 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongyang Chen
Physical formula enhanced multi-task learning for pharmacokinetics prediction
Apr 16, 2024
Artificial intelligence (AI) technology has demonstrated remarkable potential in drug dis-covery, where pharmacokinetics plays a crucial role in determining the dosage, safety, and efficacy of new drugs. A major challenge for AI-driven drug discovery (AIDD) is the scarcity of high-quality data, which often requires extensive wet-lab work. A typical example of this is pharmacokinetic experiments. In this work, we develop a physical formula enhanced mul-ti-task learning (PEMAL) method that predicts four key parameters of pharmacokinetics simultaneously. By incorporating physical formulas into the multi-task framework, PEMAL facilitates effective knowledge sharing and target alignment among the pharmacokinetic parameters, thereby enhancing the accuracy of prediction. Our experiments reveal that PEMAL significantly lowers the data demand, compared to typical Graph Neural Networks. Moreover, we demonstrate that PEMAL enhances the robustness to noise, an advantage that conventional Neural Networks do not possess. Another advantage of PEMAL is its high flexibility, which can be potentially applied to other multi-task machine learning scenarios. Overall, our work illustrates the benefits and potential of using PEMAL in AIDD and other scenarios with data scarcity and noise.
Collaborate to Adapt: Source-Free Graph Domain Adaptation via Bi-directional Adaptation
Mar 03, 2024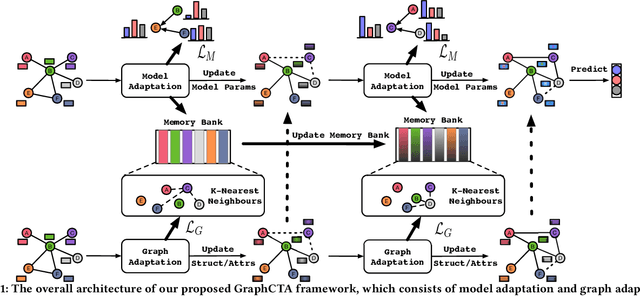
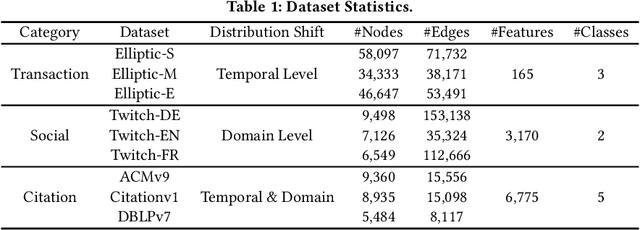
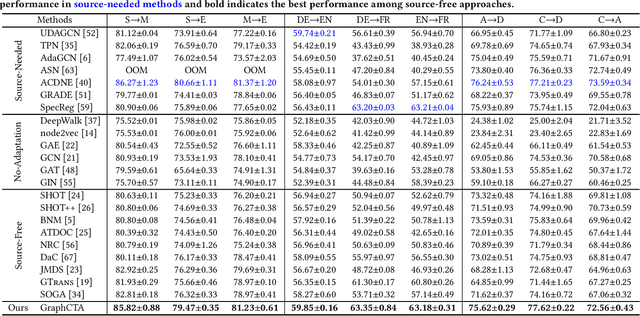
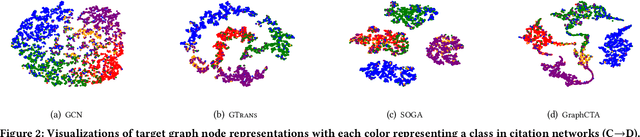
Unsupervised Graph Domain Adaptation (UGDA) has emerged as a practical solution to transfer knowledge from a label-rich source graph to a completely unlabelled target graph. However, most methods require a labelled source graph to provide supervision signals, which might not be accessible in the real-world settings due to regulations and privacy concerns. In this paper, we explore the scenario of source-free unsupervised graph domain adaptation, which tries to address the domain adaptation problem without accessing the labelled source graph. Specifically, we present a novel paradigm called GraphCTA, which performs model adaptation and graph adaptation collaboratively through a series of procedures: (1) conduct model adaptation based on node's neighborhood predictions in target graph considering both local and global information; (2) perform graph adaptation by updating graph structure and node attributes via neighborhood contrastive learning; and (3) the updated graph serves as an input to facilitate the subsequent iteration of model adaptation, thereby establishing a collaborative loop between model adaptation and graph adaptation. Comprehensive experiments are conducted on various public datasets. The experimental results demonstrate that our proposed model outperforms recent source-free baselines by large margins.
HQA-Attack: Toward High Quality Black-Box Hard-Label Adversarial Attack on Text
Feb 02, 2024Black-box hard-label adversarial attack on text is a practical and challenging task, as the text data space is inherently discrete and non-differentiable, and only the predicted label is accessible. Research on this problem is still in the embryonic stage and only a few methods are available. Nevertheless, existing methods rely on the complex heuristic algorithm or unreliable gradient estimation strategy, which probably fall into the local optimum and inevitably consume numerous queries, thus are difficult to craft satisfactory adversarial examples with high semantic similarity and low perturbation rate in a limited query budget. To alleviate above issues, we propose a simple yet effective framework to generate high quality textual adversarial examples under the black-box hard-label attack scenarios, named HQA-Attack. Specifically, after initializing an adversarial example randomly, HQA-attack first constantly substitutes original words back as many as possible, thus shrinking the perturbation rate. Then it leverages the synonym set of the remaining changed words to further optimize the adversarial example with the direction which can improve the semantic similarity and satisfy the adversarial condition simultaneously. In addition, during the optimizing procedure, it searches a transition synonym word for each changed word, thus avoiding traversing the whole synonym set and reducing the query number to some extent. Extensive experimental results on five text classification datasets, three natural language inference datasets and two real-world APIs have shown that the proposed HQA-Attack method outperforms other strong baselines significantly.
Two Heads Are Better Than One: Integrating Knowledge from Knowledge Graphs and Large Language Models for Entity Alignment
Jan 30, 2024Entity alignment, which is a prerequisite for creating a more comprehensive Knowledge Graph (KG), involves pinpointing equivalent entities across disparate KGs. Contemporary methods for entity alignment have predominantly utilized knowledge embedding models to procure entity embeddings that encapsulate various similarities-structural, relational, and attributive. These embeddings are then integrated through attention-based information fusion mechanisms. Despite this progress, effectively harnessing multifaceted information remains challenging due to inherent heterogeneity. Moreover, while Large Language Models (LLMs) have exhibited exceptional performance across diverse downstream tasks by implicitly capturing entity semantics, this implicit knowledge has yet to be exploited for entity alignment. In this study, we propose a Large Language Model-enhanced Entity Alignment framework (LLMEA), integrating structural knowledge from KGs with semantic knowledge from LLMs to enhance entity alignment. Specifically, LLMEA identifies candidate alignments for a given entity by considering both embedding similarities between entities across KGs and edit distances to a virtual equivalent entity. It then engages an LLM iteratively, posing multiple multi-choice questions to draw upon the LLM's inference capability. The final prediction of the equivalent entity is derived from the LLM's output. Experiments conducted on three public datasets reveal that LLMEA surpasses leading baseline models. Additional ablation studies underscore the efficacy of our proposed framework.
Diffusion-based graph generative methods
Jan 28, 2024Being the most cutting-edge generative methods, diffusion methods have shown great advances in wide generation tasks. Among them, graph generation attracts significant research attention for its broad application in real life. In our survey, we systematically and comprehensively review on diffusion-based graph generative methods. We first make a review on three mainstream paradigms of diffusion methods, which are denoising diffusion probabilistic models, score-based genrative models, and stochastic differential equations. Then we further categorize and introduce the latest applications of diffusion models on graphs. In the end, we point out some limitations of current studies and future directions of future explorations. The summary of existing methods metioned in this survey is in https://github.com/zhejiangzhuque/Diffusion-based-Graph-Generative-Methods.
Scientific Large Language Models: A Survey on Biological & Chemical Domains
Jan 26, 2024Large Language Models (LLMs) have emerged as a transformative power in enhancing natural language comprehension, representing a significant stride toward artificial general intelligence. The application of LLMs extends beyond conventional linguistic boundaries, encompassing specialized linguistic systems developed within various scientific disciplines. This growing interest has led to the advent of scientific LLMs, a novel subclass specifically engineered for facilitating scientific discovery. As a burgeoning area in the community of AI for Science, scientific LLMs warrant comprehensive exploration. However, a systematic and up-to-date survey introducing them is currently lacking. In this paper, we endeavor to methodically delineate the concept of "scientific language", whilst providing a thorough review of the latest advancements in scientific LLMs. Given the expansive realm of scientific disciplines, our analysis adopts a focused lens, concentrating on the biological and chemical domains. This includes an in-depth examination of LLMs for textual knowledge, small molecules, macromolecular proteins, genomic sequences, and their combinations, analyzing them in terms of model architectures, capabilities, datasets, and evaluation. Finally, we critically examine the prevailing challenges and point out promising research directions along with the advances of LLMs. By offering a comprehensive overview of technical developments in this field, this survey aspires to be an invaluable resource for researchers navigating the intricate landscape of scientific LLMs.
Geometric-Facilitated Denoising Diffusion Model for 3D Molecule Generation
Jan 05, 2024Denoising diffusion models have shown great potential in multiple research areas. Existing diffusion-based generative methods on de novo 3D molecule generation face two major challenges. Since majority heavy atoms in molecules allow connections to multiple atoms through single bonds, solely using pair-wise distance to model molecule geometries is insufficient. Therefore, the first one involves proposing an effective neural network as the denoising kernel that is capable to capture complex multi-body interatomic relationships and learn high-quality features. Due to the discrete nature of graphs, mainstream diffusion-based methods for molecules heavily rely on predefined rules and generate edges in an indirect manner. The second challenge involves accommodating molecule generation to diffusion and accurately predicting the existence of bonds. In our research, we view the iterative way of updating molecule conformations in diffusion process is consistent with molecular dynamics and introduce a novel molecule generation method named Geometric-Facilitated Molecular Diffusion (GFMDiff). For the first challenge, we introduce a Dual-Track Transformer Network (DTN) to fully excevate global spatial relationships and learn high quality representations which contribute to accurate predictions of features and geometries. As for the second challenge, we design Geometric-Facilitated Loss (GFLoss) which intervenes the formation of bonds during the training period, instead of directly embedding edges into the latent space. Comprehensive experiments on current benchmarks demonstrate the superiority of GFMDiff.
Deep Learning Assisted Multiuser MIMO Load Modulated Systems for Enhanced Downlink mmWave Communications
Nov 08, 2023This paper is focused on multiuser load modulation arrays (MU-LMAs) which are attractive due to their low system complexity and reduced cost for millimeter wave (mmWave) multi-input multi-output (MIMO) systems. The existing precoding algorithm for downlink MU-LMA relies on a sub-array structured (SAS) transmitter which may suffer from decreased degrees of freedom and complex system configuration. Furthermore, a conventional LMA codebook with codewords uniformly distributed on a hypersphere may not be channel-adaptive and may lead to increased signal detection complexity. In this paper, we conceive an MU-LMA system employing a full-array structured (FAS) transmitter and propose two algorithms accordingly. The proposed FAS-based system addresses the SAS structural problems and can support larger numbers of users. For LMA-imposed constant-power downlink precoding, we propose an FAS-based normalized block diagonalization (FAS-NBD) algorithm. However, the forced normalization may result in performance degradation. This degradation, together with the aforementioned codebook design problems, is difficult to solve analytically. This motivates us to propose a Deep Learning-enhanced (FAS-DL-NBD) algorithm for adaptive codebook design and codebook-independent decoding. It is shown that the proposed algorithms are robust to imperfect knowledge of channel state information and yield excellent error performance. Moreover, the FAS-DL-NBD algorithm enables signal detection with low complexity as the number of bits per codeword increases.
Debunking Free Fusion Myth: Online Multi-view Anomaly Detection with Disentangled Product-of-Experts Modeling
Oct 31, 2023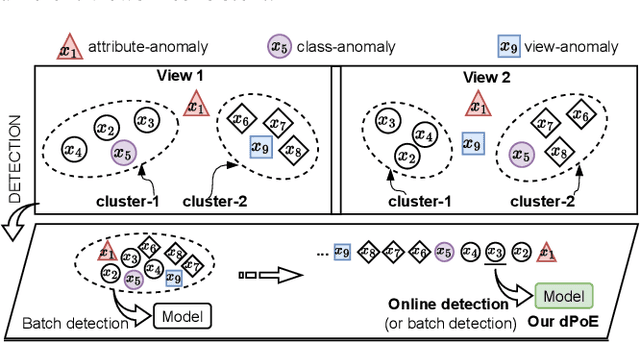
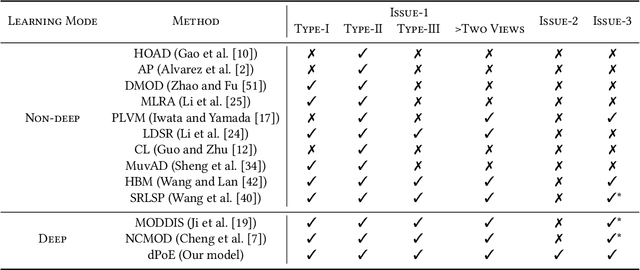
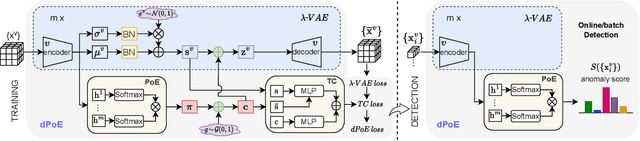

Multi-view or even multi-modal data is appealing yet challenging for real-world applications. Detecting anomalies in multi-view data is a prominent recent research topic. However, most of the existing methods 1) are only suitable for two views or type-specific anomalies, 2) suffer from the issue of fusion disentanglement, and 3) do not support online detection after model deployment. To address these challenges, our main ideas in this paper are three-fold: multi-view learning, disentangled representation learning, and generative model. To this end, we propose dPoE, a novel multi-view variational autoencoder model that involves (1) a Product-of-Experts (PoE) layer in tackling multi-view data, (2) a Total Correction (TC) discriminator in disentangling view-common and view-specific representations, and (3) a joint loss function in wrapping up all components. In addition, we devise theoretical information bounds to control both view-common and view-specific representations. Extensive experiments on six real-world datasets markedly demonstrate that the proposed dPoE outperforms baselines.
Boosting Decision-Based Black-Box Adversarial Attack with Gradient Priors
Oct 29, 2023
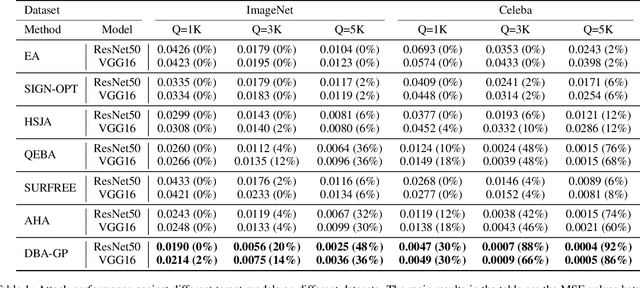
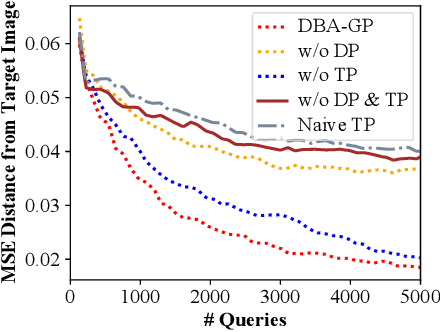
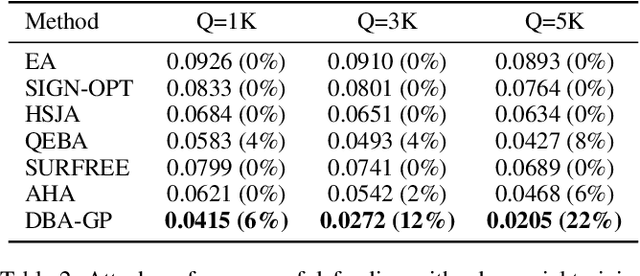
Decision-based methods have shown to be effective in black-box adversarial attacks, as they can obtain satisfactory performance and only require to access the final model prediction. Gradient estimation is a critical step in black-box adversarial attacks, as it will directly affect the query efficiency. Recent works have attempted to utilize gradient priors to facilitate score-based methods to obtain better results. However, these gradient priors still suffer from the edge gradient discrepancy issue and the successive iteration gradient direction issue, thus are difficult to simply extend to decision-based methods. In this paper, we propose a novel Decision-based Black-box Attack framework with Gradient Priors (DBA-GP), which seamlessly integrates the data-dependent gradient prior and time-dependent prior into the gradient estimation procedure. First, by leveraging the joint bilateral filter to deal with each random perturbation, DBA-GP can guarantee that the generated perturbations in edge locations are hardly smoothed, i.e., alleviating the edge gradient discrepancy, thus remaining the characteristics of the original image as much as possible. Second, by utilizing a new gradient updating strategy to automatically adjust the successive iteration gradient direction, DBA-GP can accelerate the convergence speed, thus improving the query efficiency. Extensive experiments have demonstrated that the proposed method outperforms other strong baselines significantly.