 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiwei Huang
Identifiable Latent Neural Causal Models
Mar 23, 2024
Causal representation learning seeks to uncover latent, high-level causal representations from low-level observed data. It is particularly good at predictions under unseen distribution shifts, because these shifts can generally be interpreted as consequences of interventions. Hence leveraging {seen} distribution shifts becomes a natural strategy to help identifying causal representations, which in turn benefits predictions where distributions are previously {unseen}. Determining the types (or conditions) of such distribution shifts that do contribute to the identifiability of causal representations is critical. This work establishes a {sufficient} and {necessary} condition characterizing the types of distribution shifts for identifiability in the context of latent additive noise models. Furthermore, we present partial identifiability results when only a portion of distribution shifts meets the condition. In addition, we extend our findings to latent post-nonlinear causal models. We translate our findings into a practical algorithm, allowing for the acquisition of reliable latent causal representations. Our algorithm, guided by our underlying theory, has demonstrated outstanding performance across a diverse range of synthetic and real-world datasets. The empirical observations align closely with the theoretical findings, affirming the robustness and effectiveness of our approach.
Federated Causal Discovery from Heterogeneous Data
Feb 27, 2024Conventional causal discovery methods rely on centralized data, which is inconsistent with the decentralized nature of data in many real-world situations. This discrepancy has motivated the development of federated causal discovery (FCD) approaches. However, existing FCD methods may be limited by their potentially restrictive assumptions of identifiable functional causal models or homogeneous data distributions, narrowing their applicability in diverse scenarios. In this paper, we propose a novel FCD method attempting to accommodate arbitrary causal models and heterogeneous data. We first utilize a surrogate variable corresponding to the client index to account for the data heterogeneity across different clients. We then develop a federated conditional independence test (FCIT) for causal skeleton discovery and establish a federated independent change principle (FICP) to determine causal directions. These approaches involve constructing summary statistics as a proxy of the raw data to protect data privacy. Owing to the nonparametric properties, FCIT and FICP make no assumption about particular functional forms, thereby facilitating the handling of arbitrary causal models. We conduct extensive experiments on synthetic and real datasets to show the efficacy of our method. The code is available at https://github.com/lokali/FedCDH.git.
Revealing Multimodal Contrastive Representation Learning through Latent Partial Causal Models
Feb 09, 2024Multimodal contrastive representation learning methods have proven successful across a range of domains, partly due to their ability to generate meaningful shared representations of complex phenomena. To enhance the depth of analysis and understanding of these acquired representations, we introduce a unified causal model specifically designed for multimodal data. By examining this model, we show that multimodal contrastive representation learning excels at identifying latent coupled variables within the proposed unified model, up to linear or permutation transformations resulting from different assumptions. Our findings illuminate the potential of pre-trained multimodal models, eg, CLIP, in learning disentangled representations through a surprisingly simple yet highly effective tool: linear independent component analysis. Experiments demonstrate the robustness of our findings, even when the assumptions are violated, and validate the effectiveness of the proposed method in learning disentangled representations.
Natural Counterfactuals With Necessary Backtracking
Feb 02, 2024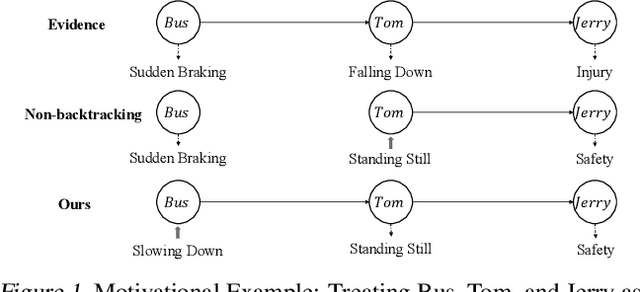
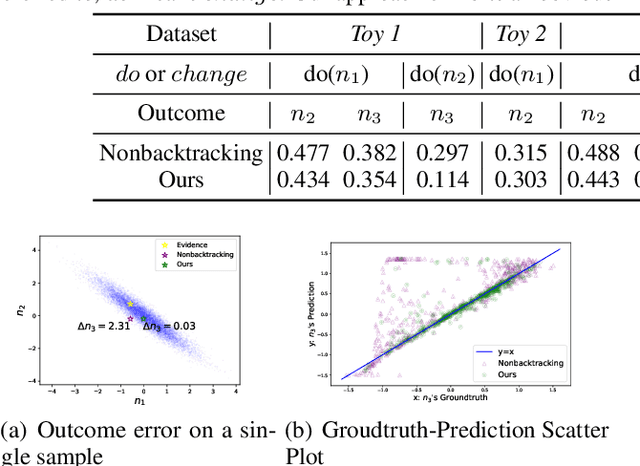
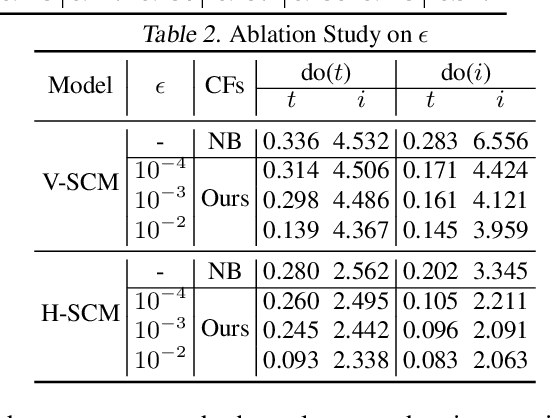
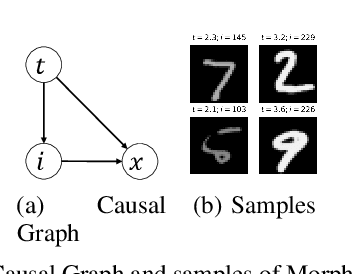
Counterfactual reasoning is pivotal in human cognition and especially important for providing explanations and making decisions. While Judea Pearl's influential approach is theoretically elegant, its generation of a counterfactual scenario often requires interventions that are too detached from the real scenarios to be feasible. In response, we propose a framework of natural counterfactuals and a method for generating counterfactuals that are natural with respect to the actual world's data distribution. Our methodology refines counterfactual reasoning, allowing changes in causally preceding variables to minimize deviations from realistic scenarios. To generate natural counterfactuals, we introduce an innovative optimization framework that permits but controls the extent of backtracking with a naturalness criterion. Empirical experiments indicate the effectiveness of our method.
HCVP: Leveraging Hierarchical Contrastive Visual Prompt for Domain Generalization
Jan 18, 2024Domain Generalization (DG) endeavors to create machine learning models that excel in unseen scenarios by learning invariant features. In DG, the prevalent practice of constraining models to a fixed structure or uniform parameterization to encapsulate invariant features can inadvertently blend specific aspects. Such an approach struggles with nuanced differentiation of inter-domain variations and may exhibit bias towards certain domains, hindering the precise learning of domain-invariant features. Recognizing this, we introduce a novel method designed to supplement the model with domain-level and task-specific characteristics. This approach aims to guide the model in more effectively separating invariant features from specific characteristics, thereby boosting the generalization. Building on the emerging trend of visual prompts in the DG paradigm, our work introduces the novel \textbf{H}ierarchical \textbf{C}ontrastive \textbf{V}isual \textbf{P}rompt (HCVP) methodology. This represents a significant advancement in the field, setting itself apart with a unique generative approach to prompts, alongside an explicit model structure and specialized loss functions. Differing from traditional visual prompts that are often shared across entire datasets, HCVP utilizes a hierarchical prompt generation network enhanced by prompt contrastive learning. These generative prompts are instance-dependent, catering to the unique characteristics inherent to different domains and tasks. Additionally, we devise a prompt modulation network that serves as a bridge, effectively incorporating the generated visual prompts into the vision transformer backbone. Experiments conducted on five DG datasets demonstrate the effectiveness of HCVP, outperforming both established DG algorithms and adaptation protocols.
A Versatile Causal Discovery Framework to Allow Causally-Related Hidden Variables
Dec 18, 2023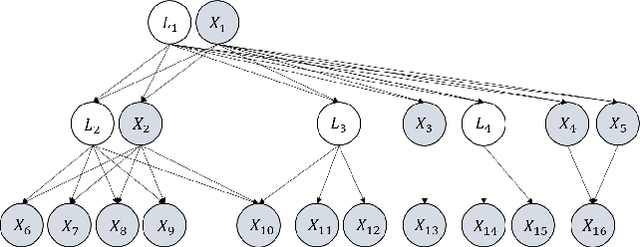

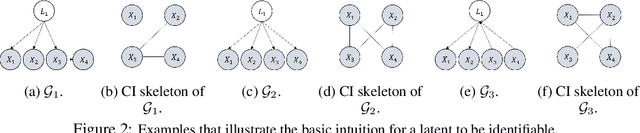
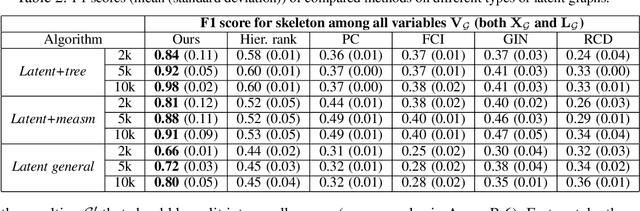
Most existing causal discovery methods rely on the assumption of no latent confounders, limiting their applicability in solving real-life problems. In this paper, we introduce a novel, versatile framework for causal discovery that accommodates the presence of causally-related hidden variables almost everywhere in the causal network (for instance, they can be effects of observed variables), based on rank information of covariance matrix over observed variables. We start by investigating the efficacy of rank in comparison to conditional independence and, theoretically, establish necessary and sufficient conditions for the identifiability of certain latent structural patterns. Furthermore, we develop a Rank-based Latent Causal Discovery algorithm, RLCD, that can efficiently locate hidden variables, determine their cardinalities, and discover the entire causal structure over both measured and hidden ones. We also show that, under certain graphical conditions, RLCD correctly identifies the Markov Equivalence Class of the whole latent causal graph asymptotically. Experimental results on both synthetic and real-world personality data sets demonstrate the efficacy of the proposed approach in finite-sample cases.
MACCA: Offline Multi-agent Reinforcement Learning with Causal Credit Assignment
Dec 06, 2023Offline Multi-agent Reinforcement Learning (MARL) is valuable in scenarios where online interaction is impractical or risky. While independent learning in MARL offers flexibility and scalability, accurately assigning credit to individual agents in offline settings poses challenges due to partial observability and emergent behavior. Directly transferring the online credit assignment method to offline settings results in suboptimal outcomes due to the absence of real-time feedback and intricate agent interactions. Our approach, MACCA, characterizing the generative process as a Dynamic Bayesian Network, captures relationships between environmental variables, states, actions, and rewards. Estimating this model on offline data, MACCA can learn each agent's contribution by analyzing the causal relationship of their individual rewards, ensuring accurate and interpretable credit assignment. Additionally, the modularity of our approach allows it to seamlessly integrate with various offline MARL methods. Theoretically, we proved that under the setting of the offline dataset, the underlying causal structure and the function for generating the individual rewards of agents are identifiable, which laid the foundation for the correctness of our modeling. Experimentally, we tested MACCA in two environments, including discrete and continuous action settings. The results show that MACCA outperforms SOTA methods and improves performance upon their backbones.
Generator Identification for Linear SDEs with Additive and Multiplicative Noise
Oct 30, 2023In this paper, we present conditions for identifying the generator of a linear stochastic differential equation (SDE) from the distribution of its solution process with a given fixed initial state. These identifiability conditions are crucial in causal inference using linear SDEs as they enable the identification of the post-intervention distributions from its observational distribution. Specifically, we derive a sufficient and necessary condition for identifying the generator of linear SDEs with additive noise, as well as a sufficient condition for identifying the generator of linear SDEs with multiplicative noise. We show that the conditions derived for both types of SDEs are generic. Moreover, we offer geometric interpretations of the derived identifiability conditions to enhance their understanding. To validate our theoretical results, we perform a series of simulations, which support and substantiate the established findings.
Identifiable Latent Polynomial Causal Models Through the Lens of Change
Oct 24, 2023
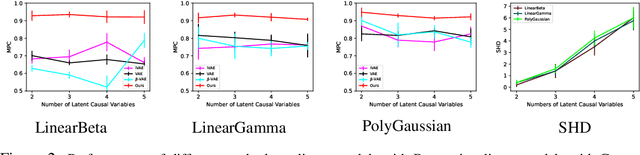
Causal representation learning aims to unveil latent high-level causal representations from observed low-level data. One of its primary tasks is to provide reliable assurance of identifying these latent causal models, known as identifiability. A recent breakthrough explores identifiability by leveraging the change of causal influences among latent causal variables across multiple environments \citep{liu2022identifying}. However, this progress rests on the assumption that the causal relationships among latent causal variables adhere strictly to linear Gaussian models. In this paper, we extend the scope of latent causal models to involve nonlinear causal relationships, represented by polynomial models, and general noise distributions conforming to the exponential family. Additionally, we investigate the necessity of imposing changes on all causal parameters and present partial identifiability results when part of them remains unchanged. Further, we propose a novel empirical estimation method, grounded in our theoretical finding, that enables learning consistent latent causal representations. Our experimental results, obtained from both synthetic and real-world data, validate our theoretical contributions concerning identifiability and consistency.
Generalized Independent Noise Condition for Estimating Causal Structure with Latent Variables
Aug 13, 2023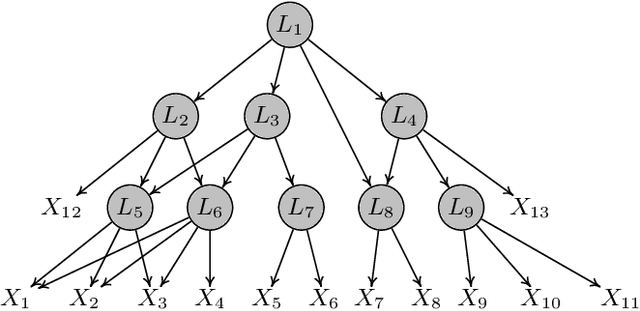

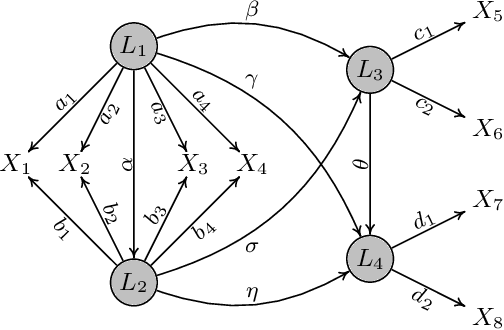
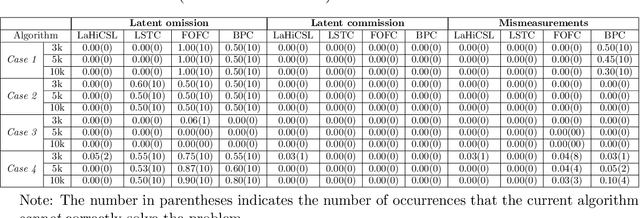
We investigate the challenging task of learning causal structure in the presence of latent variables, including locating latent variables and determining their quantity, and identifying causal relationships among both latent and observed variables. To address this, we propose a Generalized Independent Noise (GIN) condition for linear non-Gaussian acyclic causal models that incorporate latent variables, which establishes the independence between a linear combination of certain measured variables and some other measured variables. Specifically, for two observed random vectors $\bf{Y}$ and $\bf{Z}$, GIN holds if and only if $\omega^{\intercal}\mathbf{Y}$ and $\mathbf{Z}$ are independent, where $\omega$ is a non-zero parameter vector determined by the cross-covariance between $\mathbf{Y}$ and $\mathbf{Z}$. We then give necessary and sufficient graphical criteria of the GIN condition in linear non-Gaussian acyclic causal models. Roughly speaking, GIN implies the existence of an exogenous set $\mathcal{S}$ relative to the parent set of $\mathbf{Y}$ (w.r.t. the causal ordering), such that $\mathcal{S}$ d-separates $\mathbf{Y}$ from $\mathbf{Z}$. Interestingly, we find that the independent noise condition (i.e., if there is no confounder, causes are independent of the residual derived from regressing the effect on the causes) can be seen as a special case of GIN. With such a connection between GIN and latent causal structures, we further leverage the proposed GIN condition, together with a well-designed search procedure, to efficiently estimate Linear, Non-Gaussian Latent Hierarchical Models (LiNGLaHs), where latent confounders may also be causally related and may even follow a hierarchical structure. We show that the underlying causal structure of a LiNGLaH is identifiable in light of GIN conditions under mild assumptions. Experimental results show the effectiveness of the proposed approach.