 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhen Zhang
Advancing the Robustness of Large Language Models through Self-Denoised Smoothing
Apr 18, 2024
Although large language models (LLMs) have achieved significant success, their vulnerability to adversarial perturbations, including recent jailbreak attacks, has raised considerable concerns. However, the increasing size of these models and their limited access make improving their robustness a challenging task. Among various defense strategies, randomized smoothing has shown great potential for LLMs, as it does not require full access to the model's parameters or fine-tuning via adversarial training. However, randomized smoothing involves adding noise to the input before model prediction, and the final model's robustness largely depends on the model's performance on these noise corrupted data. Its effectiveness is often limited by the model's sub-optimal performance on noisy data. To address this issue, we propose to leverage the multitasking nature of LLMs to first denoise the noisy inputs and then to make predictions based on these denoised versions. We call this procedure self-denoised smoothing. Unlike previous denoised smoothing techniques in computer vision, which require training a separate model to enhance the robustness of LLMs, our method offers significantly better efficiency and flexibility. Our experimental results indicate that our method surpasses existing methods in both empirical and certified robustness in defending against adversarial attacks for both downstream tasks and human alignments (i.e., jailbreak attacks). Our code is publicly available at https://github.com/UCSB-NLP-Chang/SelfDenoise
Communication-Efficient Large-Scale Distributed Deep Learning: A Comprehensive Survey
Apr 09, 2024With the rapid growth in the volume of data sets, models, and devices in the domain of deep learning, there is increasing attention on large-scale distributed deep learning. In contrast to traditional distributed deep learning, the large-scale scenario poses new challenges that include fault tolerance, scalability of algorithms and infrastructures, and heterogeneity in data sets, models, and resources. Due to intensive synchronization of models and sharing of data across GPUs and computing nodes during distributed training and inference processes, communication efficiency becomes the bottleneck for achieving high performance at a large scale. This article surveys the literature over the period of 2018-2023 on algorithms and technologies aimed at achieving efficient communication in large-scale distributed deep learning at various levels, including algorithms, frameworks, and infrastructures. Specifically, we first introduce efficient algorithms for model synchronization and communication data compression in the context of large-scale distributed training. Next, we introduce efficient strategies related to resource allocation and task scheduling for use in distributed training and inference. After that, we present the latest technologies pertaining to modern communication infrastructures used in distributed deep learning with a focus on examining the impact of the communication overhead in a large-scale and heterogeneous setting. Finally, we conduct a case study on the distributed training of large language models at a large scale to illustrate how to apply these technologies in real cases. This article aims to offer researchers a comprehensive understanding of the current landscape of large-scale distributed deep learning and to reveal promising future research directions toward communication-efficient solutions in this scope.
The Double-Edged Sword of Input Perturbations to Robust Accurate Fairness
Apr 01, 2024Deep neural networks (DNNs) are known to be sensitive to adversarial input perturbations, leading to a reduction in either prediction accuracy or individual fairness. To jointly characterize the susceptibility of prediction accuracy and individual fairness to adversarial perturbations, we introduce a novel robustness definition termed robust accurate fairness. Informally, robust accurate fairness requires that predictions for an instance and its similar counterparts consistently align with the ground truth when subjected to input perturbations. We propose an adversarial attack approach dubbed RAFair to expose false or biased adversarial defects in DNN, which either deceive accuracy or compromise individual fairness. Then, we show that such adversarial instances can be effectively addressed by carefully designed benign perturbations, correcting their predictions to be accurate and fair. Our work explores the double-edged sword of input perturbations to robust accurate fairness in DNN and the potential of using benign perturbations to correct adversarial instances.
Identifiable Latent Neural Causal Models
Mar 23, 2024Causal representation learning seeks to uncover latent, high-level causal representations from low-level observed data. It is particularly good at predictions under unseen distribution shifts, because these shifts can generally be interpreted as consequences of interventions. Hence leveraging {seen} distribution shifts becomes a natural strategy to help identifying causal representations, which in turn benefits predictions where distributions are previously {unseen}. Determining the types (or conditions) of such distribution shifts that do contribute to the identifiability of causal representations is critical. This work establishes a {sufficient} and {necessary} condition characterizing the types of distribution shifts for identifiability in the context of latent additive noise models. Furthermore, we present partial identifiability results when only a portion of distribution shifts meets the condition. In addition, we extend our findings to latent post-nonlinear causal models. We translate our findings into a practical algorithm, allowing for the acquisition of reliable latent causal representations. Our algorithm, guided by our underlying theory, has demonstrated outstanding performance across a diverse range of synthetic and real-world datasets. The empirical observations align closely with the theoretical findings, affirming the robustness and effectiveness of our approach.
A Causal Inspired Early-Branching Structure for Domain Generalization
Mar 13, 2024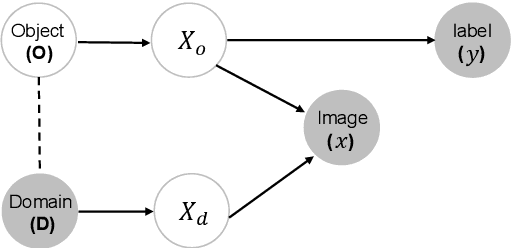
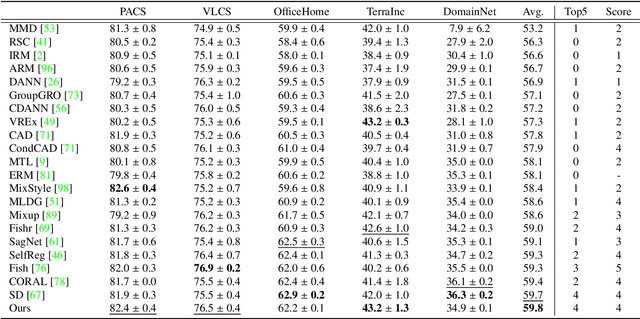
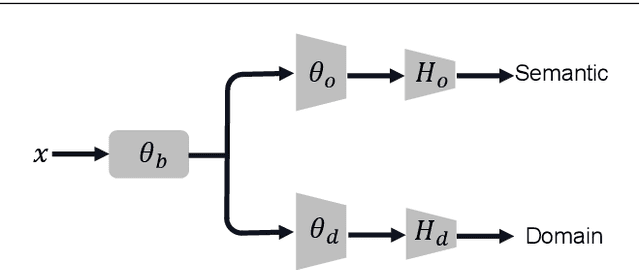
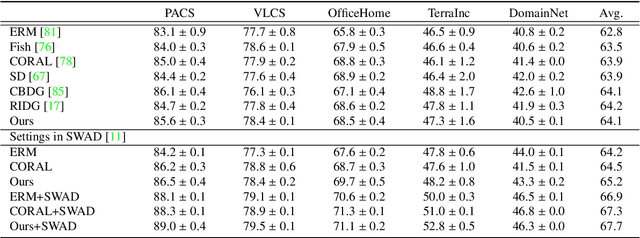
Learning domain-invariant semantic representations is crucial for achieving domain generalization (DG), where a model is required to perform well on unseen target domains. One critical challenge is that standard training often results in entangled semantic and domain-specific features. Previous works suggest formulating the problem from a causal perspective and solving the entanglement problem by enforcing marginal independence between the causal (\ie semantic) and non-causal (\ie domain-specific) features. Despite its simplicity, the basic marginal independent-based idea alone may be insufficient to identify the causal feature. By d-separation, we observe that the causal feature can be further characterized by being independent of the domain conditioned on the object, and we propose the following two strategies as complements for the basic framework. First, the observation implicitly implies that for the same object, the causal feature should not be associated with the non-causal feature, revealing that the common practice of obtaining the two features with a shared base feature extractor and two lightweight prediction heads might be inappropriate. To meet the constraint, we propose a simple early-branching structure, where the causal and non-causal feature obtaining branches share the first few blocks while diverging thereafter, for better structure design; Second, the observation implies that the causal feature remains invariant across different domains for the same object. To this end, we suggest that augmentation should be incorporated into the framework to better characterize the causal feature, and we further suggest an effective random domain sampling scheme to fulfill the task. Theoretical and experimental results show that the two strategies are beneficial for the basic marginal independent-based framework. Code is available at \url{https://github.com/liangchen527/CausEB}.
Collaborate to Adapt: Source-Free Graph Domain Adaptation via Bi-directional Adaptation
Mar 03, 2024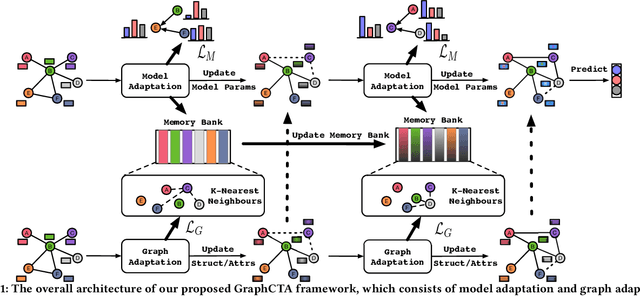
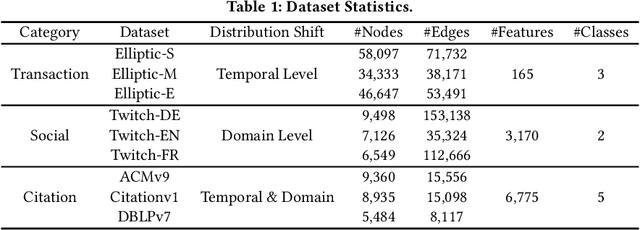
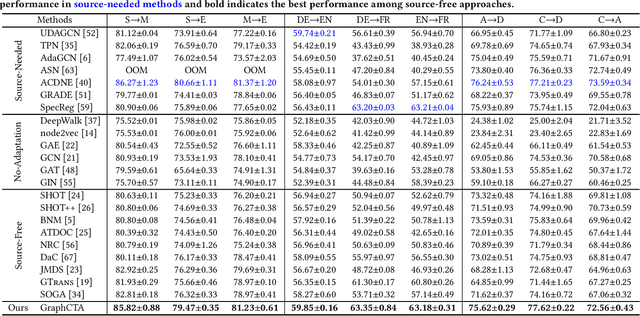
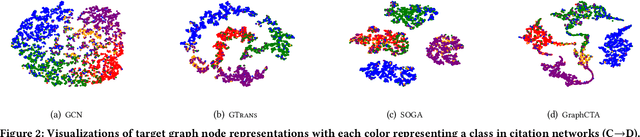
Unsupervised Graph Domain Adaptation (UGDA) has emerged as a practical solution to transfer knowledge from a label-rich source graph to a completely unlabelled target graph. However, most methods require a labelled source graph to provide supervision signals, which might not be accessible in the real-world settings due to regulations and privacy concerns. In this paper, we explore the scenario of source-free unsupervised graph domain adaptation, which tries to address the domain adaptation problem without accessing the labelled source graph. Specifically, we present a novel paradigm called GraphCTA, which performs model adaptation and graph adaptation collaboratively through a series of procedures: (1) conduct model adaptation based on node's neighborhood predictions in target graph considering both local and global information; (2) perform graph adaptation by updating graph structure and node attributes via neighborhood contrastive learning; and (3) the updated graph serves as an input to facilitate the subsequent iteration of model adaptation, thereby establishing a collaborative loop between model adaptation and graph adaptation. Comprehensive experiments are conducted on various public datasets. The experimental results demonstrate that our proposed model outperforms recent source-free baselines by large margins.
LinkNER: Linking Local Named Entity Recognition Models to Large Language Models using Uncertainty
Feb 27, 2024Named Entity Recognition (NER) serves as a fundamental task in natural language understanding, bearing direct implications for web content analysis, search engines, and information retrieval systems. Fine-tuned NER models exhibit satisfactory performance on standard NER benchmarks. However, due to limited fine-tuning data and lack of knowledge, it performs poorly on unseen entity recognition. As a result, the usability and reliability of NER models in web-related applications are compromised. Instead, Large Language Models (LLMs) like GPT-4 possess extensive external knowledge, but research indicates that they lack specialty for NER tasks. Furthermore, non-public and large-scale weights make tuning LLMs difficult. To address these challenges, we propose a framework that combines small fine-tuned models with LLMs (LinkNER) and an uncertainty-based linking strategy called RDC that enables fine-tuned models to complement black-box LLMs, achieving better performance. We experiment with both standard NER test sets and noisy social media datasets. LinkNER enhances NER task performance, notably surpassing SOTA models in robustness tests. We also quantitatively analyze the influence of key components like uncertainty estimation methods, LLMs, and in-context learning on diverse NER tasks, offering specific web-related recommendations.
BuffGraph: Enhancing Class-Imbalanced Node Classification via Buffer Nodes
Feb 20, 2024Class imbalance in graph-structured data, where minor classes are significantly underrepresented, poses a critical challenge for Graph Neural Networks (GNNs). To address this challenge, existing studies generally generate new minority nodes and edges connecting new nodes to the original graph to make classes balanced. However, they do not solve the problem that majority classes still propagate information to minority nodes by edges in the original graph which introduces bias towards majority classes. To address this, we introduce BuffGraph, which inserts buffer nodes into the graph, modulating the impact of majority classes to improve minor class representation. Our extensive experiments across diverse real-world datasets empirically demonstrate that BuffGraph outperforms existing baseline methods in class-imbalanced node classification in both natural settings and imbalanced settings. Code is available at https://anonymous.4open.science/r/BuffGraph-730A.
Distillation Enhanced Generative Retrieval
Feb 16, 2024Generative retrieval is a promising new paradigm in text retrieval that generates identifier strings of relevant passages as the retrieval target. This paradigm leverages powerful generative language models, distinct from traditional sparse or dense retrieval methods. In this work, we identify a viable direction to further enhance generative retrieval via distillation and propose a feasible framework, named DGR. DGR utilizes sophisticated ranking models, such as the cross-encoder, in a teacher role to supply a passage rank list, which captures the varying relevance degrees of passages instead of binary hard labels; subsequently, DGR employs a specially designed distilled RankNet loss to optimize the generative retrieval model, considering the passage rank order provided by the teacher model as labels. This framework only requires an additional distillation step to enhance current generative retrieval systems and does not add any burden to the inference stage. We conduct experiments on four public datasets, and the results indicate that DGR achieves state-of-the-art performance among the generative retrieval methods. Additionally, DGR demonstrates exceptional robustness and generalizability with various teacher models and distillation losses.