 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuanchun Zhou
scCDCG: Efficient Deep Structural Clustering for single-cell RNA-seq via Deep Cut-informed Graph Embedding
Apr 09, 2024
Single-cell RNA sequencing (scRNA-seq) is essential for unraveling cellular heterogeneity and diversity, offering invaluable insights for bioinformatics advancements. Despite its potential, traditional clustering methods in scRNA-seq data analysis often neglect the structural information embedded in gene expression profiles, crucial for understanding cellular correlations and dependencies. Existing strategies, including graph neural networks, face challenges in handling the inefficiency due to scRNA-seq data's intrinsic high-dimension and high-sparsity. Addressing these limitations, we introduce scCDCG (single-cell RNA-seq Clustering via Deep Cut-informed Graph), a novel framework designed for efficient and accurate clustering of scRNA-seq data that simultaneously utilizes intercellular high-order structural information. scCDCG comprises three main components: (i) A graph embedding module utilizing deep cut-informed techniques, which effectively captures intercellular high-order structural information, overcoming the over-smoothing and inefficiency issues prevalent in prior graph neural network methods. (ii) A self-supervised learning module guided by optimal transport, tailored to accommodate the unique complexities of scRNA-seq data, specifically its high-dimension and high-sparsity. (iii) An autoencoder-based feature learning module that simplifies model complexity through effective dimension reduction and feature extraction. Our extensive experiments on 6 datasets demonstrate scCDCG's superior performance and efficiency compared to 7 established models, underscoring scCDCG's potential as a transformative tool in scRNA-seq data analysis. Our code is available at: https://github.com/XPgogogo/scCDCG.
COMAE: COMprehensive Attribute Exploration for Zero-shot Hashing
Feb 26, 2024Zero-shot hashing (ZSH) has shown excellent success owing to its efficiency and generalization in large-scale retrieval scenarios. While considerable success has been achieved, there still exist urgent limitations. Existing works ignore the locality relationships of representations and attributes, which have effective transferability between seeable classes and unseeable classes. Also, the continuous-value attributes are not fully harnessed. In response, we conduct a COMprehensive Attribute Exploration for ZSH, named COMAE, which depicts the relationships from seen classes to unseen ones through three meticulously designed explorations, i.e., point-wise, pair-wise and class-wise consistency constraints. By regressing attributes from the proposed attribute prototype network, COMAE learns the local features that are relevant to the visual attributes. Then COMAE utilizes contrastive learning to comprehensively depict the context of attributes, rather than instance-independent optimization. Finally, the class-wise constraint is designed to cohesively learn the hash code, image representation, and visual attributes more effectively. Experimental results on the popular ZSH datasets demonstrate that COMAE outperforms state-of-the-art hashing techniques, especially in scenarios with a larger number of unseen label classes.
scInterpreter: Training Large Language Models to Interpret scRNA-seq Data for Cell Type Annotation
Feb 18, 2024Despite the inherent limitations of existing Large Language Models in directly reading and interpreting single-cell omics data, they demonstrate significant potential and flexibility as the Foundation Model. This research focuses on how to train and adapt the Large Language Model with the capability to interpret and distinguish cell types in single-cell RNA sequencing data. Our preliminary research results indicate that these foundational models excel in accurately categorizing known cell types, demonstrating the potential of the Large Language Models as effective tools for uncovering new biological insights.
Unveiling Delay Effects in Traffic Forecasting: A Perspective from Spatial-Temporal Delay Differential Equations
Feb 02, 2024Traffic flow forecasting is a fundamental research issue for transportation planning and management, which serves as a canonical and typical example of spatial-temporal predictions. In recent years, Graph Neural Networks (GNNs) and Recurrent Neural Networks (RNNs) have achieved great success in capturing spatial-temporal correlations for traffic flow forecasting. Yet, two non-ignorable issues haven't been well solved: 1) The message passing in GNNs is immediate, while in reality the spatial message interactions among neighboring nodes can be delayed. The change of traffic flow at one node will take several minutes, i.e., time delay, to influence its connected neighbors. 2) Traffic conditions undergo continuous changes. The prediction frequency for traffic flow forecasting may vary based on specific scenario requirements. Most existing discretized models require retraining for each prediction horizon, restricting their applicability. To tackle the above issues, we propose a neural Spatial-Temporal Delay Differential Equation model, namely STDDE. It includes both delay effects and continuity into a unified delay differential equation framework, which explicitly models the time delay in spatial information propagation. Furthermore, theoretical proofs are provided to show its stability. Then we design a learnable traffic-graph time-delay estimator, which utilizes the continuity of the hidden states to achieve the gradient backward process. Finally, we propose a continuous output module, allowing us to accurately predict traffic flow at various frequencies, which provides more flexibility and adaptability to different scenarios. Extensive experiments show the superiority of the proposed STDDE along with competitive computational efficiency.
Resolving the Imbalance Issue in Hierarchical Disciplinary Topic Inference via LLM-based Data Augmentation
Oct 15, 2023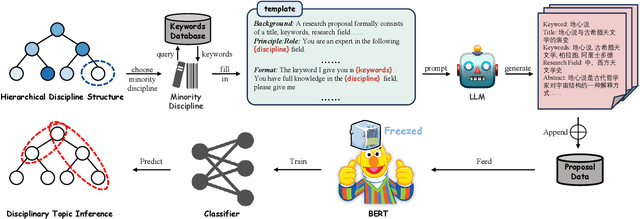

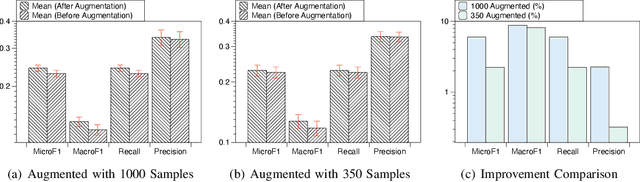
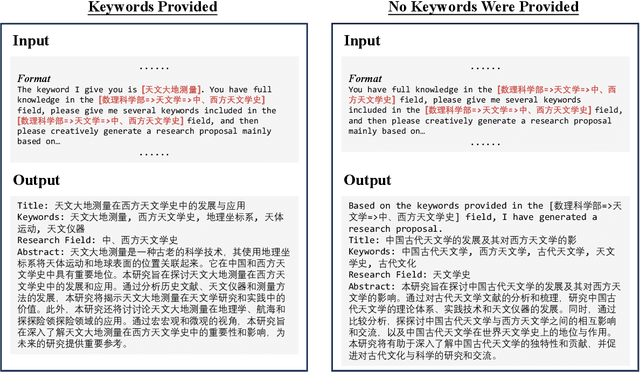
In addressing the imbalanced issue of data within the realm of Natural Language Processing, text data augmentation methods have emerged as pivotal solutions. This data imbalance is prevalent in the research proposals submitted during the funding application process. Such imbalances, resulting from the varying popularity of disciplines or the emergence of interdisciplinary studies, significantly impede the precision of downstream topic models that deduce the affiliated disciplines of these proposals. At the data level, proposals penned by experts and scientists are inherently complex technological texts, replete with intricate terminologies, which augmenting such specialized text data poses unique challenges. At the system level, this, in turn, compromises the fairness of AI-assisted reviewer assignment systems, which raises a spotlight on solving this issue. This study leverages large language models (Llama V1) as data generators to augment research proposals categorized within intricate disciplinary hierarchies, aiming to rectify data imbalances and enhance the equity of expert assignments. We first sample within the hierarchical structure to find the under-represented class. Then we designed a prompt for keyword-based research proposal generation. Our experiments attests to the efficacy of the generated data, demonstrating that research proposals produced using the prompts can effectively address the aforementioned issues and generate high quality scientific text data, thus help the model overcome the imbalanced issue.
Reinforcement-Enhanced Autoregressive Feature Transformation: Gradient-steered Search in Continuous Space for Postfix Expressions
Sep 24, 2023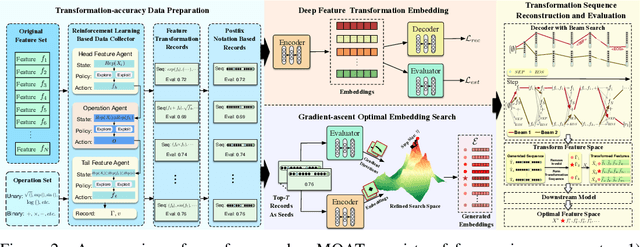
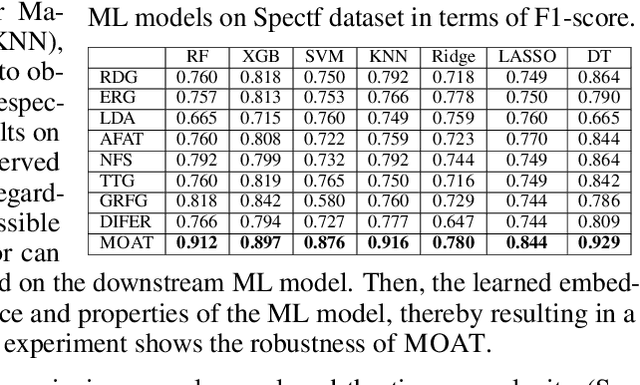

Feature transformation aims to generate new pattern-discriminative feature space from original features to improve downstream machine learning (ML) task performances. However, the discrete search space for the optimal feature explosively grows on the basis of combinations of features and operations from low-order forms to high-order forms. Existing methods, such as exhaustive search, expansion reduction, evolutionary algorithms, reinforcement learning, and iterative greedy, suffer from large search space. Overly emphasizing efficiency in algorithm design usually sacrifices stability or robustness. To fundamentally fill this gap, we reformulate discrete feature transformation as a continuous space optimization task and develop an embedding-optimization-reconstruction framework. This framework includes four steps: 1) reinforcement-enhanced data preparation, aiming to prepare high-quality transformation-accuracy training data; 2) feature transformation operation sequence embedding, intending to encapsulate the knowledge of prepared training data within a continuous space; 3) gradient-steered optimal embedding search, dedicating to uncover potentially superior embeddings within the learned space; 4) transformation operation sequence reconstruction, striving to reproduce the feature transformation solution to pinpoint the optimal feature space.
Semi-supervised Domain Adaptation in Graph Transfer Learning
Sep 19, 2023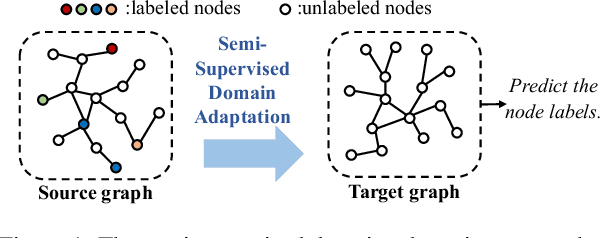
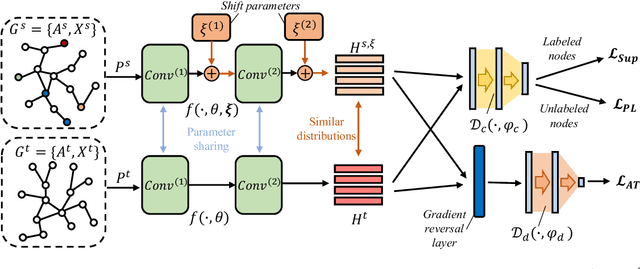
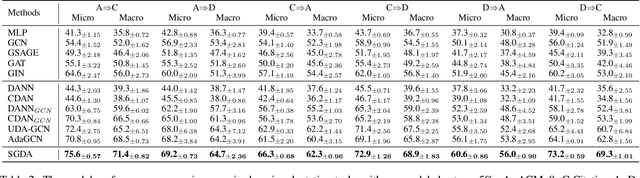
As a specific case of graph transfer learning, unsupervised domain adaptation on graphs aims for knowledge transfer from label-rich source graphs to unlabeled target graphs. However, graphs with topology and attributes usually have considerable cross-domain disparity and there are numerous real-world scenarios where merely a subset of nodes are labeled in the source graph. This imposes critical challenges on graph transfer learning due to serious domain shifts and label scarcity. To address these challenges, we propose a method named Semi-supervised Graph Domain Adaptation (SGDA). To deal with the domain shift, we add adaptive shift parameters to each of the source nodes, which are trained in an adversarial manner to align the cross-domain distributions of node embedding, thus the node classifier trained on labeled source nodes can be transferred to the target nodes. Moreover, to address the label scarcity, we propose pseudo-labeling on unlabeled nodes, which improves classification on the target graph via measuring the posterior influence of nodes based on their relative position to the class centroids. Finally, extensive experiments on a range of publicly accessible datasets validate the effectiveness of our proposed SGDA in different experimental settings.
Interdisciplinary Fairness in Imbalanced Research Proposal Topic Inference: A Hierarchical Transformer-based Method with Selective Interpolation
Sep 11, 2023
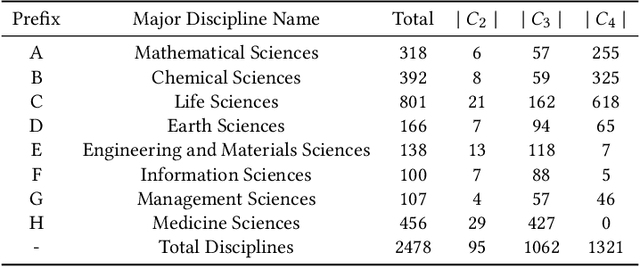

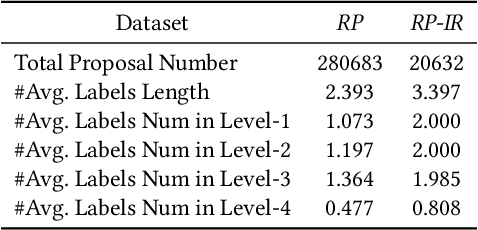
The objective of topic inference in research proposals aims to obtain the most suitable disciplinary division from the discipline system defined by a funding agency. The agency will subsequently find appropriate peer review experts from their database based on this division. Automated topic inference can reduce human errors caused by manual topic filling, bridge the knowledge gap between funding agencies and project applicants, and improve system efficiency. Existing methods focus on modeling this as a hierarchical multi-label classification problem, using generative models to iteratively infer the most appropriate topic information. However, these methods overlook the gap in scale between interdisciplinary research proposals and non-interdisciplinary ones, leading to an unjust phenomenon where the automated inference system categorizes interdisciplinary proposals as non-interdisciplinary, causing unfairness during the expert assignment. How can we address this data imbalance issue under a complex discipline system and hence resolve this unfairness? In this paper, we implement a topic label inference system based on a Transformer encoder-decoder architecture. Furthermore, we utilize interpolation techniques to create a series of pseudo-interdisciplinary proposals from non-interdisciplinary ones during training based on non-parametric indicators such as cross-topic probabilities and topic occurrence probabilities. This approach aims to reduce the bias of the system during model training. Finally, we conduct extensive experiments on a real-world dataset to verify the effectiveness of the proposed method. The experimental results demonstrate that our training strategy can significantly mitigate the unfairness generated in the topic inference task.
Temporal Inductive Path Neural Network for Temporal Knowledge Graph Reasoning
Sep 06, 2023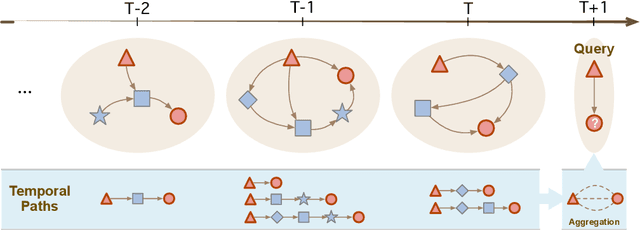

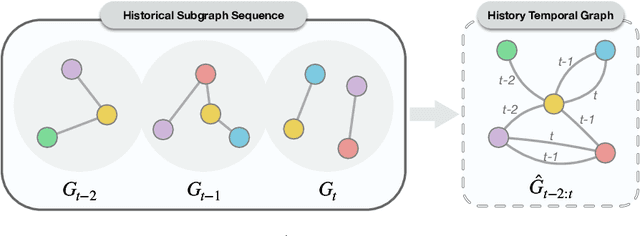
Temporal Knowledge Graph (TKG) is an extension of traditional Knowledge Graph (KG) that incorporates the dimension of time. Reasoning on TKGs is a crucial task that aims to predict future facts based on historical occurrences. The key challenge lies in uncovering structural dependencies within historical subgraphs and temporal patterns. Most existing approaches model TKGs relying on entity modeling, as nodes in the graph play a crucial role in knowledge representation. However, the real-world scenario often involves an extensive number of entities, with new entities emerging over time. This makes it challenging for entity-dependent methods to cope with extensive volumes of entities, and effectively handling newly emerging entities also becomes a significant challenge. Therefore, we propose Temporal Inductive Path Neural Network (TiPNN), which models historical information in an entity-independent perspective. Specifically, TiPNN adopts a unified graph, namely history temporal graph, to comprehensively capture and encapsulate information from history. Subsequently, we utilize the defined query-aware temporal paths to model historical path information related to queries on history temporal graph for the reasoning. Extensive experiments illustrate that the proposed model not only attains significant performance enhancements but also handles inductive settings, while additionally facilitating the provision of reasoning evidence through history temporal graphs.
Traceable Group-Wise Self-Optimizing Feature Transformation Learning: A Dual Optimization Perspective
Jun 29, 2023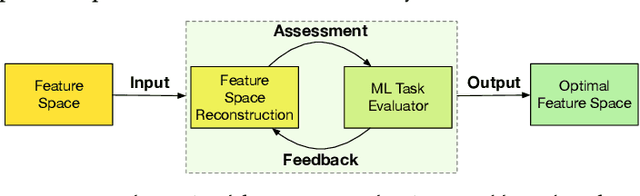
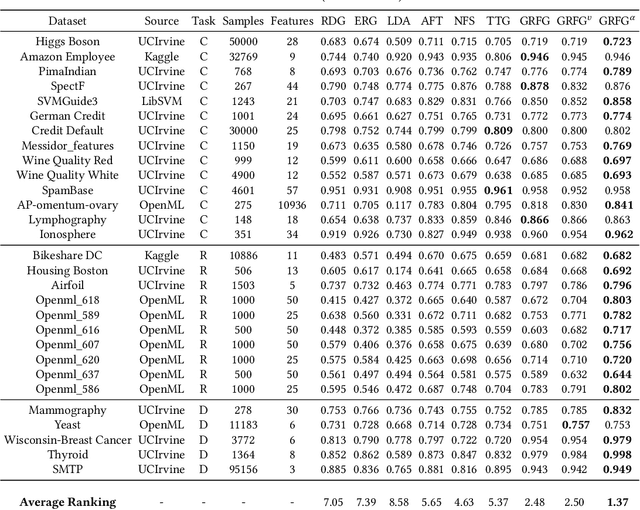
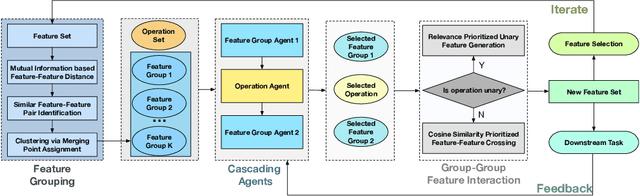
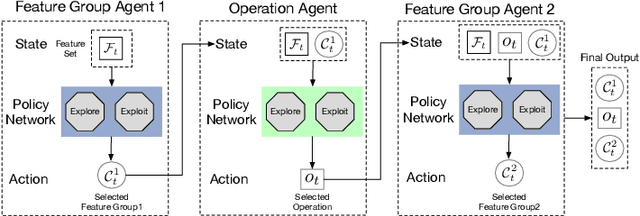
Feature transformation aims to reconstruct an effective representation space by mathematically refining the existing features. It serves as a pivotal approach to combat the curse of dimensionality, enhance model generalization, mitigate data sparsity, and extend the applicability of classical models. Existing research predominantly focuses on domain knowledge-based feature engineering or learning latent representations. However, these methods, while insightful, lack full automation and fail to yield a traceable and optimal representation space. An indispensable question arises: Can we concurrently address these limitations when reconstructing a feature space for a machine-learning task? Our initial work took a pioneering step towards this challenge by introducing a novel self-optimizing framework. This framework leverages the power of three cascading reinforced agents to automatically select candidate features and operations for generating improved feature transformation combinations. Despite the impressive strides made, there was room for enhancing its effectiveness and generalization capability. In this extended journal version, we advance our initial work from two distinct yet interconnected perspectives: 1) We propose a refinement of the original framework, which integrates a graph-based state representation method to capture the feature interactions more effectively and develop different Q-learning strategies to alleviate Q-value overestimation further. 2) We utilize a new optimization technique (actor-critic) to train the entire self-optimizing framework in order to accelerate the model convergence and improve the feature transformation performance. Finally, to validate the improved effectiveness and generalization capability of our framework, we perform extensive experiments and conduct comprehensive analyses.