 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Fan
HyDiscGAN: A Hybrid Distributed cGAN for Audio-Visual Privacy Preservation in Multimodal Sentiment Analysis
Apr 18, 2024
Multimodal Sentiment Analysis (MSA) aims to identify speakers' sentiment tendencies in multimodal video content, raising serious concerns about privacy risks associated with multimodal data, such as voiceprints and facial images. Recent distributed collaborative learning has been verified as an effective paradigm for privacy preservation in multimodal tasks. However, they often overlook the privacy distinctions among different modalities, struggling to strike a balance between performance and privacy preservation. Consequently, it poses an intriguing question of maximizing multimodal utilization to improve performance while simultaneously protecting necessary modalities. This paper forms the first attempt at modality-specified (i.e., audio and visual) privacy preservation in MSA tasks. We propose a novel Hybrid Distributed cross-modality cGAN framework (HyDiscGAN), which learns multimodality alignment to generate fake audio and visual features conditioned on shareable de-identified textual data. The objective is to leverage the fake features to approximate real audio and visual content to guarantee privacy preservation while effectively enhancing performance. Extensive experiments show that compared with the state-of-the-art MSA model, HyDiscGAN can achieve superior or competitive performance while preserving privacy.
AbsInstruct: Eliciting Abstraction Ability from LLMs through Explanation Tuning with Plausibility Estimation
Feb 16, 2024Abstraction ability is crucial in human intelligence, which can also benefit various tasks in NLP study. Existing work shows that LLMs are deficient in abstract ability, and how to improve it remains unexplored. In this work, we design the framework AbsInstruct to enhance LLMs' abstraction ability through instruction tuning. The framework builds instructions with in-depth explanations to assist LLMs in capturing the underlying rationale of abstraction. Meanwhile, we introduce a plausibility estimator to select instructions that are more consistent with the abstraction knowledge of LLMs to be aligned. Then, our framework combines abstraction instructions with general-purpose ones to build a hybrid dataset. Extensive experiments and analyses demonstrate that our framework can considerably enhance LLMs' abstraction ability with strong generalization performance while maintaining their general instruction-following abilities.
Addressing Distribution Shift in Time Series Forecasting with Instance Normalization Flows
Jan 30, 2024Due to non-stationarity of time series, the distribution shift problem largely hinders the performance of time series forecasting. Existing solutions either fail for the shifts beyond simple statistics or the limited compatibility with forecasting models. In this paper, we propose a general decoupled formulation for time series forecasting, with no reliance on fixed statistics and no restriction on forecasting architectures. Then, we make such a formulation formalized into a bi-level optimization problem, to enable the joint learning of the transformation (outer loop) and forecasting (inner loop). Moreover, the special requirements of expressiveness and bi-direction for the transformation motivate us to propose instance normalization flows (IN-Flow), a novel invertible network for time series transformation. Extensive experiments demonstrate our method consistently outperforms state-of-the-art baselines on both synthetic and real-world data.
A Saliency Enhanced Feature Fusion based multiscale RGB-D Salient Object Detection Network
Jan 22, 2024Multiscale convolutional neural network (CNN) has demonstrated remarkable capabilities in solving various vision problems. However, fusing features of different scales alwaysresults in large model sizes, impeding the application of multiscale CNNs in RGB-D saliency detection. In this paper, we propose a customized feature fusion module, called Saliency Enhanced Feature Fusion (SEFF), for RGB-D saliency detection. SEFF utilizes saliency maps of the neighboring scales to enhance the necessary features for fusing, resulting in more representative fused features. Our multiscale RGB-D saliency detector uses SEFF and processes images with three different scales. SEFF is used to fuse the features of RGB and depth images, as well as the features of decoders at different scales. Extensive experiments on five benchmark datasets have demonstrated the superiority of our method over ten SOTA saliency detectors.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
FourierGNN: Rethinking Multivariate Time Series Forecasting from a Pure Graph Perspective
Nov 10, 2023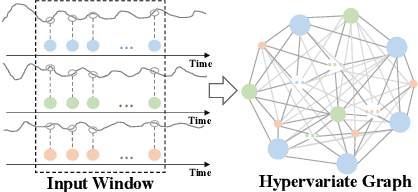
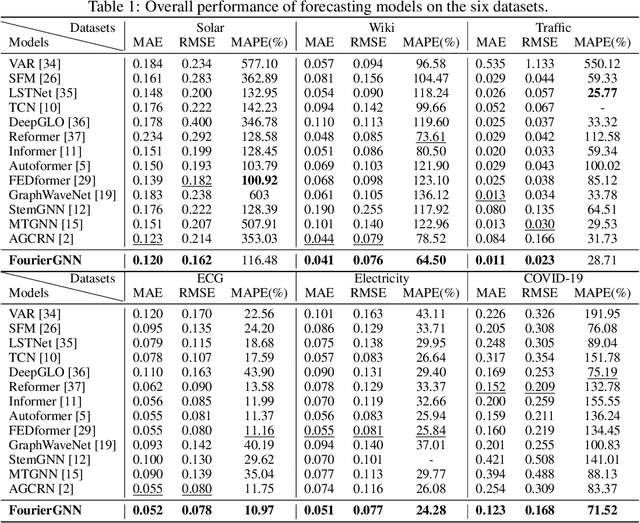

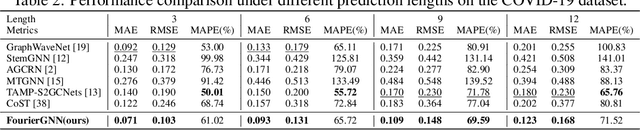
Multivariate time series (MTS) forecasting has shown great importance in numerous industries. Current state-of-the-art graph neural network (GNN)-based forecasting methods usually require both graph networks (e.g., GCN) and temporal networks (e.g., LSTM) to capture inter-series (spatial) dynamics and intra-series (temporal) dependencies, respectively. However, the uncertain compatibility of the two networks puts an extra burden on handcrafted model designs. Moreover, the separate spatial and temporal modeling naturally violates the unified spatiotemporal inter-dependencies in real world, which largely hinders the forecasting performance. To overcome these problems, we explore an interesting direction of directly applying graph networks and rethink MTS forecasting from a pure graph perspective. We first define a novel data structure, hypervariate graph, which regards each series value (regardless of variates or timestamps) as a graph node, and represents sliding windows as space-time fully-connected graphs. This perspective considers spatiotemporal dynamics unitedly and reformulates classic MTS forecasting into the predictions on hypervariate graphs. Then, we propose a novel architecture Fourier Graph Neural Network (FourierGNN) by stacking our proposed Fourier Graph Operator (FGO) to perform matrix multiplications in Fourier space. FourierGNN accommodates adequate expressiveness and achieves much lower complexity, which can effectively and efficiently accomplish the forecasting. Besides, our theoretical analysis reveals FGO's equivalence to graph convolutions in the time domain, which further verifies the validity of FourierGNN. Extensive experiments on seven datasets have demonstrated our superior performance with higher efficiency and fewer parameters compared with state-of-the-art methods.
Frequency-domain MLPs are More Effective Learners in Time Series Forecasting
Nov 10, 2023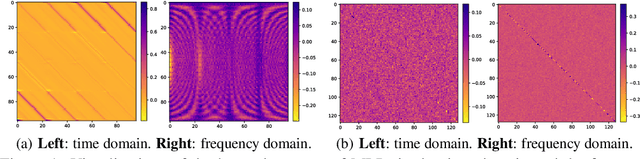
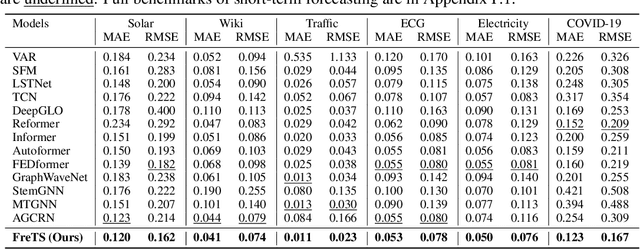
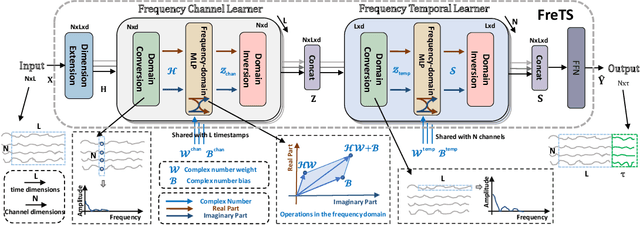
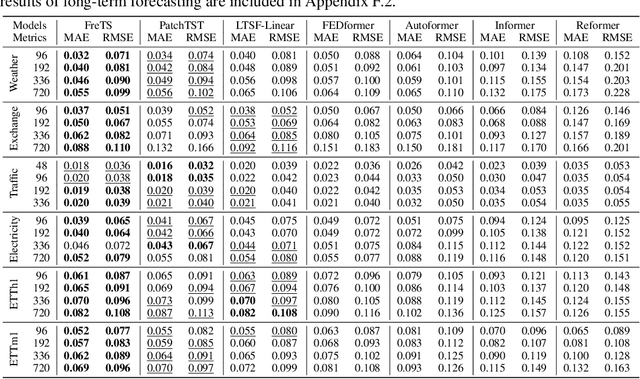
Time series forecasting has played the key role in different industrial, including finance, traffic, energy, and healthcare domains. While existing literatures have designed many sophisticated architectures based on RNNs, GNNs, or Transformers, another kind of approaches based on multi-layer perceptrons (MLPs) are proposed with simple structure, low complexity, and {superior performance}. However, most MLP-based forecasting methods suffer from the point-wise mappings and information bottleneck, which largely hinders the forecasting performance. To overcome this problem, we explore a novel direction of applying MLPs in the frequency domain for time series forecasting. We investigate the learned patterns of frequency-domain MLPs and discover their two inherent characteristic benefiting forecasting, (i) global view: frequency spectrum makes MLPs own a complete view for signals and learn global dependencies more easily, and (ii) energy compaction: frequency-domain MLPs concentrate on smaller key part of frequency components with compact signal energy. Then, we propose FreTS, a simple yet effective architecture built upon Frequency-domain MLPs for Time Series forecasting. FreTS mainly involves two stages, (i) Domain Conversion, that transforms time-domain signals into complex numbers of frequency domain; (ii) Frequency Learning, that performs our redesigned MLPs for the learning of real and imaginary part of frequency components. The above stages operated on both inter-series and intra-series scales further contribute to channel-wise and time-wise dependency learning. Extensive experiments on 13 real-world benchmarks (including 7 benchmarks for short-term forecasting and 6 benchmarks for long-term forecasting) demonstrate our consistent superiority over state-of-the-art methods.
P-Bench: A Multi-level Privacy Evaluation Benchmark for Language Models
Nov 07, 2023The rapid development of language models (LMs) brings unprecedented accessibility and usage for both models and users. On the one hand, powerful LMs, trained with massive textual data, achieve state-of-the-art performance over numerous downstream NLP tasks. On the other hand, more and more attention is paid to unrestricted model accesses that may bring malicious privacy risks of data leakage. To address these issues, many recent works propose privacy-preserving language models (PPLMs) with differential privacy (DP). Unfortunately, different DP implementations make it challenging for a fair comparison among existing PPLMs. In this paper, we present P-Bench, a multi-perspective privacy evaluation benchmark to empirically and intuitively quantify the privacy leakage of LMs. Instead of only protecting and measuring the privacy of protected data with DP parameters, P-Bench sheds light on the neglected inference data privacy during actual usage. P-Bench first clearly defines multi-faceted privacy objectives during private fine-tuning. Then, P-Bench constructs a unified pipeline to perform private fine-tuning. Lastly, P-Bench performs existing privacy attacks on LMs with pre-defined privacy objectives as the empirical evaluation results. The empirical attack results are used to fairly and intuitively evaluate the privacy leakage of various PPLMs. We conduct extensive experiments on three datasets of GLUE for mainstream LMs.
Chain-of-Choice Hierarchical Policy Learning for Conversational Recommendation
Oct 27, 2023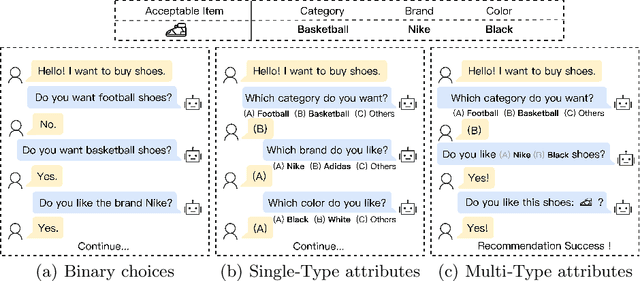
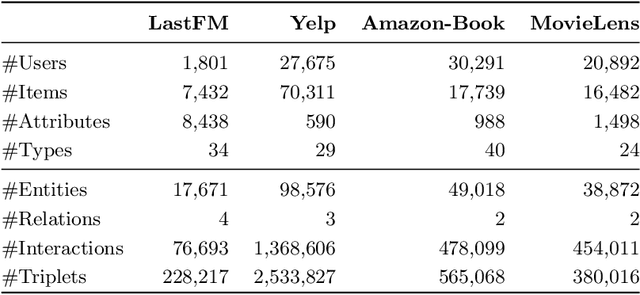
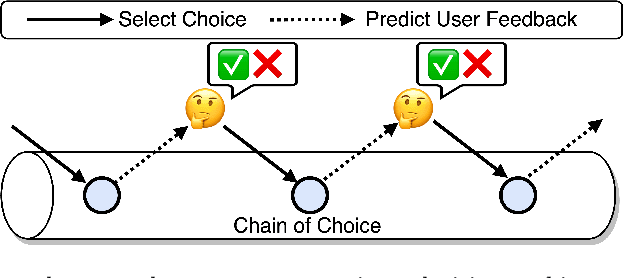
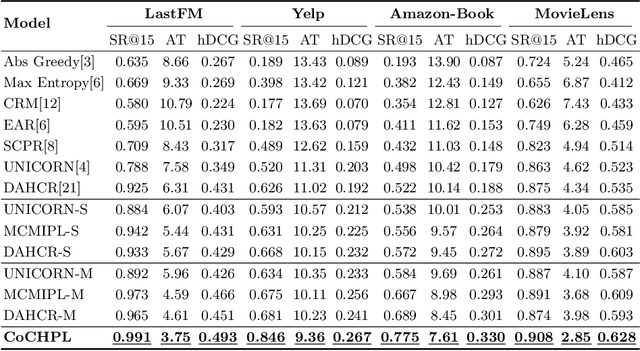
Conversational Recommender Systems (CRS) illuminate user preferences via multi-round interactive dialogues, ultimately navigating towards precise and satisfactory recommendations. However, contemporary CRS are limited to inquiring binary or multi-choice questions based on a single attribute type (e.g., color) per round, which causes excessive rounds of interaction and diminishes the user's experience. To address this, we propose a more realistic and efficient conversational recommendation problem setting, called Multi-Type-Attribute Multi-round Conversational Recommendation (MTAMCR), which enables CRS to inquire about multi-choice questions covering multiple types of attributes in each round, thereby improving interactive efficiency. Moreover, by formulating MTAMCR as a hierarchical reinforcement learning task, we propose a Chain-of-Choice Hierarchical Policy Learning (CoCHPL) framework to enhance both the questioning efficiency and recommendation effectiveness in MTAMCR. Specifically, a long-term policy over options (i.e., ask or recommend) determines the action type, while two short-term intra-option policies sequentially generate the chain of attributes or items through multi-step reasoning and selection, optimizing the diversity and interdependence of questioning attributes. Finally, extensive experiments on four benchmarks demonstrate the superior performance of CoCHPL over prevailing state-of-the-art methods.
Dual-stage Flows-based Generative Modeling for Traceable Urban Planning
Oct 03, 2023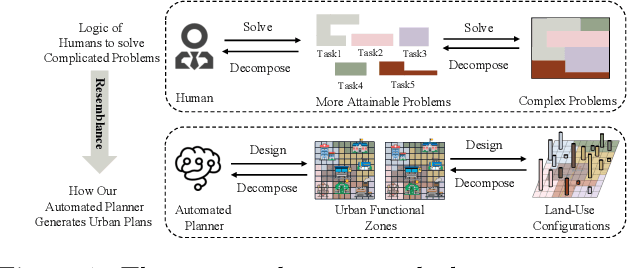
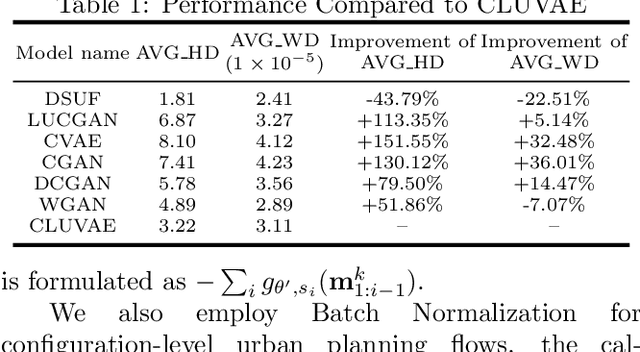
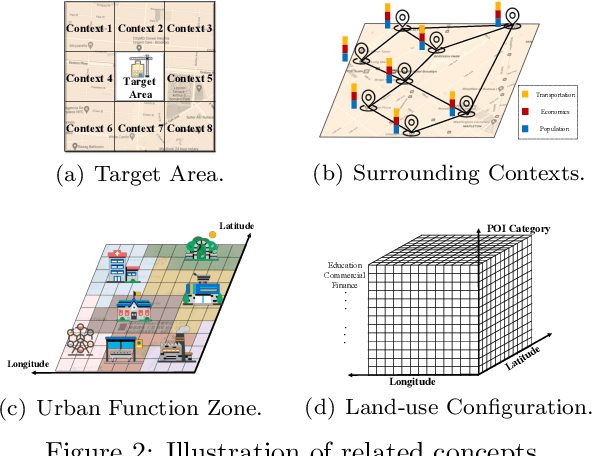
Urban planning, which aims to design feasible land-use configurations for target areas, has become increasingly essential due to the high-speed urbanization process in the modern era. However, the traditional urban planning conducted by human designers can be a complex and onerous task. Thanks to the advancement of deep learning algorithms, researchers have started to develop automated planning techniques. While these models have exhibited promising results, they still grapple with a couple of unresolved limitations: 1) Ignoring the relationship between urban functional zones and configurations and failing to capture the relationship among different functional zones. 2) Less interpretable and stable generation process. To overcome these limitations, we propose a novel generative framework based on normalizing flows, namely Dual-stage Urban Flows (DSUF) framework. Specifically, the first stage is to utilize zone-level urban planning flows to generate urban functional zones based on given surrounding contexts and human guidance. Then we employ an Information Fusion Module to capture the relationship among functional zones and fuse the information of different aspects. The second stage is to use configuration-level urban planning flows to obtain land-use configurations derived from fused information. We design several experiments to indicate that our framework can outperform compared to other generative models for the urban planning task.