 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJian Zhao
Confidence-Aware RGB-D Face Recognition via Virtual Depth Synthesis
Mar 16, 2024
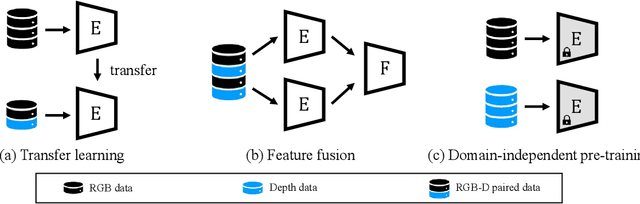


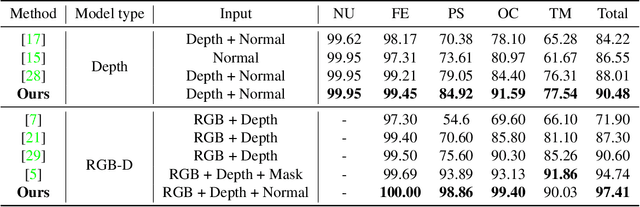
2D face recognition encounters challenges in unconstrained environments due to varying illumination, occlusion, and pose. Recent studies focus on RGB-D face recognition to improve robustness by incorporating depth information. However, collecting sufficient paired RGB-D training data is expensive and time-consuming, hindering wide deployment. In this work, we first construct a diverse depth dataset generated by 3D Morphable Models for depth model pre-training. Then, we propose a domain-independent pre-training framework that utilizes readily available pre-trained RGB and depth models to separately perform face recognition without needing additional paired data for retraining. To seamlessly integrate the two distinct networks and harness the complementary benefits of RGB and depth information for improved accuracy, we propose an innovative Adaptive Confidence Weighting (ACW). This mechanism is designed to learn confidence estimates for each modality to achieve modality fusion at the score level. Our method is simple and lightweight, only requiring ACW training beyond the backbone models. Experiments on multiple public RGB-D face recognition benchmarks demonstrate state-of-the-art performance surpassing previous methods based on depth estimation and feature fusion, validating the efficacy of our approach.
HAM-TTS: Hierarchical Acoustic Modeling for Token-Based Zero-Shot Text-to-Speech with Model and Data Scaling
Mar 09, 2024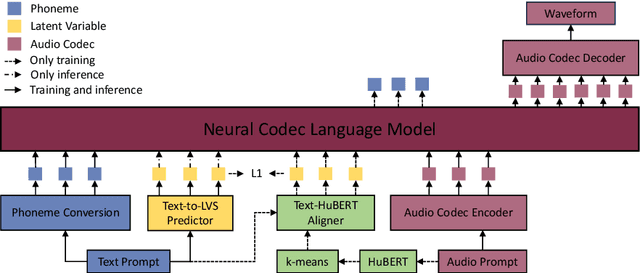

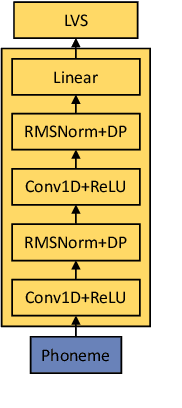
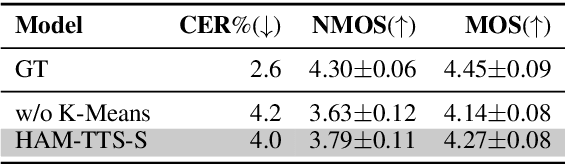
Token-based text-to-speech (TTS) models have emerged as a promising avenue for generating natural and realistic speech, yet they grapple with low pronunciation accuracy, speaking style and timbre inconsistency, and a substantial need for diverse training data. In response, we introduce a novel hierarchical acoustic modeling approach complemented by a tailored data augmentation strategy and train it on the combination of real and synthetic data, scaling the data size up to 650k hours, leading to the zero-shot TTS model with 0.8B parameters. Specifically, our method incorporates a latent variable sequence containing supplementary acoustic information based on refined self-supervised learning (SSL) discrete units into the TTS model by a predictor. This significantly mitigates pronunciation errors and style mutations in synthesized speech. During training, we strategically replace and duplicate segments of the data to enhance timbre uniformity. Moreover, a pretrained few-shot voice conversion model is utilized to generate a plethora of voices with identical content yet varied timbres. This facilitates the explicit learning of utterance-level one-to-many mappings, enriching speech diversity and also ensuring consistency in timbre. Comparative experiments (Demo page: https://anonymous.4open.science/w/ham-tts/)demonstrate our model's superiority over VALL-E in pronunciation precision and maintaining speaking style, as well as timbre continuity.
PRCL: Probabilistic Representation Contrastive Learning for Semi-Supervised Semantic Segmentation
Feb 28, 2024Tremendous breakthroughs have been developed in Semi-Supervised Semantic Segmentation (S4) through contrastive learning. However, due to limited annotations, the guidance on unlabeled images is generated by the model itself, which inevitably exists noise and disturbs the unsupervised training process. To address this issue, we propose a robust contrastive-based S4 framework, termed the Probabilistic Representation Contrastive Learning (PRCL) framework to enhance the robustness of the unsupervised training process. We model the pixel-wise representation as Probabilistic Representations (PR) via multivariate Gaussian distribution and tune the contribution of the ambiguous representations to tolerate the risk of inaccurate guidance in contrastive learning. Furthermore, we introduce Global Distribution Prototypes (GDP) by gathering all PRs throughout the whole training process. Since the GDP contains the information of all representations with the same class, it is robust from the instant noise in representations and bears the intra-class variance of representations. In addition, we generate Virtual Negatives (VNs) based on GDP to involve the contrastive learning process. Extensive experiments on two public benchmarks demonstrate the superiority of our PRCL framework.
EmoWear: Exploring Emotional Teasers for Voice Message Interaction on Smartwatches
Feb 11, 2024Voice messages, by nature, prevent users from gauging the emotional tone without fully diving into the audio content. This hinders the shared emotional experience at the pre-retrieval stage. Research scarcely explored "Emotional Teasers"-pre-retrieval cues offering a glimpse into an awaiting message's emotional tone without disclosing its content. We introduce EmoWear, a smartwatch voice messaging system enabling users to apply 30 animation teasers on message bubbles to reflect emotions. EmoWear eases senders' choice by prioritizing emotions based on semantic and acoustic processing. EmoWear was evaluated in comparison with a mirroring system using color-coded message bubbles as emotional cues (N=24). Results showed EmoWear significantly enhanced emotional communication experience in both receiving and sending messages. The animated teasers were considered intuitive and valued for diverse expressions. Desirable interaction qualities and practical implications are distilled for future design. We thereby contribute both a novel system and empirical knowledge concerning emotional teasers for voice messaging.
Not All Data Matters: An End-to-End Adaptive Dataset Pruning Framework for Enhancing Model Performance and Efficiency
Dec 09, 2023While deep neural networks have demonstrated remarkable performance across various tasks, they typically require massive training data. Due to the presence of redundancies and biases in real-world datasets, not all data in the training dataset contributes to the model performance. To address this issue, dataset pruning techniques have been introduced to enhance model performance and efficiency by eliminating redundant training samples and reducing computational and memory overhead. However, previous works most rely on manually crafted scalar scores, limiting their practical performance and scalability across diverse deep networks and datasets. In this paper, we propose AdaPruner, an end-to-end Adaptive DAtaset PRUNing framEwoRk. AdaPruner can perform effective dataset pruning without the need for explicitly defined metrics. Our framework jointly prunes training data and fine-tunes models with task-specific optimization objectives. AdaPruner leverages (1) An adaptive dataset pruning (ADP) module, which iteratively prunes redundant samples to an expected pruning ratio; and (2) A pruning performance controller (PPC) module, which optimizes the model performance for accurate pruning. Therefore, AdaPruner exhibits high scalability and compatibility across various datasets and deep networks, yielding improved dataset distribution and enhanced model performance. AdaPruner can still significantly enhance model performance even after pruning up to 10-30\% of the training data. Notably, these improvements are accompanied by substantial savings in memory and computation costs. Qualitative and quantitative experiments suggest that AdaPruner outperforms other state-of-the-art dataset pruning methods by a large margin.
DanZero+: Dominating the GuanDan Game through Reinforcement Learning
Dec 05, 2023The utilization of artificial intelligence (AI) in card games has been a well-explored subject within AI research for an extensive period. Recent advancements have propelled AI programs to showcase expertise in intricate card games such as Mahjong, DouDizhu, and Texas Hold'em. In this work, we aim to develop an AI program for an exceptionally complex and popular card game called GuanDan. This game involves four players engaging in both competitive and cooperative play throughout a long process to upgrade their level, posing great challenges for AI due to its expansive state and action space, long episode length, and complex rules. Employing reinforcement learning techniques, specifically Deep Monte Carlo (DMC), and a distributed training framework, we first put forward an AI program named DanZero for this game. Evaluation against baseline AI programs based on heuristic rules highlights the outstanding performance of our bot. Besides, in order to further enhance the AI's capabilities, we apply policy-based reinforcement learning algorithm to GuanDan. To address the challenges arising from the huge action space, which will significantly impact the performance of policy-based algorithms, we adopt the pre-trained model to facilitate the training process and the achieved AI program manages to achieve a superior performance.
RADAP: A Robust and Adaptive Defense Against Diverse Adversarial Patches on Face Recognition
Nov 29, 2023Face recognition (FR) systems powered by deep learning have become widely used in various applications. However, they are vulnerable to adversarial attacks, especially those based on local adversarial patches that can be physically applied to real-world objects. In this paper, we propose RADAP, a robust and adaptive defense mechanism against diverse adversarial patches in both closed-set and open-set FR systems. RADAP employs innovative techniques, such as FCutout and F-patch, which use Fourier space sampling masks to improve the occlusion robustness of the FR model and the performance of the patch segmenter. Moreover, we introduce an edge-aware binary cross-entropy (EBCE) loss function to enhance the accuracy of patch detection. We also present the split and fill (SAF) strategy, which is designed to counter the vulnerability of the patch segmenter to complete white-box adaptive attacks. We conduct comprehensive experiments to validate the effectiveness of RADAP, which shows significant improvements in defense performance against various adversarial patches, while maintaining clean accuracy higher than that of the undefended Vanilla model.
NeRFTAP: Enhancing Transferability of Adversarial Patches on Face Recognition using Neural Radiance Fields
Nov 29, 2023Face recognition (FR) technology plays a crucial role in various applications, but its vulnerability to adversarial attacks poses significant security concerns. Existing research primarily focuses on transferability to different FR models, overlooking the direct transferability to victim's face images, which is a practical threat in real-world scenarios. In this study, we propose a novel adversarial attack method that considers both the transferability to the FR model and the victim's face image, called NeRFTAP. Leveraging NeRF-based 3D-GAN, we generate new view face images for the source and target subjects to enhance transferability of adversarial patches. We introduce a style consistency loss to ensure the visual similarity between the adversarial UV map and the target UV map under a 0-1 mask, enhancing the effectiveness and naturalness of the generated adversarial face images. Extensive experiments and evaluations on various FR models demonstrate the superiority of our approach over existing attack techniques. Our work provides valuable insights for enhancing the robustness of FR systems in practical adversarial settings.
A Simple Geometric-Aware Indoor Positioning Interpolation Algorithm Based on Manifold Learning
Nov 27, 2023Interpolation methodologies have been widely used within the domain of indoor positioning systems. However, existing indoor positioning interpolation algorithms exhibit several inherent limitations, including reliance on complex mathematical models, limited flexibility, and relatively low precision. To enhance the accuracy and efficiency of indoor positioning interpolation techniques, this paper proposes a simple yet powerful geometric-aware interpolation algorithm for indoor positioning tasks. The key to our algorithm is to exploit the geometric attributes of the local topological manifold using manifold learning principles. Therefore, instead of constructing complicated mathematical models, the proposed algorithm facilitates the more precise and efficient estimation of points grounded in the local topological manifold. Moreover, our proposed method can be effortlessly integrated into any indoor positioning system, thereby bolstering its adaptability. Through a systematic array of experiments and comprehensive performance analyses conducted on both simulated and real-world datasets, we demonstrate that the proposed algorithm consistently outperforms the most commonly used and representative interpolation approaches regarding interpolation accuracy and efficiency. Furthermore, the experimental results also underscore the substantial practical utility of our method and its potential applicability in real-time indoor positioning scenarios.
Panda or not Panda? Understanding Adversarial Attacks with Interactive Visualization
Nov 22, 2023Adversarial machine learning (AML) studies attacks that can fool machine learning algorithms into generating incorrect outcomes as well as the defenses against worst-case attacks to strengthen model robustness. Specifically for image classification, it is challenging to understand adversarial attacks due to their use of subtle perturbations that are not human-interpretable, as well as the variability of attack impacts influenced by diverse methodologies, instance differences, and model architectures. Through a design study with AML learners and teachers, we introduce AdvEx, a multi-level interactive visualization system that comprehensively presents the properties and impacts of evasion attacks on different image classifiers for novice AML learners. We quantitatively and qualitatively assessed AdvEx in a two-part evaluation including user studies and expert interviews. Our results show that AdvEx is not only highly effective as a visualization tool for understanding AML mechanisms, but also provides an engaging and enjoyable learning experience, thus demonstrating its overall benefits for AML learners.