 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKun Zhang
POMDP-Guided Active Force-Based Search for Robotic Insertion
Apr 05, 2024
In robotic insertion tasks where the uncertainty exceeds the allowable tolerance, a good search strategy is essential for successful insertion and significantly influences efficiency. The commonly used blind search method is time-consuming and does not exploit the rich contact information. In this paper, we propose a novel search strategy that actively utilizes the information contained in the contact configuration and shows high efficiency. In particular, we formulate this problem as a Partially Observable Markov Decision Process (POMDP) with carefully designed primitives based on an in-depth analysis of the contact configuration's static stability. From the formulated POMDP, we can derive a novel search strategy. Thanks to its simplicity, this search strategy can be incorporated into a Finite-State-Machine (FSM) controller. The behaviors of the FSM controller are realized through a low-level Cartesian Impedance Controller. Our method is based purely on the robot's proprioceptive sensing and does not need visual or tactile sensors. To evaluate the effectiveness of our proposed strategy and control framework, we conduct extensive comparison experiments in simulation, where we compare our method with the baseline approach. The results demonstrate that our proposed method achieves a higher success rate with a shorter search time and search trajectory length compared to the baseline method. Additionally, we show that our method is robust to various initial displacement errors.
Masked Multi-Domain Network: Multi-Type and Multi-Scenario Conversion Rate Prediction with a Single Model
Mar 26, 2024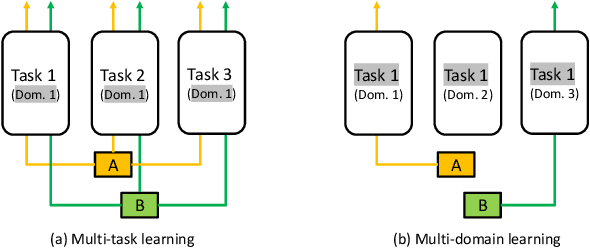

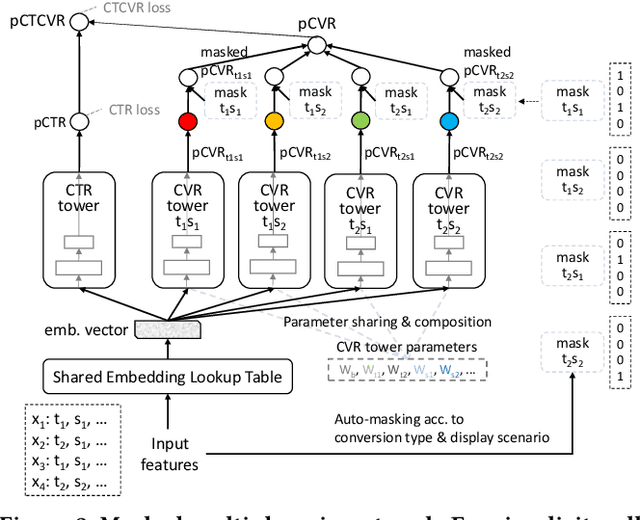
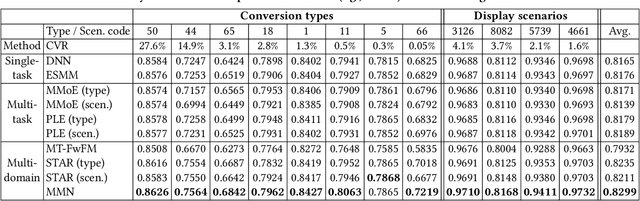
In real-world advertising systems, conversions have different types in nature and ads can be shown in different display scenarios, both of which highly impact the actual conversion rate (CVR). This results in the multi-type and multi-scenario CVR prediction problem. A desired model for this problem should satisfy the following requirements: 1) Accuracy: the model should achieve fine-grained accuracy with respect to any conversion type in any display scenario. 2) Scalability: the model parameter size should be affordable. 3) Convenience: the model should not require a large amount of effort in data partitioning, subset processing and separate storage. Existing approaches cannot simultaneously satisfy these requirements. For example, building a separate model for each (conversion type, display scenario) pair is neither scalable nor convenient. Building a unified model trained on all the data with conversion type and display scenario included as two features is not accurate enough. In this paper, we propose the Masked Multi-domain Network (MMN) to solve this problem. To achieve the accuracy requirement, we model domain-specific parameters and propose a dynamically weighted loss to account for the loss scale imbalance issue within each mini-batch. To achieve the scalability requirement, we propose a parameter sharing and composition strategy to reduce model parameters from a product space to a sum space. To achieve the convenience requirement, we propose an auto-masking strategy which can take mixed data from all the domains as input. It avoids the overhead caused by data partitioning, individual processing and separate storage. Both offline and online experimental results validate the superiority of MMN for multi-type and multi-scenario CVR prediction. MMN is now the serving model for real-time CVR prediction in UC Toutiao.
Identifiable Latent Neural Causal Models
Mar 23, 2024Causal representation learning seeks to uncover latent, high-level causal representations from low-level observed data. It is particularly good at predictions under unseen distribution shifts, because these shifts can generally be interpreted as consequences of interventions. Hence leveraging {seen} distribution shifts becomes a natural strategy to help identifying causal representations, which in turn benefits predictions where distributions are previously {unseen}. Determining the types (or conditions) of such distribution shifts that do contribute to the identifiability of causal representations is critical. This work establishes a {sufficient} and {necessary} condition characterizing the types of distribution shifts for identifiability in the context of latent additive noise models. Furthermore, we present partial identifiability results when only a portion of distribution shifts meets the condition. In addition, we extend our findings to latent post-nonlinear causal models. We translate our findings into a practical algorithm, allowing for the acquisition of reliable latent causal representations. Our algorithm, guided by our underlying theory, has demonstrated outstanding performance across a diverse range of synthetic and real-world datasets. The empirical observations align closely with the theoretical findings, affirming the robustness and effectiveness of our approach.
Local Causal Discovery with Linear non-Gaussian Cyclic Models
Mar 21, 2024Local causal discovery is of great practical significance, as there are often situations where the discovery of the global causal structure is unnecessary, and the interest lies solely on a single target variable. Most existing local methods utilize conditional independence relations, providing only a partially directed graph, and assume acyclicity for the ground-truth structure, even though real-world scenarios often involve cycles like feedback mechanisms. In this work, we present a general, unified local causal discovery method with linear non-Gaussian models, whether they are cyclic or acyclic. We extend the application of independent component analysis from the global context to independent subspace analysis, enabling the exact identification of the equivalent local directed structures and causal strengths from the Markov blanket of the target variable. We also propose an alternative regression-based method in the particular acyclic scenarios. Our identifiability results are empirically validated using both synthetic and real-world datasets.
Gene Regulatory Network Inference in the Presence of Dropouts: a Causal View
Mar 21, 2024Gene regulatory network inference (GRNI) is a challenging problem, particularly owing to the presence of zeros in single-cell RNA sequencing data: some are biological zeros representing no gene expression, while some others are technical zeros arising from the sequencing procedure (aka dropouts), which may bias GRNI by distorting the joint distribution of the measured gene expressions. Existing approaches typically handle dropout error via imputation, which may introduce spurious relations as the true joint distribution is generally unidentifiable. To tackle this issue, we introduce a causal graphical model to characterize the dropout mechanism, namely, Causal Dropout Model. We provide a simple yet effective theoretical result: interestingly, the conditional independence (CI) relations in the data with dropouts, after deleting the samples with zero values (regardless if technical or not) for the conditioned variables, are asymptotically identical to the CI relations in the original data without dropouts. This particular test-wise deletion procedure, in which we perform CI tests on the samples without zeros for the conditioned variables, can be seamlessly integrated with existing structure learning approaches including constraint-based and greedy score-based methods, thus giving rise to a principled framework for GRNI in the presence of dropouts. We further show that the causal dropout model can be validated from data, and many existing statistical models to handle dropouts fit into our model as specific parametric instances. Empirical evaluation on synthetic, curated, and real-world experimental transcriptomic data comprehensively demonstrate the efficacy of our method.
Steering LLMs Towards Unbiased Responses: A Causality-Guided Debiasing Framework
Mar 13, 2024


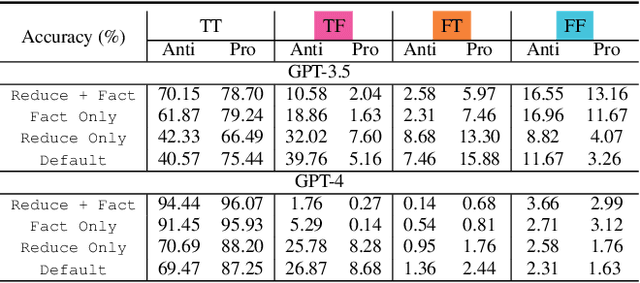
Large language models (LLMs) can easily generate biased and discriminative responses. As LLMs tap into consequential decision-making (e.g., hiring and healthcare), it is of crucial importance to develop strategies to mitigate these biases. This paper focuses on social bias, tackling the association between demographic information and LLM outputs. We propose a causality-guided debiasing framework that utilizes causal understandings of (1) the data-generating process of the training corpus fed to LLMs, and (2) the internal reasoning process of LLM inference, to guide the design of prompts for debiasing LLM outputs through selection mechanisms. Our framework unifies existing de-biasing prompting approaches such as inhibitive instructions and in-context contrastive examples, and sheds light on new ways of debiasing by encouraging bias-free reasoning. Our strong empirical performance on real-world datasets demonstrates that our framework provides principled guidelines on debiasing LLM outputs even with only the black-box access.
Confidence Matters: Revisiting Intrinsic Self-Correction Capabilities of Large Language Models
Feb 27, 2024The recent success of Large Language Models (LLMs) has catalyzed an increasing interest in their self-correction capabilities. This paper presents a comprehensive investigation into the intrinsic self-correction of LLMs, attempting to address the ongoing debate about its feasibility. Our research has identified an important latent factor - the "confidence" of LLMs - during the self-correction process. Overlooking this factor may cause the models to over-criticize themselves, resulting in unreliable conclusions regarding the efficacy of self-correction. We have experimentally observed that LLMs possess the capability to understand the "confidence" in their own responses. It motivates us to develop an "If-or-Else" (IoE) prompting framework, designed to guide LLMs in assessing their own "confidence", facilitating intrinsic self-corrections. We conduct extensive experiments and demonstrate that our IoE-based Prompt can achieve a consistent improvement regarding the accuracy of self-corrected responses over the initial answers. Our study not only sheds light on the underlying factors affecting self-correction in LLMs, but also introduces a practical framework that utilizes the IoE prompting principle to efficiently improve self-correction capabilities with "confidence". The code is available at https://github.com/MBZUAI-CLeaR/IoE-Prompting.git.
Federated Causal Discovery from Heterogeneous Data
Feb 27, 2024Conventional causal discovery methods rely on centralized data, which is inconsistent with the decentralized nature of data in many real-world situations. This discrepancy has motivated the development of federated causal discovery (FCD) approaches. However, existing FCD methods may be limited by their potentially restrictive assumptions of identifiable functional causal models or homogeneous data distributions, narrowing their applicability in diverse scenarios. In this paper, we propose a novel FCD method attempting to accommodate arbitrary causal models and heterogeneous data. We first utilize a surrogate variable corresponding to the client index to account for the data heterogeneity across different clients. We then develop a federated conditional independence test (FCIT) for causal skeleton discovery and establish a federated independent change principle (FICP) to determine causal directions. These approaches involve constructing summary statistics as a proxy of the raw data to protect data privacy. Owing to the nonparametric properties, FCIT and FICP make no assumption about particular functional forms, thereby facilitating the handling of arbitrary causal models. We conduct extensive experiments on synthetic and real datasets to show the efficacy of our method. The code is available at https://github.com/lokali/FedCDH.git.
Counterfactual Generation with Identifiability Guarantees
Feb 23, 2024Counterfactual generation lies at the core of various machine learning tasks, including image translation and controllable text generation. This generation process usually requires the identification of the disentangled latent representations, such as content and style, that underlie the observed data. However, it becomes more challenging when faced with a scarcity of paired data and labeling information. Existing disentangled methods crucially rely on oversimplified assumptions, such as assuming independent content and style variables, to identify the latent variables, even though such assumptions may not hold for complex data distributions. For instance, food reviews tend to involve words like tasty, whereas movie reviews commonly contain words such as thrilling for the same positive sentiment. This problem is exacerbated when data are sampled from multiple domains since the dependence between content and style may vary significantly over domains. In this work, we tackle the domain-varying dependence between the content and the style variables inherent in the counterfactual generation task. We provide identification guarantees for such latent-variable models by leveraging the relative sparsity of the influences from different latent variables. Our theoretical insights enable the development of a doMain AdapTive counTerfactual gEneration model, called (MATTE). Our theoretically grounded framework achieves state-of-the-art performance in unsupervised style transfer tasks, where neither paired data nor style labels are utilized, across four large-scale datasets. Code is available at https://github.com/hanqi-qi/Matte.git
When and How: Learning Identifiable Latent States for Nonstationary Time Series Forecasting
Feb 20, 2024Temporal distribution shifts are ubiquitous in time series data. One of the most popular methods assumes that the temporal distribution shift occurs uniformly to disentangle the stationary and nonstationary dependencies. But this assumption is difficult to meet, as we do not know when the distribution shifts occur. To solve this problem, we propose to learn IDentifiable latEnt stAtes (IDEA) to detect when the distribution shifts occur. Beyond that, we further disentangle the stationary and nonstationary latent states via sufficient observation assumption to learn how the latent states change. Specifically, we formalize the causal process with environment-irrelated stationary and environment-related nonstationary variables. Under mild conditions, we show that latent environments and stationary/nonstationary variables are identifiable. Based on these theories, we devise the IDEA model, which incorporates an autoregressive hidden Markov model to estimate latent environments and modular prior networks to identify latent states. The IDEA model outperforms several latest nonstationary forecasting methods on various benchmark datasets, highlighting its advantages in real-world scenarios.