 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChong Wang
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Mar 22, 2024

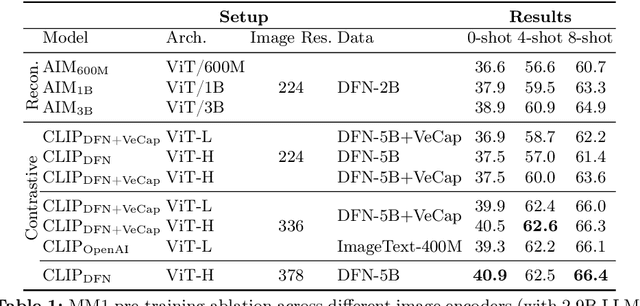
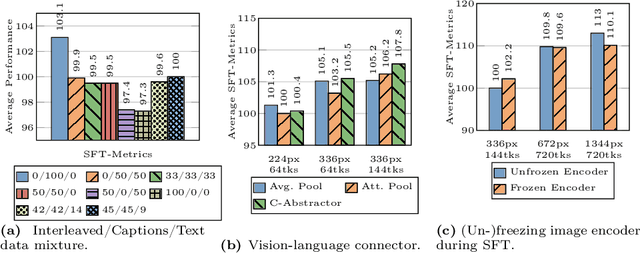
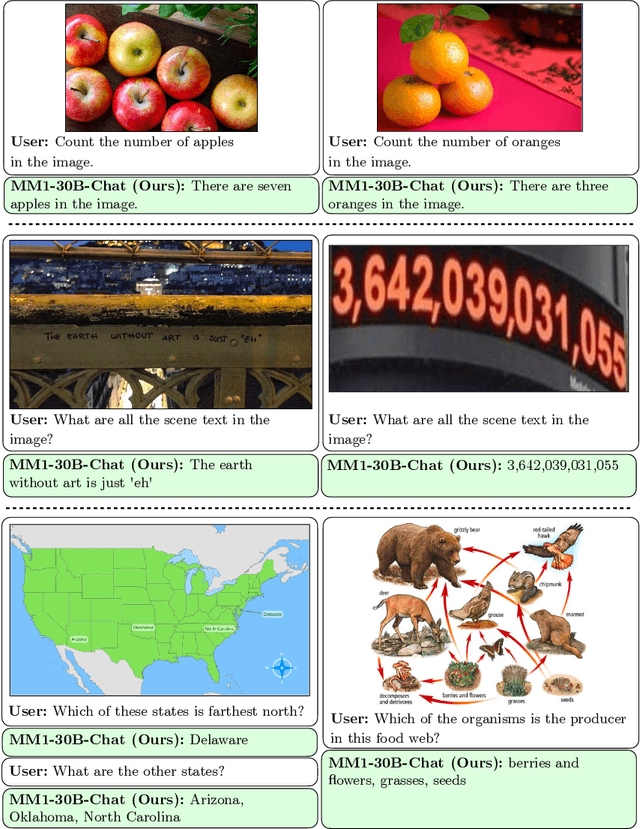
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
Recurrent Drafter for Fast Speculative Decoding in Large Language Models
Mar 22, 2024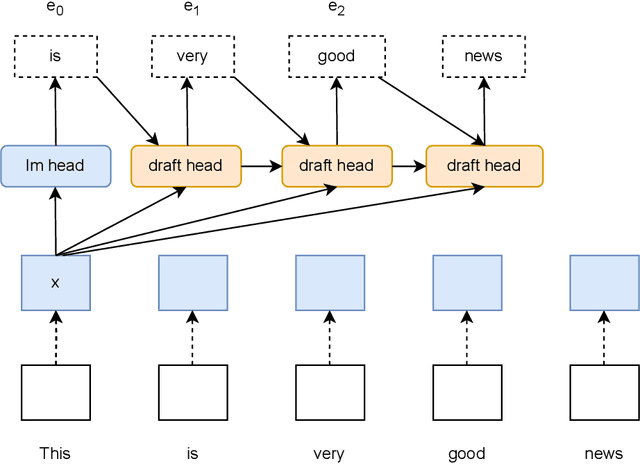
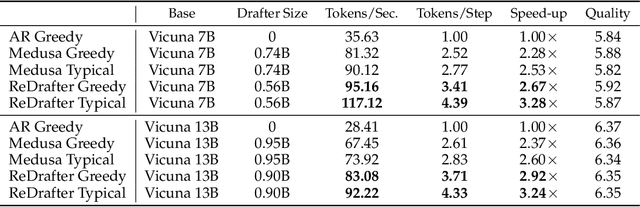
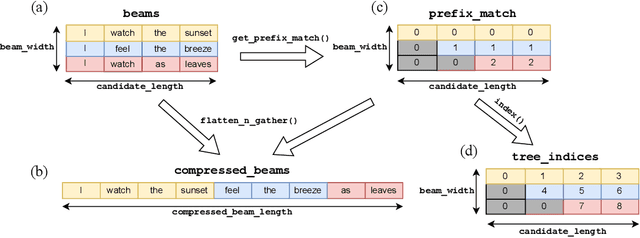
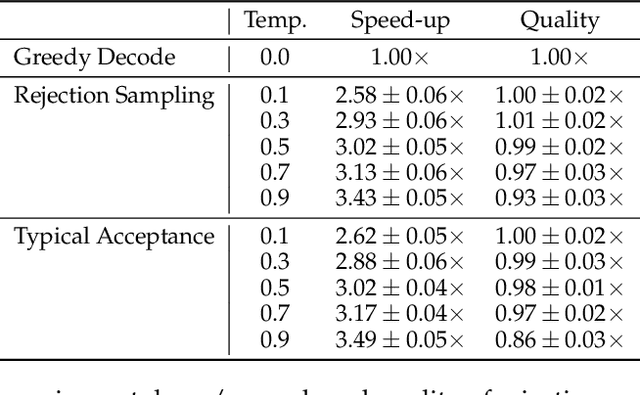
In this paper, we introduce an improved approach of speculative decoding aimed at enhancing the efficiency of serving large language models. Our method capitalizes on the strengths of two established techniques: the classic two-model speculative decoding approach, and the more recent single-model approach, Medusa. Drawing inspiration from Medusa, our approach adopts a single-model strategy for speculative decoding. However, our method distinguishes itself by employing a single, lightweight draft head with a recurrent dependency design, akin in essence to the small, draft model uses in classic speculative decoding, but without the complexities of the full transformer architecture. And because of the recurrent dependency, we can use beam search to swiftly filter out undesired candidates with the draft head. The outcome is a method that combines the simplicity of single-model design and avoids the need to create a data-dependent tree attention structure only for inference in Medusa. We empirically demonstrate the effectiveness of the proposed method on several popular open source language models, along with a comprehensive analysis of the trade-offs involved in adopting this approach.
Benchmarking Adversarial Robustness of Image Shadow Removal with Shadow-adaptive Attacks
Mar 15, 2024
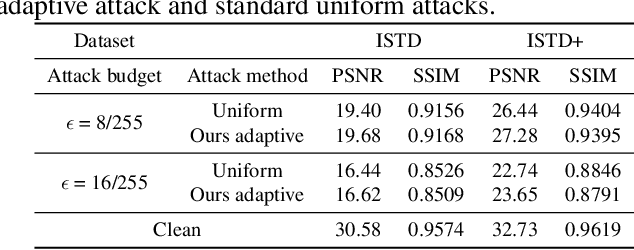
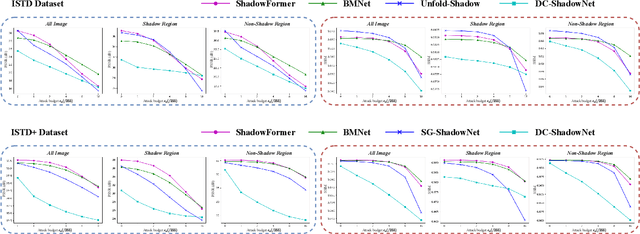

Shadow removal is a task aimed at erasing regional shadows present in images and reinstating visually pleasing natural scenes with consistent illumination. While recent deep learning techniques have demonstrated impressive performance in image shadow removal, their robustness against adversarial attacks remains largely unexplored. Furthermore, many existing attack frameworks typically allocate a uniform budget for perturbations across the entire input image, which may not be suitable for attacking shadow images. This is primarily due to the unique characteristic of spatially varying illumination within shadow images. In this paper, we propose a novel approach, called shadow-adaptive adversarial attack. Different from standard adversarial attacks, our attack budget is adjusted based on the pixel intensity in different regions of shadow images. Consequently, the optimized adversarial noise in the shadowed regions becomes visually less perceptible while permitting a greater tolerance for perturbations in non-shadow regions. The proposed shadow-adaptive attacks naturally align with the varying illumination distribution in shadow images, resulting in perturbations that are less conspicuous. Building on this, we conduct a comprehensive empirical evaluation of existing shadow removal methods, subjecting them to various levels of attack on publicly available datasets.
Progressive Divide-and-Conquer via Subsampling Decomposition for Accelerated MRI
Mar 15, 2024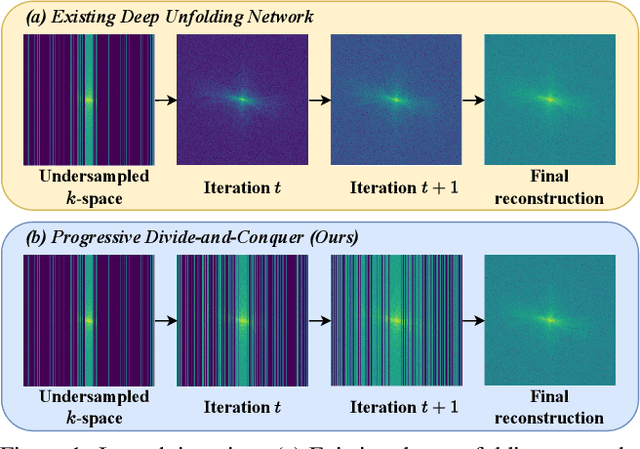
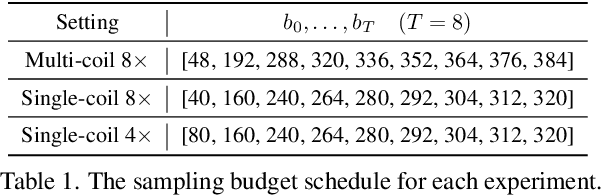
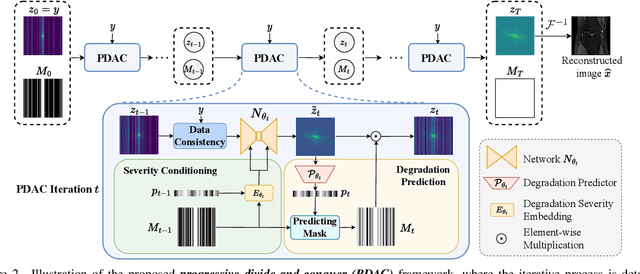
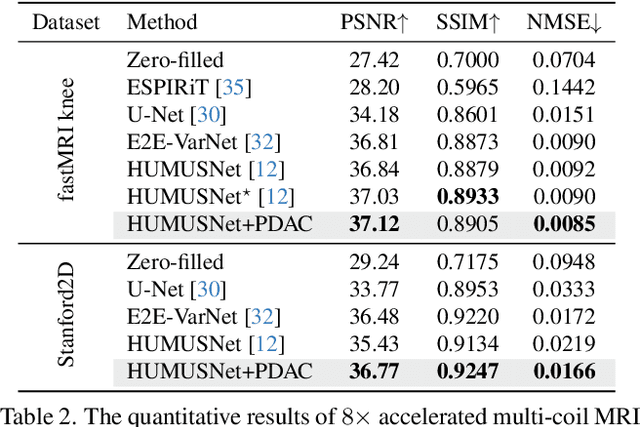
Deep unfolding networks (DUN) have emerged as a popular iterative framework for accelerated magnetic resonance imaging (MRI) reconstruction. However, conventional DUN aims to reconstruct all the missing information within the entire null space in each iteration. Thus it could be challenging when dealing with highly ill-posed degradation, usually leading to unsatisfactory reconstruction. In this work, we propose a Progressive Divide-And-Conquer (PDAC) strategy, aiming to break down the subsampling process in the actual severe degradation and thus perform reconstruction sequentially. Starting from decomposing the original maximum-a-posteriori problem of accelerated MRI, we present a rigorous derivation of the proposed PDAC framework, which could be further unfolded into an end-to-end trainable network. Specifically, each iterative stage in PDAC focuses on recovering a distinct moderate degradation according to the decomposition. Furthermore, as part of the PDAC iteration, such decomposition is adaptively learned as an auxiliary task through a degradation predictor which provides an estimation of the decomposed sampling mask. Following this prediction, the sampling mask is further integrated via a severity conditioning module to ensure awareness of the degradation severity at each stage. Extensive experiments demonstrate that our proposed method achieves superior performance on the publicly available fastMRI and Stanford2D FSE datasets in both multi-coil and single-coil settings.
Learn Suspected Anomalies from Event Prompts for Video Anomaly Detection
Mar 02, 2024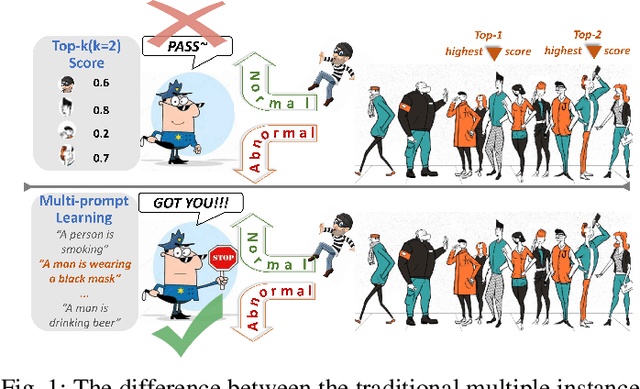
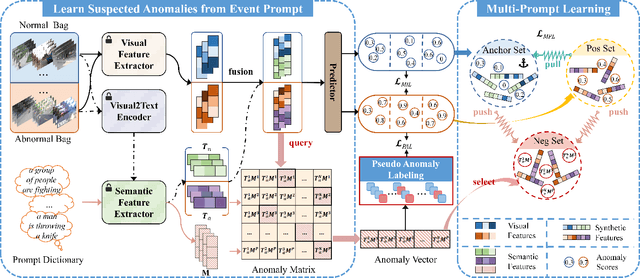

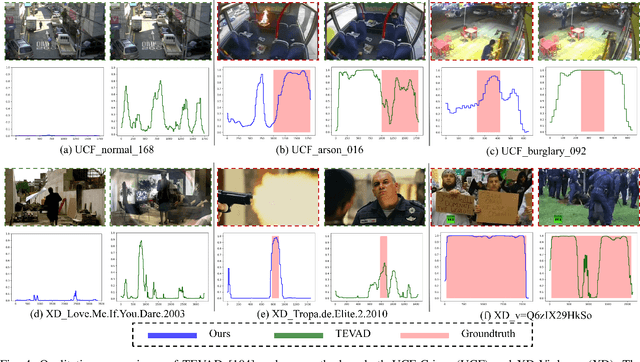
Most models for weakly supervised video anomaly detection (WS-VAD) rely on multiple instance learning, aiming to distinguish normal and abnormal snippets without specifying the type of anomaly. The ambiguous nature of anomaly definitions across contexts introduces bias in detecting abnormal and normal snippets within the abnormal bag. Taking the first step to show the model why it is anomalous, a novel framework is proposed to guide the learning of suspected anomalies from event prompts. Given a textual prompt dictionary of potential anomaly events and the captions generated from anomaly videos, the semantic anomaly similarity between them could be calculated to identify the suspected anomalous events for each video snippet. It enables a new multi-prompt learning process to constrain the visual-semantic features across all videos, as well as provides a new way to label pseudo anomalies for self-training. To demonstrate effectiveness, comprehensive experiments and detailed ablation studies are conducted on four datasets, namely XD-Violence, UCF-Crime, TAD, and ShanghaiTech. Our proposed model outperforms most state-of-the-art methods in terms of AP or AUC (82.6\%, 87.7\%, 93.1\%, and 97.4\%). Furthermore, it shows promising performance in open-set and cross-dataset cases.
Security Code Review by LLMs: A Deep Dive into Responses
Jan 29, 2024Security code review aims to combine automated tools and manual efforts to detect security defects during development. The rapid development of Large Language Models (LLMs) has shown promising potential in software development, as well as opening up new possibilities in automated security code review. To explore the challenges of applying LLMs in practical code review for security defect detection, this study compared the detection performance of three state-of-the-art LLMs (Gemini Pro, GPT-4, and GPT-3.5) under five prompts on 549 code files that contain security defects from real-world code reviews. Through analyzing 82 responses generated by the best-performing LLM-prompt combination based on 100 randomly selected code files, we extracted and categorized quality problems present in these responses into 5 themes and 16 categories. Our results indicate that the responses produced by LLMs often suffer from verbosity, vagueness, and incompleteness, highlighting the necessity to enhance their conciseness, understandability, and compliance to security defect detection. This work reveals the deficiencies of LLM-generated responses in security code review and paves the way for future optimization of LLMs towards this task.
A Prompt Learning Framework for Source Code Summarization
Dec 26, 2023(Source) code summarization is the task of automatically generating natural language summaries for given code snippets. Such summaries play a key role in helping developers understand and maintain source code. Recently, with the successful application of large language models (LLMs) in numerous fields, software engineering researchers have also attempted to adapt LLMs to solve code summarization tasks. The main adaptation schemes include instruction prompting and task-oriented fine-tuning. However, instruction prompting involves designing crafted prompts for zero-shot learning or selecting appropriate samples for few-shot learning and requires users to have professional domain knowledge, while task-oriented fine-tuning requires high training costs. In this paper, we propose a novel prompt learning framework for code summarization called PromptCS. PromptCS trains a prompt agent that can generate continuous prompts to unleash the potential for LLMs in code summarization. Compared to the human-written discrete prompt, the continuous prompts are produced under the guidance of LLMs and are therefore easier to understand by LLMs. PromptCS freezes the parameters of LLMs when training the prompt agent, which can greatly reduce the requirements for training resources. We evaluate PromptCS on the CodeSearchNet dataset involving multiple programming languages. The results show that PromptCS significantly outperforms instruction prompting schemes on all four widely used metrics. In some base LLMs, e.g., CodeGen-Multi-2B and StarCoderBase-1B and -3B, PromptCS even outperforms the task-oriented fine-tuning scheme. More importantly, the training efficiency of PromptCS is faster than the task-oriented fine-tuning scheme, with a more pronounced advantage on larger LLMs. The results of the human evaluation demonstrate that PromptCS can generate more good summaries compared to baselines.