 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHui Liu
Modeling Selective Feature Attention for Representation-based Siamese Text Matching
Apr 25, 2024
Representation-based Siamese networks have risen to popularity in lightweight text matching due to their low deployment and inference costs. While word-level attention mechanisms have been implemented within Siamese networks to improve performance, we propose Feature Attention (FA), a novel downstream block designed to enrich the modeling of dependencies among embedding features. Employing "squeeze-and-excitation" techniques, the FA block dynamically adjusts the emphasis on individual features, enabling the network to concentrate more on features that significantly contribute to the final classification. Building upon FA, we introduce a dynamic "selection" mechanism called Selective Feature Attention (SFA), which leverages a stacked BiGRU Inception structure. The SFA block facilitates multi-scale semantic extraction by traversing different stacked BiGRU layers, encouraging the network to selectively concentrate on semantic information and embedding features across varying levels of abstraction. Both the FA and SFA blocks offer a seamless integration capability with various Siamese networks, showcasing a plug-and-play characteristic. Experimental evaluations conducted across diverse text matching baselines and benchmarks underscore the indispensability of modeling feature attention and the superiority of the "selection" mechanism.
Graph Machine Learning in the Era of Large Language Models (LLMs)
Apr 23, 2024Graphs play an important role in representing complex relationships in various domains like social networks, knowledge graphs, and molecular discovery. With the advent of deep learning, Graph Neural Networks (GNNs) have emerged as a cornerstone in Graph Machine Learning (Graph ML), facilitating the representation and processing of graph structures. Recently, LLMs have demonstrated unprecedented capabilities in language tasks and are widely adopted in a variety of applications such as computer vision and recommender systems. This remarkable success has also attracted interest in applying LLMs to the graph domain. Increasing efforts have been made to explore the potential of LLMs in advancing Graph ML's generalization, transferability, and few-shot learning ability. Meanwhile, graphs, especially knowledge graphs, are rich in reliable factual knowledge, which can be utilized to enhance the reasoning capabilities of LLMs and potentially alleviate their limitations such as hallucinations and the lack of explainability. Given the rapid progress of this research direction, a systematic review summarizing the latest advancements for Graph ML in the era of LLMs is necessary to provide an in-depth understanding to researchers and practitioners. Therefore, in this survey, we first review the recent developments in Graph ML. We then explore how LLMs can be utilized to enhance the quality of graph features, alleviate the reliance on labeled data, and address challenges such as graph heterogeneity and out-of-distribution (OOD) generalization. Afterward, we delve into how graphs can enhance LLMs, highlighting their abilities to enhance LLM pre-training and inference. Furthermore, we investigate various applications and discuss the potential future directions in this promising field.
Explanation based Bias Decoupling Regularization for Natural Language Inference
Apr 20, 2024The robustness of Transformer-based Natural Language Inference encoders is frequently compromised as they tend to rely more on dataset biases than on the intended task-relevant features. Recent studies have attempted to mitigate this by reducing the weight of biased samples during the training process. However, these debiasing methods primarily focus on identifying which samples are biased without explicitly determining the biased components within each case. This limitation restricts those methods' capability in out-of-distribution inference. To address this issue, we aim to train models to adopt the logic humans use in explaining causality. We propose a simple, comprehensive, and interpretable method: Explanation based Bias Decoupling Regularization (EBD-Reg). EBD-Reg employs human explanations as criteria, guiding the encoder to establish a tripartite parallel supervision of Distinguishing, Decoupling and Aligning. This method enables encoders to identify and focus on keywords that represent the task-relevant features during inference, while discarding the residual elements acting as biases. Empirical evidence underscores that EBD-Reg effectively guides various Transformer-based encoders to decouple biases through a human-centric lens, significantly surpassing other methods in terms of out-of-distribution inference capabilities.
RainyScape: Unsupervised Rainy Scene Reconstruction using Decoupled Neural Rendering
Apr 17, 2024We propose RainyScape, an unsupervised framework for reconstructing clean scenes from a collection of multi-view rainy images. RainyScape consists of two main modules: a neural rendering module and a rain-prediction module that incorporates a predictor network and a learnable latent embedding that captures the rain characteristics of the scene. Specifically, based on the spectral bias property of neural networks, we first optimize the neural rendering pipeline to obtain a low-frequency scene representation. Subsequently, we jointly optimize the two modules, driven by the proposed adaptive direction-sensitive gradient-based reconstruction loss, which encourages the network to distinguish between scene details and rain streaks, facilitating the propagation of gradients to the relevant components. Extensive experiments on both the classic neural radiance field and the recently proposed 3D Gaussian splatting demonstrate the superiority of our method in effectively eliminating rain streaks and rendering clean images, achieving state-of-the-art performance. The constructed high-quality dataset and source code will be publicly available.
SIFiD: Reassess Summary Factual Inconsistency Detection with LLM
Mar 12, 2024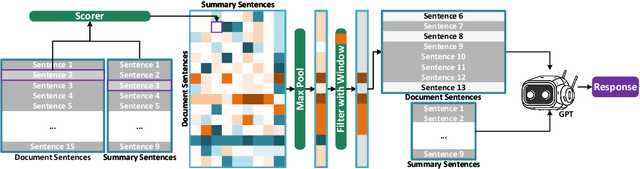
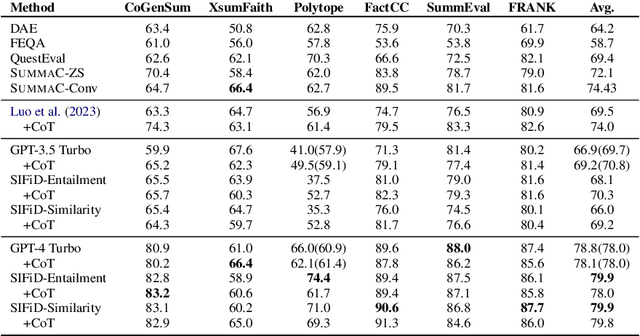
Ensuring factual consistency between the summary and the original document is paramount in summarization tasks. Consequently, considerable effort has been dedicated to detecting inconsistencies. With the advent of Large Language Models (LLMs), recent studies have begun to leverage their advanced language understanding capabilities for inconsistency detection. However, early attempts have shown that LLMs underperform traditional models due to their limited ability to follow instructions and the absence of an effective detection methodology. In this study, we reassess summary inconsistency detection with LLMs, comparing the performances of GPT-3.5 and GPT-4. To advance research in LLM-based inconsistency detection, we propose SIFiD (Summary Inconsistency Detection with Filtered Document) that identify key sentences within documents by either employing natural language inference or measuring semantic similarity between summaries and documents.
Predicting Single-cell Drug Sensitivity by Adaptive Weighted Feature for Adversarial Multi-source Domain Adaptation
Mar 08, 2024

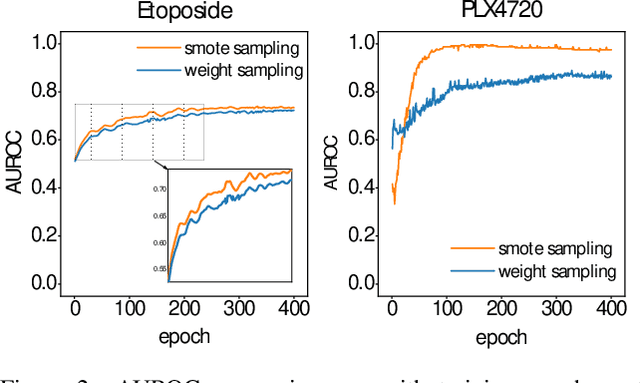

The development of single-cell sequencing technology had promoted the generation of a large amount of single-cell transcriptional profiles, providing valuable opportunities to explore drug-resistant cell subpopulations in a tumor. However, the drug sensitivity data in single-cell level is still scarce to date, pressing an urgent and highly challenging task for computational prediction of the drug sensitivity to individual cells. This paper proposed scAdaDrug, a multi-source adaptive weighting model to predict single-cell drug sensitivity. We used an autoencoder to extract domain-invariant features related to drug sensitivity from multiple source domains by exploiting adversarial domain adaptation. Especially, we introduced an adaptive weight generator to produce importance-aware and mutual independent weights, which could adaptively modulate the embedding of each sample in dimension-level for both source and target domains. Extensive experimental results showed that our model achieved state-of-the-art performance in predicting drug sensitivity on sinle-cell datasets, as well as on cell line and patient datasets.
Superpixel Graph Contrastive Clustering with Semantic-Invariant Augmentations for Hyperspectral Images
Mar 04, 2024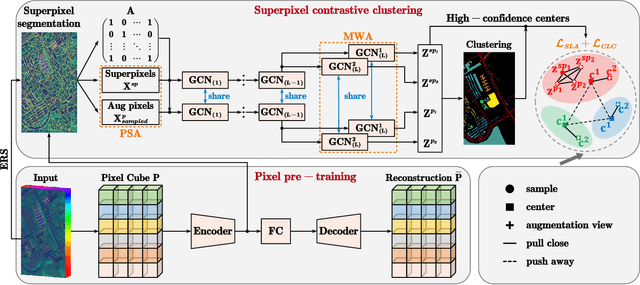



Hyperspectral images (HSI) clustering is an important but challenging task. The state-of-the-art (SOTA) methods usually rely on superpixels, however, they do not fully utilize the spatial and spectral information in HSI 3-D structure, and their optimization targets are not clustering-oriented. In this work, we first use 3-D and 2-D hybrid convolutional neural networks to extract the high-order spatial and spectral features of HSI through pre-training, and then design a superpixel graph contrastive clustering (SPGCC) model to learn discriminative superpixel representations. Reasonable augmented views are crucial for contrastive clustering, and conventional contrastive learning may hurt the cluster structure since different samples are pushed away in the embedding space even if they belong to the same class. In SPGCC, we design two semantic-invariant data augmentations for HSI superpixels: pixel sampling augmentation and model weight augmentation. Then sample-level alignment and clustering-center-level contrast are performed for better intra-class similarity and inter-class dissimilarity of superpixel embeddings. We perform clustering and network optimization alternatively. Experimental results on several HSI datasets verify the advantages of the proposed method, e.g., on India Pines, our model improves the clustering accuracy from 58.79% to 67.59% compared to the SOTA method.
Towards Calibrated Deep Clustering Network
Mar 04, 2024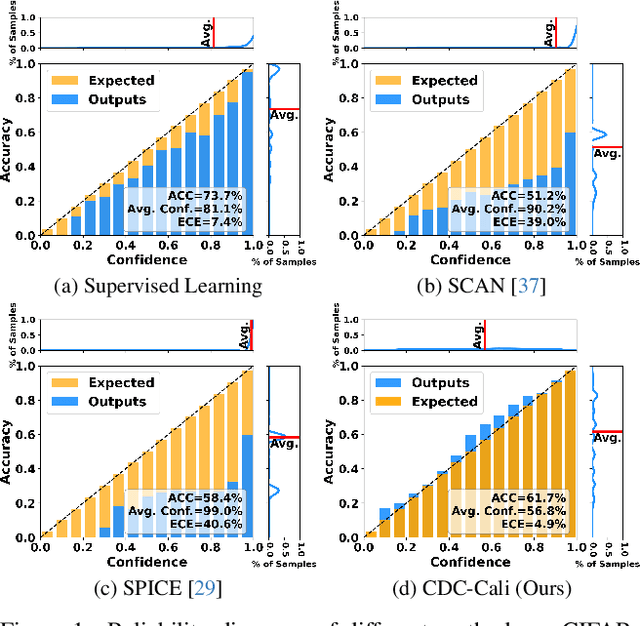
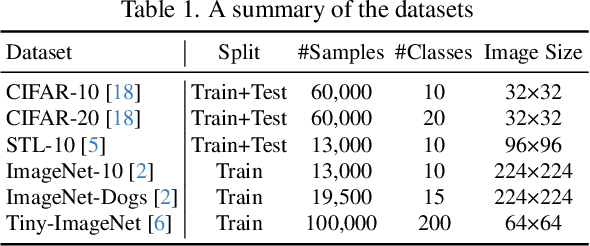
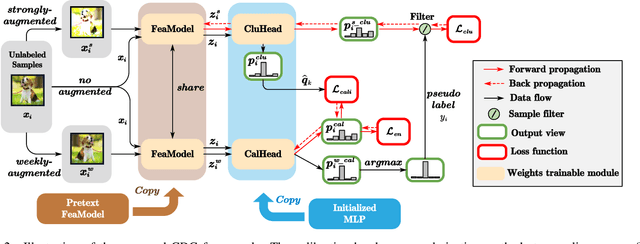
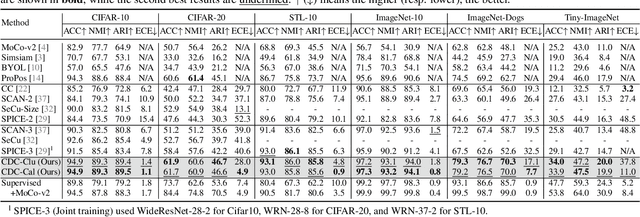
Deep clustering has exhibited remarkable performance; however, the overconfidence problem, i.e., the estimated confidence for a sample belonging to a particular cluster greatly exceeds its actual prediction accuracy, has been overlooked in prior research. To tackle this critical issue, we pioneer the development of a calibrated deep clustering framework. Specifically, we propose a novel dual-head deep clustering pipeline that can effectively calibrate the estimated confidence and the actual accuracy. The calibration head adjusts the overconfident predictions of the clustering head using regularization methods, generating prediction confidence and pseudo-labels that match the model learning status. This calibration process also guides the clustering head in dynamically selecting reliable high-confidence samples for training. Additionally, we introduce an effective network initialization strategy that enhances both training speed and network robustness. Extensive experiments demonstrate the proposed calibrated deep clustering framework not only surpasses state-of-the-art deep clustering methods by approximately 10 times in terms of expected calibration error but also significantly outperforms them in terms of clustering accuracy.
Improving the JPEG-resistance of Adversarial Attacks on Face Recognition by Interpolation Smoothing
Feb 26, 2024JPEG compression can significantly impair the performance of adversarial face examples, which previous adversarial attacks on face recognition (FR) have not adequately addressed. Considering this challenge, we propose a novel adversarial attack on FR that aims to improve the resistance of adversarial examples against JPEG compression. Specifically, during the iterative process of generating adversarial face examples, we interpolate the adversarial face examples into a smaller size. Then we utilize these interpolated adversarial face examples to create the adversarial examples in the next iteration. Subsequently, we restore the adversarial face examples to their original size by interpolating. Throughout the entire process, our proposed method can smooth the adversarial perturbations, effectively mitigating the presence of high-frequency signals in the crafted adversarial face examples that are typically eliminated by JPEG compression. Our experimental results demonstrate the effectiveness of our proposed method in improving the JPEG-resistance of adversarial face examples.
Rethinking Large Language Model Architectures for Sequential Recommendations
Feb 14, 2024Recently, sequential recommendation has been adapted to the LLM paradigm to enjoy the power of LLMs. LLM-based methods usually formulate recommendation information into natural language and the model is trained to predict the next item in an auto-regressive manner. Despite their notable success, the substantial computational overhead of inference poses a significant obstacle to their real-world applicability. In this work, we endeavor to streamline existing LLM-based recommendation models and propose a simple yet highly effective model Lite-LLM4Rec. The primary goal of Lite-LLM4Rec is to achieve efficient inference for the sequential recommendation task. Lite-LLM4Rec circumvents the beam search decoding by using a straight item projection head for ranking scores generation. This design stems from our empirical observation that beam search decoding is ultimately unnecessary for sequential recommendations. Additionally, Lite-LLM4Rec introduces a hierarchical LLM structure tailored to efficiently handle the extensive contextual information associated with items, thereby reducing computational overhead while enjoying the capabilities of LLMs. Experiments on three publicly available datasets corroborate the effectiveness of Lite-LLM4Rec in both performance and inference efficiency (notably 46.8% performance improvement and 97.28% efficiency improvement on ML-1m) over existing LLM-based methods. Our implementations will be open sourced.