 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYanjie Fu
Knockoff-Guided Feature Selection via A Single Pre-trained Reinforced Agent
Mar 06, 2024
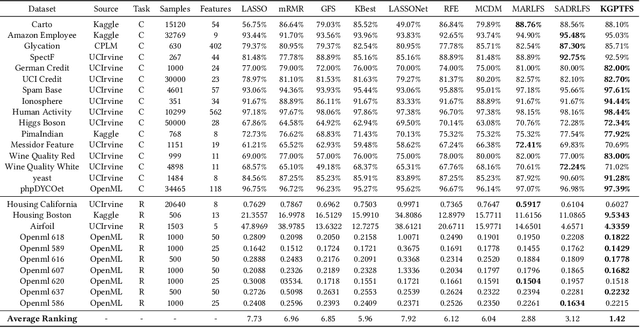
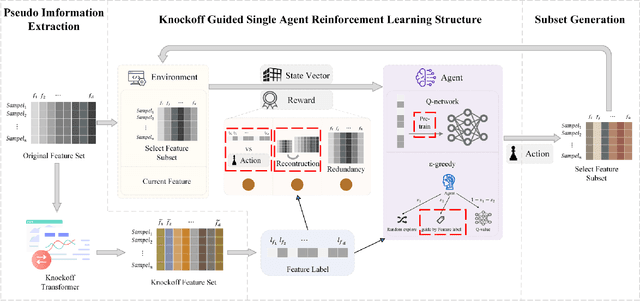
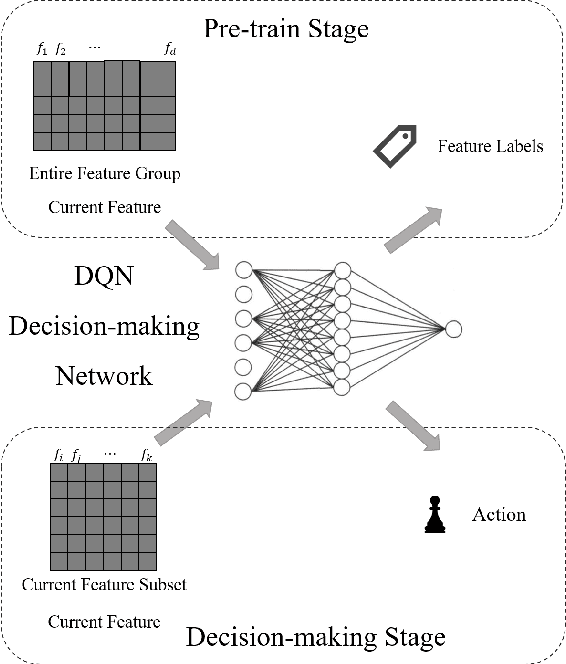
Feature selection prepares the AI-readiness of data by eliminating redundant features. Prior research falls into two primary categories: i) Supervised Feature Selection, which identifies the optimal feature subset based on their relevance to the target variable; ii) Unsupervised Feature Selection, which reduces the feature space dimensionality by capturing the essential information within the feature set instead of using target variable. However, SFS approaches suffer from time-consuming processes and limited generalizability due to the dependence on the target variable and downstream ML tasks. UFS methods are constrained by the deducted feature space is latent and untraceable. To address these challenges, we introduce an innovative framework for feature selection, which is guided by knockoff features and optimized through reinforcement learning, to identify the optimal and effective feature subset. In detail, our method involves generating "knockoff" features that replicate the distribution and characteristics of the original features but are independent of the target variable. Each feature is then assigned a pseudo label based on its correlation with all the knockoff features, serving as a novel metric for feature evaluation. Our approach utilizes these pseudo labels to guide the feature selection process in 3 novel ways, optimized by a single reinforced agent: 1). A deep Q-network, pre-trained with the original features and their corresponding pseudo labels, is employed to improve the efficacy of the exploration process in feature selection. 2). We introduce unsupervised rewards to evaluate the feature subset quality based on the pseudo labels and the feature space reconstruction loss to reduce dependencies on the target variable. 3). A new {\epsilon}-greedy strategy is used, incorporating insights from the pseudo labels to make the feature selection process more effective.
Feature Selection as Deep Sequential Generative Learning
Mar 06, 2024
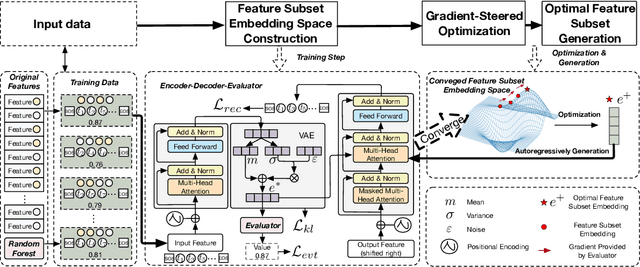
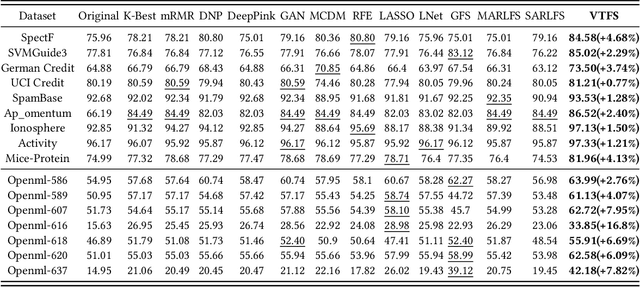
Feature selection aims to identify the most pattern-discriminative feature subset. In prior literature, filter (e.g., backward elimination) and embedded (e.g., Lasso) methods have hyperparameters (e.g., top-K, score thresholding) and tie to specific models, thus, hard to generalize; wrapper methods search a feature subset in a huge discrete space and is computationally costly. To transform the way of feature selection, we regard a selected feature subset as a selection decision token sequence and reformulate feature selection as a deep sequential generative learning task that distills feature knowledge and generates decision sequences. Our method includes three steps: (1) We develop a deep variational transformer model over a joint of sequential reconstruction, variational, and performance evaluator losses. Our model can distill feature selection knowledge and learn a continuous embedding space to map feature selection decision sequences into embedding vectors associated with utility scores. (2) We leverage the trained feature subset utility evaluator as a gradient provider to guide the identification of the optimal feature subset embedding;(3) We decode the optimal feature subset embedding to autoregressively generate the best feature selection decision sequence with autostop. Extensive experimental results show this generative perspective is effective and generic, without large discrete search space and expert-specific hyperparameters.
LLM-Enhanced User-Item Interactions: Leveraging Edge Information for Optimized Recommendations
Feb 14, 2024The extraordinary performance of large language models has not only reshaped the research landscape in the field of NLP but has also demonstrated its exceptional applicative potential in various domains. However, the potential of these models in mining relationships from graph data remains under-explored. Graph neural networks, as a popular research area in recent years, have numerous studies on relationship mining. Yet, current cutting-edge research in graph neural networks has not been effectively integrated with large language models, leading to limited efficiency and capability in graph relationship mining tasks. A primary challenge is the inability of LLMs to deeply exploit the edge information in graphs, which is critical for understanding complex node relationships. This gap limits the potential of LLMs to extract meaningful insights from graph structures, limiting their applicability in more complex graph-based analysis. We focus on how to utilize existing LLMs for mining and understanding relationships in graph data, applying these techniques to recommendation tasks. We propose an innovative framework that combines the strong contextual representation capabilities of LLMs with the relationship extraction and analysis functions of GNNs for mining relationships in graph data. Specifically, we design a new prompt construction framework that integrates relational information of graph data into natural language expressions, aiding LLMs in more intuitively grasping the connectivity information within graph data. Additionally, we introduce graph relationship understanding and analysis functions into LLMs to enhance their focus on connectivity information in graph data. Our evaluation on real-world datasets demonstrates the framework's ability to understand connectivity information in graph data.
Addressing Distribution Shift in Time Series Forecasting with Instance Normalization Flows
Jan 30, 2024Due to non-stationarity of time series, the distribution shift problem largely hinders the performance of time series forecasting. Existing solutions either fail for the shifts beyond simple statistics or the limited compatibility with forecasting models. In this paper, we propose a general decoupled formulation for time series forecasting, with no reliance on fixed statistics and no restriction on forecasting architectures. Then, we make such a formulation formalized into a bi-level optimization problem, to enable the joint learning of the transformation (outer loop) and forecasting (inner loop). Moreover, the special requirements of expressiveness and bi-direction for the transformation motivate us to propose instance normalization flows (IN-Flow), a novel invertible network for time series transformation. Extensive experiments demonstrate our method consistently outperforms state-of-the-art baselines on both synthetic and real-world data.
Dual-stage Flows-based Generative Modeling for Traceable Urban Planning
Oct 03, 2023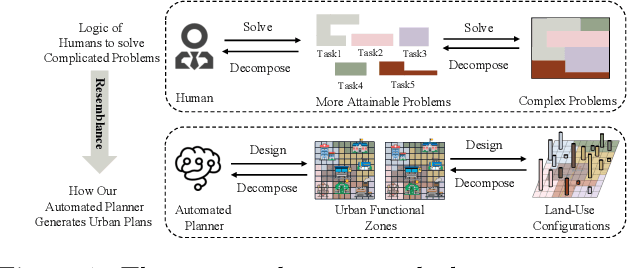
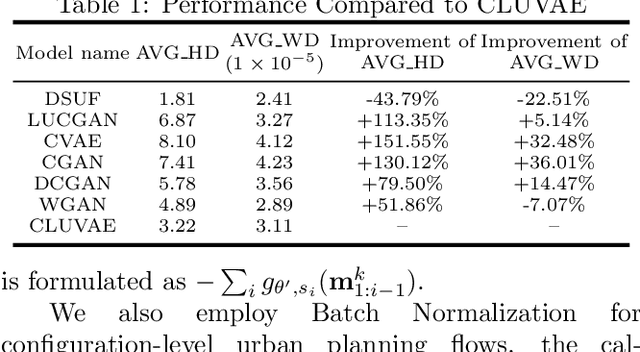
Urban planning, which aims to design feasible land-use configurations for target areas, has become increasingly essential due to the high-speed urbanization process in the modern era. However, the traditional urban planning conducted by human designers can be a complex and onerous task. Thanks to the advancement of deep learning algorithms, researchers have started to develop automated planning techniques. While these models have exhibited promising results, they still grapple with a couple of unresolved limitations: 1) Ignoring the relationship between urban functional zones and configurations and failing to capture the relationship among different functional zones. 2) Less interpretable and stable generation process. To overcome these limitations, we propose a novel generative framework based on normalizing flows, namely Dual-stage Urban Flows (DSUF) framework. Specifically, the first stage is to utilize zone-level urban planning flows to generate urban functional zones based on given surrounding contexts and human guidance. Then we employ an Information Fusion Module to capture the relationship among functional zones and fuse the information of different aspects. The second stage is to use configuration-level urban planning flows to obtain land-use configurations derived from fused information. We design several experiments to indicate that our framework can outperform compared to other generative models for the urban planning task.
Feature Cognition Enhancement via Interaction-Aware Automated Transformation
Sep 29, 2023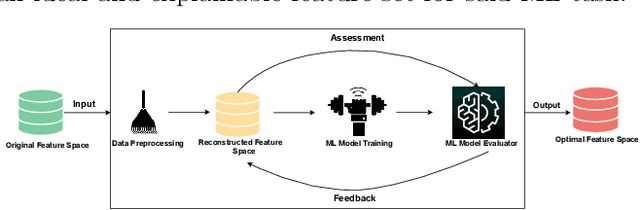

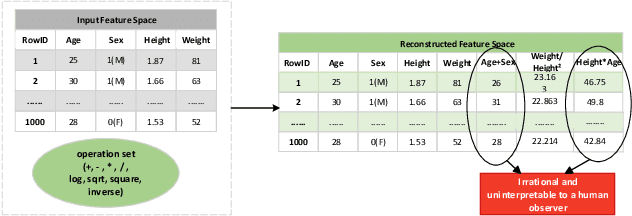
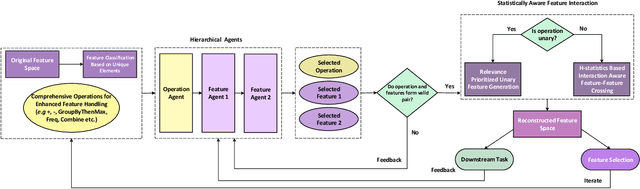
Creating an effective representation space is crucial for mitigating the curse of dimensionality, enhancing model generalization, addressing data sparsity, and leveraging classical models more effectively. Recent advancements in automated feature engineering (AutoFE) have made significant progress in addressing various challenges associated with representation learning, issues such as heavy reliance on intensive labor and empirical experiences, lack of explainable explicitness, and inflexible feature space reconstruction embedded into downstream tasks. However, these approaches are constrained by: 1) generation of potentially unintelligible and illogical reconstructed feature spaces, stemming from the neglect of expert-level cognitive processes; 2) lack of systematic exploration, which subsequently results in slower model convergence for identification of optimal feature space. To address these, we introduce an interaction-aware reinforced generation perspective. We redefine feature space reconstruction as a nested process of creating meaningful features and controlling feature set size through selection. We develop a hierarchical reinforcement learning structure with cascading Markov Decision Processes to automate feature and operation selection, as well as feature crossing. By incorporating statistical measures, we reward agents based on the interaction strength between selected features, resulting in intelligent and efficient exploration of the feature space that emulates human decision-making. Extensive experiments are conducted to validate our proposed approach.
Reinforcement-Enhanced Autoregressive Feature Transformation: Gradient-steered Search in Continuous Space for Postfix Expressions
Sep 24, 2023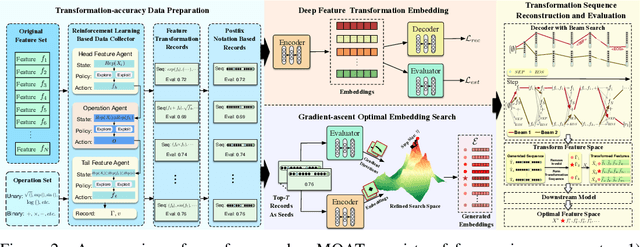
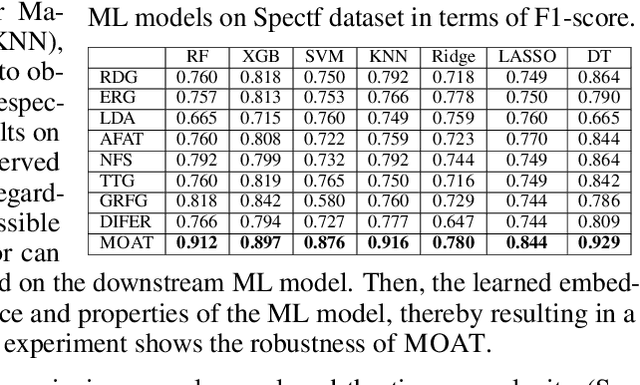
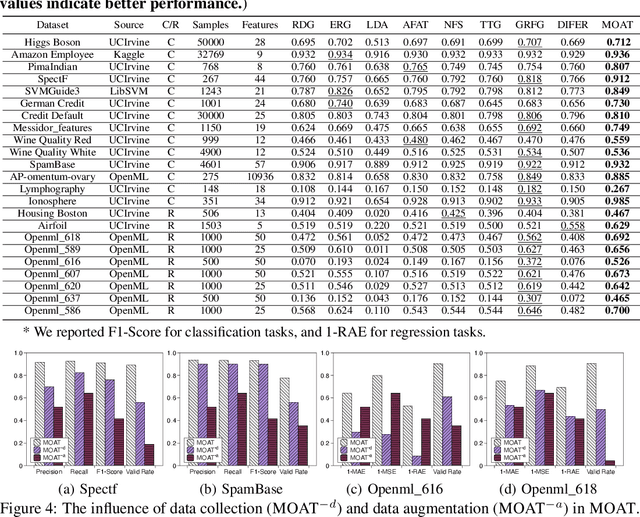

Feature transformation aims to generate new pattern-discriminative feature space from original features to improve downstream machine learning (ML) task performances. However, the discrete search space for the optimal feature explosively grows on the basis of combinations of features and operations from low-order forms to high-order forms. Existing methods, such as exhaustive search, expansion reduction, evolutionary algorithms, reinforcement learning, and iterative greedy, suffer from large search space. Overly emphasizing efficiency in algorithm design usually sacrifices stability or robustness. To fundamentally fill this gap, we reformulate discrete feature transformation as a continuous space optimization task and develop an embedding-optimization-reconstruction framework. This framework includes four steps: 1) reinforcement-enhanced data preparation, aiming to prepare high-quality transformation-accuracy training data; 2) feature transformation operation sequence embedding, intending to encapsulate the knowledge of prepared training data within a continuous space; 3) gradient-steered optimal embedding search, dedicating to uncover potentially superior embeddings within the learned space; 4) transformation operation sequence reconstruction, striving to reproduce the feature transformation solution to pinpoint the optimal feature space.
Self-optimizing Feature Generation via Categorical Hashing Representation and Hierarchical Reinforcement Crossing
Sep 14, 2023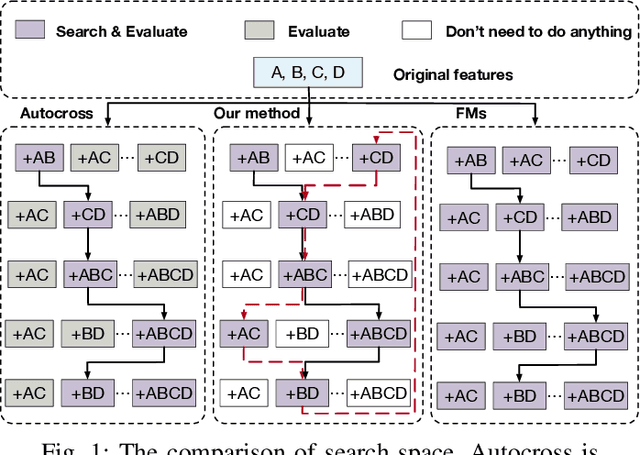

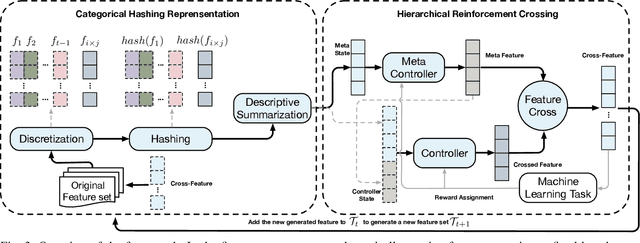
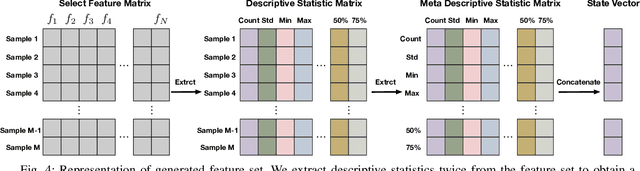
Feature generation aims to generate new and meaningful features to create a discriminative representation space.A generated feature is meaningful when the generated feature is from a feature pair with inherent feature interaction. In the real world, experienced data scientists can identify potentially useful feature-feature interactions, and generate meaningful dimensions from an exponentially large search space, in an optimal crossing form over an optimal generation path. But, machines have limited human-like abilities.We generalize such learning tasks as self-optimizing feature generation. Self-optimizing feature generation imposes several under-addressed challenges on existing systems: meaningful, robust, and efficient generation. To tackle these challenges, we propose a principled and generic representation-crossing framework to solve self-optimizing feature generation.To achieve hashing representation, we propose a three-step approach: feature discretization, feature hashing, and descriptive summarization. To achieve reinforcement crossing, we develop a hierarchical reinforcement feature crossing approach.We present extensive experimental results to demonstrate the effectiveness and efficiency of the proposed method. The code is available at https://github.com/yingwangyang/HRC_feature_cross.git.
Interdisciplinary Fairness in Imbalanced Research Proposal Topic Inference: A Hierarchical Transformer-based Method with Selective Interpolation
Sep 11, 2023
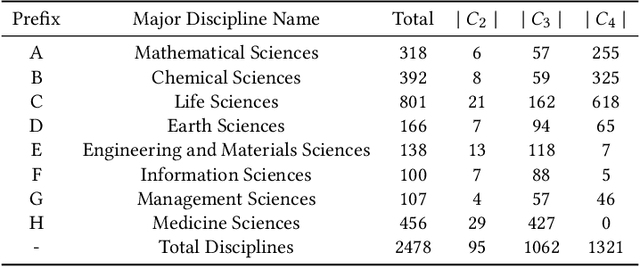

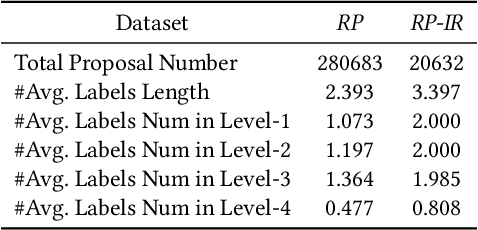
The objective of topic inference in research proposals aims to obtain the most suitable disciplinary division from the discipline system defined by a funding agency. The agency will subsequently find appropriate peer review experts from their database based on this division. Automated topic inference can reduce human errors caused by manual topic filling, bridge the knowledge gap between funding agencies and project applicants, and improve system efficiency. Existing methods focus on modeling this as a hierarchical multi-label classification problem, using generative models to iteratively infer the most appropriate topic information. However, these methods overlook the gap in scale between interdisciplinary research proposals and non-interdisciplinary ones, leading to an unjust phenomenon where the automated inference system categorizes interdisciplinary proposals as non-interdisciplinary, causing unfairness during the expert assignment. How can we address this data imbalance issue under a complex discipline system and hence resolve this unfairness? In this paper, we implement a topic label inference system based on a Transformer encoder-decoder architecture. Furthermore, we utilize interpolation techniques to create a series of pseudo-interdisciplinary proposals from non-interdisciplinary ones during training based on non-parametric indicators such as cross-topic probabilities and topic occurrence probabilities. This approach aims to reduce the bias of the system during model training. Finally, we conduct extensive experiments on a real-world dataset to verify the effectiveness of the proposed method. The experimental results demonstrate that our training strategy can significantly mitigate the unfairness generated in the topic inference task.
Traceable Group-Wise Self-Optimizing Feature Transformation Learning: A Dual Optimization Perspective
Jun 29, 2023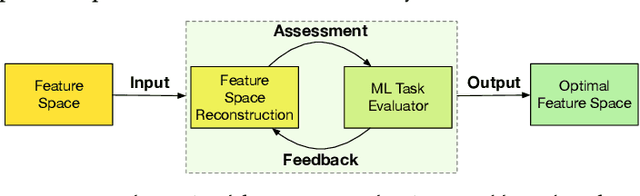
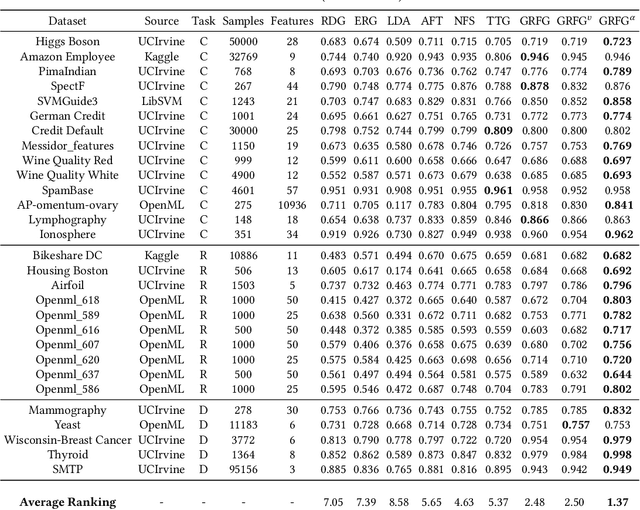
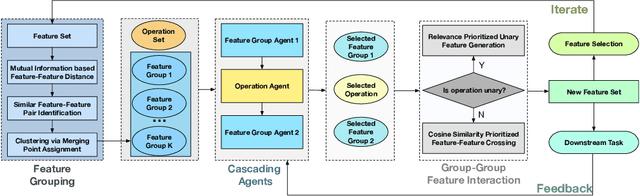
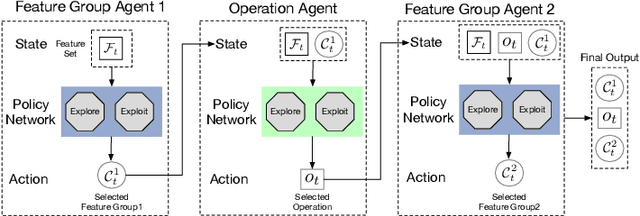
Feature transformation aims to reconstruct an effective representation space by mathematically refining the existing features. It serves as a pivotal approach to combat the curse of dimensionality, enhance model generalization, mitigate data sparsity, and extend the applicability of classical models. Existing research predominantly focuses on domain knowledge-based feature engineering or learning latent representations. However, these methods, while insightful, lack full automation and fail to yield a traceable and optimal representation space. An indispensable question arises: Can we concurrently address these limitations when reconstructing a feature space for a machine-learning task? Our initial work took a pioneering step towards this challenge by introducing a novel self-optimizing framework. This framework leverages the power of three cascading reinforced agents to automatically select candidate features and operations for generating improved feature transformation combinations. Despite the impressive strides made, there was room for enhancing its effectiveness and generalization capability. In this extended journal version, we advance our initial work from two distinct yet interconnected perspectives: 1) We propose a refinement of the original framework, which integrates a graph-based state representation method to capture the feature interactions more effectively and develop different Q-learning strategies to alleviate Q-value overestimation further. 2) We utilize a new optimization technique (actor-critic) to train the entire self-optimizing framework in order to accelerate the model convergence and improve the feature transformation performance. Finally, to validate the improved effectiveness and generalization capability of our framework, we perform extensive experiments and conduct comprehensive analyses.