 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeiping Ding
Referring Flexible Image Restoration
Apr 16, 2024
In reality, images often exhibit multiple degradations, such as rain and fog at night (triple degradations). However, in many cases, individuals may not want to remove all degradations, for instance, a blurry lens revealing a beautiful snowy landscape (double degradations). In such scenarios, people may only desire to deblur. These situations and requirements shed light on a new challenge in image restoration, where a model must perceive and remove specific degradation types specified by human commands in images with multiple degradations. We term this task Referring Flexible Image Restoration (RFIR). To address this, we first construct a large-scale synthetic dataset called RFIR, comprising 153,423 samples with the degraded image, text prompt for specific degradation removal and restored image. RFIR consists of five basic degradation types: blur, rain, haze, low light and snow while six main sub-categories are included for varying degrees of degradation removal. To tackle the challenge, we propose a novel transformer-based multi-task model named TransRFIR, which simultaneously perceives degradation types in the degraded image and removes specific degradation upon text prompt. TransRFIR is based on two devised attention modules, Multi-Head Agent Self-Attention (MHASA) and Multi-Head Agent Cross Attention (MHACA), where MHASA and MHACA introduce the agent token and reach the linear complexity, achieving lower computation cost than vanilla self-attention and cross-attention and obtaining competitive performances. Our TransRFIR achieves state-of-the-art performances compared with other counterparts and is proven as an effective architecture for image restoration. We release our project at https://github.com/GuanRunwei/FIR-CP.
How to characterize imprecision in multi-view clustering?
Apr 07, 2024It is still challenging to cluster multi-view data since existing methods can only assign an object to a specific (singleton) cluster when combining different view information. As a result, it fails to characterize imprecision of objects in overlapping regions of different clusters, thus leading to a high risk of errors. In this paper, we thereby want to answer the question: how to characterize imprecision in multi-view clustering? Correspondingly, we propose a multi-view low-rank evidential c-means based on entropy constraint (MvLRECM). The proposed MvLRECM can be considered as a multi-view version of evidential c-means based on the theory of belief functions. In MvLRECM, each object is allowed to belong to different clusters with various degrees of support (masses of belief) to characterize uncertainty when decision-making. Moreover, if an object is in the overlapping region of several singleton clusters, it can be assigned to a meta-cluster, defined as the union of these singleton clusters, to characterize the local imprecision in the result. In addition, entropy-weighting and low-rank constraints are employed to reduce imprecision and improve accuracy. Compared to state-of-the-art methods, the effectiveness of MvLRECM is demonstrated based on several toy and UCI real datasets.
Few-Shot Object Detection: Research Advances and Challenges
Apr 07, 2024Object detection as a subfield within computer vision has achieved remarkable progress, which aims to accurately identify and locate a specific object from images or videos. Such methods rely on large-scale labeled training samples for each object category to ensure accurate detection, but obtaining extensive annotated data is a labor-intensive and expensive process in many real-world scenarios. To tackle this challenge, researchers have explored few-shot object detection (FSOD) that combines few-shot learning and object detection techniques to rapidly adapt to novel objects with limited annotated samples. This paper presents a comprehensive survey to review the significant advancements in the field of FSOD in recent years and summarize the existing challenges and solutions. Specifically, we first introduce the background and definition of FSOD to emphasize potential value in advancing the field of computer vision. We then propose a novel FSOD taxonomy method and survey the plentifully remarkable FSOD algorithms based on this fact to report a comprehensive overview that facilitates a deeper understanding of the FSOD problem and the development of innovative solutions. Finally, we discuss the advantages and limitations of these algorithms to summarize the challenges, potential research direction, and development trend of object detection in the data scarcity scenario.
Fusion Dynamical Systems with Machine Learning in Imitation Learning: A Comprehensive Overview
Mar 29, 2024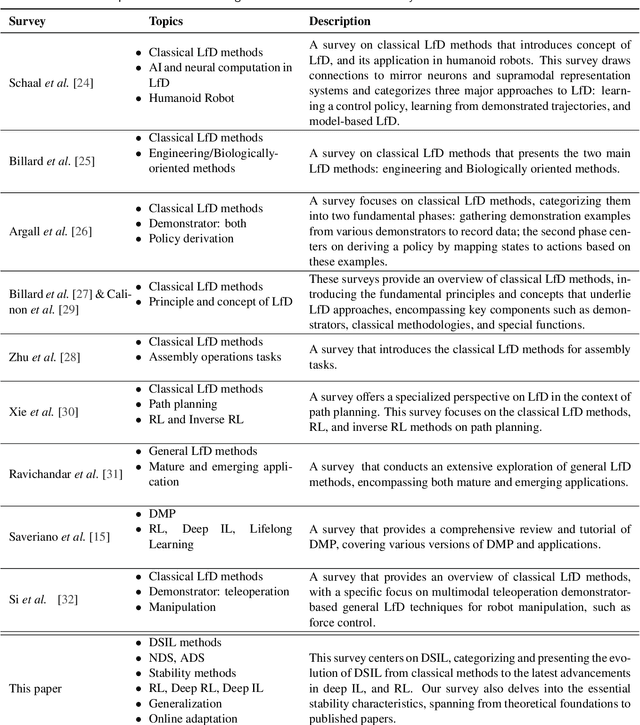
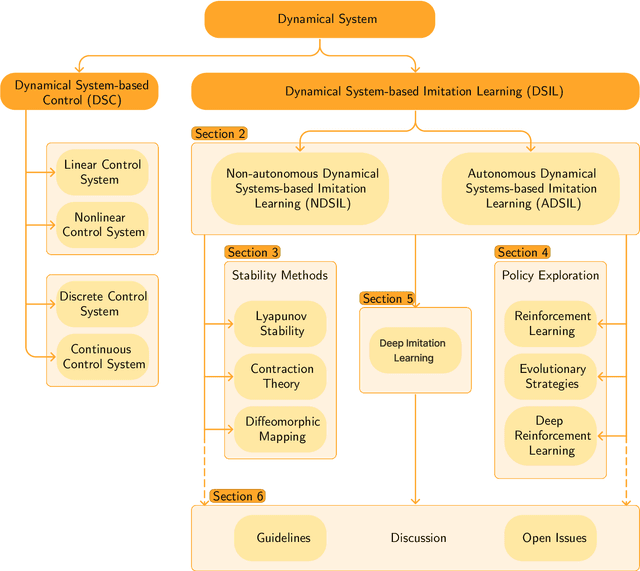

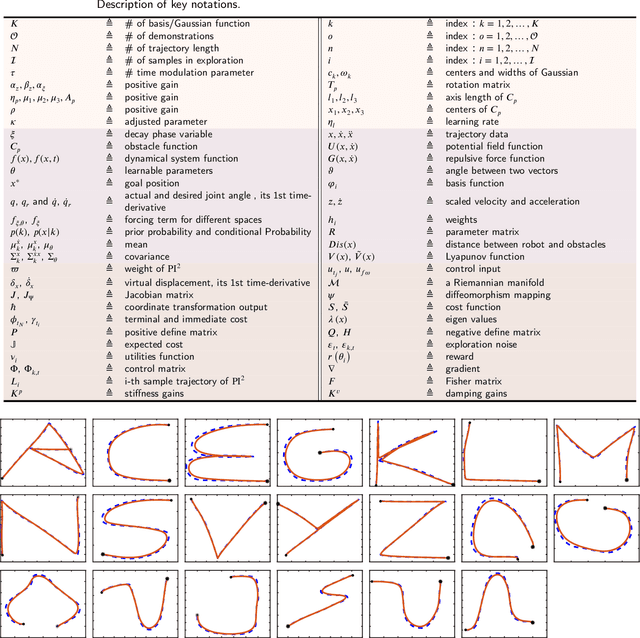
Imitation Learning (IL), also referred to as Learning from Demonstration (LfD), holds significant promise for capturing expert motor skills through efficient imitation, facilitating adept navigation of complex scenarios. A persistent challenge in IL lies in extending generalization from historical demonstrations, enabling the acquisition of new skills without re-teaching. Dynamical system-based IL (DSIL) emerges as a significant subset of IL methodologies, offering the ability to learn trajectories via movement primitives and policy learning based on experiential abstraction. This paper emphasizes the fusion of theoretical paradigms, integrating control theory principles inherent in dynamical systems into IL. This integration notably enhances robustness, adaptability, and convergence in the face of novel scenarios. This survey aims to present a comprehensive overview of DSIL methods, spanning from classical approaches to recent advanced approaches. We categorize DSIL into autonomous dynamical systems and non-autonomous dynamical systems, surveying traditional IL methods with low-dimensional input and advanced deep IL methods with high-dimensional input. Additionally, we present and analyze three main stability methods for IL: Lyapunov stability, contraction theory, and diffeomorphism mapping. Our exploration also extends to popular policy improvement methods for DSIL, encompassing reinforcement learning, deep reinforcement learning, and evolutionary strategies.
DE$^3$-BERT: Distance-Enhanced Early Exiting for BERT based on Prototypical Networks
Feb 03, 2024Early exiting has demonstrated its effectiveness in accelerating the inference of pre-trained language models like BERT by dynamically adjusting the number of layers executed. However, most existing early exiting methods only consider local information from an individual test sample to determine their exiting indicators, failing to leverage the global information offered by sample population. This leads to suboptimal estimation of prediction correctness, resulting in erroneous exiting decisions. To bridge the gap, we explore the necessity of effectively combining both local and global information to ensure reliable early exiting during inference. Purposefully, we leverage prototypical networks to learn class prototypes and devise a distance metric between samples and class prototypes. This enables us to utilize global information for estimating the correctness of early predictions. On this basis, we propose a novel Distance-Enhanced Early Exiting framework for BERT (DE$^3$-BERT). DE$^3$-BERT implements a hybrid exiting strategy that supplements classic entropy-based local information with distance-based global information to enhance the estimation of prediction correctness for more reliable early exiting decisions. Extensive experiments on the GLUE benchmark demonstrate that DE$^3$-BERT consistently outperforms state-of-the-art models under different speed-up ratios with minimal storage or computational overhead, yielding a better trade-off between model performance and inference efficiency. Additionally, an in-depth analysis further validates the generality and interpretability of our method.
Achelous++: Power-Oriented Water-Surface Panoptic Perception Framework on Edge Devices based on Vision-Radar Fusion and Pruning of Heterogeneous Modalities
Dec 14, 2023Urban water-surface robust perception serves as the foundation for intelligent monitoring of aquatic environments and the autonomous navigation and operation of unmanned vessels, especially in the context of waterway safety. It is worth noting that current multi-sensor fusion and multi-task learning models consume substantial power and heavily rely on high-power GPUs for inference. This contributes to increased carbon emissions, a concern that runs counter to the prevailing emphasis on environmental preservation and the pursuit of sustainable, low-carbon urban environments. In light of these concerns, this paper concentrates on low-power, lightweight, multi-task panoptic perception through the fusion of visual and 4D radar data, which is seen as a promising low-cost perception method. We propose a framework named Achelous++ that facilitates the development and comprehensive evaluation of multi-task water-surface panoptic perception models. Achelous++ can simultaneously execute five perception tasks with high speed and low power consumption, including object detection, object semantic segmentation, drivable-area segmentation, waterline segmentation, and radar point cloud semantic segmentation. Furthermore, to meet the demand for developers to customize models for real-time inference on low-performance devices, a novel multi-modal pruning strategy known as Heterogeneous-Aware SynFlow (HA-SynFlow) is proposed. Besides, Achelous++ also supports random pruning at initialization with different layer-wise sparsity, such as Uniform and Erdos-Renyi-Kernel (ERK). Overall, our Achelous++ framework achieves state-of-the-art performance on the WaterScenes benchmark, excelling in both accuracy and power efficiency compared to other single-task and multi-task models. We release and maintain the code at https://github.com/GuanRunwei/Achelous.
Survey on deep learning in multimodal medical imaging for cancer detection
Dec 04, 2023The task of multimodal cancer detection is to determine the locations and categories of lesions by using different imaging techniques, which is one of the key research methods for cancer diagnosis. Recently, deep learning-based object detection has made significant developments due to its strength in semantic feature extraction and nonlinear function fitting. However, multimodal cancer detection remains challenging due to morphological differences in lesions, interpatient variability, difficulty in annotation, and imaging artifacts. In this survey, we mainly investigate over 150 papers in recent years with respect to multimodal cancer detection using deep learning, with a focus on datasets and solutions to various challenges such as data annotation, variance between classes, small-scale lesions, and occlusion. We also provide an overview of the advantages and drawbacks of each approach. Finally, we discuss the current scope of work and provide directions for the future development of multimodal cancer detection.
DNFS-VNE: Deep Neuro-Fuzzy System-Driven Virtual Network Embedding Algorithm
Oct 13, 2023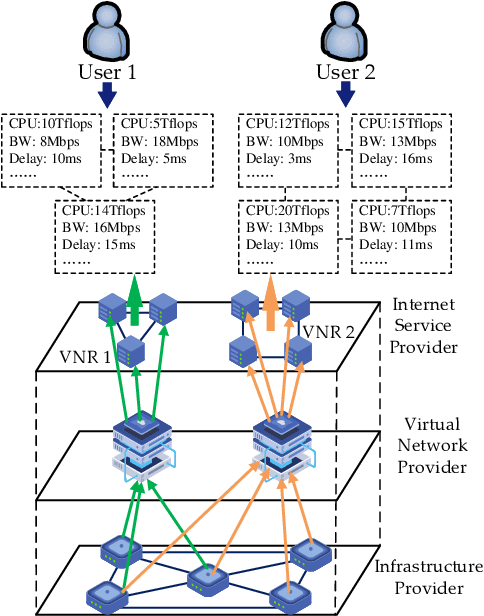
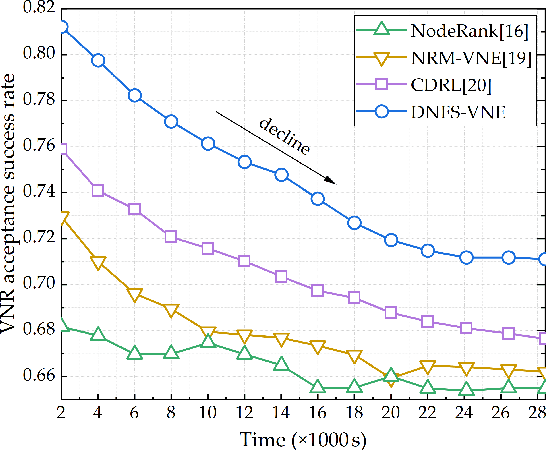
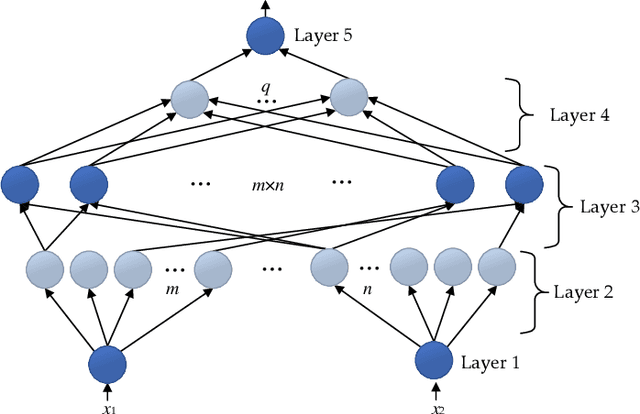
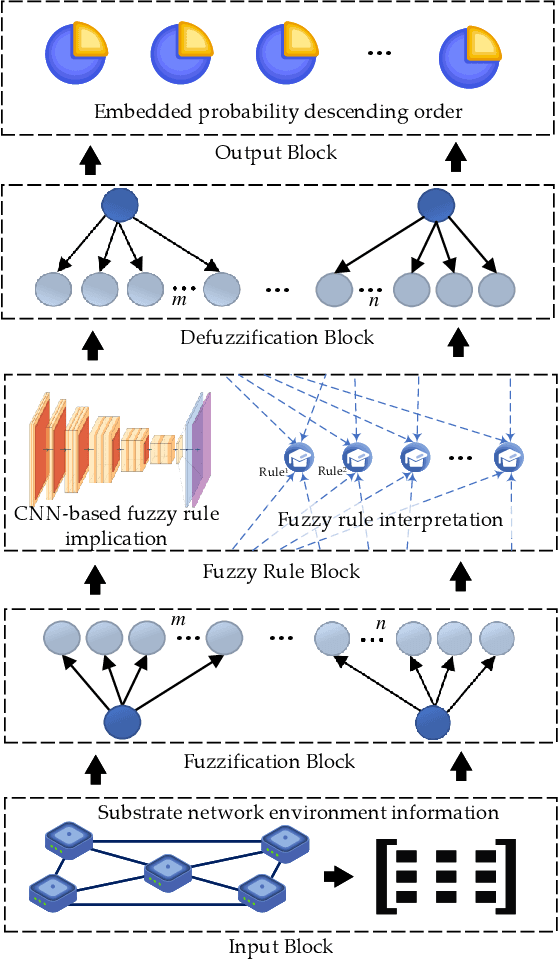
By decoupling substrate resources, network virtualization (NV) is a promising solution for meeting diverse demands and ensuring differentiated quality of service (QoS). In particular, virtual network embedding (VNE) is a critical enabling technology that enhances the flexibility and scalability of network deployment by addressing the coupling of Internet processes and services. However, in the existing works, the black-box nature of deep neural networks (DNNs) limits the analysis, development, and improvement of systems. In recent times, interpretable deep learning (DL) represented by deep neuro-fuzzy systems (DNFS) combined with fuzzy inference has shown promising interpretability to further exploit the hidden value in the data. Motivated by this, we propose a DNFS-based VNE algorithm that aims to provide an interpretable NV scheme. Specifically, data-driven convolutional neural networks (CNNs) are used as fuzzy implication operators to compute the embedding probabilities of candidate substrate nodes through entailment operations. And, the identified fuzzy rule patterns are cached into the weights by forward computation and gradient back-propagation (BP). In addition, the fuzzy rule base is constructed based on Mamdani-type linguistic rules using linguistic labels. Finally, the effectiveness of evaluation indicators and fuzzy rules is verified by experiments.
EGANS: Evolutionary Generative Adversarial Network Search for Zero-Shot Learning
Aug 19, 2023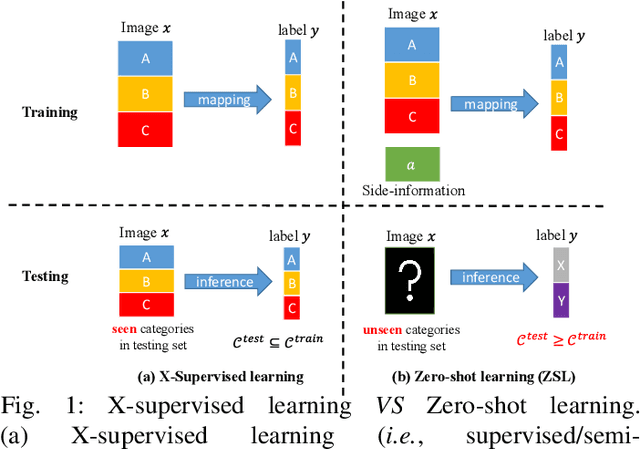
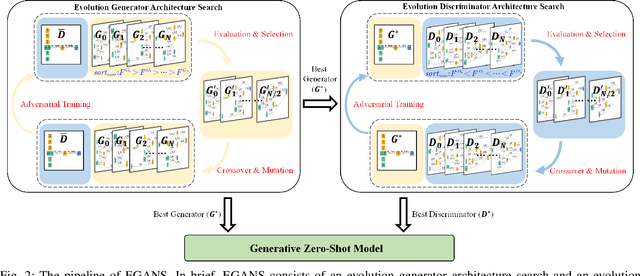
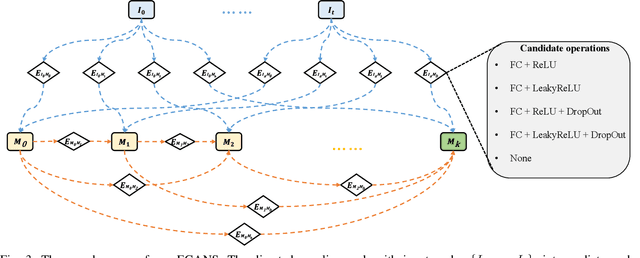
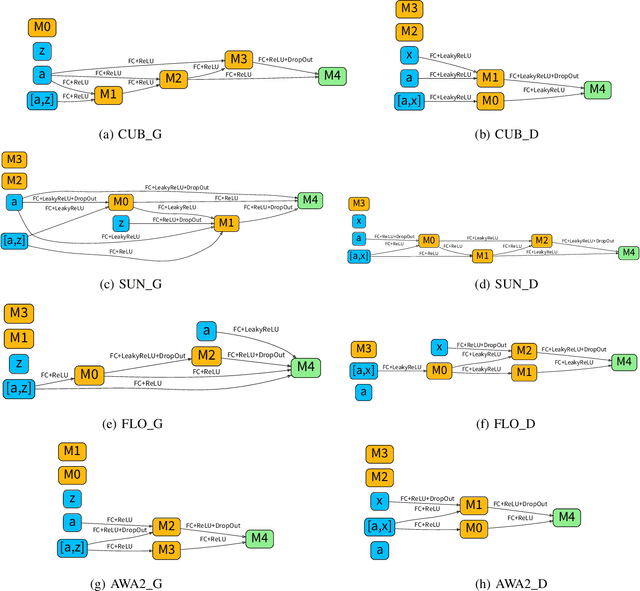
Zero-shot learning (ZSL) aims to recognize the novel classes which cannot be collected for training a prediction model. Accordingly, generative models (e.g., generative adversarial network (GAN)) are typically used to synthesize the visual samples conditioned by the class semantic vectors and achieve remarkable progress for ZSL. However, existing GAN-based generative ZSL methods are based on hand-crafted models, which cannot adapt to various datasets/scenarios and fails to model instability. To alleviate these challenges, we propose evolutionary generative adversarial network search (termed EGANS) to automatically design the generative network with good adaptation and stability, enabling reliable visual feature sample synthesis for advancing ZSL. Specifically, we adopt cooperative dual evolution to conduct a neural architecture search for both generator and discriminator under a unified evolutionary adversarial framework. EGANS is learned by two stages: evolution generator architecture search and evolution discriminator architecture search. During the evolution generator architecture search, we adopt a many-to-one adversarial training strategy to evolutionarily search for the optimal generator. Then the optimal generator is further applied to search for the optimal discriminator in the evolution discriminator architecture search with a similar evolution search algorithm. Once the optimal generator and discriminator are searched, we entail them into various generative ZSL baselines for ZSL classification. Extensive experiments show that EGANS consistently improve existing generative ZSL methods on the standard CUB, SUN, AWA2 and FLO datasets. The significant performance gains indicate that the evolutionary neural architecture search explores a virgin field in ZSL.
A Survey on Fairness-aware Recommender Systems
Jun 01, 2023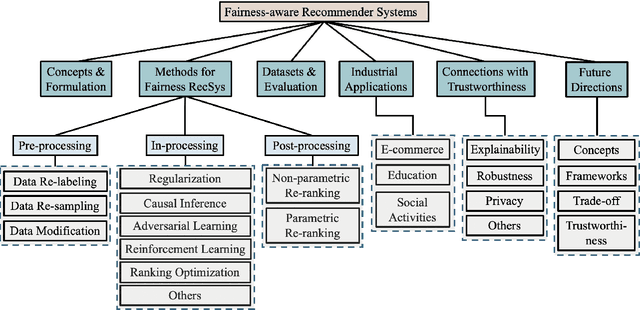
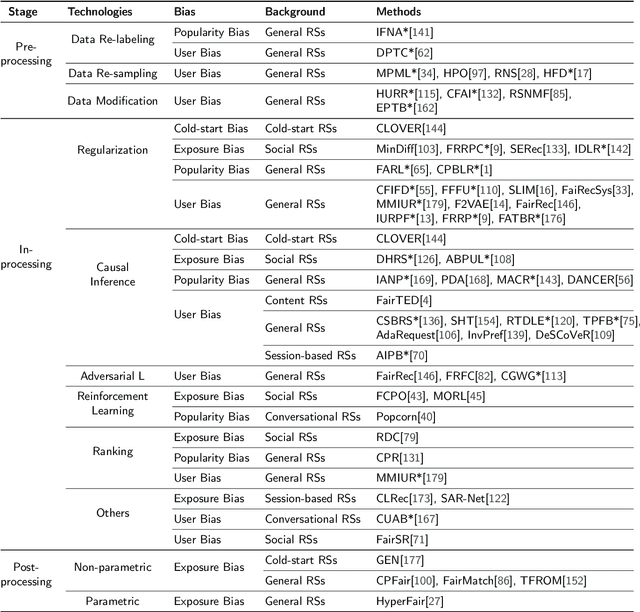
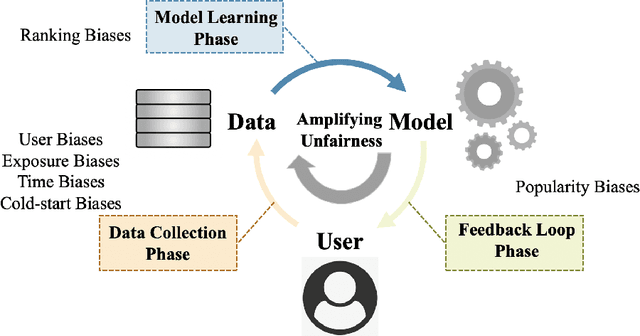
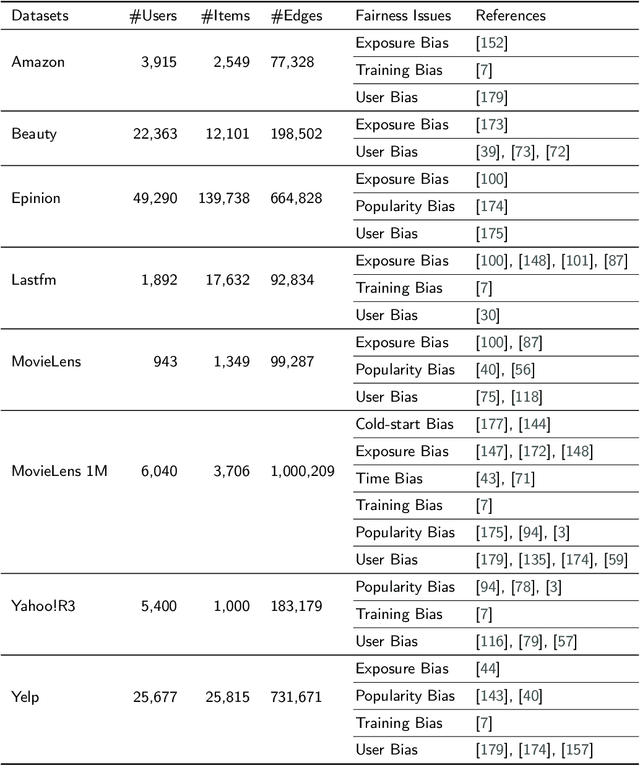
As information filtering services, recommender systems have extremely enriched our daily life by providing personalized suggestions and facilitating people in decision-making, which makes them vital and indispensable to human society in the information era. However, as people become more dependent on them, recent studies show that recommender systems potentially own unintentional impacts on society and individuals because of their unfairness (e.g., gender discrimination in job recommendations). To develop trustworthy services, it is crucial to devise fairness-aware recommender systems that can mitigate these bias issues. In this survey, we summarise existing methodologies and practices of fairness in recommender systems. Firstly, we present concepts of fairness in different recommendation scenarios, comprehensively categorize current advances, and introduce typical methods to promote fairness in different stages of recommender systems. Next, after introducing datasets and evaluation metrics applied to assess the fairness of recommender systems, we will delve into the significant influence that fairness-aware recommender systems exert on real-world industrial applications. Subsequently, we highlight the connection between fairness and other principles of trustworthy recommender systems, aiming to consider trustworthiness principles holistically while advocating for fairness. Finally, we summarize this review, spotlighting promising opportunities in comprehending concepts, frameworks, the balance between accuracy and fairness, and the ties with trustworthiness, with the ultimate goal of fostering the development of fairness-aware recommender systems.