 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShun Zheng
Addressing Distribution Shift in Time Series Forecasting with Instance Normalization Flows
Jan 30, 2024
Due to non-stationarity of time series, the distribution shift problem largely hinders the performance of time series forecasting. Existing solutions either fail for the shifts beyond simple statistics or the limited compatibility with forecasting models. In this paper, we propose a general decoupled formulation for time series forecasting, with no reliance on fixed statistics and no restriction on forecasting architectures. Then, we make such a formulation formalized into a bi-level optimization problem, to enable the joint learning of the transformation (outer loop) and forecasting (inner loop). Moreover, the special requirements of expressiveness and bi-direction for the transformation motivate us to propose instance normalization flows (IN-Flow), a novel invertible network for time series transformation. Extensive experiments demonstrate our method consistently outperforms state-of-the-art baselines on both synthetic and real-world data.
BatteryML:An Open-source platform for Machine Learning on Battery Degradation
Oct 23, 2023Battery degradation remains a pivotal concern in the energy storage domain, with machine learning emerging as a potent tool to drive forward insights and solutions. However, this intersection of electrochemical science and machine learning poses complex challenges. Machine learning experts often grapple with the intricacies of battery science, while battery researchers face hurdles in adapting intricate models tailored to specific datasets. Beyond this, a cohesive standard for battery degradation modeling, inclusive of data formats and evaluative benchmarks, is conspicuously absent. Recognizing these impediments, we present BatteryML - a one-step, all-encompass, and open-source platform designed to unify data preprocessing, feature extraction, and the implementation of both traditional and state-of-the-art models. This streamlined approach promises to enhance the practicality and efficiency of research applications. BatteryML seeks to fill this void, fostering an environment where experts from diverse specializations can collaboratively contribute, thus elevating the collective understanding and advancement of battery research.The code for our project is publicly available on GitHub at https://github.com/microsoft/BatteryML.
Towards Foundation Models for Learning on Tabular Data
Oct 22, 2023
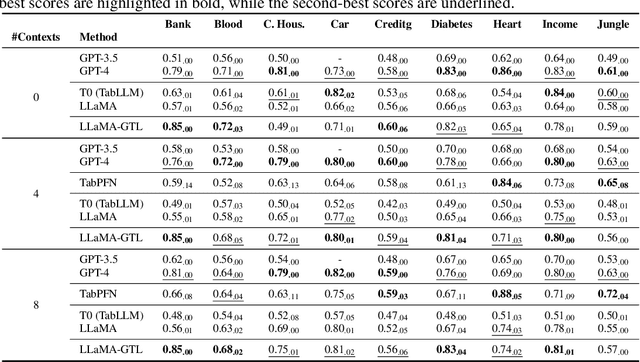
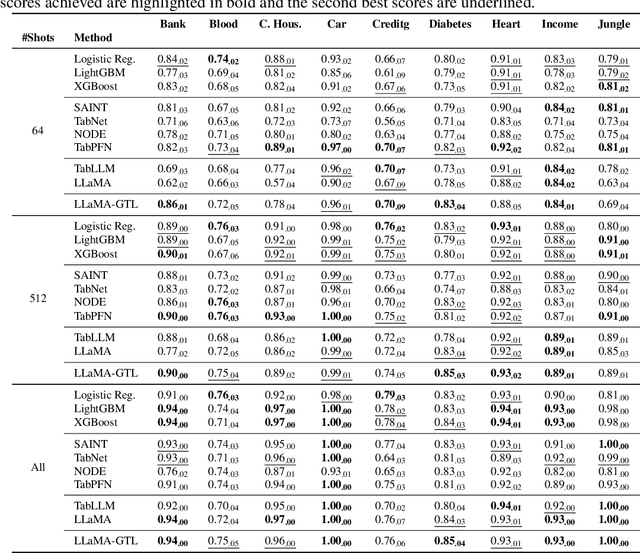
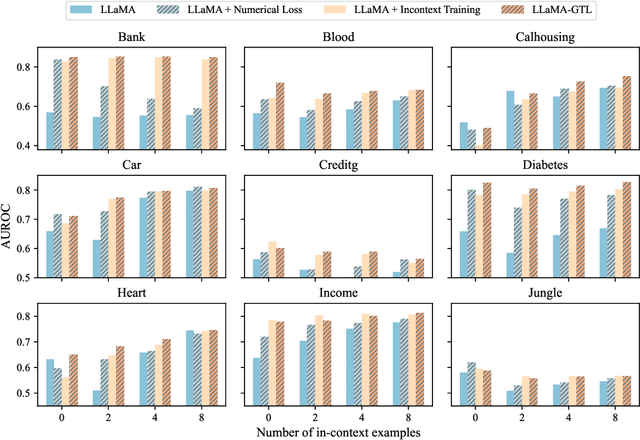
Learning on tabular data underpins numerous real-world applications. Despite considerable efforts in developing effective learning models for tabular data, current transferable tabular models remain in their infancy, limited by either the lack of support for direct instruction following in new tasks or the neglect of acquiring foundational knowledge and capabilities from diverse tabular datasets. In this paper, we propose Tabular Foundation Models (TabFMs) to overcome these limitations. TabFMs harness the potential of generative tabular learning, employing a pre-trained large language model (LLM) as the base model and fine-tuning it using purpose-designed objectives on an extensive range of tabular datasets. This approach endows TabFMs with a profound understanding and universal capabilities essential for learning on tabular data. Our evaluations underscore TabFM's effectiveness: not only does it significantly excel in instruction-following tasks like zero-shot and in-context inference, but it also showcases performance that approaches, and in instances, even transcends, the renowned yet mysterious closed-source LLMs like GPT-4. Furthermore, when fine-tuning with scarce data, our model achieves remarkable efficiency and maintains competitive performance with abundant training data. Finally, while our results are promising, we also delve into TabFM's limitations and potential opportunities, aiming to stimulate and expedite future research on developing more potent TabFMs.
Learning Intra- and Inter-Cell Differences for Accurate Battery Lifespan Prediction across Diverse Conditions
Oct 11, 2023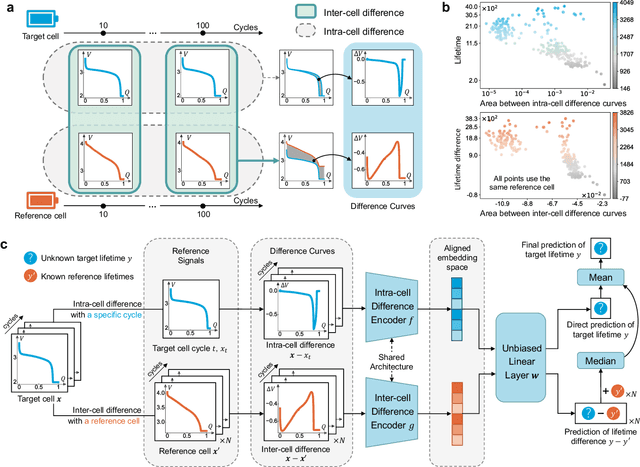
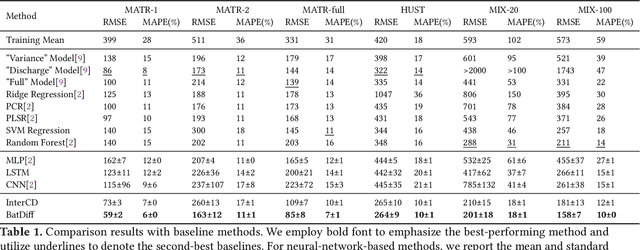
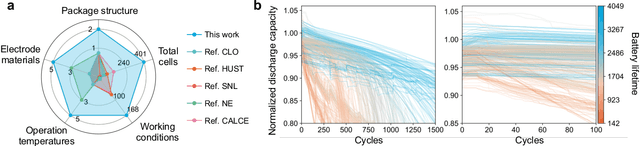
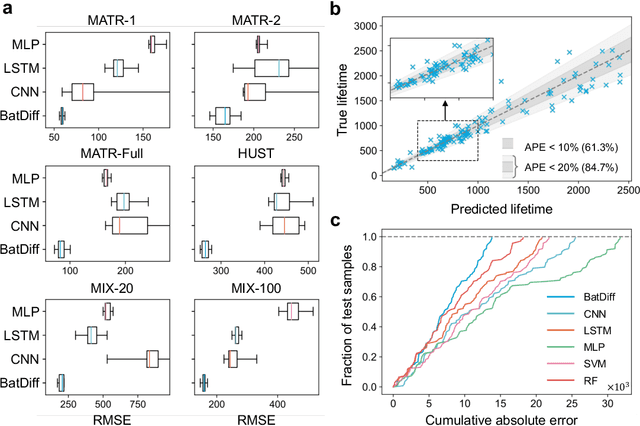
Battery life prediction holds significant practical value for battery research and development. Currently, many data-driven models rely on early electrical signals from specific target batteries to predict their lifespan. A common shortfall is that most existing methods are developed based on specific aging conditions, which not only limits their model's capability but also diminishes their effectiveness in predicting degradation under varied conditions. As a result, these models often miss out on fully benefiting from the rich historical data available under other conditions. Here, to address above, we introduce an approach that explicitly captures differences between electrical signals of a target battery and a reference battery, irrespective of their materials and aging conditions, to forecast the target battery life. Through this inter-cell difference, we not only enhance the feature space but also pave the way for a universal battery life prediction framework. Remarkably, our model that combines the inter- and intra-cell differences shines across diverse conditions, standing out in its efficiency and accuracy using all accessible datasets. An essential application of our approach is its capability to leverage data from older batteries effectively, enabling newer batteries to capitalize on insights gained from past batteries. This work not only enriches the battery data utilization strategy but also sets the stage for smarter battery management system in the future.
ProbTS: A Unified Toolkit to Probe Deep Time-series Forecasting
Oct 11, 2023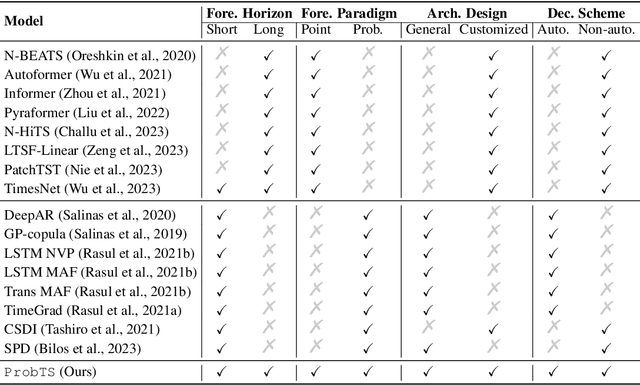
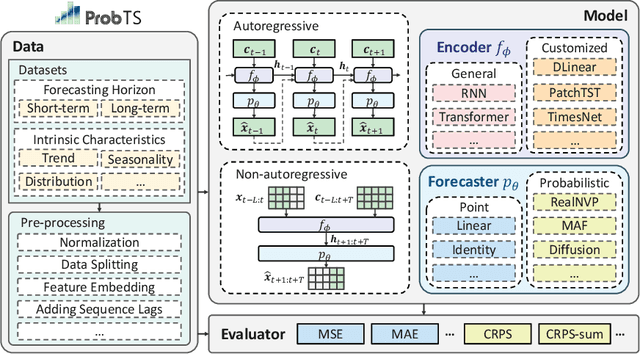
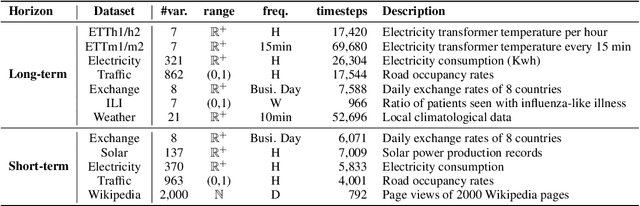

Time-series forecasting serves as a linchpin in a myriad of applications, spanning various domains. With the growth of deep learning, this arena has bifurcated into two salient branches: one focuses on crafting specific neural architectures tailored for time series, and the other harnesses advanced deep generative models for probabilistic forecasting. While both branches have made significant progress, their differences across data scenarios, methodological focuses, and decoding schemes pose profound, yet unexplored, research questions. To bridge this knowledge chasm, we introduce ProbTS, a pioneering toolkit developed to synergize and compare these two distinct branches. Endowed with a unified data module, a modularized model module, and a comprehensive evaluator module, ProbTS allows us to revisit and benchmark leading methods from both branches. The scrutiny with ProbTS highlights their distinct characteristics, relative strengths and weaknesses, and areas that need further exploration. Our analyses point to new avenues for research, aiming for more effective time-series forecasting.
Warpformer: A Multi-scale Modeling Approach for Irregular Clinical Time Series
Jun 14, 2023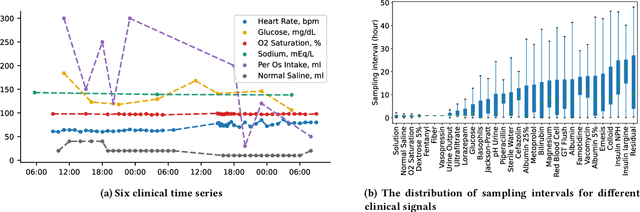
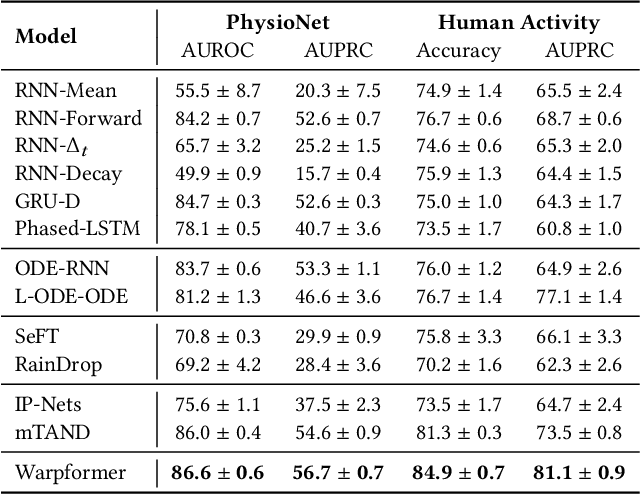
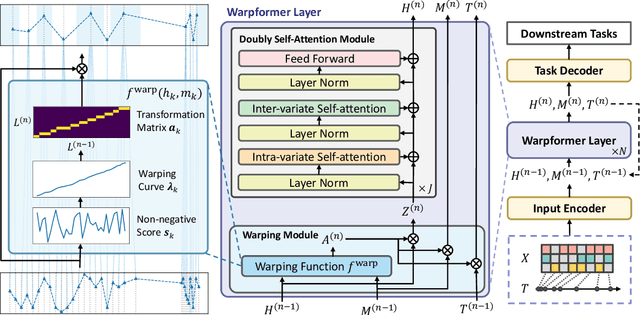
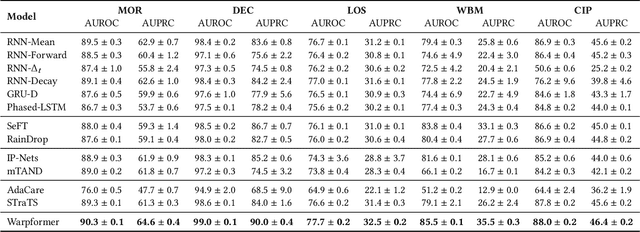
Irregularly sampled multivariate time series are ubiquitous in various fields, particularly in healthcare, and exhibit two key characteristics: intra-series irregularity and inter-series discrepancy. Intra-series irregularity refers to the fact that time-series signals are often recorded at irregular intervals, while inter-series discrepancy refers to the significant variability in sampling rates among diverse series. However, recent advances in irregular time series have primarily focused on addressing intra-series irregularity, overlooking the issue of inter-series discrepancy. To bridge this gap, we present Warpformer, a novel approach that fully considers these two characteristics. In a nutshell, Warpformer has several crucial designs, including a specific input representation that explicitly characterizes both intra-series irregularity and inter-series discrepancy, a warping module that adaptively unifies irregular time series in a given scale, and a customized attention module for representation learning. Additionally, we stack multiple warping and attention modules to learn at different scales, producing multi-scale representations that balance coarse-grained and fine-grained signals for downstream tasks. We conduct extensive experiments on widely used datasets and a new large-scale benchmark built from clinical databases. The results demonstrate the superiority of Warpformer over existing state-of-the-art approaches.
UADB: Unsupervised Anomaly Detection Booster
Jun 03, 2023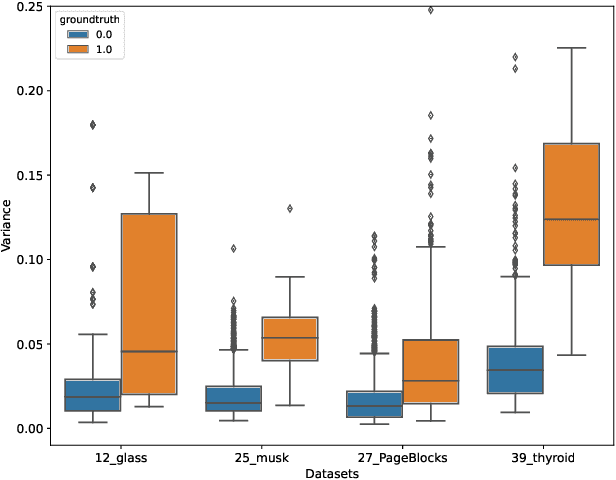
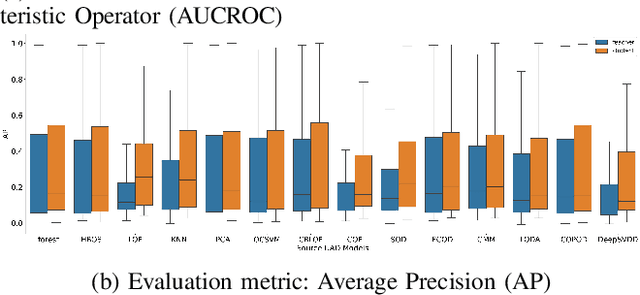
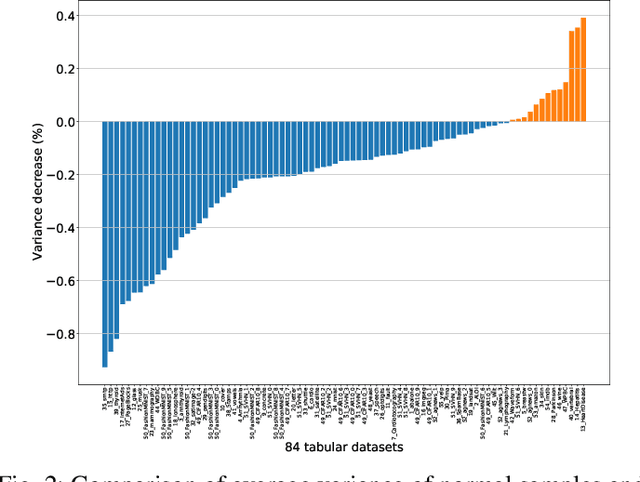
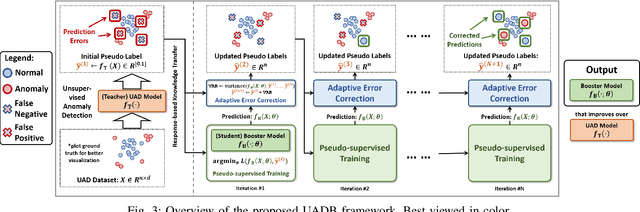
Unsupervised Anomaly Detection (UAD) is a key data mining problem owing to its wide real-world applications. Due to the complete absence of supervision signals, UAD methods rely on implicit assumptions about anomalous patterns (e.g., scattered/sparsely/densely clustered) to detect anomalies. However, real-world data are complex and vary significantly across different domains. No single assumption can describe such complexity and be valid in all scenarios. This is also confirmed by recent research that shows no UAD method is omnipotent. Based on above observations, instead of searching for a magic universal winner assumption, we seek to design a general UAD Booster (UADB) that empowers any UAD models with adaptability to different data. This is a challenging task given the heterogeneous model structures and assumptions adopted by existing UAD methods. To achieve this, we dive deep into the UAD problem and find that compared to normal data, anomalies (i) lack clear structure/pattern in feature space, thus (ii) harder to learn by model without a suitable assumption, and finally, leads to (iii) high variance between different learners. In light of these findings, we propose to (i) distill the knowledge of the source UAD model to an imitation learner (booster) that holds no data assumption, then (ii) exploit the variance between them to perform automatic correction, and thus (iii) improve the booster over the original UAD model. We use a neural network as the booster for its strong expressive power as a universal approximator and ability to perform flexible post-hoc tuning. Note that UADB is a model-agnostic framework that can enhance heterogeneous UAD models in a unified way. Extensive experiments on over 80 tabular datasets demonstrate the effectiveness of UADB.
Learning Differential Operators for Interpretable Time Series Modeling
Sep 03, 2022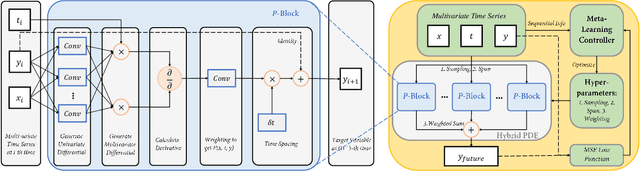



Modeling sequential patterns from data is at the core of various time series forecasting tasks. Deep learning models have greatly outperformed many traditional models, but these black-box models generally lack explainability in prediction and decision making. To reveal the underlying trend with understandable mathematical expressions, scientists and economists tend to use partial differential equations (PDEs) to explain the highly nonlinear dynamics of sequential patterns. However, it usually requires domain expert knowledge and a series of simplified assumptions, which is not always practical and can deviate from the ever-changing world. Is it possible to learn the differential relations from data dynamically to explain the time-evolving dynamics? In this work, we propose an learning framework that can automatically obtain interpretable PDE models from sequential data. Particularly, this framework is comprised of learnable differential blocks, named $P$-blocks, which is proved to be able to approximate any time-evolving complex continuous functions in theory. Moreover, to capture the dynamics shift, this framework introduces a meta-learning controller to dynamically optimize the hyper-parameters of a hybrid PDE model. Extensive experiments on times series forecasting of financial, engineering, and health data show that our model can provide valuable interpretability and achieve comparable performance to state-of-the-art models. From empirical studies, we find that learning a few differential operators may capture the major trend of sequential dynamics without massive computational complexity.
Less Is More: Fast Multivariate Time Series Forecasting with Light Sampling-oriented MLP Structures
Jul 04, 2022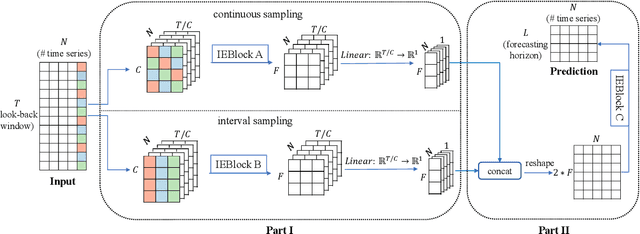
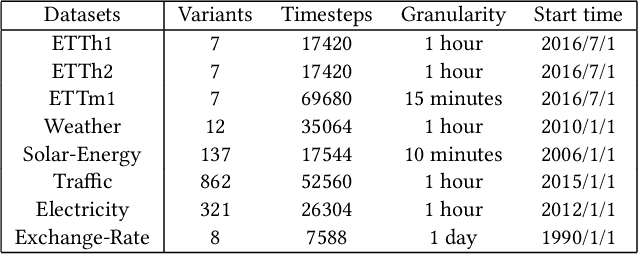
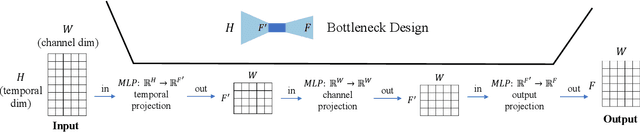
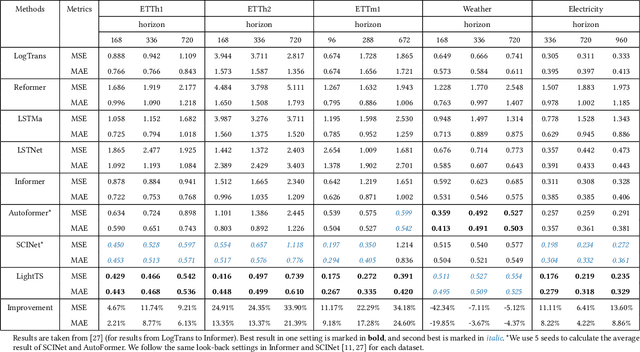
Multivariate time series forecasting has seen widely ranging applications in various domains, including finance, traffic, energy, and healthcare. To capture the sophisticated temporal patterns, plenty of research studies designed complex neural network architectures based on many variants of RNNs, GNNs, and Transformers. However, complex models are often computationally expensive and thus face a severe challenge in training and inference efficiency when applied to large-scale real-world datasets. In this paper, we introduce LightTS, a light deep learning architecture merely based on simple MLP-based structures. The key idea of LightTS is to apply an MLP-based structure on top of two delicate down-sampling strategies, including interval sampling and continuous sampling, inspired by a crucial fact that down-sampling time series often preserves the majority of its information. We conduct extensive experiments on eight widely used benchmark datasets. Compared with the existing state-of-the-art methods, LightTS demonstrates better performance on five of them and comparable performance on the rest. Moreover, LightTS is highly efficient. It uses less than 5% FLOPS compared with previous SOTA methods on the largest benchmark dataset. In addition, LightTS is robust and has a much smaller variance in forecasting accuracy than previous SOTA methods in long sequence forecasting tasks.
DEPTS: Deep Expansion Learning for Periodic Time Series Forecasting
Mar 15, 2022
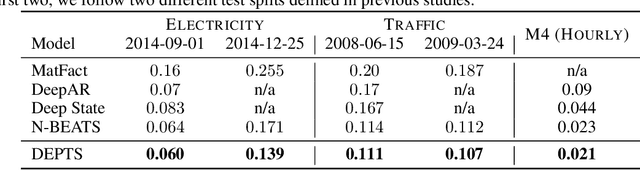
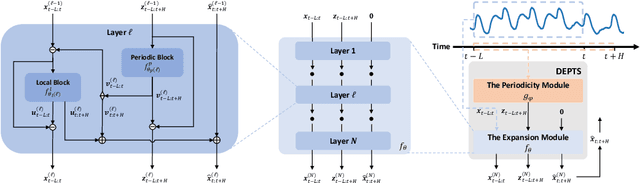
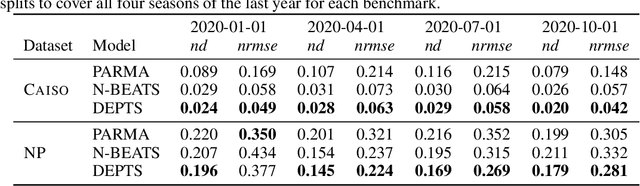
Periodic time series (PTS) forecasting plays a crucial role in a variety of industries to foster critical tasks, such as early warning, pre-planning, resource scheduling, etc. However, the complicated dependencies of the PTS signal on its inherent periodicity as well as the sophisticated composition of various periods hinder the performance of PTS forecasting. In this paper, we introduce a deep expansion learning framework, DEPTS, for PTS forecasting. DEPTS starts with a decoupled formulation by introducing the periodic state as a hidden variable, which stimulates us to make two dedicated modules to tackle the aforementioned two challenges. First, we develop an expansion module on top of residual learning to perform a layer-by-layer expansion of those complicated dependencies. Second, we introduce a periodicity module with a parameterized periodic function that holds sufficient capacity to capture diversified periods. Moreover, our two customized modules also have certain interpretable capabilities, such as attributing the forecasts to either local momenta or global periodicity and characterizing certain core periodic properties, e.g., amplitudes and frequencies. Extensive experiments on both synthetic data and real-world data demonstrate the effectiveness of DEPTS on handling PTS. In most cases, DEPTS achieves significant improvements over the best baseline. Specifically, the error reduction can even reach up to 20% for a few cases. Finally, all codes are publicly available.