 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuqi Li
BatteryML:An Open-source platform for Machine Learning on Battery Degradation
Oct 23, 2023
Battery degradation remains a pivotal concern in the energy storage domain, with machine learning emerging as a potent tool to drive forward insights and solutions. However, this intersection of electrochemical science and machine learning poses complex challenges. Machine learning experts often grapple with the intricacies of battery science, while battery researchers face hurdles in adapting intricate models tailored to specific datasets. Beyond this, a cohesive standard for battery degradation modeling, inclusive of data formats and evaluative benchmarks, is conspicuously absent. Recognizing these impediments, we present BatteryML - a one-step, all-encompass, and open-source platform designed to unify data preprocessing, feature extraction, and the implementation of both traditional and state-of-the-art models. This streamlined approach promises to enhance the practicality and efficiency of research applications. BatteryML seeks to fill this void, fostering an environment where experts from diverse specializations can collaboratively contribute, thus elevating the collective understanding and advancement of battery research.The code for our project is publicly available on GitHub at https://github.com/microsoft/BatteryML.
Learning Intra- and Inter-Cell Differences for Accurate Battery Lifespan Prediction across Diverse Conditions
Oct 11, 2023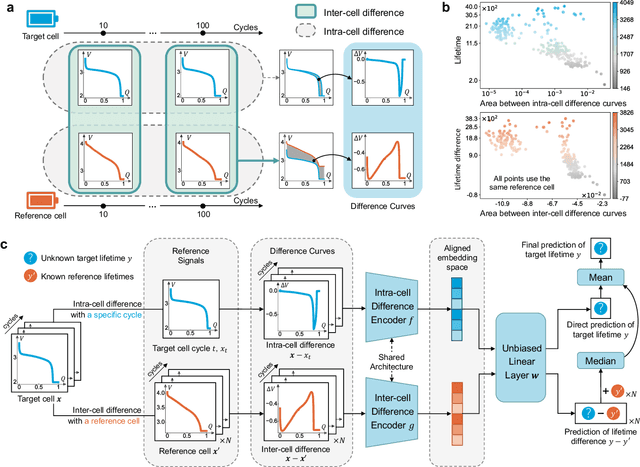
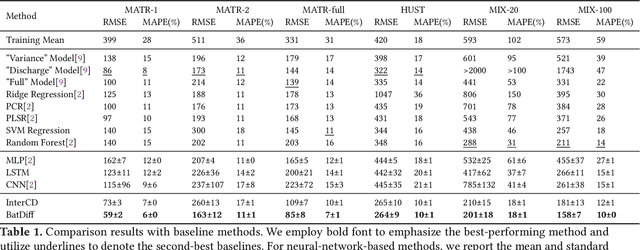
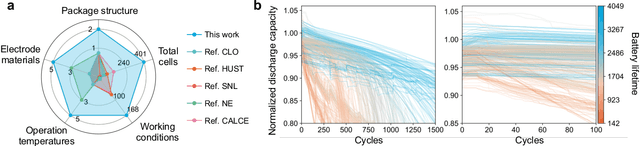
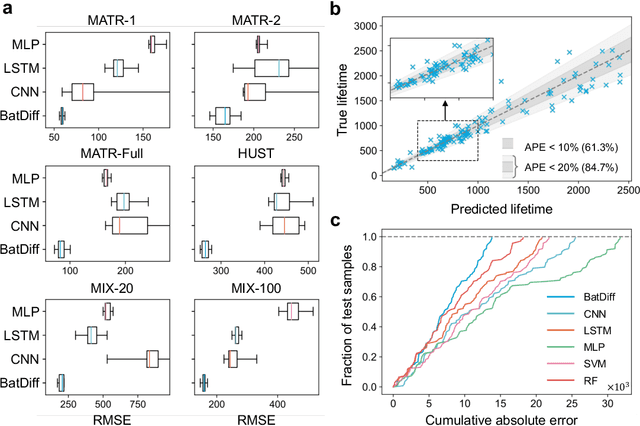
Battery life prediction holds significant practical value for battery research and development. Currently, many data-driven models rely on early electrical signals from specific target batteries to predict their lifespan. A common shortfall is that most existing methods are developed based on specific aging conditions, which not only limits their model's capability but also diminishes their effectiveness in predicting degradation under varied conditions. As a result, these models often miss out on fully benefiting from the rich historical data available under other conditions. Here, to address above, we introduce an approach that explicitly captures differences between electrical signals of a target battery and a reference battery, irrespective of their materials and aging conditions, to forecast the target battery life. Through this inter-cell difference, we not only enhance the feature space but also pave the way for a universal battery life prediction framework. Remarkably, our model that combines the inter- and intra-cell differences shines across diverse conditions, standing out in its efficiency and accuracy using all accessible datasets. An essential application of our approach is its capability to leverage data from older batteries effectively, enabling newer batteries to capitalize on insights gained from past batteries. This work not only enriches the battery data utilization strategy but also sets the stage for smarter battery management system in the future.
Team AcieLee: Technical Report for EPIC-SOUNDS Audio-Based Interaction Recognition Challenge 2023
Jun 15, 2023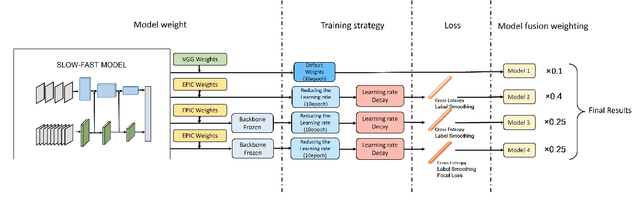

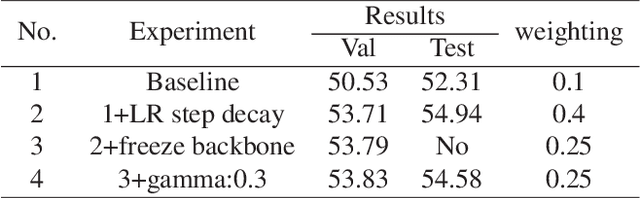
In this report, we describe the technical details of our submission to the EPIC-SOUNDS Audio-Based Interaction Recognition Challenge 2023, by Team "AcieLee" (username: Yuqi\_Li). The task is to classify the audio caused by interactions between objects, or from events of the camera wearer. We conducted exhaustive experiments and found learning rate step decay, backbone frozen, label smoothing and focal loss contribute most to the performance improvement. After training, we combined multiple models from different stages and integrated them into a single model by assigning fusion weights. This proposed method allowed us to achieve 3rd place in the CVPR 2023 workshop of EPIC-SOUNDS Audio-Based Interaction Recognition Challenge.
Yield Evaluation of Citrus Fruits based on the YoloV5 compressed by Knowledge Distillation
Nov 16, 2022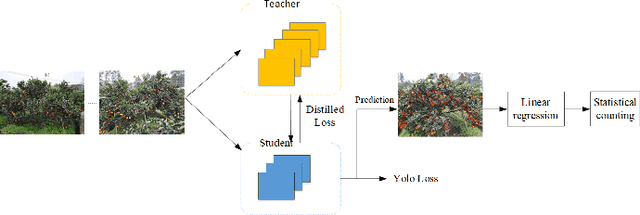
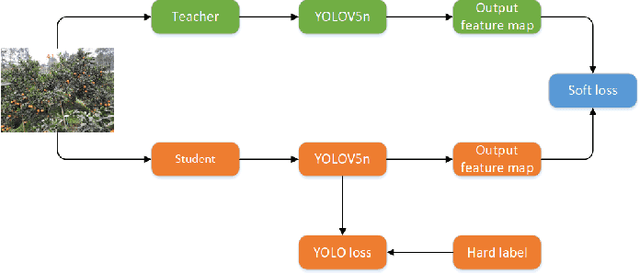


In the field of planting fruit trees, pre-harvest estimation of fruit yield is important for fruit storage and price evaluation. However, considering the cost, the yield of each tree cannot be assessed by directly picking the immature fruit. Therefore, the problem is a very difficult task. In this paper, a fruit counting and yield assessment method based on computer vision is proposed for citrus fruit trees as an example. Firstly, images of single fruit trees from different angles are acquired and the number of fruits is detected using a deep Convolutional Neural Network model YOLOv5, and the model is compressed using a knowledge distillation method. Then, a linear regression method is used to model yield-related features and evaluate yield. Experiments show that the proposed method can accurately count fruits and approximate the yield.
ISP-Agnostic Image Reconstruction for Under-Display Cameras
Nov 02, 2021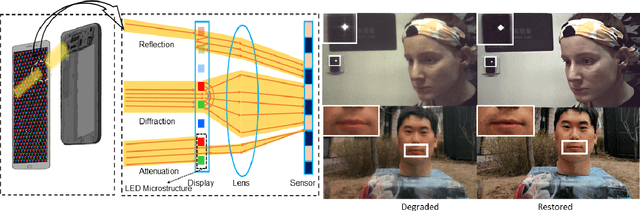

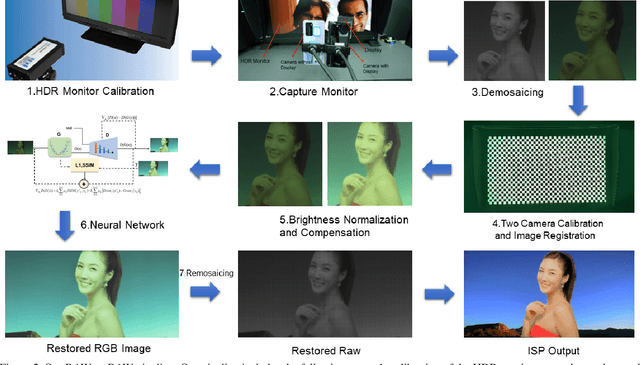
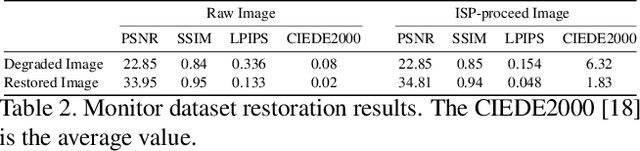
Under-display cameras have been proposed in recent years as a way to reduce the form factor of mobile devices while maximizing the screen area. Unfortunately, placing the camera behind the screen results in significant image distortions, including loss of contrast, blur, noise, color shift, scattering artifacts, and reduced light sensitivity. In this paper, we propose an image-restoration pipeline that is ISP-agnostic, i.e. it can be combined with any legacy ISP to produce a final image that matches the appearance of regular cameras using the same ISP. This is achieved with a deep learning approach that performs a RAW-to-RAW image restoration. To obtain large quantities of real under-display camera training data with sufficient contrast and scene diversity, we furthermore develop a data capture method utilizing an HDR monitor, as well as a data augmentation method to generate suitable HDR content. The monitor data is supplemented with real-world data that has less scene diversity but allows us to achieve fine detail recovery without being limited by the monitor resolution. Together, this approach successfully restores color and contrast as well as image detail.
End-to-End Hyperspectral-Depth Imaging with Learned Diffractive Optics
Sep 01, 2020
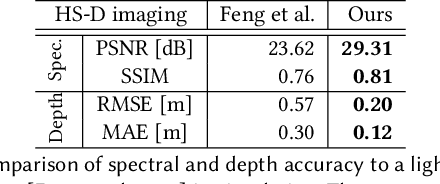
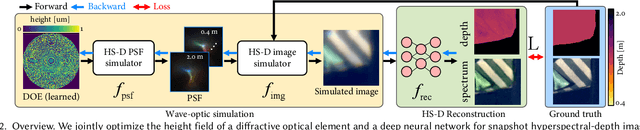
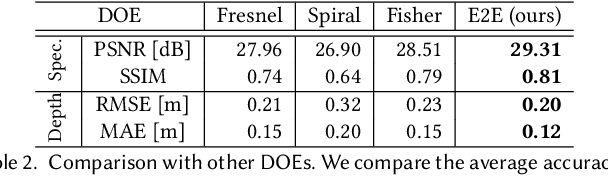
To extend the capabilities of spectral imaging, hyperspectral and depth imaging have been combined to capture the higher-dimensional visual information. However, the form factor of the combined imaging systems increases, limiting the applicability of this new technology. In this work, we propose a monocular imaging system for simultaneously capturing hyperspectral-depth (HS-D) scene information with an optimized diffractive optical element (DOE). In the training phase, this DOE is optimized jointly with a convolutional neural network to estimate HS-D data from a snapshot input. To study natural image statistics of this high-dimensional visual data and to enable such a machine learning-based DOE training procedure, we record two HS-D datasets. One is used for end-to-end optimization in deep optical HS-D imaging, and the other is used for enhancing reconstruction performance with a real-DOE prototype. The optimized DOE is fabricated with a grayscale lithography process and inserted into a portable HS-D camera prototype, which is shown to robustly capture HS-D information. In extensive evaluations, we demonstrate that our deep optical imaging system achieves state-of-the-art results for HS-D imaging and that the optimized DOE outperforms alternative optical designs.
A Set-Theoretic Study of the Relationships of Image Models and Priors for Restoration Problems
Mar 29, 2020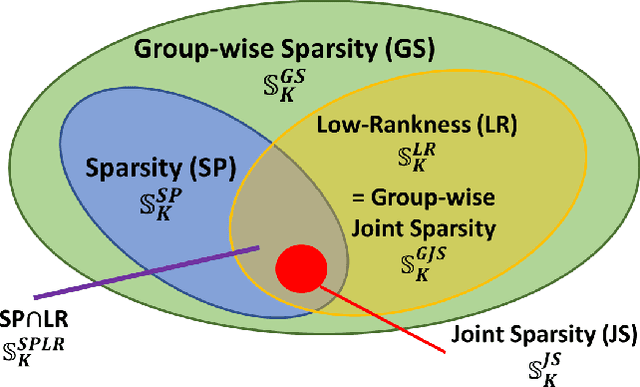
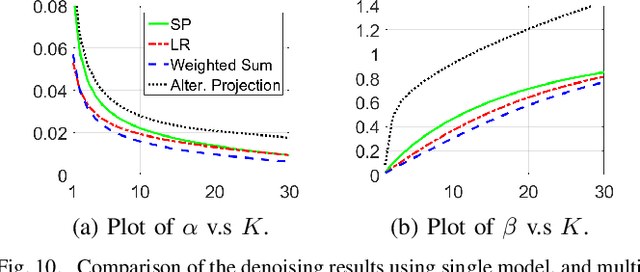
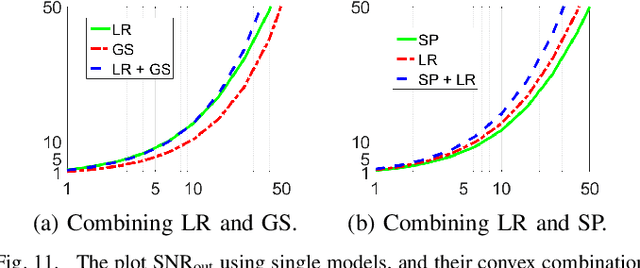

Image prior modeling is the key issue in image recovery, computational imaging, compresses sensing, and other inverse problems. Recent algorithms combining multiple effective priors such as the sparse or low-rank models, have demonstrated superior performance in various applications. However, the relationships among the popular image models are unclear, and no theory in general is available to demonstrate their connections. In this paper, we present a theoretical analysis on the image models, to bridge the gap between applications and image prior understanding, including sparsity, group-wise sparsity, joint sparsity, and low-rankness, etc. We systematically study how effective each image model is for image restoration. Furthermore, we relate the denoising performance improvement by combining multiple models, to the image model relationships. Extensive experiments are conducted to compare the denoising results which are consistent with our analysis. On top of the model-based methods, we quantitatively demonstrate the image properties that are inexplicitly exploited by deep learning method, of which can further boost the denoising performance by combining with its complementary image models.
Short-Term Temporal Convolutional Networks for Dynamic Hand Gesture Recognition
Dec 31, 2019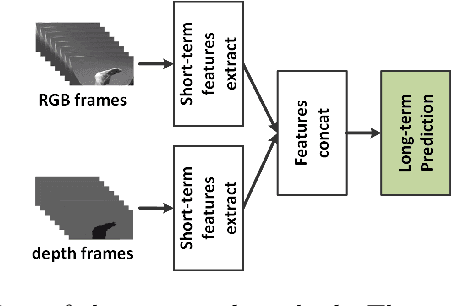
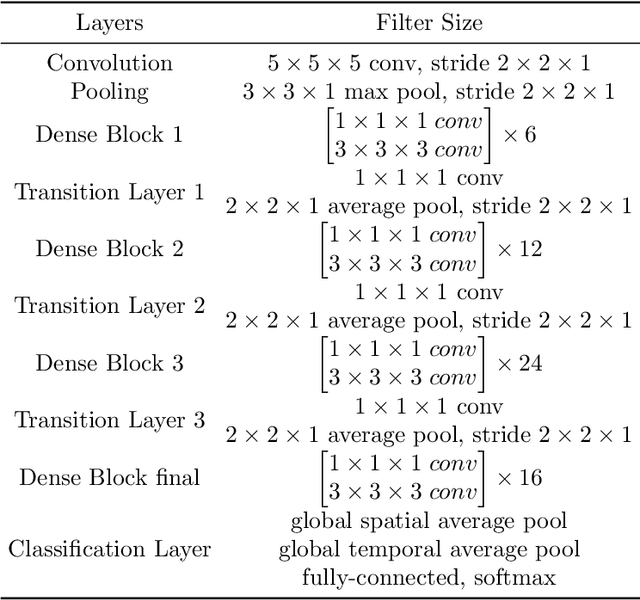
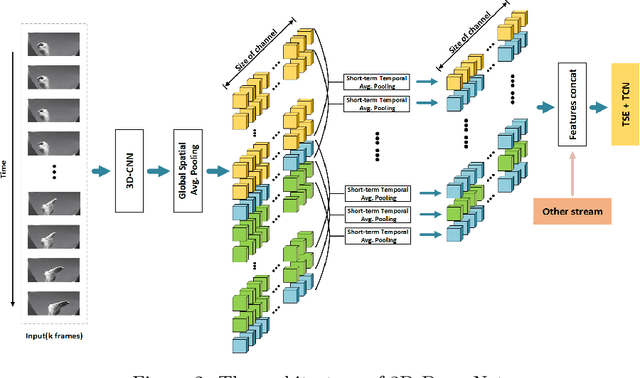

The purpose of gesture recognition is to recognize meaningful movements of human bodies, and gesture recognition is an important issue in computer vision. In this paper, we present a multimodal gesture recognition method based on 3D densely convolutional networks (3D-DenseNets) and improved temporal convolutional networks (TCNs). The key idea of our approach is to find a compact and effective representation of spatial and temporal features, which orderly and separately divide task of gesture video analysis into two parts: spatial analysis and temporal analysis. In spatial analysis, we adopt 3D-DenseNets to learn short-term spatio-temporal features effectively. Subsequently, in temporal analysis, we use TCNs to extract temporal features and employ improved Squeeze-and-Excitation Networks (SENets) to strengthen the representational power of temporal features from each TCNs' layers. The method has been evaluated on the VIVA and the NVIDIA Gesture Dynamic Hand Gesture Datasets. Our approach obtains very competitive performance on VIVA benchmarks with the classification accuracies of 91.54%, and achieve state-of-the art performance with 86.37% accuracy on NVIDIA benchmark.
GAN-based Projector for Faster Recovery in Compressed Sensing with Convergence Guarantees
Feb 26, 2019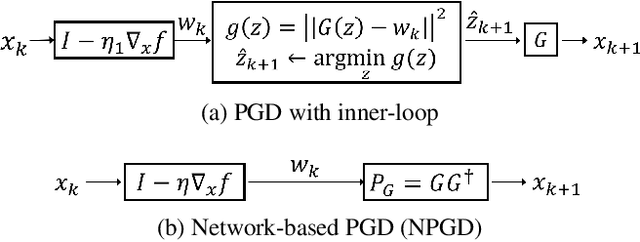
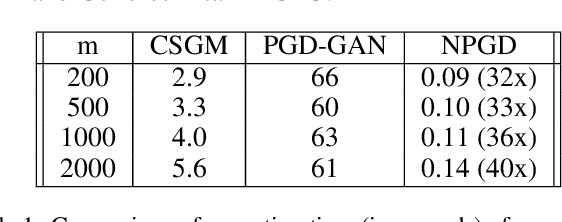
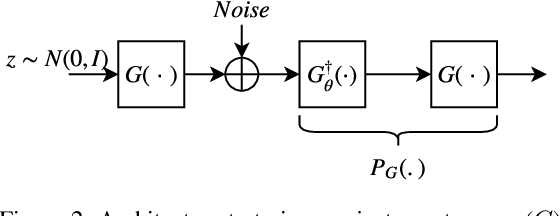
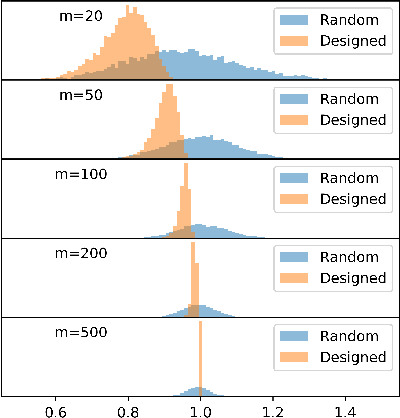
A Generative Adversarial Network (GAN) with generator $G$ trained to model the prior of images has been shown to perform better than sparsity-based regularizers in ill-posed inverse problems. In this work, we propose a new method of deploying a GAN-based prior to solve linear inverse problems using projected gradient descent (PGD). Our method learns a network-based projector for use in the PGD algorithm, eliminating the need for expensive computation of the Jacobian of $G$. Experiments show that our approach provides a speed-up of $30\text{-}40\times$ over earlier GAN-based recovery methods for similar accuracy in compressed sensing. Our main theoretical result is that if the measurement matrix is moderately conditioned for range($G$) and the projector is $\delta$-approximate, then the algorithm is guaranteed to reach $O(\delta)$ reconstruction error in $O(log(1/\delta))$ steps in the low noise regime. Additionally, we propose a fast method to design such measurement matrices for a given $G$. Extensive experiments demonstrate the efficacy of this method by requiring $5\text{-}10\times$ fewer measurements than random Gaussian measurement matrices for comparable recovery performance.
Temporal Bilinear Networks for Video Action Recognition
Nov 25, 2018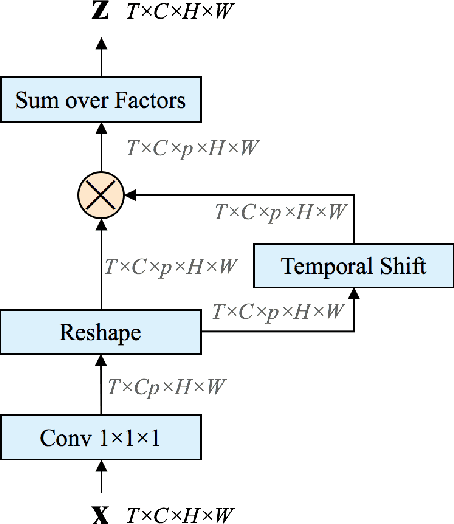

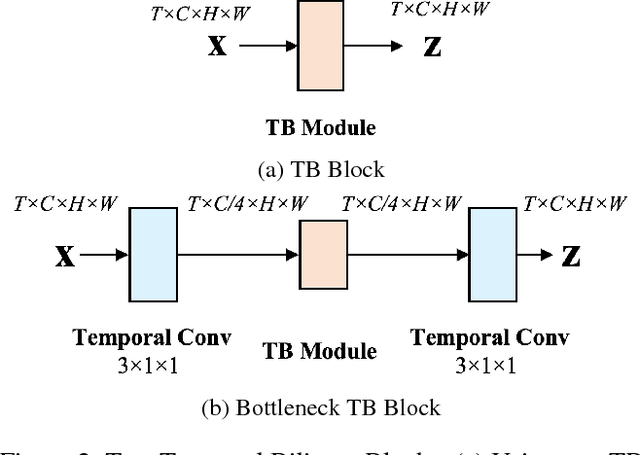

Temporal modeling in videos is a fundamental yet challenging problem in computer vision. In this paper, we propose a novel Temporal Bilinear (TB) model to capture the temporal pairwise feature interactions between adjacent frames. Compared with some existing temporal methods which are limited in linear transformations, our TB model considers explicit quadratic bilinear transformations in the temporal domain for motion evolution and sequential relation modeling. We further leverage the factorized bilinear model in linear complexity and a bottleneck network design to build our TB blocks, which also constrains the parameters and computation cost. We consider two schemes in terms of the incorporation of TB blocks and the original 2D spatial convolutions, namely wide and deep Temporal Bilinear Networks (TBN). Finally, we perform experiments on several widely adopted datasets including Kinetics, UCF101 and HMDB51. The effectiveness of our TBNs is validated by comprehensive ablation analyses and comparisons with various state-of-the-art methods.