 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYi Yu
MoE-FFD: Mixture of Experts for Generalized and Parameter-Efficient Face Forgery Detection
Apr 12, 2024
Deepfakes have recently raised significant trust issues and security concerns among the public. Compared to CNN face forgery detectors, ViT-based methods take advantage of the expressivity of transformers, achieving superior detection performance. However, these approaches still exhibit the following limitations: (1). Fully fine-tuning ViT-based models from ImageNet weights demands substantial computational and storage resources; (2). ViT-based methods struggle to capture local forgery clues, leading to model bias and limited generalizability. To tackle these challenges, this work introduces Mixture-of-Experts modules for Face Forgery Detection (MoE-FFD), a generalized yet parameter-efficient ViT-based approach. MoE-FFD only updates lightweight Low-Rank Adaptation (LoRA) and Adapter layers while keeping the ViT backbone frozen, thereby achieving parameter-efficient training. Moreover, MoE-FFD leverages the expressivity of transformers and local priors of CNNs to simultaneously extract global and local forgery clues. Additionally, novel MoE modules are designed to scale the model's capacity and select optimal forgery experts, further enhancing forgery detection performance. The proposed MoE learning scheme can be seamlessly adapted to various transformer backbones in a plug-and-play manner. Extensive experimental results demonstrate that the proposed method achieves state-of-the-art face forgery detection performance with reduced parameter overhead. The code will be released upon acceptance.
Empirical Upscaling of Point-scale Soil Moisture Measurements for Spatial Evaluation of Model Simulations and Satellite Retrievals
Apr 08, 2024The evaluation of modelled or satellite-derived soil moisture (SM) estimates is usually dependent on comparisons against in-situ SM measurements. However, the inherent mismatch in spatial support (i.e., scale) necessitates a cautious interpretation of point-to-pixel comparisons. The upscaling of the in-situ measurements to a commensurate resolution to that of the modelled or retrieved SM will lead to a fairer comparison and statistically more defensible evaluation. In this study, we presented an upscaling approach that combines spatiotemporal fusion with machine learning to extrapolate point-scale SM measurements from 28 in-situ sites to a 100 m resolution for an agricultural area of 100 km by 100 km. We conducted a four-fold cross-validation, which consistently demonstrated comparable correlation performance across folds, ranging from 0.6 to 0.9. The proposed approach was further validated based on a cross-cluster strategy by using two spatial subsets within the study area, denoted as cluster A and B, each of which equally comprised of 12 in-situ sites. The cross-cluster validation underscored the capability of the upscaling approach to map the spatial variability of SM within areas that were not covered by in-situ sites, with correlation performance ranging between 0.6 and 0.8. In general, our proposed upscaling approach offers an avenue to extrapolate point measurements of SM to a spatial scale more akin to climatic model grids or remotely sensed observations. Future investigations should delve into a further evaluation of the upscaling approach using independent data, such as model simulations, satellite retrievals or field campaign data.
Safeguarding Medical Image Segmentation Datasets against Unauthorized Training via Contour- and Texture-Aware Perturbations
Mar 21, 2024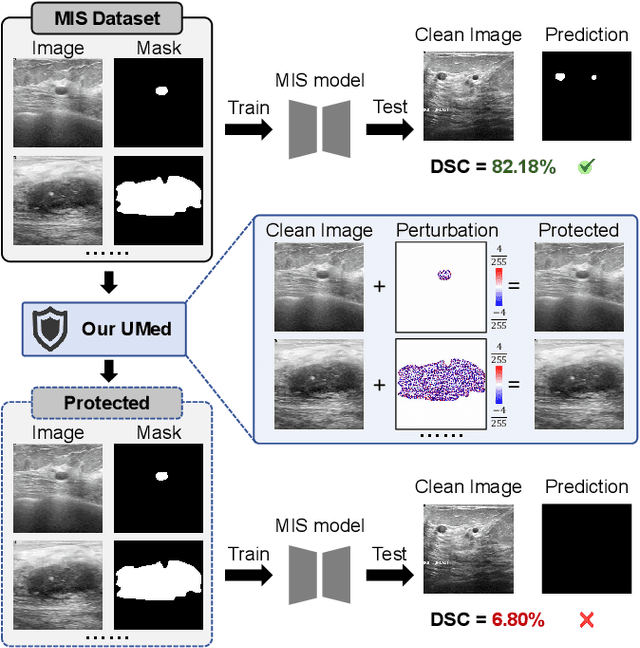
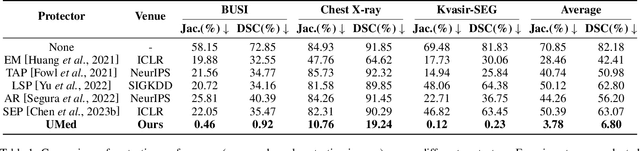
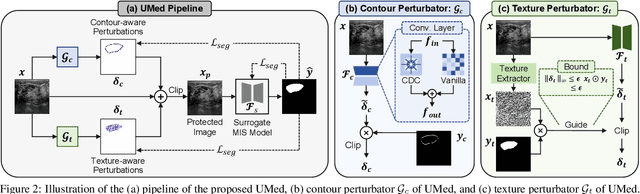
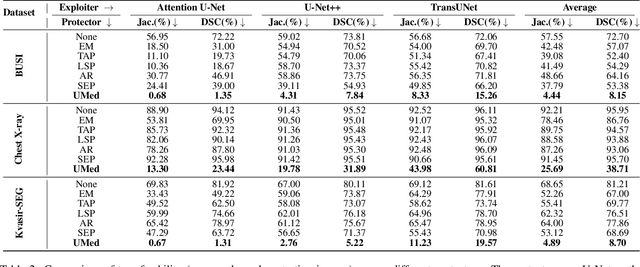
The widespread availability of publicly accessible medical images has significantly propelled advancements in various research and clinical fields. Nonetheless, concerns regarding unauthorized training of AI systems for commercial purposes and the duties of patient privacy protection have led numerous institutions to hesitate to share their images. This is particularly true for medical image segmentation (MIS) datasets, where the processes of collection and fine-grained annotation are time-intensive and laborious. Recently, Unlearnable Examples (UEs) methods have shown the potential to protect images by adding invisible shortcuts. These shortcuts can prevent unauthorized deep neural networks from generalizing. However, existing UEs are designed for natural image classification and fail to protect MIS datasets imperceptibly as their protective perturbations are less learnable than important prior knowledge in MIS, e.g., contour and texture features. To this end, we propose an Unlearnable Medical image generation method, termed UMed. UMed integrates the prior knowledge of MIS by injecting contour- and texture-aware perturbations to protect images. Given that our target is to only poison features critical to MIS, UMed requires only minimal perturbations within the ROI and its contour to achieve greater imperceptibility (average PSNR is 50.03) and protective performance (clean average DSC degrades from 82.18% to 6.80%).
Federated Transfer Learning with Differential Privacy
Mar 17, 2024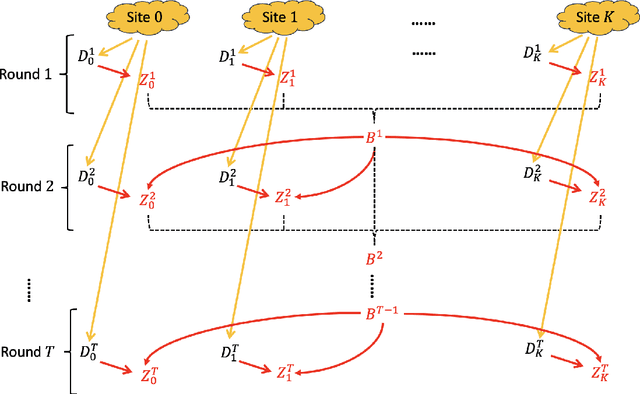

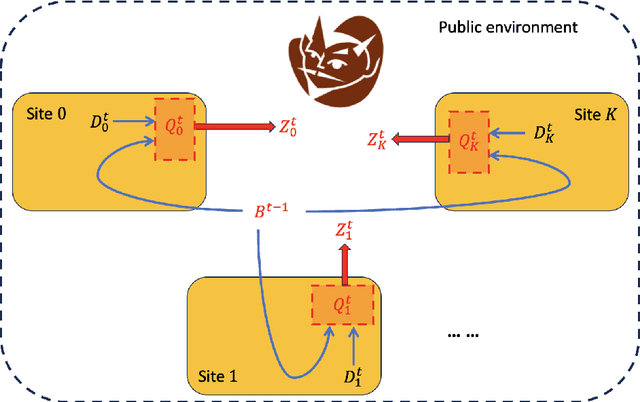

Federated learning is gaining increasing popularity, with data heterogeneity and privacy being two prominent challenges. In this paper, we address both issues within a federated transfer learning framework, aiming to enhance learning on a target data set by leveraging information from multiple heterogeneous source data sets while adhering to privacy constraints. We rigorously formulate the notion of \textit{federated differential privacy}, which offers privacy guarantees for each data set without assuming a trusted central server. Under this privacy constraint, we study three classical statistical problems, namely univariate mean estimation, low-dimensional linear regression, and high-dimensional linear regression. By investigating the minimax rates and identifying the costs of privacy for these problems, we show that federated differential privacy is an intermediate privacy model between the well-established local and central models of differential privacy. Our analyses incorporate data heterogeneity and privacy, highlighting the fundamental costs of both in federated learning and underscoring the benefit of knowledge transfer across data sets.
Progressive Divide-and-Conquer via Subsampling Decomposition for Accelerated MRI
Mar 15, 2024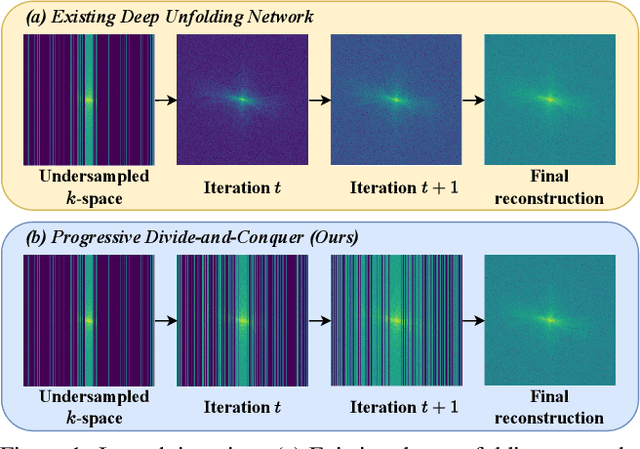
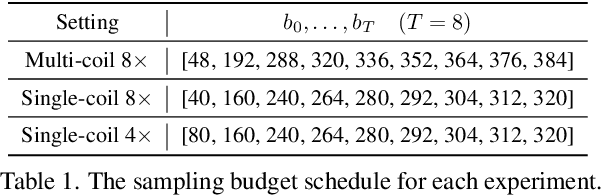
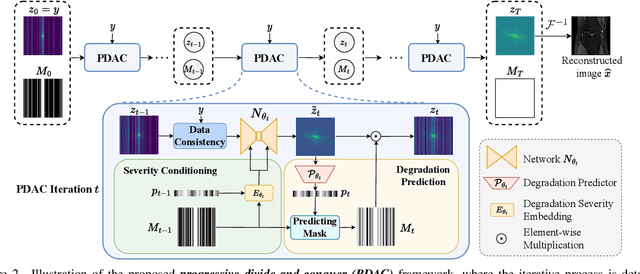
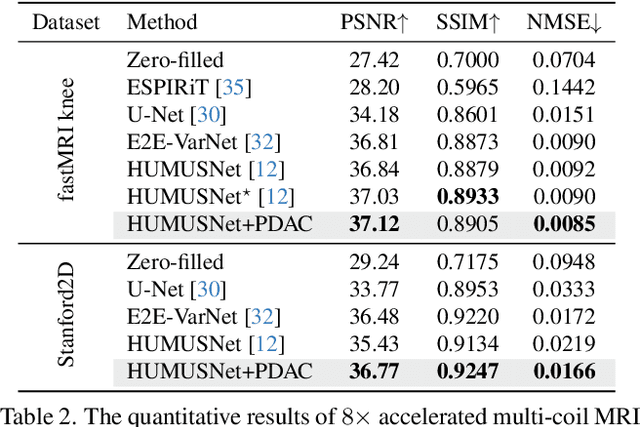
Deep unfolding networks (DUN) have emerged as a popular iterative framework for accelerated magnetic resonance imaging (MRI) reconstruction. However, conventional DUN aims to reconstruct all the missing information within the entire null space in each iteration. Thus it could be challenging when dealing with highly ill-posed degradation, usually leading to unsatisfactory reconstruction. In this work, we propose a Progressive Divide-And-Conquer (PDAC) strategy, aiming to break down the subsampling process in the actual severe degradation and thus perform reconstruction sequentially. Starting from decomposing the original maximum-a-posteriori problem of accelerated MRI, we present a rigorous derivation of the proposed PDAC framework, which could be further unfolded into an end-to-end trainable network. Specifically, each iterative stage in PDAC focuses on recovering a distinct moderate degradation according to the decomposition. Furthermore, as part of the PDAC iteration, such decomposition is adaptively learned as an auxiliary task through a degradation predictor which provides an estimation of the decomposed sampling mask. Following this prediction, the sampling mask is further integrated via a severity conditioning module to ensure awareness of the degradation severity at each stage. Extensive experiments demonstrate that our proposed method achieves superior performance on the publicly available fastMRI and Stanford2D FSE datasets in both multi-coil and single-coil settings.
Benchmarking Adversarial Robustness of Image Shadow Removal with Shadow-adaptive Attacks
Mar 15, 2024
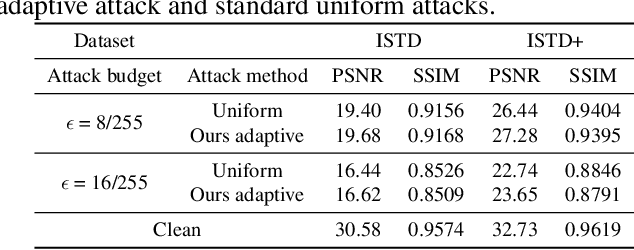
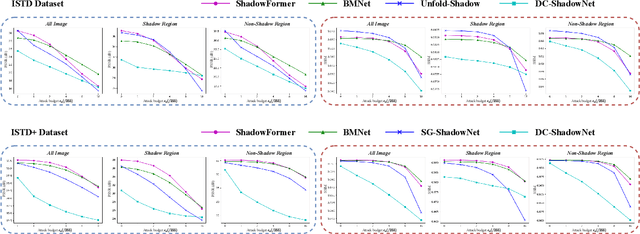

Shadow removal is a task aimed at erasing regional shadows present in images and reinstating visually pleasing natural scenes with consistent illumination. While recent deep learning techniques have demonstrated impressive performance in image shadow removal, their robustness against adversarial attacks remains largely unexplored. Furthermore, many existing attack frameworks typically allocate a uniform budget for perturbations across the entire input image, which may not be suitable for attacking shadow images. This is primarily due to the unique characteristic of spatially varying illumination within shadow images. In this paper, we propose a novel approach, called shadow-adaptive adversarial attack. Different from standard adversarial attacks, our attack budget is adjusted based on the pixel intensity in different regions of shadow images. Consequently, the optimized adversarial noise in the shadowed regions becomes visually less perceptible while permitting a greater tolerance for perturbations in non-shadow regions. The proposed shadow-adaptive attacks naturally align with the varying illumination distribution in shadow images, resulting in perturbations that are less conspicuous. Building on this, we conduct a comprehensive empirical evaluation of existing shadow removal methods, subjecting them to various levels of attack on publicly available datasets.
LM2D: Lyrics- and Music-Driven Dance Synthesis
Mar 14, 2024
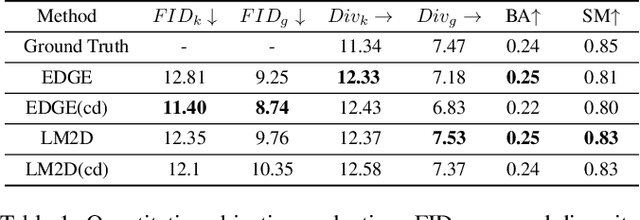
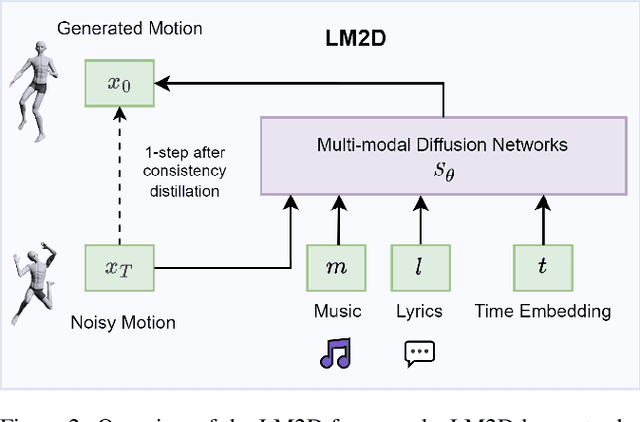
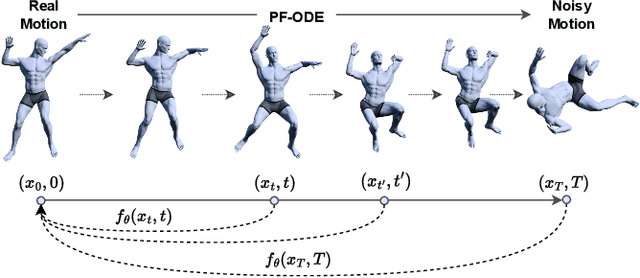
Dance typically involves professional choreography with complex movements that follow a musical rhythm and can also be influenced by lyrical content. The integration of lyrics in addition to the auditory dimension, enriches the foundational tone and makes motion generation more amenable to its semantic meanings. However, existing dance synthesis methods tend to model motions only conditioned on audio signals. In this work, we make two contributions to bridge this gap. First, we propose LM2D, a novel probabilistic architecture that incorporates a multimodal diffusion model with consistency distillation, designed to create dance conditioned on both music and lyrics in one diffusion generation step. Second, we introduce the first 3D dance-motion dataset that encompasses both music and lyrics, obtained with pose estimation technologies. We evaluate our model against music-only baseline models with objective metrics and human evaluations, including dancers and choreographers. The results demonstrate LM2D is able to produce realistic and diverse dance matching both lyrics and music. A video summary can be accessed at: https://youtu.be/4XCgvYookvA.
PnPNet: Pull-and-Push Networks for Volumetric Segmentation with Boundary Confusion
Dec 13, 2023Precise boundary segmentation of volumetric images is a critical task for image-guided diagnosis and computer-assisted intervention, especially for boundary confusion in clinical practice. However, U-shape networks cannot effectively resolve this challenge due to the lack of boundary shape constraints. Besides, existing methods of refining boundaries overemphasize the slender structure, which results in the overfitting phenomenon due to networks' limited abilities to model tiny objects. In this paper, we reconceptualize the mechanism of boundary generation by encompassing the interaction dynamics with adjacent regions. Moreover, we propose a unified network termed PnPNet to model shape characteristics of the confused boundary region. Core ingredients of PnPNet contain the pushing and pulling branches. Specifically, based on diffusion theory, we devise the semantic difference module (SDM) from the pushing branch to squeeze the boundary region. Explicit and implicit differential information inside SDM significantly boost representation abilities for inter-class boundaries. Additionally, motivated by the K-means algorithm, the class clustering module (CCM) from the pulling branch is introduced to stretch the intersected boundary region. Thus, pushing and pulling branches will shrink and enlarge the boundary uncertainty respectively. They furnish two adversarial forces to promote models to output a more precise delineation of boundaries. We carry out experiments on three challenging public datasets and one in-house dataset, containing three types of boundary confusion in model predictions. Experimental results demonstrate the superiority of PnPNet over other segmentation networks, especially on evaluation metrics of HD and ASSD. Besides, pushing and pulling branches can serve as plug-and-play modules to enhance classic U-shape baseline models. Codes are available.
Scalable Motion Style Transfer with Constrained Diffusion Generation
Dec 12, 2023Current training of motion style transfer systems relies on consistency losses across style domains to preserve contents, hindering its scalable application to a large number of domains and private data. Recent image transfer works show the potential of independent training on each domain by leveraging implicit bridging between diffusion models, with the content preservation, however, limited to simple data patterns. We address this by imposing biased sampling in backward diffusion while maintaining the domain independence in the training stage. We construct the bias from the source domain keyframes and apply them as the gradient of content constraints, yielding a framework with keyframe manifold constraint gradients (KMCGs). Our validation demonstrates the success of training separate models to transfer between as many as ten dance motion styles. Comprehensive experiments find a significant improvement in preserving motion contents in comparison to baseline and ablative diffusion-based style transfer models. In addition, we perform a human study for a subjective assessment of the quality of generated dance motions. The results validate the competitiveness of KMCGs.
Parallax-Tolerant Image Stitching with Epipolar Displacement Field
Nov 28, 2023Large parallax image stitching is a challenging task. Existing methods often struggle to maintain both the local and global structures of the image while reducing alignment artifacts and warping distortions. In this paper, we propose a novel approach that utilizes epipolar geometry to establish a warping technique based on the epipolar displacement field. Initially, the warping rule for pixels in the epipolar geometry is established through the infinite homography. Subsequently, Subsequently, the epipolar displacement field, which represents the sliding distance of the warped pixel along the epipolar line, is formulated by thin plate splines based on the principle of local elastic deformation. The stitching result can be generated by inversely warping the pixels according to the epipolar displacement field. This method incorporates the epipolar constraints in the warping rule, which ensures high-quality alignment and maintains the projectivity of the panorama. Qualitative and quantitative comparative experiments demonstrate the competitiveness of the proposed method in stitching images large parallax.