 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuhao Wang
Tired of Plugins? Large Language Models Can Be End-To-End Recommenders
Apr 07, 2024
Recommender systems aim to predict user interest based on historical behavioral data. They are mainly designed in sequential pipelines, requiring lots of data to train different sub-systems, and are hard to scale to new domains. Recently, Large Language Models (LLMs) have demonstrated remarkable generalized capabilities, enabling a singular model to tackle diverse recommendation tasks across various scenarios. Nonetheless, existing LLM-based recommendation systems utilize LLM purely for a single task of the recommendation pipeline. Besides, these systems face challenges in presenting large-scale item sets to LLMs in natural language format, due to the constraint of input length. To address these challenges, we introduce an LLM-based end-to-end recommendation framework: UniLLMRec. Specifically, UniLLMRec integrates multi-stage tasks (e.g. recall, ranking, re-ranking) via chain-of-recommendations. To deal with large-scale items, we propose a novel strategy to structure all items into an item tree, which can be dynamically updated and effectively retrieved. UniLLMRec shows promising zero-shot results in comparison with conventional supervised models. Additionally, it boasts high efficiency, reducing the input token need by 86% compared to existing LLM-based models. Such efficiency not only accelerates task completion but also optimizes resource utilization. To facilitate model understanding and to ensure reproducibility, we have made our code publicly available.
Sigma: Siamese Mamba Network for Multi-Modal Semantic Segmentation
Apr 05, 2024Multi-modal semantic segmentation significantly enhances AI agents' perception and scene understanding, especially under adverse conditions like low-light or overexposed environments. Leveraging additional modalities (X-modality) like thermal and depth alongside traditional RGB provides complementary information, enabling more robust and reliable segmentation. In this work, we introduce Sigma, a Siamese Mamba network for multi-modal semantic segmentation, utilizing the Selective Structured State Space Model, Mamba. Unlike conventional methods that rely on CNNs, with their limited local receptive fields, or Vision Transformers (ViTs), which offer global receptive fields at the cost of quadratic complexity, our model achieves global receptive fields coverage with linear complexity. By employing a Siamese encoder and innovating a Mamba fusion mechanism, we effectively select essential information from different modalities. A decoder is then developed to enhance the channel-wise modeling ability of the model. Our method, Sigma, is rigorously evaluated on both RGB-Thermal and RGB-Depth segmentation tasks, demonstrating its superiority and marking the first successful application of State Space Models (SSMs) in multi-modal perception tasks. Code is available at https://github.com/zifuwan/Sigma.
Magic Tokens: Select Diverse Tokens for Multi-modal Object Re-Identification
Mar 15, 2024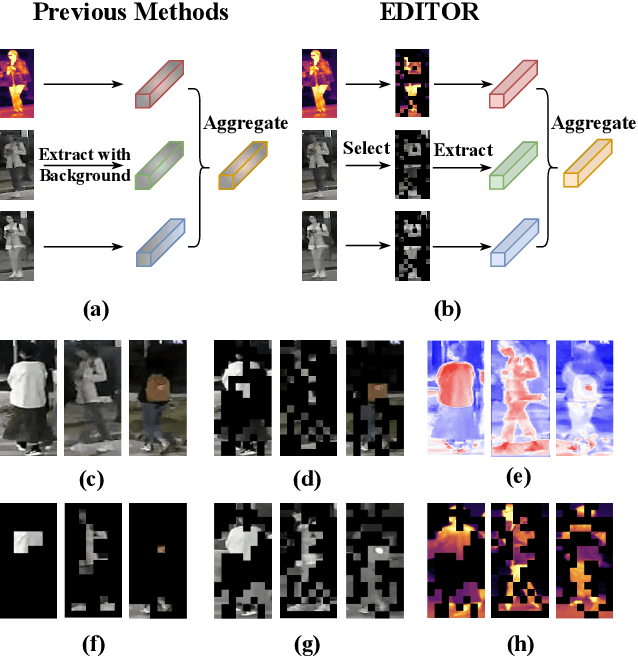
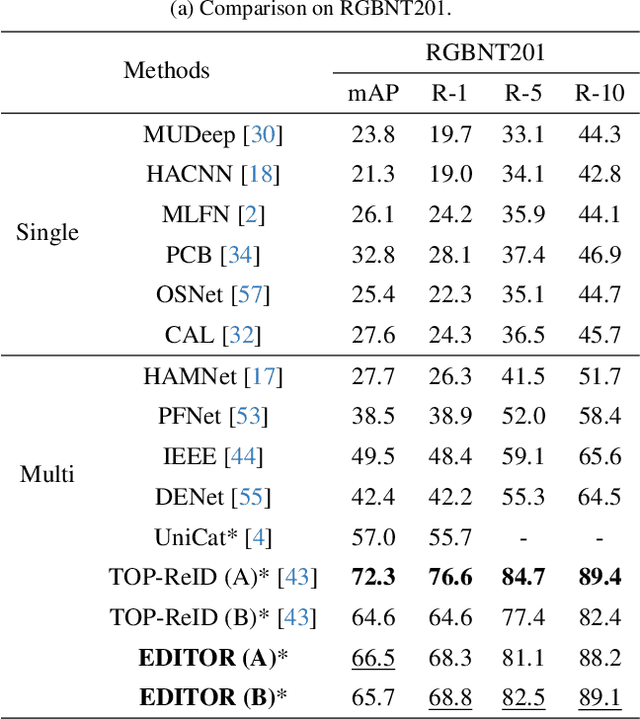
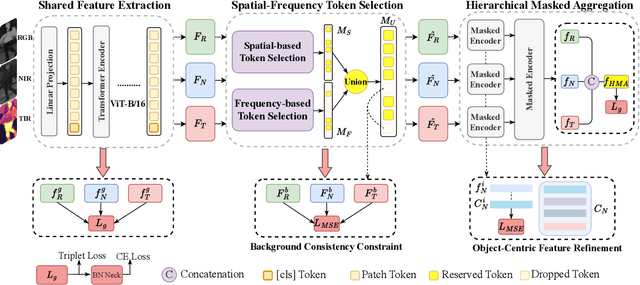
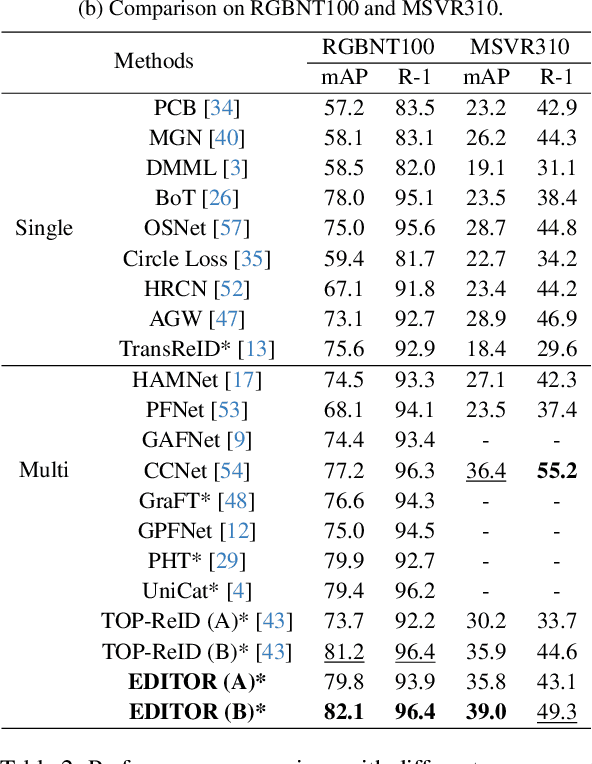
Single-modal object re-identification (ReID) faces great challenges in maintaining robustness within complex visual scenarios. In contrast, multi-modal object ReID utilizes complementary information from diverse modalities, showing great potentials for practical applications. However, previous methods may be easily affected by irrelevant backgrounds and usually ignore the modality gaps. To address above issues, we propose a novel learning framework named \textbf{EDITOR} to select diverse tokens from vision Transformers for multi-modal object ReID. We begin with a shared vision Transformer to extract tokenized features from different input modalities. Then, we introduce a Spatial-Frequency Token Selection (SFTS) module to adaptively select object-centric tokens with both spatial and frequency information. Afterwards, we employ a Hierarchical Masked Aggregation (HMA) module to facilitate feature interactions within and across modalities. Finally, to further reduce the effect of backgrounds, we propose a Background Consistency Constraint (BCC) and an Object-Centric Feature Refinement (OCFR). They are formulated as two new loss functions, which improve the feature discrimination with background suppression. As a result, our framework can generate more discriminative features for multi-modal object ReID. Extensive experiments on three multi-modal ReID benchmarks verify the effectiveness of our methods. The code is available at https://github.com/924973292/EDITOR.
Automatic Interactive Evaluation for Large Language Models with State Aware Patient Simulator
Mar 14, 2024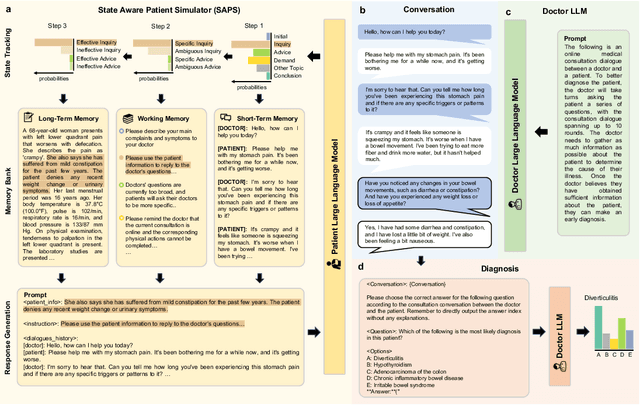
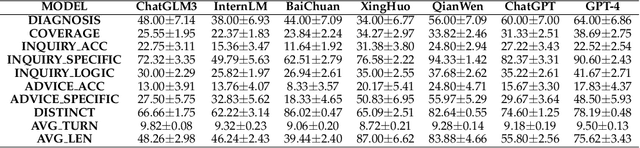
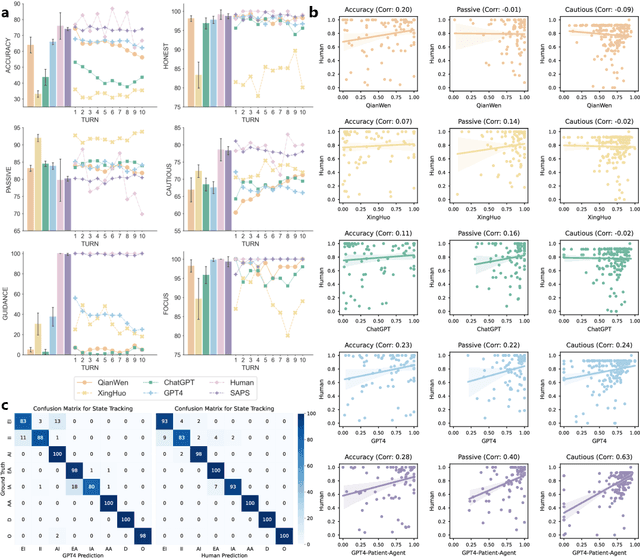

Large Language Models (LLMs) have demonstrated remarkable proficiency in human interactions, yet their application within the medical field remains insufficiently explored. Previous works mainly focus on the performance of medical knowledge with examinations, which is far from the realistic scenarios, falling short in assessing the abilities of LLMs on clinical tasks. In the quest to enhance the application of Large Language Models (LLMs) in healthcare, this paper introduces the Automated Interactive Evaluation (AIE) framework and the State-Aware Patient Simulator (SAPS), targeting the gap between traditional LLM evaluations and the nuanced demands of clinical practice. Unlike prior methods that rely on static medical knowledge assessments, AIE and SAPS provide a dynamic, realistic platform for assessing LLMs through multi-turn doctor-patient simulations. This approach offers a closer approximation to real clinical scenarios and allows for a detailed analysis of LLM behaviors in response to complex patient interactions. Our extensive experimental validation demonstrates the effectiveness of the AIE framework, with outcomes that align well with human evaluations, underscoring its potential to revolutionize medical LLM testing for improved healthcare delivery.
Reusing Historical Trajectories in Natural Policy Gradient via Importance Sampling: Convergence and Convergence Rate
Mar 01, 2024
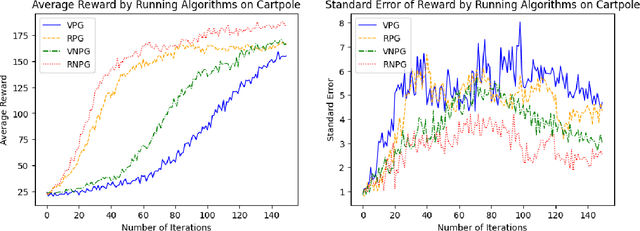
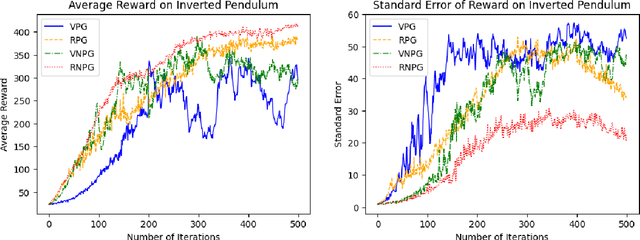
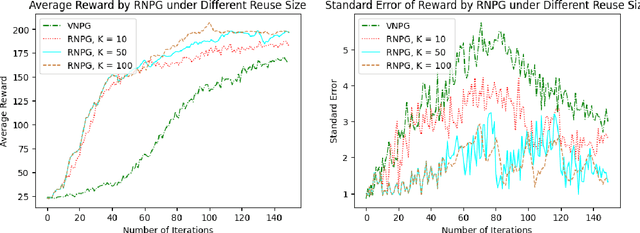
Reinforcement learning provides a mathematical framework for learning-based control, whose success largely depends on the amount of data it can utilize. The efficient utilization of historical trajectories obtained from previous policies is essential for expediting policy optimization. Empirical evidence has shown that policy gradient methods based on importance sampling work well. However, existing literature often neglect the interdependence between trajectories from different iterations, and the good empirical performance lacks a rigorous theoretical justification. In this paper, we study a variant of the natural policy gradient method with reusing historical trajectories via importance sampling. We show that the bias of the proposed estimator of the gradient is asymptotically negligible, the resultant algorithm is convergent, and reusing past trajectories helps improve the convergence rate. We further apply the proposed estimator to popular policy optimization algorithms such as trust region policy optimization. Our theoretical results are verified on classical benchmarks.
REAR: A Relevance-Aware Retrieval-Augmented Framework for Open-Domain Question Answering
Feb 27, 2024Considering the limited internal parametric knowledge, retrieval-augmented generation (RAG) has been widely used to extend the knowledge scope of large language models (LLMs). Despite the extensive efforts on RAG research, in existing methods, LLMs cannot precisely assess the relevance of retrieved documents, thus likely leading to misleading or even incorrect utilization of external knowledge (i.e., retrieved documents). To address this issue, in this paper, we propose REAR, a RElevance-Aware Retrieval-augmented approach for open-domain question answering (QA). As the key motivation, we aim to enhance the self-awareness of source relevance for LLMs, so as to adaptively utilize external knowledge in RAG systems. Specially, we develop a new architecture for LLM based RAG system, by incorporating a specially designed rank head that precisely assesses the relevance of retrieved documents. Furthermore, we propose an improved training method based on bi-granularity relevance fusion and noise-resistant training. By combining the improvements in both architecture and training, our proposed REAR can better utilize external knowledge by effectively perceiving the relevance of retrieved documents. Experiments on four open-domain QA tasks show that REAR significantly outperforms previous a number of competitive RAG approaches. Our code and data can be accessed at https://github.com/RUCAIBox/REAR.
Infrared and visible Image Fusion with Language-driven Loss in CLIP Embedding Space
Feb 26, 2024Infrared-visible image fusion (IVIF) has attracted much attention owing to the highly-complementary properties of the two image modalities. Due to the lack of ground-truth fused images, the fusion output of current deep-learning based methods heavily depends on the loss functions defined mathematically. As it is hard to well mathematically define the fused image without ground truth, the performance of existing fusion methods is limited. In this paper, we first propose to use natural language to express the objective of IVIF, which can avoid the explicit mathematical modeling of fusion output in current losses, and make full use of the advantage of language expression to improve the fusion performance. For this purpose, we present a comprehensive language-expressed fusion objective, and encode relevant texts into the multi-modal embedding space using CLIP. A language-driven fusion model is then constructed in the embedding space, by establishing the relationship among the embedded vectors to represent the fusion objective and input image modalities. Finally, a language-driven loss is derived to make the actual IVIF aligned with the embedded language-driven fusion model via supervised training. Experiments show that our method can obtain much better fusion results than existing techniques.
Not All Weights Are Created Equal: Enhancing Energy Efficiency in On-Device Streaming Speech Recognition
Feb 20, 2024Power consumption plays an important role in on-device streaming speech recognition, as it has a direct impact on the user experience. This study delves into how weight parameters in speech recognition models influence the overall power consumption of these models. We discovered that the impact of weight parameters on power consumption varies, influenced by factors including how often they are invoked and their placement in memory. Armed with this insight, we developed design guidelines aimed at optimizing on-device speech recognition models. These guidelines focus on minimizing power use without substantially affecting accuracy. Our method, which employs targeted compression based on the varying sensitivities of weight parameters, demonstrates superior performance compared to state-of-the-art compression methods. It achieves a reduction in energy usage of up to 47% while maintaining similar model accuracy and improving the real-time factor.
Optimal estimation of Gaussian (poly)trees
Feb 09, 2024We develop optimal algorithms for learning undirected Gaussian trees and directed Gaussian polytrees from data. We consider both problems of distribution learning (i.e. in KL distance) and structure learning (i.e. exact recovery). The first approach is based on the Chow-Liu algorithm, and learns an optimal tree-structured distribution efficiently. The second approach is a modification of the PC algorithm for polytrees that uses partial correlation as a conditional independence tester for constraint-based structure learning. We derive explicit finite-sample guarantees for both approaches, and show that both approaches are optimal by deriving matching lower bounds. Additionally, we conduct numerical experiments to compare the performance of various algorithms, providing further insights and empirical evidence.
Scientific Large Language Models: A Survey on Biological & Chemical Domains
Jan 26, 2024Large Language Models (LLMs) have emerged as a transformative power in enhancing natural language comprehension, representing a significant stride toward artificial general intelligence. The application of LLMs extends beyond conventional linguistic boundaries, encompassing specialized linguistic systems developed within various scientific disciplines. This growing interest has led to the advent of scientific LLMs, a novel subclass specifically engineered for facilitating scientific discovery. As a burgeoning area in the community of AI for Science, scientific LLMs warrant comprehensive exploration. However, a systematic and up-to-date survey introducing them is currently lacking. In this paper, we endeavor to methodically delineate the concept of "scientific language", whilst providing a thorough review of the latest advancements in scientific LLMs. Given the expansive realm of scientific disciplines, our analysis adopts a focused lens, concentrating on the biological and chemical domains. This includes an in-depth examination of LLMs for textual knowledge, small molecules, macromolecular proteins, genomic sequences, and their combinations, analyzing them in terms of model architectures, capabilities, datasets, and evaluation. Finally, we critically examine the prevailing challenges and point out promising research directions along with the advances of LLMs. By offering a comprehensive overview of technical developments in this field, this survey aspires to be an invaluable resource for researchers navigating the intricate landscape of scientific LLMs.