 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeihong Deng
Confidence-Aware RGB-D Face Recognition via Virtual Depth Synthesis
Mar 16, 2024
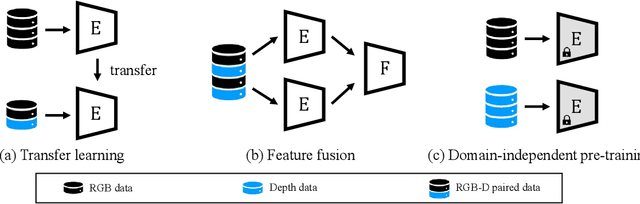


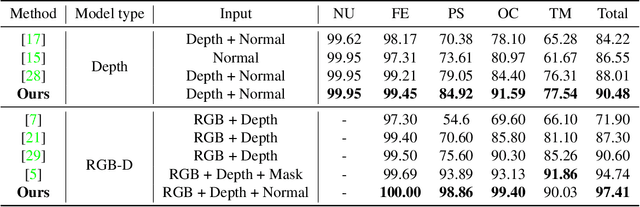
2D face recognition encounters challenges in unconstrained environments due to varying illumination, occlusion, and pose. Recent studies focus on RGB-D face recognition to improve robustness by incorporating depth information. However, collecting sufficient paired RGB-D training data is expensive and time-consuming, hindering wide deployment. In this work, we first construct a diverse depth dataset generated by 3D Morphable Models for depth model pre-training. Then, we propose a domain-independent pre-training framework that utilizes readily available pre-trained RGB and depth models to separately perform face recognition without needing additional paired data for retraining. To seamlessly integrate the two distinct networks and harness the complementary benefits of RGB and depth information for improved accuracy, we propose an innovative Adaptive Confidence Weighting (ACW). This mechanism is designed to learn confidence estimates for each modality to achieve modality fusion at the score level. Our method is simple and lightweight, only requiring ACW training beyond the backbone models. Experiments on multiple public RGB-D face recognition benchmarks demonstrate state-of-the-art performance surpassing previous methods based on depth estimation and feature fusion, validating the efficacy of our approach.
Faceptor: A Generalist Model for Face Perception
Mar 14, 2024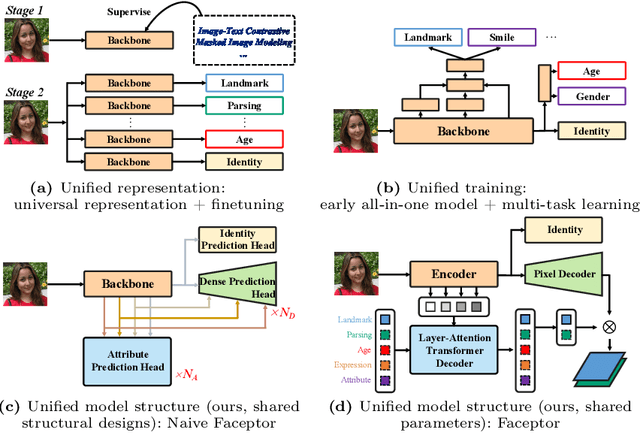
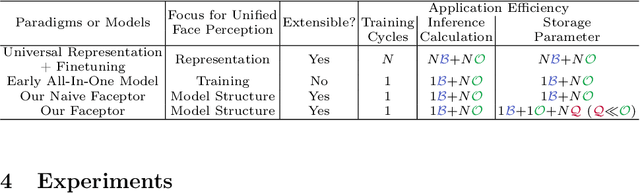
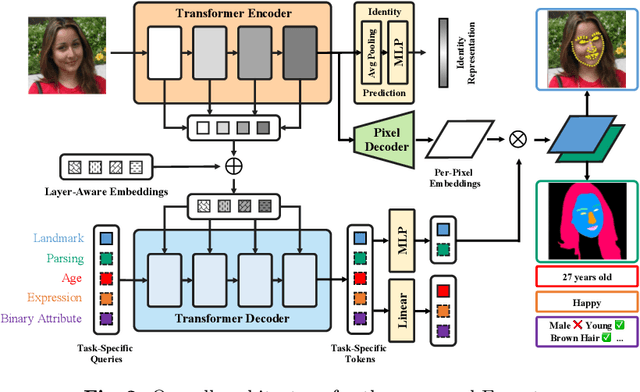
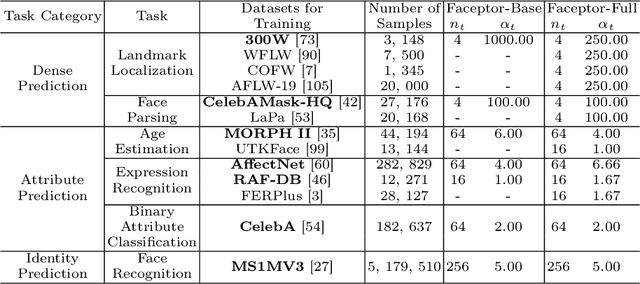
With the comprehensive research conducted on various face analysis tasks, there is a growing interest among researchers to develop a unified approach to face perception. Existing methods mainly discuss unified representation and training, which lack task extensibility and application efficiency. To tackle this issue, we focus on the unified model structure, exploring a face generalist model. As an intuitive design, Naive Faceptor enables tasks with the same output shape and granularity to share the structural design of the standardized output head, achieving improved task extensibility. Furthermore, Faceptor is proposed to adopt a well-designed single-encoder dual-decoder architecture, allowing task-specific queries to represent new-coming semantics. This design enhances the unification of model structure while improving application efficiency in terms of storage overhead. Additionally, we introduce Layer-Attention into Faceptor, enabling the model to adaptively select features from optimal layers to perform the desired tasks. Through joint training on 13 face perception datasets, Faceptor achieves exceptional performance in facial landmark localization, face parsing, age estimation, expression recognition, binary attribute classification, and face recognition, achieving or surpassing specialized methods in most tasks. Our training framework can also be applied to auxiliary supervised learning, significantly improving performance in data-sparse tasks such as age estimation and expression recognition. The code and models will be made publicly available at https://github.com/lxq1000/Faceptor.
FakeNewsGPT4: Advancing Multimodal Fake News Detection through Knowledge-Augmented LVLMs
Mar 04, 2024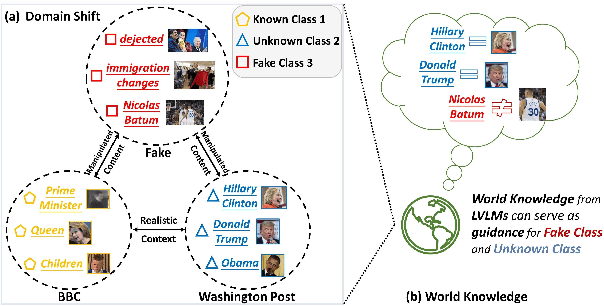
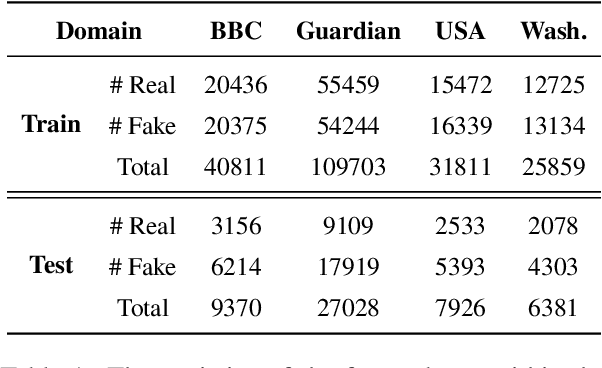
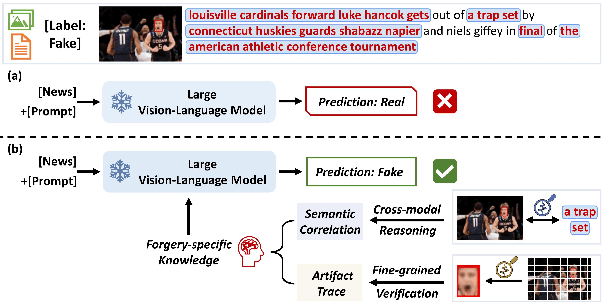
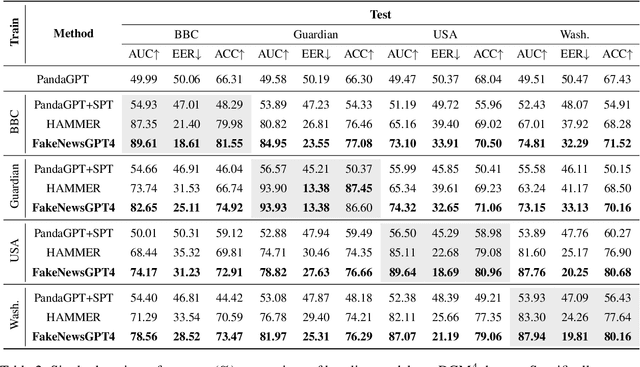
The massive generation of multimodal fake news exhibits substantial distribution discrepancies, prompting the need for generalized detectors. However, the insulated nature of training within specific domains restricts the capability of classical detectors to obtain open-world facts. In this paper, we propose FakeNewsGPT4, a novel framework that augments Large Vision-Language Models (LVLMs) with forgery-specific knowledge for manipulation reasoning while inheriting extensive world knowledge as complementary. Knowledge augmentation in FakeNewsGPT4 involves acquiring two types of forgery-specific knowledge, i.e., semantic correlation and artifact trace, and merging them into LVLMs. Specifically, we design a multi-level cross-modal reasoning module that establishes interactions across modalities for extracting semantic correlations. Concurrently, a dual-branch fine-grained verification module is presented to comprehend localized details to encode artifact traces. The generated knowledge is translated into refined embeddings compatible with LVLMs. We also incorporate candidate answer heuristics and soft prompts to enhance input informativeness. Extensive experiments on the public benchmark demonstrate that FakeNewsGPT4 achieves superior cross-domain performance compared to previous methods. Code will be available.
Open-Set Facial Expression Recognition
Jan 23, 2024Facial expression recognition (FER) models are typically trained on datasets with a fixed number of seven basic classes. However, recent research works point out that there are far more expressions than the basic ones. Thus, when these models are deployed in the real world, they may encounter unknown classes, such as compound expressions that cannot be classified into existing basic classes. To address this issue, we propose the open-set FER task for the first time. Though there are many existing open-set recognition methods, we argue that they do not work well for open-set FER because FER data are all human faces with very small inter-class distances, which makes the open-set samples very similar to close-set samples. In this paper, we are the first to transform the disadvantage of small inter-class distance into an advantage by proposing a new way for open-set FER. Specifically, we find that small inter-class distance allows for sparsely distributed pseudo labels of open-set samples, which can be viewed as symmetric noisy labels. Based on this novel observation, we convert the open-set FER to a noisy label detection problem. We further propose a novel method that incorporates attention map consistency and cycle training to detect the open-set samples. Extensive experiments on various FER datasets demonstrate that our method clearly outperforms state-of-the-art open-set recognition methods by large margins. Code is available at https://github.com/zyh-uaiaaaa.
Marginal Debiased Network for Fair Visual Recognition
Jan 04, 2024Deep neural networks (DNNs) are often prone to learn the spurious correlations between target classes and bias attributes, like gender and race, inherent in a major portion of training data (bias-aligned samples), thus showing unfair behavior and arising controversy in the modern pluralistic and egalitarian society. In this paper, we propose a novel marginal debiased network (MDN) to learn debiased representations. More specifically, a marginal softmax loss (MSL) is designed by introducing the idea of margin penalty into the fairness problem, which assigns a larger margin for bias-conflicting samples (data without spurious correlations) than for bias-aligned ones, so as to deemphasize the spurious correlations and improve generalization on unbiased test criteria. To determine the margins, our MDN is optimized through a meta learning framework. We propose a meta equalized loss (MEL) to perceive the model fairness, and adaptively update the margin parameters by metaoptimization which requires the trained model guided by the optimal margins should minimize MEL computed on an unbiased meta-validation set. Extensive experiments on BiasedMNIST, Corrupted CIFAR-10, CelebA and UTK-Face datasets demonstrate that our MDN can achieve a remarkable performance on under-represented samples and obtain superior debiased results against the previous approaches.
Enhancing Generalization of Invisible Facial Privacy Cloak via Gradient Accumulation
Jan 03, 2024The blooming of social media and face recognition (FR) systems has increased people's concern about privacy and security. A new type of adversarial privacy cloak (class-universal) can be applied to all the images of regular users, to prevent malicious FR systems from acquiring their identity information. In this work, we discover the optimization dilemma in the existing methods -- the local optima problem in large-batch optimization and the gradient information elimination problem in small-batch optimization. To solve these problems, we propose Gradient Accumulation (GA) to aggregate multiple small-batch gradients into a one-step iterative gradient to enhance the gradient stability and reduce the usage of quantization operations. Experiments show that our proposed method achieves high performance on the Privacy-Commons dataset against black-box face recognition models.
Skeleton2vec: A Self-supervised Learning Framework with Contextualized Target Representations for Skeleton Sequence
Jan 01, 2024Self-supervised pre-training paradigms have been extensively explored in the field of skeleton-based action recognition. In particular, methods based on masked prediction have pushed the performance of pre-training to a new height. However, these methods take low-level features, such as raw joint coordinates or temporal motion, as prediction targets for the masked regions, which is suboptimal. In this paper, we show that using high-level contextualized features as prediction targets can achieve superior performance. Specifically, we propose Skeleton2vec, a simple and efficient self-supervised 3D action representation learning framework, which utilizes a transformer-based teacher encoder taking unmasked training samples as input to create latent contextualized representations as prediction targets. Benefiting from the self-attention mechanism, the latent representations generated by the teacher encoder can incorporate the global context of the entire training samples, leading to a richer training task. Additionally, considering the high temporal correlations in skeleton sequences, we propose a motion-aware tube masking strategy which divides the skeleton sequence into several tubes and performs persistent masking within each tube based on motion priors, thus forcing the model to build long-range spatio-temporal connections and focus on action-semantic richer regions. Extensive experiments on NTU-60, NTU-120, and PKU-MMD datasets demonstrate that our proposed Skeleton2vec outperforms previous methods and achieves state-of-the-art results.
Depth Map Denoising Network and Lightweight Fusion Network for Enhanced 3D Face Recognition
Jan 01, 2024With the increasing availability of consumer depth sensors, 3D face recognition (FR) has attracted more and more attention. However, the data acquired by these sensors are often coarse and noisy, making them impractical to use directly. In this paper, we introduce an innovative Depth map denoising network (DMDNet) based on the Denoising Implicit Image Function (DIIF) to reduce noise and enhance the quality of facial depth images for low-quality 3D FR. After generating clean depth faces using DMDNet, we further design a powerful recognition network called Lightweight Depth and Normal Fusion network (LDNFNet), which incorporates a multi-branch fusion block to learn unique and complementary features between different modalities such as depth and normal images. Comprehensive experiments conducted on four distinct low-quality databases demonstrate the effectiveness and robustness of our proposed methods. Furthermore, when combining DMDNet and LDNFNet, we achieve state-of-the-art results on the Lock3DFace database.
AdvCloak: Customized Adversarial Cloak for Privacy Protection
Dec 22, 2023With extensive face images being shared on social media, there has been a notable escalation in privacy concerns. In this paper, we propose AdvCloak, an innovative framework for privacy protection using generative models. AdvCloak is designed to automatically customize class-wise adversarial masks that can maintain superior image-level naturalness while providing enhanced feature-level generalization ability. Specifically, AdvCloak sequentially optimizes the generative adversarial networks by employing a two-stage training strategy. This strategy initially focuses on adapting the masks to the unique individual faces via image-specific training and then enhances their feature-level generalization ability to diverse facial variations of individuals via person-specific training. To fully utilize the limited training data, we combine AdvCloak with several general geometric modeling methods, to better describe the feature subspace of source identities. Extensive quantitative and qualitative evaluations on both common and celebrity datasets demonstrate that AdvCloak outperforms existing state-of-the-art methods in terms of efficiency and effectiveness.
Oracle Character Recognition using Unsupervised Discriminative Consistency Network
Dec 11, 2023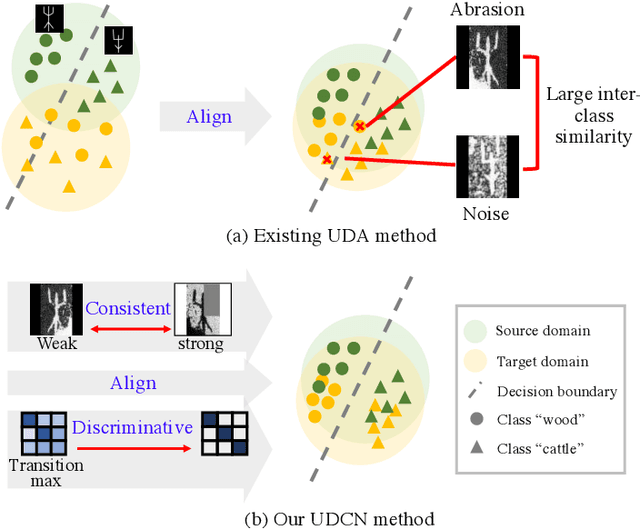
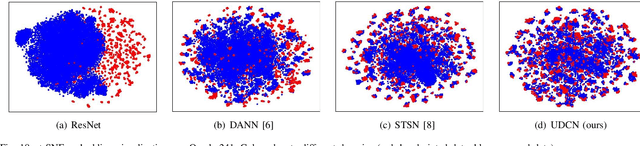
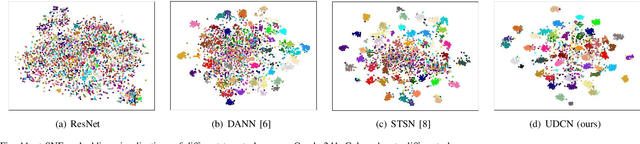

Ancient history relies on the study of ancient characters. However, real-world scanned oracle characters are difficult to collect and annotate, posing a major obstacle for oracle character recognition (OrCR). Besides, serious abrasion and inter-class similarity also make OrCR more challenging. In this paper, we propose a novel unsupervised domain adaptation method for OrCR, which enables to transfer knowledge from labeled handprinted oracle characters to unlabeled scanned data. We leverage pseudo-labeling to incorporate the semantic information into adaptation and constrain augmentation consistency to make the predictions of scanned samples consistent under different perturbations, leading to the model robustness to abrasion, stain and distortion. Simultaneously, an unsupervised transition loss is proposed to learn more discriminative features on the scanned domain by optimizing both between-class and within-class transition probability. Extensive experiments show that our approach achieves state-of-the-art result on Oracle-241 dataset and substantially outperforms the recently proposed structure-texture separation network by 15.1%.