 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoliang Li
Exposing AI-generated Videos: A Benchmark Dataset and a Local-and-Global Temporal Defect Based Detection Method
May 07, 2024
The generative model has made significant advancements in the creation of realistic videos, which causes security issues. However, this emerging risk has not been adequately addressed due to the absence of a benchmark dataset for AI-generated videos. In this paper, we first construct a video dataset using advanced diffusion-based video generation algorithms with various semantic contents. Besides, typical video lossy operations over network transmission are adopted to generate degraded samples. Then, by analyzing local and global temporal defects of current AI-generated videos, a novel detection framework by adaptively learning local motion information and global appearance variation is constructed to expose fake videos. Finally, experiments are conducted to evaluate the generalization and robustness of different spatial and temporal domain detection methods, where the results can serve as the baseline and demonstrate the research challenge for future studies.
Gradient-Congruity Guided Federated Sparse Training
May 02, 2024Edge computing allows artificial intelligence and machine learning models to be deployed on edge devices, where they can learn from local data and collaborate to form a global model. Federated learning (FL) is a distributed machine learning technique that facilitates this process while preserving data privacy. However, FL also faces challenges such as high computational and communication costs regarding resource-constrained devices, and poor generalization performance due to the heterogeneity of data across edge clients and the presence of out-of-distribution data. In this paper, we propose the Gradient-Congruity Guided Federated Sparse Training (FedSGC), a novel method that integrates dynamic sparse training and gradient congruity inspection into federated learning framework to address these issues. Our method leverages the idea that the neurons, in which the associated gradients with conflicting directions with respect to the global model contain irrelevant or less generalized information for other clients, and could be pruned during the sparse training process. Conversely, the neurons where the associated gradients with consistent directions could be grown in a higher priority. In this way, FedSGC can greatly reduce the local computation and communication overheads while, at the same time, enhancing the generalization abilities of FL. We evaluate our method on challenging non-i.i.d settings and show that it achieves competitive accuracy with state-of-the-art FL methods across various scenarios while minimizing computation and communication costs.
MoE-FFD: Mixture of Experts for Generalized and Parameter-Efficient Face Forgery Detection
Apr 12, 2024Deepfakes have recently raised significant trust issues and security concerns among the public. Compared to CNN face forgery detectors, ViT-based methods take advantage of the expressivity of transformers, achieving superior detection performance. However, these approaches still exhibit the following limitations: (1). Fully fine-tuning ViT-based models from ImageNet weights demands substantial computational and storage resources; (2). ViT-based methods struggle to capture local forgery clues, leading to model bias and limited generalizability. To tackle these challenges, this work introduces Mixture-of-Experts modules for Face Forgery Detection (MoE-FFD), a generalized yet parameter-efficient ViT-based approach. MoE-FFD only updates lightweight Low-Rank Adaptation (LoRA) and Adapter layers while keeping the ViT backbone frozen, thereby achieving parameter-efficient training. Moreover, MoE-FFD leverages the expressivity of transformers and local priors of CNNs to simultaneously extract global and local forgery clues. Additionally, novel MoE modules are designed to scale the model's capacity and select optimal forgery experts, further enhancing forgery detection performance. The proposed MoE learning scheme can be seamlessly adapted to various transformer backbones in a plug-and-play manner. Extensive experimental results demonstrate that the proposed method achieves state-of-the-art face forgery detection performance with reduced parameter overhead. The code will be released upon acceptance.
Log Neural Controlled Differential Equations: The Lie Brackets Make a Difference
Feb 28, 2024The vector field of a controlled differential equation (CDE) describes the relationship between a control path and the evolution of a solution path. Neural CDEs (NCDEs) treat time series data as observations from a control path, parameterise a CDE's vector field using a neural network, and use the solution path as a continuously evolving hidden state. As their formulation makes them robust to irregular sampling rates, NCDEs are a powerful approach for modelling real-world data. Building on neural rough differential equations (NRDEs), we introduce Log-NCDEs, a novel and effective method for training NCDEs. The core component of Log-NCDEs is the Log-ODE method, a tool from the study of rough paths for approximating a CDE's solution. On a range of multivariate time series classification benchmarks, Log-NCDEs are shown to achieve a higher average test set accuracy than NCDEs, NRDEs, and two state-of-the-art models, S5 and the linear recurrent unit.
TELLER: A Trustworthy Framework for Explainable, Generalizable and Controllable Fake News Detection
Feb 12, 2024The proliferation of fake news has emerged as a severe societal problem, raising significant interest from industry and academia. While existing deep-learning based methods have made progress in detecting fake news accurately, their reliability may be compromised caused by the non-transparent reasoning processes, poor generalization abilities and inherent risks of integration with large language models (LLMs). To address this challenge, we propose {\methodname}, a novel framework for trustworthy fake news detection that prioritizes explainability, generalizability and controllability of models. This is achieved via a dual-system framework that integrates cognition and decision systems, adhering to the principles above. The cognition system harnesses human expertise to generate logical predicates, which guide LLMs in generating human-readable logic atoms. Meanwhile, the decision system deduces generalizable logic rules to aggregate these atoms, enabling the identification of the truthfulness of the input news across diverse domains and enhancing transparency in the decision-making process. Finally, we present comprehensive evaluation results on four datasets, demonstrating the feasibility and trustworthiness of our proposed framework. Our implementation is available at \url{https://github.com/less-and-less-bugs/Trust_TELLER}.
Domain Generalization with Small Data
Feb 09, 2024In this work, we propose to tackle the problem of domain generalization in the context of \textit{insufficient samples}. Instead of extracting latent feature embeddings based on deterministic models, we propose to learn a domain-invariant representation based on the probabilistic framework by mapping each data point into probabilistic embeddings. Specifically, we first extend empirical maximum mean discrepancy (MMD) to a novel probabilistic MMD that can measure the discrepancy between mixture distributions (i.e., source domains) consisting of a series of latent distributions rather than latent points. Moreover, instead of imposing the contrastive semantic alignment (CSA) loss based on pairs of latent points, a novel probabilistic CSA loss encourages positive probabilistic embedding pairs to be closer while pulling other negative ones apart. Benefiting from the learned representation captured by probabilistic models, our proposed method can marriage the measurement on the \textit{distribution over distributions} (i.e., the global perspective alignment) and the distribution-based contrastive semantic alignment (i.e., the local perspective alignment). Extensive experimental results on three challenging medical datasets show the effectiveness of our proposed method in the context of insufficient data compared with state-of-the-art methods.
Target-agnostic Source-free Domain Adaptation for Regression Tasks
Dec 01, 2023



Unsupervised domain adaptation (UDA) seeks to bridge the domain gap between the target and source using unlabeled target data. Source-free UDA removes the requirement for labeled source data at the target to preserve data privacy and storage. However, work on source-free UDA assumes knowledge of domain gap distribution, and hence is limited to either target-aware or classification task. To overcome it, we propose TASFAR, a novel target-agnostic source-free domain adaptation approach for regression tasks. Using prediction confidence, TASFAR estimates a label density map as the target label distribution, which is then used to calibrate the source model on the target domain. We have conducted extensive experiments on four regression tasks with various domain gaps, namely, pedestrian dead reckoning for different users, image-based people counting in different scenes, housing-price prediction at different districts, and taxi-trip duration prediction from different departure points. TASFAR is shown to substantially outperform the state-of-the-art source-free UDA approaches by averagely reducing 22% errors for the four tasks and achieve notably comparable accuracy as source-based UDA without using source data.
Robust Domain Misinformation Detection via Multi-modal Feature Alignment
Nov 24, 2023Social media misinformation harms individuals and societies and is potentialized by fast-growing multi-modal content (i.e., texts and images), which accounts for higher "credibility" than text-only news pieces. Although existing supervised misinformation detection methods have obtained acceptable performances in key setups, they may require large amounts of labeled data from various events, which can be time-consuming and tedious. In turn, directly training a model by leveraging a publicly available dataset may fail to generalize due to domain shifts between the training data (a.k.a. source domains) and the data from target domains. Most prior work on domain shift focuses on a single modality (e.g., text modality) and ignores the scenario where sufficient unlabeled target domain data may not be readily available in an early stage. The lack of data often happens due to the dynamic propagation trend (i.e., the number of posts related to fake news increases slowly before catching the public attention). We propose a novel robust domain and cross-modal approach (\textbf{RDCM}) for multi-modal misinformation detection. It reduces the domain shift by aligning the joint distribution of textual and visual modalities through an inter-domain alignment module and bridges the semantic gap between both modalities through a cross-modality alignment module. We also propose a framework that simultaneously considers application scenarios of domain generalization (in which the target domain data is unavailable) and domain adaptation (in which unlabeled target domain data is available). Evaluation results on two public multi-modal misinformation detection datasets (Pheme and Twitter Datasets) evince the superiority of the proposed model. The formal implementation of this paper can be found in this link: https://github.com/less-and-less-bugs/RDCM
Pixel-Inconsistency Modeling for Image Manipulation Localization
Sep 30, 2023
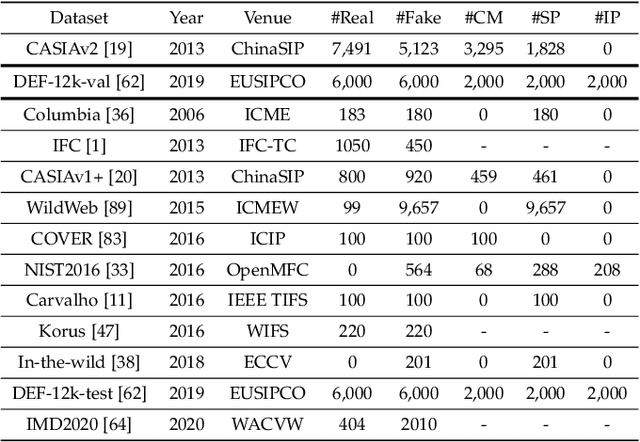

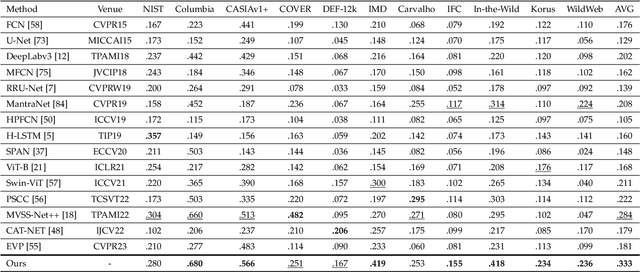
Digital image forensics plays a crucial role in image authentication and manipulation localization. Despite the progress powered by deep neural networks, existing forgery localization methodologies exhibit limitations when deployed to unseen datasets and perturbed images (i.e., lack of generalization and robustness to real-world applications). To circumvent these problems and aid image integrity, this paper presents a generalized and robust manipulation localization model through the analysis of pixel inconsistency artifacts. The rationale is grounded on the observation that most image signal processors (ISP) involve the demosaicing process, which introduces pixel correlations in pristine images. Moreover, manipulating operations, including splicing, copy-move, and inpainting, directly affect such pixel regularity. We, therefore, first split the input image into several blocks and design masked self-attention mechanisms to model the global pixel dependency in input images. Simultaneously, we optimize another local pixel dependency stream to mine local manipulation clues within input forgery images. In addition, we design novel Learning-to-Weight Modules (LWM) to combine features from the two streams, thereby enhancing the final forgery localization performance. To improve the training process, we propose a novel Pixel-Inconsistency Data Augmentation (PIDA) strategy, driving the model to focus on capturing inherent pixel-level artifacts instead of mining semantic forgery traces. This work establishes a comprehensive benchmark integrating 15 representative detection models across 12 datasets. Extensive experiments show that our method successfully extracts inherent pixel-inconsistency forgery fingerprints and achieve state-of-the-art generalization and robustness performances in image manipulation localization.
Rethinking Sensors Modeling: Hierarchical Information Enhanced Traffic Forecasting
Sep 20, 2023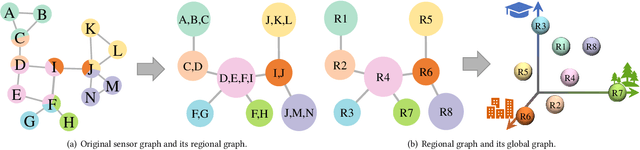

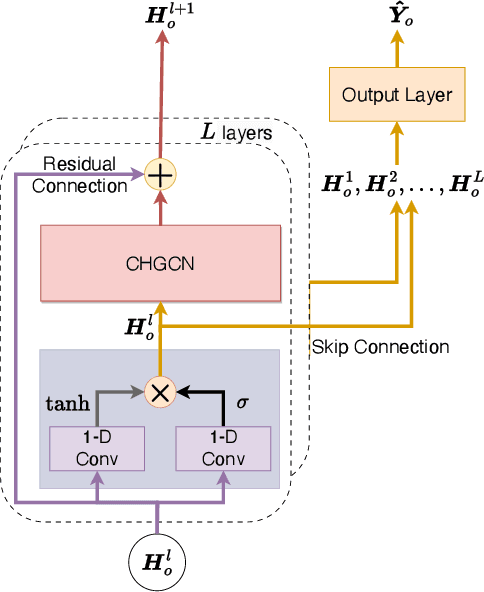
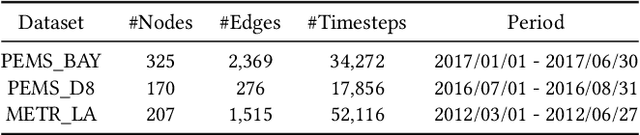
With the acceleration of urbanization, traffic forecasting has become an essential role in smart city construction. In the context of spatio-temporal prediction, the key lies in how to model the dependencies of sensors. However, existing works basically only consider the micro relationships between sensors, where the sensors are treated equally, and their macroscopic dependencies are neglected. In this paper, we argue to rethink the sensor's dependency modeling from two hierarchies: regional and global perspectives. Particularly, we merge original sensors with high intra-region correlation as a region node to preserve the inter-region dependency. Then, we generate representative and common spatio-temporal patterns as global nodes to reflect a global dependency between sensors and provide auxiliary information for spatio-temporal dependency learning. In pursuit of the generality and reality of node representations, we incorporate a Meta GCN to calibrate the regional and global nodes in the physical data space. Furthermore, we devise the cross-hierarchy graph convolution to propagate information from different hierarchies. In a nutshell, we propose a Hierarchical Information Enhanced Spatio-Temporal prediction method, HIEST, to create and utilize the regional dependency and common spatio-temporal patterns. Extensive experiments have verified the leading performance of our HIEST against state-of-the-art baselines. We publicize the code to ease reproducibility.