 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhongyi Han
CLIP-driven Outliers Synthesis for few-shot OOD detection
Mar 30, 2024
Few-shot OOD detection focuses on recognizing out-of-distribution (OOD) images that belong to classes unseen during training, with the use of only a small number of labeled in-distribution (ID) images. Up to now, a mainstream strategy is based on large-scale vision-language models, such as CLIP. However, these methods overlook a crucial issue: the lack of reliable OOD supervision information, which can lead to biased boundaries between in-distribution (ID) and OOD. To tackle this problem, we propose CLIP-driven Outliers Synthesis~(CLIP-OS). Firstly, CLIP-OS enhances patch-level features' perception by newly proposed patch uniform convolution, and adaptively obtains the proportion of ID-relevant information by employing CLIP-surgery-discrepancy, thus achieving separation between ID-relevant and ID-irrelevant. Next, CLIP-OS synthesizes reliable OOD data by mixing up ID-relevant features from different classes to provide OOD supervision information. Afterward, CLIP-OS leverages synthetic OOD samples by unknown-aware prompt learning to enhance the separability of ID and OOD. Extensive experiments across multiple benchmarks demonstrate that CLIP-OS achieves superior few-shot OOD detection capability.
HCVP: Leveraging Hierarchical Contrastive Visual Prompt for Domain Generalization
Jan 18, 2024Domain Generalization (DG) endeavors to create machine learning models that excel in unseen scenarios by learning invariant features. In DG, the prevalent practice of constraining models to a fixed structure or uniform parameterization to encapsulate invariant features can inadvertently blend specific aspects. Such an approach struggles with nuanced differentiation of inter-domain variations and may exhibit bias towards certain domains, hindering the precise learning of domain-invariant features. Recognizing this, we introduce a novel method designed to supplement the model with domain-level and task-specific characteristics. This approach aims to guide the model in more effectively separating invariant features from specific characteristics, thereby boosting the generalization. Building on the emerging trend of visual prompts in the DG paradigm, our work introduces the novel \textbf{H}ierarchical \textbf{C}ontrastive \textbf{V}isual \textbf{P}rompt (HCVP) methodology. This represents a significant advancement in the field, setting itself apart with a unique generative approach to prompts, alongside an explicit model structure and specialized loss functions. Differing from traditional visual prompts that are often shared across entire datasets, HCVP utilizes a hierarchical prompt generation network enhanced by prompt contrastive learning. These generative prompts are instance-dependent, catering to the unique characteristics inherent to different domains and tasks. Additionally, we devise a prompt modulation network that serves as a bridge, effectively incorporating the generated visual prompts into the vision transformer backbone. Experiments conducted on five DG datasets demonstrate the effectiveness of HCVP, outperforming both established DG algorithms and adaptation protocols.
How Well Does GPT-4V(ision) Adapt to Distribution Shifts? A Preliminary Investigation
Dec 13, 2023



In machine learning, generalization against distribution shifts -- where deployment conditions diverge from the training scenarios -- is crucial, particularly in fields like climate modeling, biomedicine, and autonomous driving. The emergence of foundation models, distinguished by their extensive pretraining and task versatility, has led to an increased interest in their adaptability to distribution shifts. GPT-4V(ision) acts as the most advanced publicly accessible multimodal foundation model, with extensive applications across various domains, including anomaly detection, video understanding, image generation, and medical diagnosis. However, its robustness against data distributions remains largely underexplored. Addressing this gap, this study rigorously evaluates GPT-4V's adaptability and generalization capabilities in dynamic environments, benchmarking against prominent models like CLIP and LLaVA. We delve into GPT-4V's zero-shot generalization across 13 diverse datasets spanning natural, medical, and molecular domains. We further investigate its adaptability to controlled data perturbations and examine the efficacy of in-context learning as a tool to enhance its adaptation. Our findings delineate GPT-4V's capability boundaries in distribution shifts, shedding light on its strengths and limitations across various scenarios. Importantly, this investigation contributes to our understanding of how AI foundation models generalize to distribution shifts, offering pivotal insights into their adaptability and robustness. Code is publicly available at https://github.com/jameszhou-gl/gpt-4v-distribution-shift.
Topological Structure Learning for Weakly-Supervised Out-of-Distribution Detection
Sep 16, 2022



Out-of-distribution (OOD) detection is the key to deploying models safely in the open world. For OOD detection, collecting sufficient in-distribution (ID) labeled data is usually more time-consuming and costly than unlabeled data. When ID labeled data is limited, the previous OOD detection methods are no longer superior due to their high dependence on the amount of ID labeled data. Based on limited ID labeled data and sufficient unlabeled data, we define a new setting called Weakly-Supervised Out-of-Distribution Detection (WSOOD). To solve the new problem, we propose an effective method called Topological Structure Learning (TSL). Firstly, TSL uses a contrastive learning method to build the initial topological structure space for ID and OOD data. Secondly, TSL mines effective topological connections in the initial topological space. Finally, based on limited ID labeled data and mined topological connections, TSL reconstructs the topological structure in a new topological space to increase the separability of ID and OOD instances. Extensive studies on several representative datasets show that TSL remarkably outperforms the state-of-the-art, verifying the validity and robustness of our method in the new setting of WSOOD.
Active Source Free Domain Adaptation
May 22, 2022



Source free domain adaptation (SFDA) aims to transfer a trained source model to the unlabeled target domain without accessing the source data. However, the SFDA setting faces an effect bottleneck due to the absence of source data and target supervised information, as evidenced by the limited performance gains of newest SFDA methods. In this paper, for the first time, we introduce a more practical scenario called active source free domain adaptation (ASFDA) that permits actively selecting a few target data to be labeled by experts. To achieve that, we first find that those satisfying the properties of neighbor-chaotic, individual-different, and target-like are the best points to select, and we define them as the minimum happy (MH) points. We then propose minimum happy points learning (MHPL) to actively explore and exploit MH points. We design three unique strategies: neighbor ambient uncertainty, neighbor diversity relaxation, and one-shot querying, to explore the MH points. Further, to fully exploit MH points in the learning process, we design a neighbor focal loss that assigns the weighted neighbor purity to the cross-entropy loss of MH points to make the model focus more on them. Extensive experiments verify that MHPL remarkably exceeds the various types of baselines and achieves significant performance gains at a small cost of labeling.
Learning to Rectify for Robust Learning with Noisy Labels
Nov 08, 2021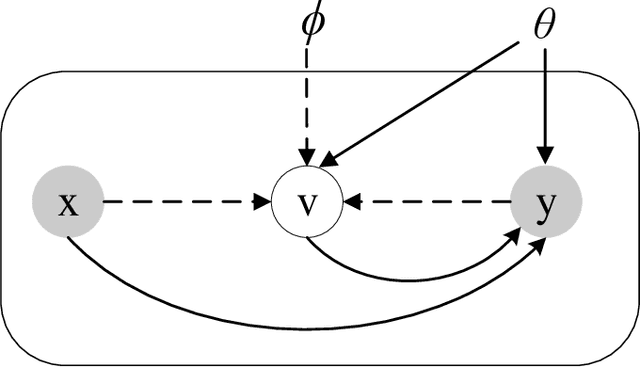
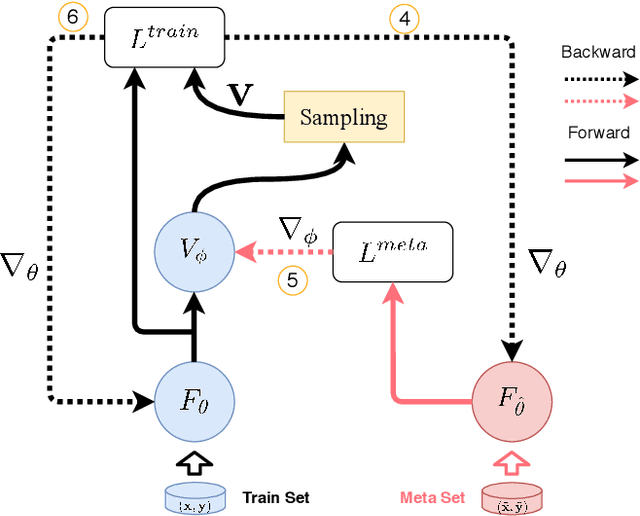
Label noise significantly degrades the generalization ability of deep models in applications. Effective strategies and approaches, \textit{e.g.} re-weighting, or loss correction, are designed to alleviate the negative impact of label noise when training a neural network. Those existing works usually rely on the pre-specified architecture and manually tuning the additional hyper-parameters. In this paper, we propose warped probabilistic inference (WarPI) to achieve adaptively rectifying the training procedure for the classification network within the meta-learning scenario. In contrast to the deterministic models, WarPI is formulated as a hierarchical probabilistic model by learning an amortization meta-network, which can resolve sample ambiguity and be therefore more robust to serious label noise. Unlike the existing approximated weighting function of directly generating weight values from losses, our meta-network is learned to estimate a rectifying vector from the input of the logits and labels, which has the capability of leveraging sufficient information lying in them. This provides an effective way to rectify the learning procedure for the classification network, demonstrating a significant improvement of the generalization ability. Besides, modeling the rectifying vector as a latent variable and learning the meta-network can be seamlessly integrated into the SGD optimization of the classification network. We evaluate WarPI on four benchmarks of robust learning with noisy labels and achieve the new state-of-the-art under variant noise types. Extensive study and analysis also demonstrate the effectiveness of our model.
Learning Transferable Parameters for Unsupervised Domain Adaptation
Aug 13, 2021



Unsupervised domain adaptation (UDA) enables a learning machine to adapt from a labeled source domain to an unlabeled domain under the distribution shift. Thanks to the strong representation ability of deep neural networks, recent remarkable achievements in UDA resort to learning domain-invariant features. Intuitively, the hope is that a good feature representation, together with the hypothesis learned from the source domain, can generalize well to the target domain. However, the learning processes of domain-invariant features and source hypothesis inevitably involve domain-specific information that would degrade the generalizability of UDA models on the target domain. In this paper, motivated by the lottery ticket hypothesis that only partial parameters are essential for generalization, we find that only partial parameters are essential for learning domain-invariant information and generalizing well in UDA. Such parameters are termed transferable parameters. In contrast, the other parameters tend to fit domain-specific details and often fail to generalize, which we term as untransferable parameters. Driven by this insight, we propose Transferable Parameter Learning (TransPar) to reduce the side effect brought by domain-specific information in the learning process and thus enhance the memorization of domain-invariant information. Specifically, according to the distribution discrepancy degree, we divide all parameters into transferable and untransferable ones in each training iteration. We then perform separate updates rules for the two types of parameters. Extensive experiments on image classification and regression tasks (keypoint detection) show that TransPar outperforms prior arts by non-trivial margins. Moreover, experiments demonstrate that TransPar can be integrated into the most popular deep UDA networks and be easily extended to handle any data distribution shift scenarios.
Robust Screening of COVID-19 from Chest X-ray via Discriminative Cost-Sensitive Learning
May 21, 2020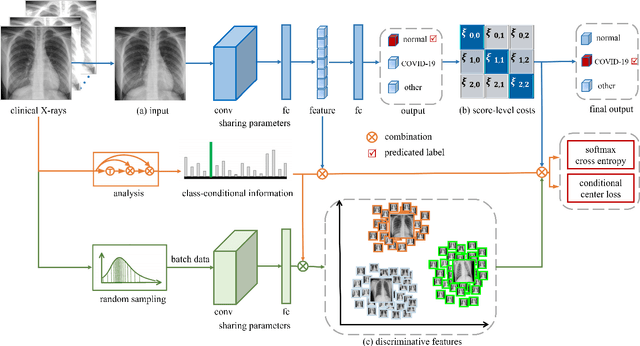
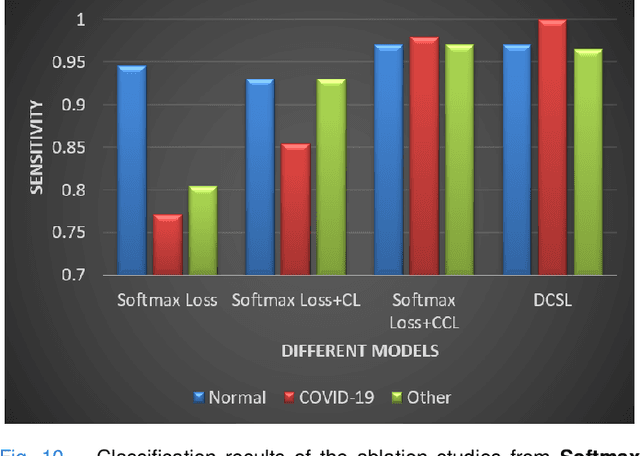
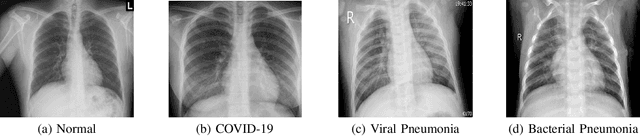
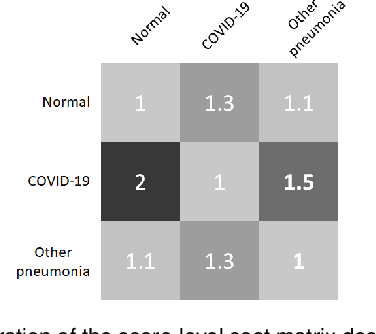
This paper addresses the new problem of automated screening of coronavirus disease 2019 (COVID-19) based on chest X-rays, which is urgently demanded toward fast stopping the pandemic. However, robust and accurate screening of COVID-19 from chest X-rays is still a globally recognized challenge because of two bottlenecks: 1) imaging features of COVID-19 share some similarities with other pneumonia on chest X-rays, and 2) the misdiagnosis rate of COVID-19 is very high, and the misdiagnosis cost is expensive. While a few pioneering works have made much progress, they underestimate both crucial bottlenecks. In this paper, we report our solution, discriminative cost-sensitive learning (DCSL), which should be the choice if the clinical needs the assisted screening of COVID-19 from chest X-rays. DCSL combines both advantages from fine-grained classification and cost-sensitive learning. Firstly, DCSL develops a conditional center loss that learns deep discriminative representation. Secondly, DCSL establishes score-level cost-sensitive learning that can adaptively enlarge the cost of misclassifying COVID-19 examples into other classes. DCSL is so flexible that it can apply in any deep neural network. We collected a large-scale multi-class dataset comprised of 2,239 chest X-ray examples: 239 examples from confirmed COVID-19 cases, 1,000 examples with confirmed bacterial or viral pneumonia cases, and 1,000 examples of healthy people. Extensive experiments on the three-class classification show that our algorithm remarkably outperforms state-of-the-art algorithms. It achieves an accuracy of 97.01%, a precision of 97%, a sensitivity of 97.09%, and an F1-score of 96.98%. These results endow our algorithm as an efficient tool for the fast large-scale screening of COVID-19.
Towards Accurate and Robust Domain Adaptation under Noisy Environments
May 05, 2020



In non-stationary environments, learning machines usually confront the domain adaptation scenario where the data distribution does change over time. Previous domain adaptation works have achieved great success in theory and practice. However, they always lose robustness in noisy environments where the labels and features of examples from the source domain become corrupted. In this paper, we report our attempt towards achieving accurate noise-robust domain adaptation. We first give a theoretical analysis that reveals how harmful noises influence unsupervised domain adaptation. To eliminate the effect of label noise, we propose an offline curriculum learning for minimizing a newly-defined empirical source risk. To reduce the impact of feature noise, we propose a proxy distribution based margin discrepancy. We seamlessly transform our methods into an adversarial network that performs efficient joint optimization for them, successfully mitigating the negative influence from both data corruption and distribution shift. A series of empirical studies show that our algorithm remarkably outperforms state of the art, over 10% accuracy improvements in some domain adaptation tasks under noisy environments.
Unifying Neural Learning and Symbolic Reasoning for Spinal Medical Report Generation
Apr 28, 2020



Automated medical report generation in spine radiology, i.e., given spinal medical images and directly create radiologist-level diagnosis reports to support clinical decision making, is a novel yet fundamental study in the domain of artificial intelligence in healthcare. However, it is incredibly challenging because it is an extremely complicated task that involves visual perception and high-level reasoning processes. In this paper, we propose the neural-symbolic learning (NSL) framework that performs human-like learning by unifying deep neural learning and symbolic logical reasoning for the spinal medical report generation. Generally speaking, the NSL framework firstly employs deep neural learning to imitate human visual perception for detecting abnormalities of target spinal structures. Concretely, we design an adversarial graph network that interpolates a symbolic graph reasoning module into a generative adversarial network through embedding prior domain knowledge, achieving semantic segmentation of spinal structures with high complexity and variability. NSL secondly conducts human-like symbolic logical reasoning that realizes unsupervised causal effect analysis of detected entities of abnormalities through meta-interpretive learning. NSL finally fills these discoveries of target diseases into a unified template, successfully achieving a comprehensive medical report generation. When it employed in a real-world clinical dataset, a series of empirical studies demonstrate its capacity on spinal medical report generation as well as show that our algorithm remarkably exceeds existing methods in the detection of spinal structures. These indicate its potential as a clinical tool that contributes to computer-aided diagnosis.