 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiming Chen
Progressive Semantic-Guided Vision Transformer for Zero-Shot Learning
Apr 11, 2024
Zero-shot learning (ZSL) recognizes the unseen classes by conducting visual-semantic interactions to transfer semantic knowledge from seen classes to unseen ones, supported by semantic information (e.g., attributes). However, existing ZSL methods simply extract visual features using a pre-trained network backbone (i.e., CNN or ViT), which fail to learn matched visual-semantic correspondences for representing semantic-related visual features as lacking of the guidance of semantic information, resulting in undesirable visual-semantic interactions. To tackle this issue, we propose a progressive semantic-guided vision transformer for zero-shot learning (dubbed ZSLViT). ZSLViT mainly considers two properties in the whole network: i) discover the semantic-related visual representations explicitly, and ii) discard the semantic-unrelated visual information. Specifically, we first introduce semantic-embedded token learning to improve the visual-semantic correspondences via semantic enhancement and discover the semantic-related visual tokens explicitly with semantic-guided token attention. Then, we fuse low semantic-visual correspondence visual tokens to discard the semantic-unrelated visual information for visual enhancement. These two operations are integrated into various encoders to progressively learn semantic-related visual representations for accurate visual-semantic interactions in ZSL. The extensive experiments show that our ZSLViT achieves significant performance gains on three popular benchmark datasets, i.e., CUB, SUN, and AWA2.
Few-Shot Object Detection: Research Advances and Challenges
Apr 07, 2024Object detection as a subfield within computer vision has achieved remarkable progress, which aims to accurately identify and locate a specific object from images or videos. Such methods rely on large-scale labeled training samples for each object category to ensure accurate detection, but obtaining extensive annotated data is a labor-intensive and expensive process in many real-world scenarios. To tackle this challenge, researchers have explored few-shot object detection (FSOD) that combines few-shot learning and object detection techniques to rapidly adapt to novel objects with limited annotated samples. This paper presents a comprehensive survey to review the significant advancements in the field of FSOD in recent years and summarize the existing challenges and solutions. Specifically, we first introduce the background and definition of FSOD to emphasize potential value in advancing the field of computer vision. We then propose a novel FSOD taxonomy method and survey the plentifully remarkable FSOD algorithms based on this fact to report a comprehensive overview that facilitates a deeper understanding of the FSOD problem and the development of innovative solutions. Finally, we discuss the advantages and limitations of these algorithms to summarize the challenges, potential research direction, and development trend of object detection in the data scarcity scenario.
HCVP: Leveraging Hierarchical Contrastive Visual Prompt for Domain Generalization
Jan 18, 2024Domain Generalization (DG) endeavors to create machine learning models that excel in unseen scenarios by learning invariant features. In DG, the prevalent practice of constraining models to a fixed structure or uniform parameterization to encapsulate invariant features can inadvertently blend specific aspects. Such an approach struggles with nuanced differentiation of inter-domain variations and may exhibit bias towards certain domains, hindering the precise learning of domain-invariant features. Recognizing this, we introduce a novel method designed to supplement the model with domain-level and task-specific characteristics. This approach aims to guide the model in more effectively separating invariant features from specific characteristics, thereby boosting the generalization. Building on the emerging trend of visual prompts in the DG paradigm, our work introduces the novel \textbf{H}ierarchical \textbf{C}ontrastive \textbf{V}isual \textbf{P}rompt (HCVP) methodology. This represents a significant advancement in the field, setting itself apart with a unique generative approach to prompts, alongside an explicit model structure and specialized loss functions. Differing from traditional visual prompts that are often shared across entire datasets, HCVP utilizes a hierarchical prompt generation network enhanced by prompt contrastive learning. These generative prompts are instance-dependent, catering to the unique characteristics inherent to different domains and tasks. Additionally, we devise a prompt modulation network that serves as a bridge, effectively incorporating the generated visual prompts into the vision transformer backbone. Experiments conducted on five DG datasets demonstrate the effectiveness of HCVP, outperforming both established DG algorithms and adaptation protocols.
ECEA: Extensible Co-Existing Attention for Few-Shot Object Detection
Sep 15, 2023
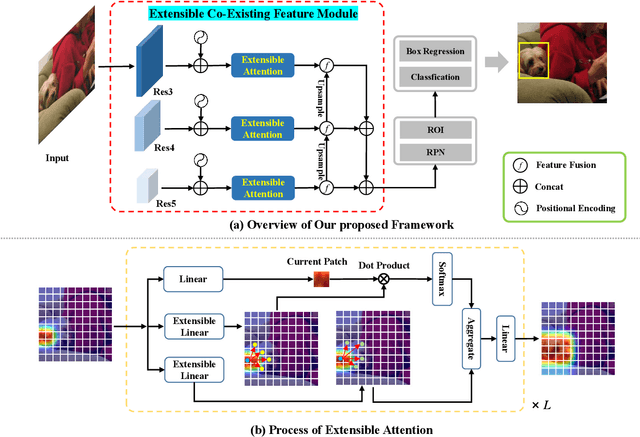
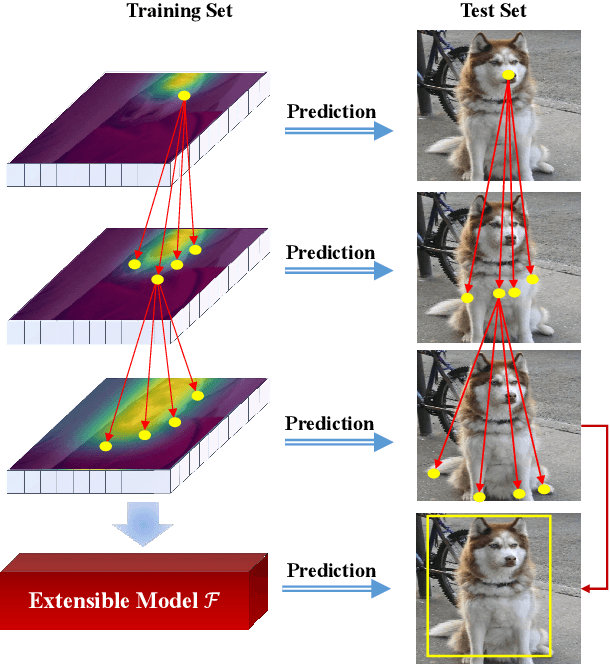
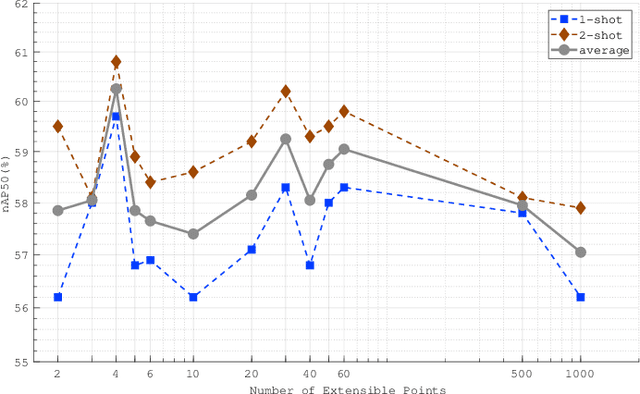
Few-shot object detection (FSOD) identifies objects from extremely few annotated samples. Most existing FSOD methods, recently, apply the two-stage learning paradigm, which transfers the knowledge learned from abundant base classes to assist the few-shot detectors by learning the global features. However, such existing FSOD approaches seldom consider the localization of objects from local to global. Limited by the scarce training data in FSOD, the training samples of novel classes typically capture part of objects, resulting in such FSOD methods cannot detect the completely unseen object during testing. To tackle this problem, we propose an Extensible Co-Existing Attention (ECEA) module to enable the model to infer the global object according to the local parts. Essentially, the proposed module continuously learns the extensible ability on the base stage with abundant samples and transfers it to the novel stage, which can assist the few-shot model to quickly adapt in extending local regions to co-existing regions. Specifically, we first devise an extensible attention mechanism that starts with a local region and extends attention to co-existing regions that are similar and adjacent to the given local region. We then implement the extensible attention mechanism in different feature scales to progressively discover the full object in various receptive fields. Extensive experiments on the PASCAL VOC and COCO datasets show that our ECEA module can assist the few-shot detector to completely predict the object despite some regions failing to appear in the training samples and achieve the new state of the art compared with existing FSOD methods.
EGANS: Evolutionary Generative Adversarial Network Search for Zero-Shot Learning
Aug 19, 2023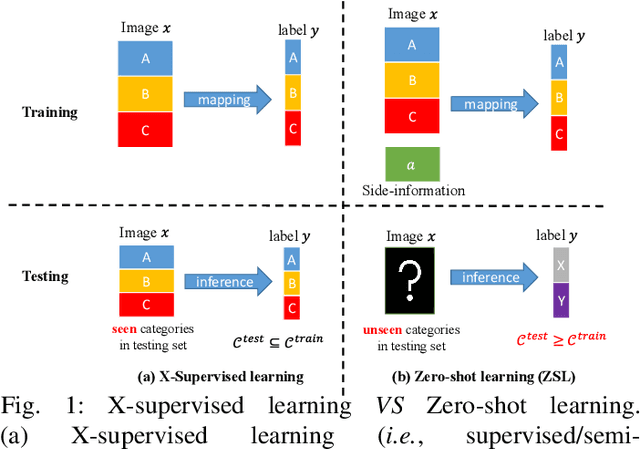
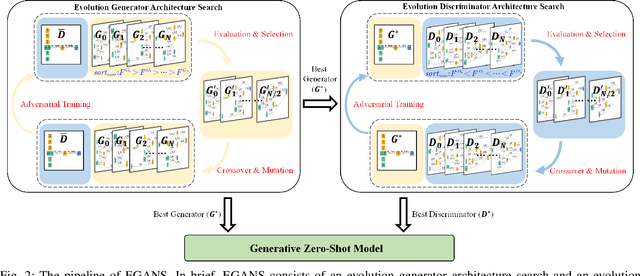
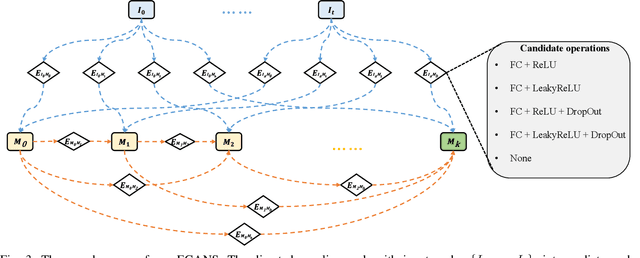
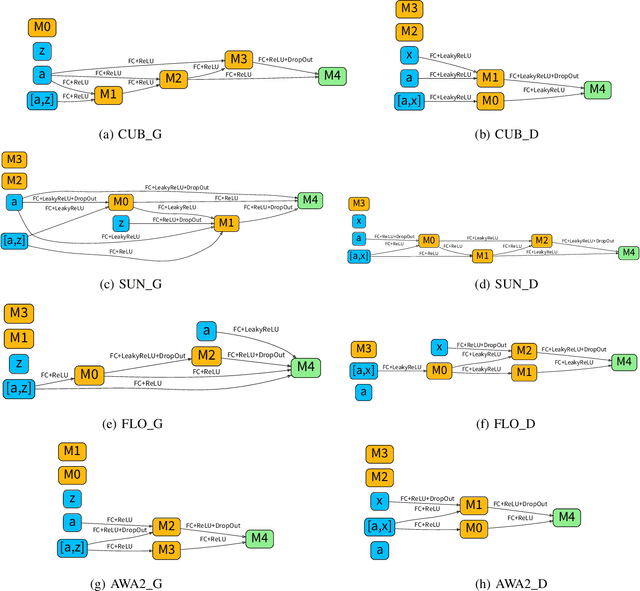
Zero-shot learning (ZSL) aims to recognize the novel classes which cannot be collected for training a prediction model. Accordingly, generative models (e.g., generative adversarial network (GAN)) are typically used to synthesize the visual samples conditioned by the class semantic vectors and achieve remarkable progress for ZSL. However, existing GAN-based generative ZSL methods are based on hand-crafted models, which cannot adapt to various datasets/scenarios and fails to model instability. To alleviate these challenges, we propose evolutionary generative adversarial network search (termed EGANS) to automatically design the generative network with good adaptation and stability, enabling reliable visual feature sample synthesis for advancing ZSL. Specifically, we adopt cooperative dual evolution to conduct a neural architecture search for both generator and discriminator under a unified evolutionary adversarial framework. EGANS is learned by two stages: evolution generator architecture search and evolution discriminator architecture search. During the evolution generator architecture search, we adopt a many-to-one adversarial training strategy to evolutionarily search for the optimal generator. Then the optimal generator is further applied to search for the optimal discriminator in the evolution discriminator architecture search with a similar evolution search algorithm. Once the optimal generator and discriminator are searched, we entail them into various generative ZSL baselines for ZSL classification. Extensive experiments show that EGANS consistently improve existing generative ZSL methods on the standard CUB, SUN, AWA2 and FLO datasets. The significant performance gains indicate that the evolutionary neural architecture search explores a virgin field in ZSL.
Evolving Semantic Prototype Improves Generative Zero-Shot Learning
Jun 12, 2023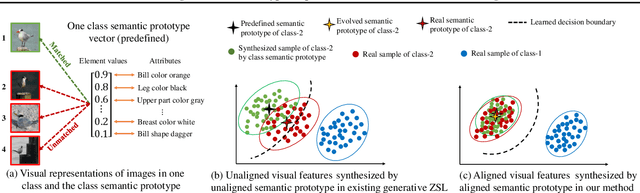
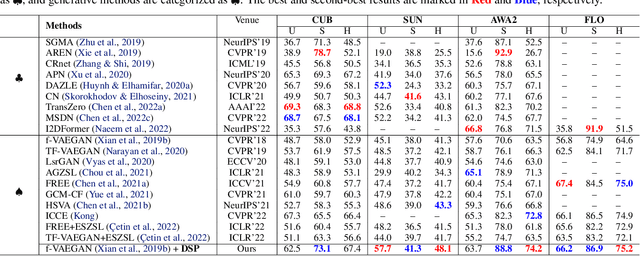
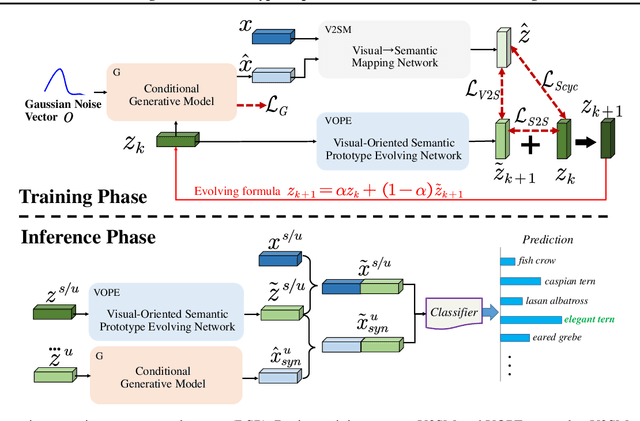
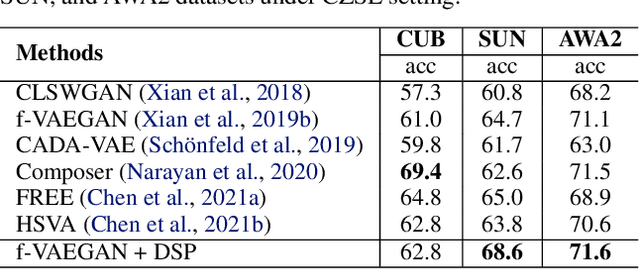
In zero-shot learning (ZSL), generative methods synthesize class-related sample features based on predefined semantic prototypes. They advance the ZSL performance by synthesizing unseen class sample features for better training the classifier. We observe that each class's predefined semantic prototype (also referred to as semantic embedding or condition) does not accurately match its real semantic prototype. So the synthesized visual sample features do not faithfully represent the real sample features, limiting the classifier training and existing ZSL performance. In this paper, we formulate this mismatch phenomenon as the visual-semantic domain shift problem. We propose a dynamic semantic prototype evolving (DSP) method to align the empirically predefined semantic prototypes and the real prototypes for class-related feature synthesis. The alignment is learned by refining sample features and semantic prototypes in a unified framework and making the synthesized visual sample features approach real sample features. After alignment, synthesized sample features from unseen classes are closer to the real sample features and benefit DSP to improve existing generative ZSL methods by 8.5\%, 8.0\%, and 9.7\% on the standard CUB, SUN AWA2 datasets, the significant performance improvement indicates that evolving semantic prototype explores a virgin field in ZSL.
MSDN: Mutually Semantic Distillation Network for Zero-Shot Learning
Mar 07, 2022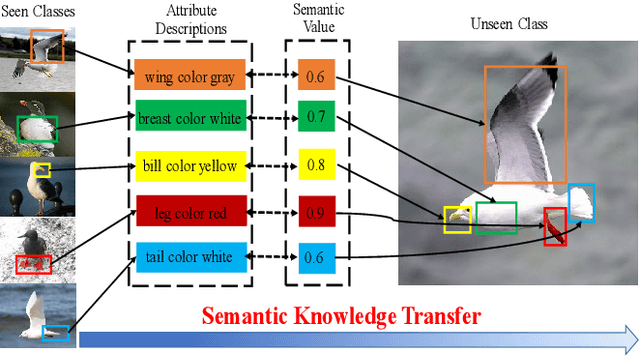
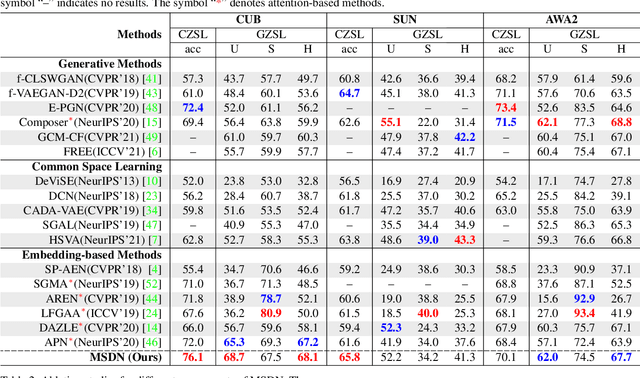

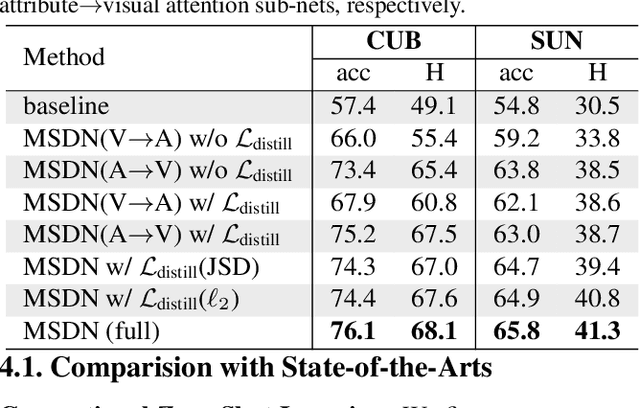
The key challenge of zero-shot learning (ZSL) is how to infer the latent semantic knowledge between visual and attribute features on seen classes, and thus achieving a desirable knowledge transfer to unseen classes. Prior works either simply align the global features of an image with its associated class semantic vector or utilize unidirectional attention to learn the limited latent semantic representations, which could not effectively discover the intrinsic semantic knowledge e.g., attribute semantics) between visual and attribute features. To solve the above dilemma, we propose a Mutually Semantic Distillation Network (MSDN), which progressively distills the intrinsic semantic representations between visual and attribute features for ZSL. MSDN incorporates an attribute$\rightarrow$visual attention sub-net that learns attribute-based visual features, and a visual$\rightarrow$attribute attention sub-net that learns visual-based attribute features. By further introducing a semantic distillation loss, the two mutual attention sub-nets are capable of learning collaboratively and teaching each other throughout the training process. The proposed MSDN yields significant improvements over the strong baselines, leading to new state-of-the-art performances on three popular challenging benchmarks, i.e., CUB, SUN, and AWA2. Our codes have been available at: \url{https://github.com/shiming-chen/MSDN}.
TransZero++: Cross Attribute-Guided Transformer for Zero-Shot Learning
Dec 21, 2021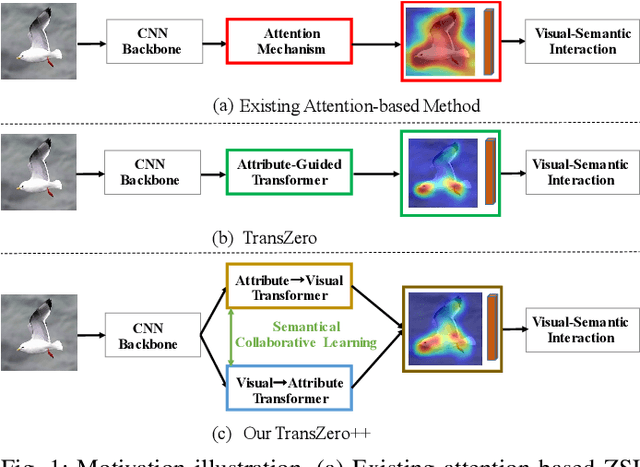
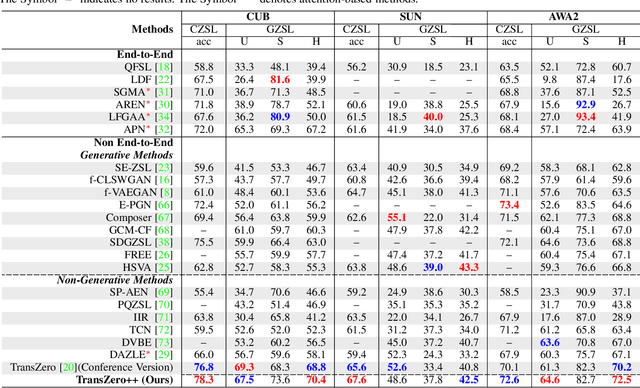
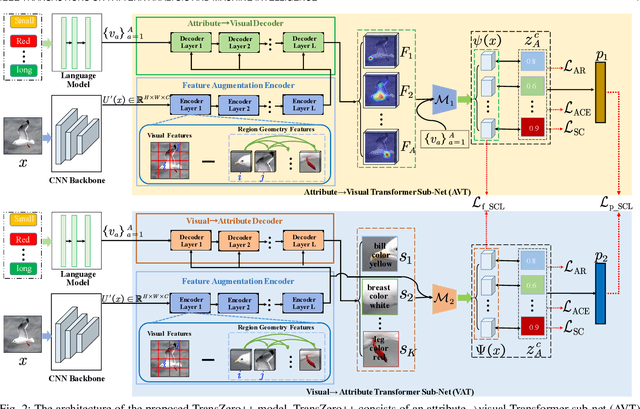
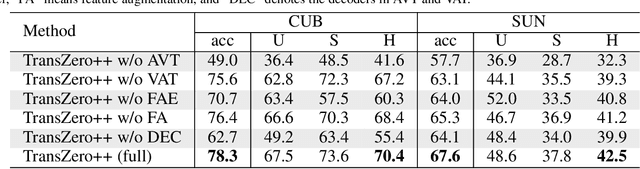
Zero-shot learning (ZSL) tackles the novel class recognition problem by transferring semantic knowledge from seen classes to unseen ones. Existing attention-based models have struggled to learn inferior region features in a single image by solely using unidirectional attention, which ignore the transferability and discriminative attribute localization of visual features. In this paper, we propose a cross attribute-guided Transformer network, termed TransZero++, to refine visual features and learn accurate attribute localization for semantic-augmented visual embedding representations in ZSL. TransZero++ consists of an attribute$\rightarrow$visual Transformer sub-net (AVT) and a visual$\rightarrow$attribute Transformer sub-net (VAT). Specifically, AVT first takes a feature augmentation encoder to alleviate the cross-dataset problem, and improves the transferability of visual features by reducing the entangled relative geometry relationships among region features. Then, an attribute$\rightarrow$visual decoder is employed to localize the image regions most relevant to each attribute in a given image for attribute-based visual feature representations. Analogously, VAT uses the similar feature augmentation encoder to refine the visual features, which are further applied in visual$\rightarrow$attribute decoder to learn visual-based attribute features. By further introducing semantical collaborative losses, the two attribute-guided transformers teach each other to learn semantic-augmented visual embeddings via semantical collaborative learning. Extensive experiments show that TransZero++ achieves the new state-of-the-art results on three challenging ZSL benchmarks. The codes are available at: \url{https://github.com/shiming-chen/TransZero_pp}.
TransZero: Attribute-guided Transformer for Zero-Shot Learning
Dec 03, 2021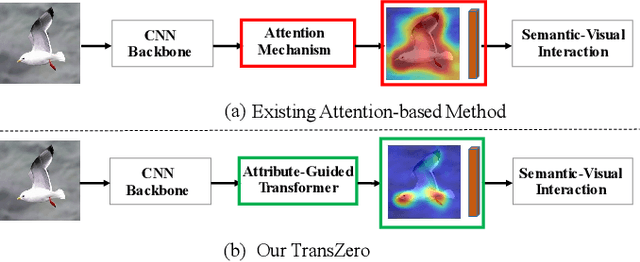
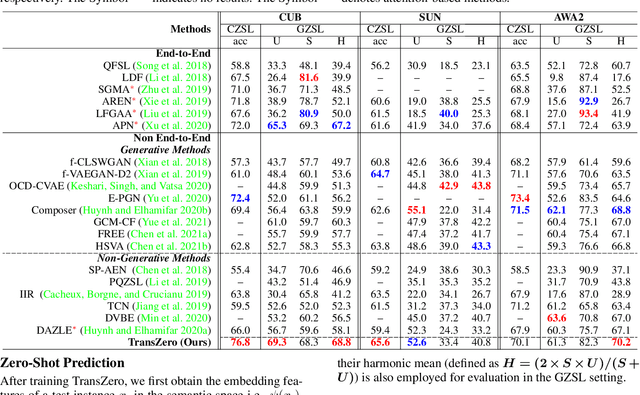
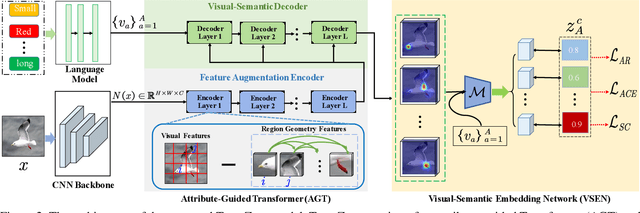
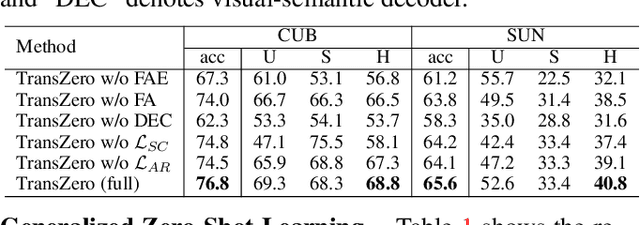
Zero-shot learning (ZSL) aims to recognize novel classes by transferring semantic knowledge from seen classes to unseen ones. Semantic knowledge is learned from attribute descriptions shared between different classes, which act as strong priors for localizing object attributes that represent discriminative region features, enabling significant visual-semantic interaction. Although some attention-based models have attempted to learn such region features in a single image, the transferability and discriminative attribute localization of visual features are typically neglected. In this paper, we propose an attribute-guided Transformer network, termed TransZero, to refine visual features and learn attribute localization for discriminative visual embedding representations in ZSL. Specifically, TransZero takes a feature augmentation encoder to alleviate the cross-dataset bias between ImageNet and ZSL benchmarks, and improves the transferability of visual features by reducing the entangled relative geometry relationships among region features. To learn locality-augmented visual features, TransZero employs a visual-semantic decoder to localize the image regions most relevant to each attribute in a given image, under the guidance of semantic attribute information. Then, the locality-augmented visual features and semantic vectors are used to conduct effective visual-semantic interaction in a visual-semantic embedding network. Extensive experiments show that TransZero achieves the new state of the art on three ZSL benchmarks. The codes are available at: \url{https://github.com/shiming-chen/TransZero}.
HSVA: Hierarchical Semantic-Visual Adaptation for Zero-Shot Learning
Oct 08, 2021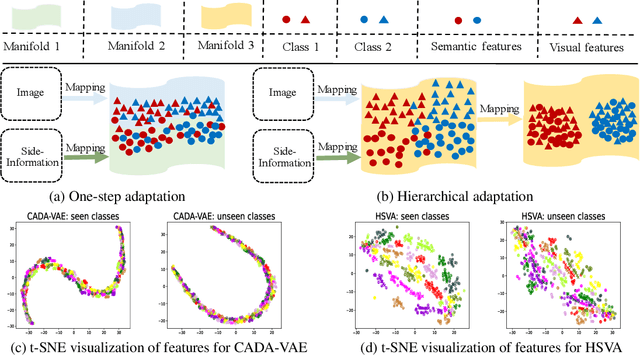

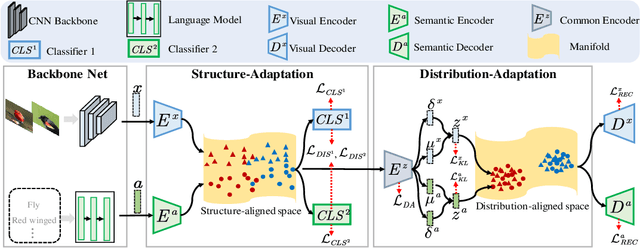
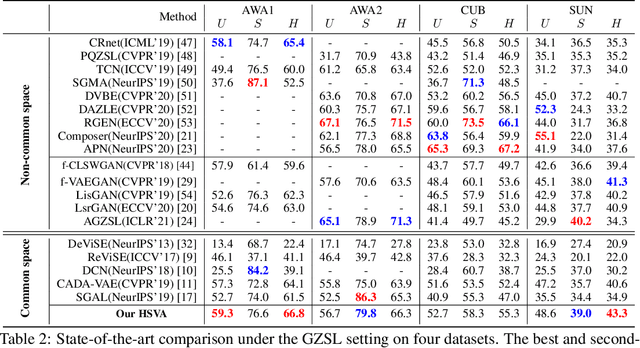
Zero-shot learning (ZSL) tackles the unseen class recognition problem, transferring semantic knowledge from seen classes to unseen ones. Typically, to guarantee desirable knowledge transfer, a common (latent) space is adopted for associating the visual and semantic domains in ZSL. However, existing common space learning methods align the semantic and visual domains by merely mitigating distribution disagreement through one-step adaptation. This strategy is usually ineffective due to the heterogeneous nature of the feature representations in the two domains, which intrinsically contain both distribution and structure variations. To address this and advance ZSL, we propose a novel hierarchical semantic-visual adaptation (HSVA) framework. Specifically, HSVA aligns the semantic and visual domains by adopting a hierarchical two-step adaptation, i.e., structure adaptation and distribution adaptation. In the structure adaptation step, we take two task-specific encoders to encode the source data (visual domain) and the target data (semantic domain) into a structure-aligned common space. To this end, a supervised adversarial discrepancy (SAD) module is proposed to adversarially minimize the discrepancy between the predictions of two task-specific classifiers, thus making the visual and semantic feature manifolds more closely aligned. In the distribution adaptation step, we directly minimize the Wasserstein distance between the latent multivariate Gaussian distributions to align the visual and semantic distributions using a common encoder. Finally, the structure and distribution adaptation are derived in a unified framework under two partially-aligned variational autoencoders. Extensive experiments on four benchmark datasets demonstrate that HSVA achieves superior performance on both conventional and generalized ZSL. The code is available at \url{https://github.com/shiming-chen/HSVA} .