 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiangyu Zhao
M3oE: Multi-Domain Multi-Task Mixture-of Experts Recommendation Framework
Apr 29, 2024
Multi-domain recommendation and multi-task recommendation have demonstrated their effectiveness in leveraging common information from different domains and objectives for comprehensive user modeling. Nonetheless, the practical recommendation usually faces multiple domains and tasks simultaneously, which cannot be well-addressed by current methods. To this end, we introduce M3oE, an adaptive multi-domain multi-task mixture-of-experts recommendation framework. M3oE integrates multi-domain information, maps knowledge across domains and tasks, and optimizes multiple objectives. We leverage three mixture-of-experts modules to learn common, domain-aspect, and task-aspect user preferences respectively to address the complex dependencies among multiple domains and tasks in a disentangled manner. Additionally, we design a two-level fusion mechanism for precise control over feature extraction and fusion across diverse domains and tasks. The framework's adaptability is further enhanced by applying AutoML technique, which allows dynamic structure optimization. To the best of the authors' knowledge, our M3oE is the first effort to solve multi-domain multi-task recommendation self-adaptively. Extensive experiments on two benchmark datasets against diverse baselines demonstrate M3oE's superior performance. The implementation code is available to ensure reproducibility.
ControlTraj: Controllable Trajectory Generation with Topology-Constrained Diffusion Model
Apr 23, 2024Generating trajectory data is among promising solutions to addressing privacy concerns, collection costs, and proprietary restrictions usually associated with human mobility analyses. However, existing trajectory generation methods are still in their infancy due to the inherent diversity and unpredictability of human activities, grappling with issues such as fidelity, flexibility, and generalizability. To overcome these obstacles, we propose ControlTraj, a Controllable Trajectory generation framework with the topology-constrained diffusion model. Distinct from prior approaches, ControlTraj utilizes a diffusion model to generate high-fidelity trajectories while integrating the structural constraints of road network topology to guide the geographical outcomes. Specifically, we develop a novel road segment autoencoder to extract fine-grained road segment embedding. The encoded features, along with trip attributes, are subsequently merged into the proposed geographic denoising UNet architecture, named GeoUNet, to synthesize geographic trajectories from white noise. Through experimentation across three real-world data settings, ControlTraj demonstrates its ability to produce human-directed, high-fidelity trajectory generation with adaptability to unexplored geographical contexts.
When Emotional Stimuli meet Prompt Designing: An Auto-Prompt Graphical Paradigm
Apr 16, 2024With the development of Large Language Models (LLM), numerous prompts have been proposed, each with a rich set of features and their own merits. This paper summarizes the prompt words for large language models (LLMs), categorizing them into stimulating and framework types, and proposes an Auto-Prompt Graphical Paradigm(APGP) that combines both stimulating and framework prompts to enhance the problem-solving capabilities of LLMs across multiple domains, then exemplifies it with a framework that adheres to this paradigm. The framework involves automated prompt generation and consideration of emotion-stimulus factors, guiding LLMs in problem abstraction, diversified solutions generation, comprehensive optimization, and self-verification after providing answers, ensuring solution accuracy. Compared to traditional stimuli and framework prompts, this framework integrates the advantages of both by adopting automated approaches inspired by APE work, overcoming the limitations of manually designed prompts. Test results on the ruozhiba and BBH datasets demonstrate that this framework can effectively improve the efficiency and accuracy of LLMs in problem-solving, paving the way for new applications of LLMs.
Tired of Plugins? Large Language Models Can Be End-To-End Recommenders
Apr 07, 2024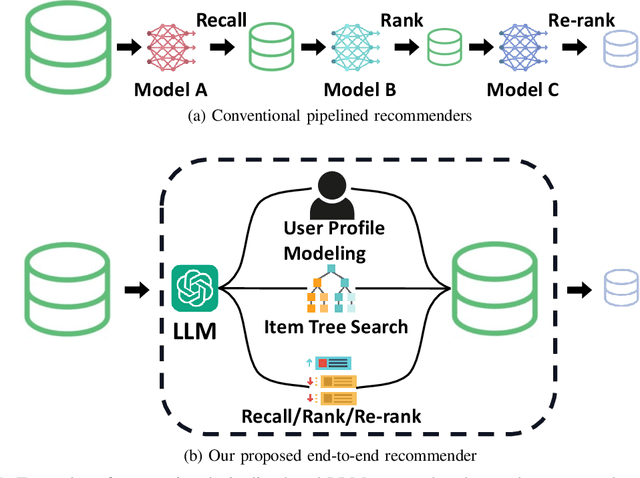
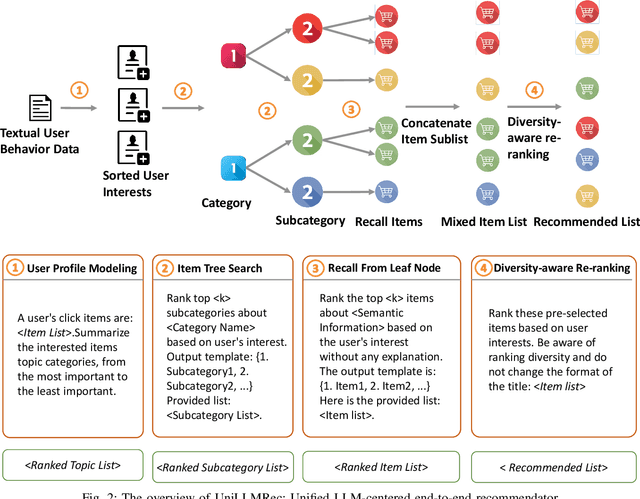
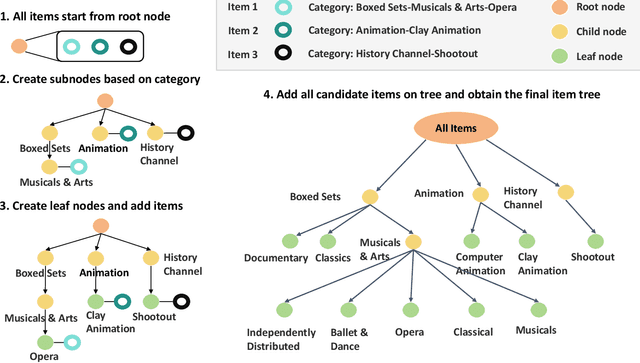
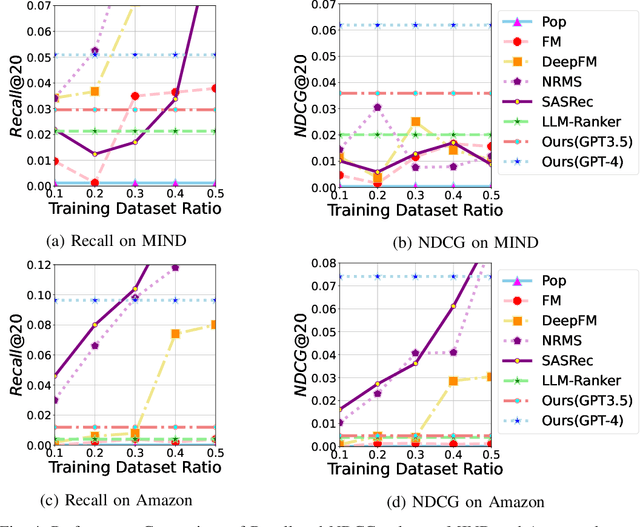
Recommender systems aim to predict user interest based on historical behavioral data. They are mainly designed in sequential pipelines, requiring lots of data to train different sub-systems, and are hard to scale to new domains. Recently, Large Language Models (LLMs) have demonstrated remarkable generalized capabilities, enabling a singular model to tackle diverse recommendation tasks across various scenarios. Nonetheless, existing LLM-based recommendation systems utilize LLM purely for a single task of the recommendation pipeline. Besides, these systems face challenges in presenting large-scale item sets to LLMs in natural language format, due to the constraint of input length. To address these challenges, we introduce an LLM-based end-to-end recommendation framework: UniLLMRec. Specifically, UniLLMRec integrates multi-stage tasks (e.g. recall, ranking, re-ranking) via chain-of-recommendations. To deal with large-scale items, we propose a novel strategy to structure all items into an item tree, which can be dynamically updated and effectively retrieved. UniLLMRec shows promising zero-shot results in comparison with conventional supervised models. Additionally, it boasts high efficiency, reducing the input token need by 86% compared to existing LLM-based models. Such efficiency not only accelerates task completion but also optimizes resource utilization. To facilitate model understanding and to ensure reproducibility, we have made our code publicly available.
Sequential Recommendation for Optimizing Both Immediate Feedback and Long-term Retention
Apr 04, 2024In the landscape of Recommender System (RS) applications, reinforcement learning (RL) has recently emerged as a powerful tool, primarily due to its proficiency in optimizing long-term rewards. Nevertheless, it suffers from instability in the learning process, stemming from the intricate interactions among bootstrapping, off-policy training, and function approximation. Moreover, in multi-reward recommendation scenarios, designing a proper reward setting that reconciles the inner dynamics of various tasks is quite intricate. In response to these challenges, we introduce DT4IER, an advanced decision transformer-based recommendation model that is engineered to not only elevate the effectiveness of recommendations but also to achieve a harmonious balance between immediate user engagement and long-term retention. The DT4IER applies an innovative multi-reward design that adeptly balances short and long-term rewards with user-specific attributes, which serve to enhance the contextual richness of the reward sequence ensuring a more informed and personalized recommendation process. To enhance its predictive capabilities, DT4IER incorporates a high-dimensional encoder, skillfully designed to identify and leverage the intricate interrelations across diverse tasks. Furthermore, we integrate a contrastive learning approach within the action embedding predictions, a strategy that significantly boosts the model's overall performance. Experiments on three real-world datasets demonstrate the effectiveness of DT4IER against state-of-the-art Sequential Recommender Systems (SRSs) and Multi-Task Learning (MTL) models in terms of both prediction accuracy and effectiveness in specific tasks. The source code is accessible online to facilitate replication
ERASE: Benchmarking Feature Selection Methods for Deep Recommender Systems
Mar 20, 2024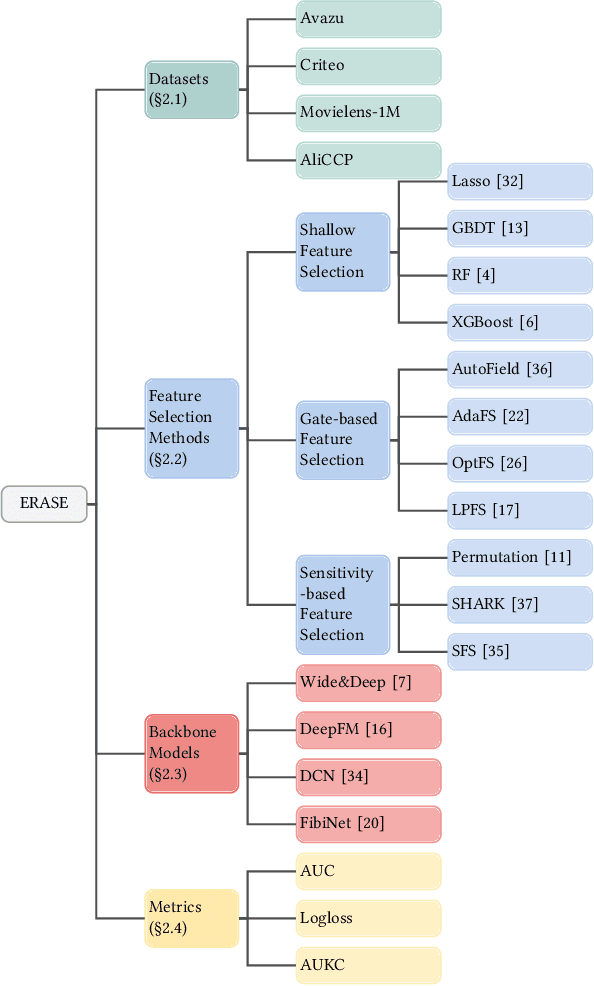
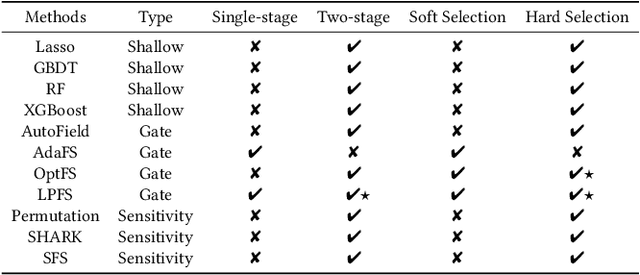
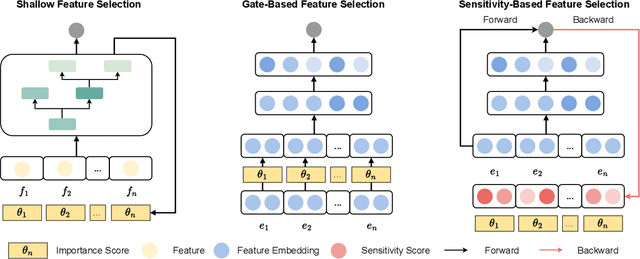
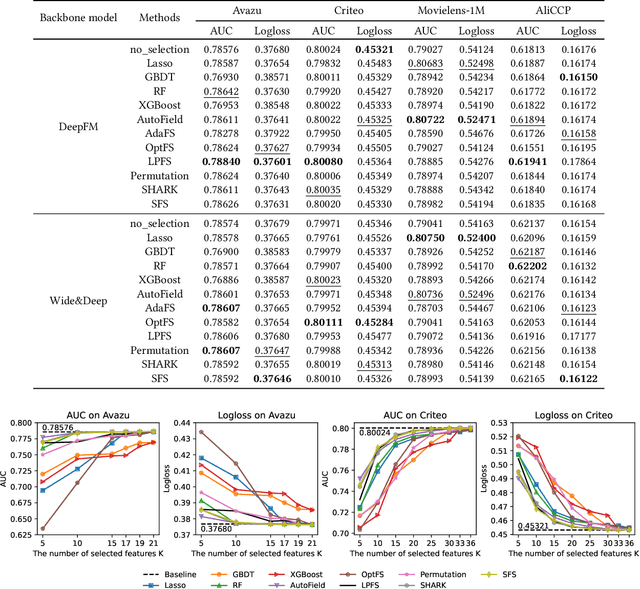
Deep Recommender Systems (DRS) are increasingly dependent on a large number of feature fields for more precise recommendations. Effective feature selection methods are consequently becoming critical for further enhancing the accuracy and optimizing storage efficiencies to align with the deployment demands. This research area, particularly in the context of DRS, is nascent and faces three core challenges. Firstly, variant experimental setups across research papers often yield unfair comparisons, obscuring practical insights. Secondly, the existing literature's lack of detailed analysis on selection attributes, based on large-scale datasets and a thorough comparison among selection techniques and DRS backbones, restricts the generalizability of findings and impedes deployment on DRS. Lastly, research often focuses on comparing the peak performance achievable by feature selection methods, an approach that is typically computationally infeasible for identifying the optimal hyperparameters and overlooks evaluating the robustness and stability of these methods. To bridge these gaps, this paper presents ERASE, a comprehensive bEnchmaRk for feAture SElection for DRS. ERASE comprises a thorough evaluation of eleven feature selection methods, covering both traditional and deep learning approaches, across four public datasets, private industrial datasets, and a real-world commercial platform, achieving significant enhancement. Our code is available online for ease of reproduction.
SSDRec: Self-Augmented Sequence Denoising for Sequential Recommendation
Mar 07, 2024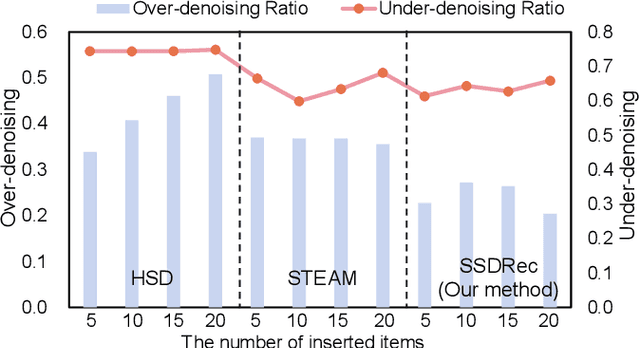
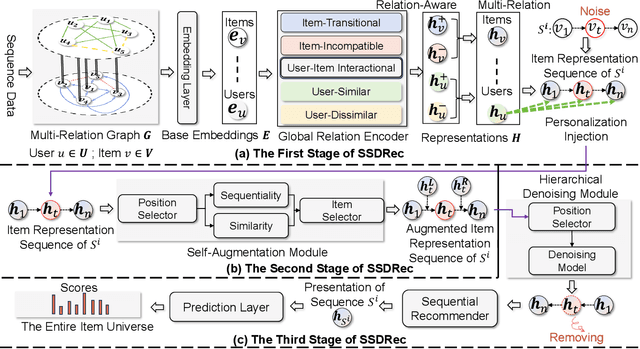
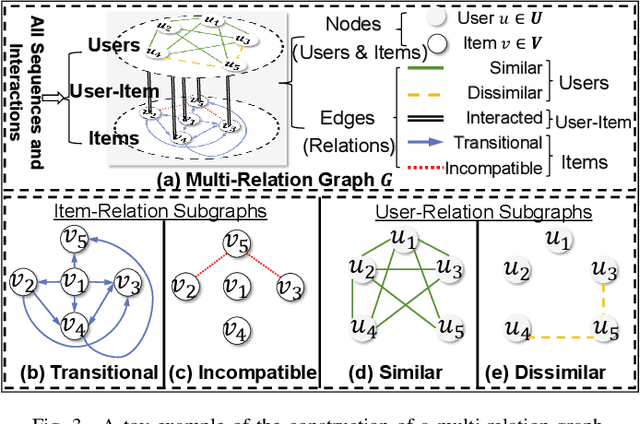
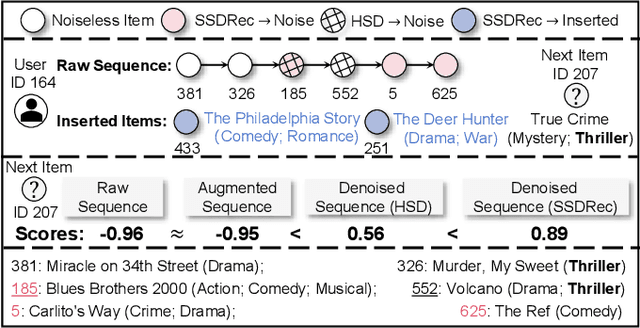
Traditional sequential recommendation methods assume that users' sequence data is clean enough to learn accurate sequence representations to reflect user preferences. In practice, users' sequences inevitably contain noise (e.g., accidental interactions), leading to incorrect reflections of user preferences. Consequently, some pioneer studies have explored modeling sequentiality and correlations in sequences to implicitly or explicitly reduce noise's influence. However, relying on only available intra-sequence information (i.e., sequentiality and correlations in a sequence) is insufficient and may result in over-denoising and under-denoising problems (OUPs), especially for short sequences. To improve reliability, we propose to augment sequences by inserting items before denoising. However, due to the data sparsity issue and computational costs, it is challenging to select proper items from the entire item universe to insert into proper positions in a target sequence. Motivated by the above observation, we propose a novel framework--Self-augmented Sequence Denoising for sequential Recommendation (SSDRec) with a three-stage learning paradigm to solve the above challenges. In the first stage, we empower SSDRec by a global relation encoder to learn multi-faceted inter-sequence relations in a data-driven manner. These relations serve as prior knowledge to guide subsequent stages. In the second stage, we devise a self-augmentation module to augment sequences to alleviate OUPs. Finally, we employ a hierarchical denoising module in the third stage to reduce the risk of false augmentations and pinpoint all noise in raw sequences. Extensive experiments on five real-world datasets demonstrate the superiority of \model over state-of-the-art denoising methods and its flexible applications to mainstream sequential recommendation models. The source code is available at https://github.com/zc-97/SSDRec.
The 2nd Workshop on Recommendation with Generative Models
Mar 07, 2024
The rise of generative models has driven significant advancements in recommender systems, leaving unique opportunities for enhancing users' personalized recommendations. This workshop serves as a platform for researchers to explore and exchange innovative concepts related to the integration of generative models into recommender systems. It primarily focuses on five key perspectives: (i) improving recommender algorithms, (ii) generating personalized content, (iii) evolving the user-system interaction paradigm, (iv) enhancing trustworthiness checks, and (v) refining evaluation methodologies for generative recommendations. With generative models advancing rapidly, an increasing body of research is emerging in these domains, underscoring the timeliness and critical importance of this workshop. The related research will introduce innovative technologies to recommender systems and contribute to fresh challenges in both academia and industry. In the long term, this research direction has the potential to revolutionize the traditional recommender paradigms and foster the development of next-generation recommender systems.
BiVRec: Bidirectional View-based Multimodal Sequential Recommendation
Mar 05, 2024The integration of multimodal information into sequential recommender systems has attracted significant attention in recent research. In the initial stages of multimodal sequential recommendation models, the mainstream paradigm was ID-dominant recommendations, wherein multimodal information was fused as side information. However, due to their limitations in terms of transferability and information intrusion, another paradigm emerged, wherein multimodal features were employed directly for recommendation, enabling recommendation across datasets. Nonetheless, it overlooked user ID information, resulting in low information utilization and high training costs. To this end, we propose an innovative framework, BivRec, that jointly trains the recommendation tasks in both ID and multimodal views, leveraging their synergistic relationship to enhance recommendation performance bidirectionally. To tackle the information heterogeneity issue, we first construct structured user interest representations and then learn the synergistic relationship between them. Specifically, BivRec comprises three modules: Multi-scale Interest Embedding, comprehensively modeling user interests by expanding user interaction sequences with multi-scale patching; Intra-View Interest Decomposition, constructing highly structured interest representations using carefully designed Gaussian attention and Cluster attention; and Cross-View Interest Learning, learning the synergistic relationship between the two recommendation views through coarse-grained overall semantic similarity and fine-grained interest allocation similarity BiVRec achieves state-of-the-art performance on five datasets and showcases various practical advantages.
Multi-perspective Improvement of Knowledge Graph Completion with Large Language Models
Mar 04, 2024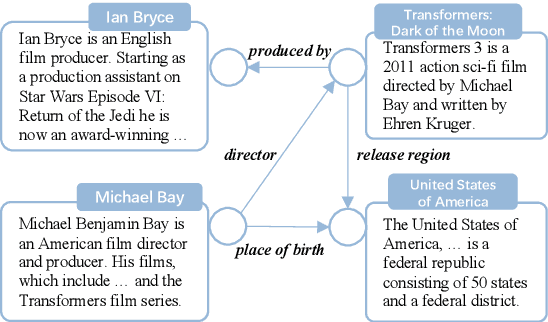

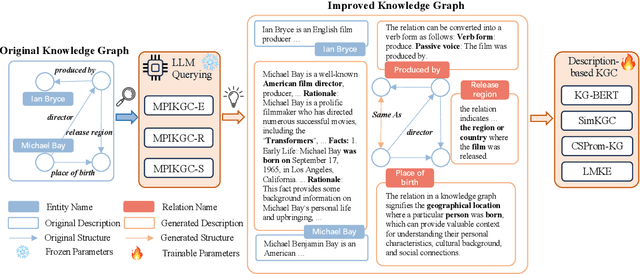
Knowledge graph completion (KGC) is a widely used method to tackle incompleteness in knowledge graphs (KGs) by making predictions for missing links. Description-based KGC leverages pre-trained language models to learn entity and relation representations with their names or descriptions, which shows promising results. However, the performance of description-based KGC is still limited by the quality of text and the incomplete structure, as it lacks sufficient entity descriptions and relies solely on relation names, leading to sub-optimal results. To address this issue, we propose MPIKGC, a general framework to compensate for the deficiency of contextualized knowledge and improve KGC by querying large language models (LLMs) from various perspectives, which involves leveraging the reasoning, explanation, and summarization capabilities of LLMs to expand entity descriptions, understand relations, and extract structures, respectively. We conducted extensive evaluation of the effectiveness and improvement of our framework based on four description-based KGC models and four datasets, for both link prediction and triplet classification tasks.