LFNN) by leveraging local error signals and optionally incorporating backpropagation (BP) and global loss. We investigate worker behavior and evaluate LFNNs through extensive experimentation. Our LFNNs trained with local error signals achieve significantly lower error rates than previous BP-free algorithms on MNIST and CIFAR-10 and even surpass BP-enabled baselines. In the case of ImageNet, our LFNN-l demonstrates superior scalability and outperforms previous BP-free algorithms by a significant margin.
Neuro-Inspired Hierarchical Multimodal Learning
Sep 27, 2023Integrating and processing information from various sources or modalities are critical for obtaining a comprehensive and accurate perception of the real world. Drawing inspiration from neuroscience, we develop the Information-Theoretic Hierarchical Perception (ITHP) model, which utilizes the concept of information bottleneck. Distinct from most traditional fusion models that aim to incorporate all modalities as input, our model designates the prime modality as input, while the remaining modalities act as detectors in the information pathway. Our proposed perception model focuses on constructing an effective and compact information flow by achieving a balance between the minimization of mutual information between the latent state and the input modal state, and the maximization of mutual information between the latent states and the remaining modal states. This approach leads to compact latent state representations that retain relevant information while minimizing redundancy, thereby substantially enhancing the performance of downstream tasks. Experimental evaluations on both the MUStARD and CMU-MOSI datasets demonstrate that our model consistently distills crucial information in multimodal learning scenarios, outperforming state-of-the-art benchmarks.
Fractional dynamics foster deep learning of COPD stage prediction
Mar 13, 2023



Chronic obstructive pulmonary disease (COPD) is one of the leading causes of death worldwide. Current COPD diagnosis (i.e., spirometry) could be unreliable because the test depends on an adequate effort from the tester and testee. Moreover, the early diagnosis of COPD is challenging. We address COPD detection by constructing two novel physiological signals datasets (4432 records from 54 patients in the WestRo COPD dataset and 13824 medical records from 534 patients in the WestRo Porti COPD dataset). The authors demonstrate their complex coupled fractal dynamical characteristics and perform a fractional-order dynamics deep learning analysis to diagnose COPD. The authors found that the fractional-order dynamical modeling can extract distinguishing signatures from the physiological signals across patients with all COPD stages from stage 0 (healthy) to stage 4 (very severe). They use the fractional signatures to develop and train a deep neural network that predicts COPD stages based on the input features (such as thorax breathing effort, respiratory rate, or oxygen saturation). The authors show that the fractional dynamic deep learning model (FDDLM) achieves a COPD prediction accuracy of 98.66% and can serve as a robust alternative to spirometry. The FDDLM also has high accuracy when validated on a dataset with different physiological signals.
Raising The Limit Of Image Rescaling Using Auxiliary Encoding
Mar 12, 2023
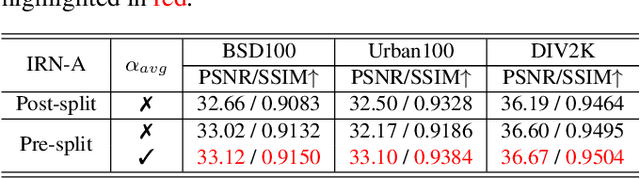
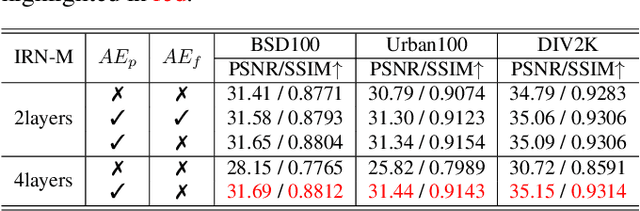

Normalizing flow models using invertible neural networks (INN) have been widely investigated for successful generative image super-resolution (SR) by learning the transformation between the normal distribution of latent variable $z$ and the conditional distribution of high-resolution (HR) images gave a low-resolution (LR) input. Recently, image rescaling models like IRN utilize the bidirectional nature of INN to push the performance limit of image upscaling by optimizing the downscaling and upscaling steps jointly. While the random sampling of latent variable $z$ is useful in generating diverse photo-realistic images, it is not desirable for image rescaling when accurate restoration of the HR image is more important. Hence, in places of random sampling of $z$, we propose auxiliary encoding modules to further push the limit of image rescaling performance. Two options to store the encoded latent variables in downscaled LR images, both readily supported in existing image file format, are proposed. One is saved as the alpha-channel, the other is saved as meta-data in the image header, and the corresponding modules are denoted as suffixes -A and -M respectively. Optimal network architectural changes are investigated for both options to demonstrate their effectiveness in raising the rescaling performance limit on different baseline models including IRN and DLV-IRN.
Coupled Multiwavelet Neural Operator Learning for Coupled Partial Differential Equations
Mar 04, 2023



Coupled partial differential equations (PDEs) are key tasks in modeling the complex dynamics of many physical processes. Recently, neural operators have shown the ability to solve PDEs by learning the integral kernel directly in Fourier/Wavelet space, so the difficulty for solving the coupled PDEs depends on dealing with the coupled mappings between the functions. Towards this end, we propose a \textit{coupled multiwavelets neural operator} (CMWNO) learning scheme by decoupling the coupled integral kernels during the multiwavelet decomposition and reconstruction procedures in the Wavelet space. The proposed model achieves significantly higher accuracy compared to previous learning-based solvers in solving the coupled PDEs including Gray-Scott (GS) equations and the non-local mean field game (MFG) problem. According to our experimental results, the proposed model exhibits a $2\times \sim 4\times$ improvement relative $L$2 error compared to the best results from the state-of-the-art models.
* Accepted to ICLR 2023