 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuhang Liu
Identifiable Latent Neural Causal Models
Mar 23, 2024
Causal representation learning seeks to uncover latent, high-level causal representations from low-level observed data. It is particularly good at predictions under unseen distribution shifts, because these shifts can generally be interpreted as consequences of interventions. Hence leveraging {seen} distribution shifts becomes a natural strategy to help identifying causal representations, which in turn benefits predictions where distributions are previously {unseen}. Determining the types (or conditions) of such distribution shifts that do contribute to the identifiability of causal representations is critical. This work establishes a {sufficient} and {necessary} condition characterizing the types of distribution shifts for identifiability in the context of latent additive noise models. Furthermore, we present partial identifiability results when only a portion of distribution shifts meets the condition. In addition, we extend our findings to latent post-nonlinear causal models. We translate our findings into a practical algorithm, allowing for the acquisition of reliable latent causal representations. Our algorithm, guided by our underlying theory, has demonstrated outstanding performance across a diverse range of synthetic and real-world datasets. The empirical observations align closely with the theoretical findings, affirming the robustness and effectiveness of our approach.
Revealing Multimodal Contrastive Representation Learning through Latent Partial Causal Models
Feb 09, 2024Multimodal contrastive representation learning methods have proven successful across a range of domains, partly due to their ability to generate meaningful shared representations of complex phenomena. To enhance the depth of analysis and understanding of these acquired representations, we introduce a unified causal model specifically designed for multimodal data. By examining this model, we show that multimodal contrastive representation learning excels at identifying latent coupled variables within the proposed unified model, up to linear or permutation transformations resulting from different assumptions. Our findings illuminate the potential of pre-trained multimodal models, eg, CLIP, in learning disentangled representations through a surprisingly simple yet highly effective tool: linear independent component analysis. Experiments demonstrate the robustness of our findings, even when the assumptions are violated, and validate the effectiveness of the proposed method in learning disentangled representations.
Detection-based Intermediate Supervision for Visual Question Answering
Dec 26, 2023Recently, neural module networks (NMNs) have yielded ongoing success in answering compositional visual questions, especially those involving multi-hop visual and logical reasoning. NMNs decompose the complex question into several sub-tasks using instance-modules from the reasoning paths of that question and then exploit intermediate supervisions to guide answer prediction, thereby improving inference interpretability. However, their performance may be hindered due to sketchy modeling of intermediate supervisions. For instance, (1) a prior assumption that each instance-module refers to only one grounded object yet overlooks other potentially associated grounded objects, impeding full cross-modal alignment learning; (2) IoU-based intermediate supervisions may introduce noise signals as the bounding box overlap issue might guide the model's focus towards irrelevant objects. To address these issues, a novel method, \textbf{\underline{D}}etection-based \textbf{\underline{I}}ntermediate \textbf{\underline{S}}upervision (DIS), is proposed, which adopts a generative detection framework to facilitate multiple grounding supervisions via sequence generation. As such, DIS offers more comprehensive and accurate intermediate supervisions, thereby boosting answer prediction performance. Furthermore, by considering intermediate results, DIS enhances the consistency in answering compositional questions and their sub-questions.Extensive experiments demonstrate the superiority of our proposed DIS, showcasing both improved accuracy and state-of-the-art reasoning consistency compared to prior approaches.
CLAP: Contrastive Learning with Augmented Prompts for Robustness on Pretrained Vision-Language Models
Nov 28, 2023Contrastive vision-language models, e.g., CLIP, have garnered substantial attention for their exceptional generalization capabilities. However, their robustness to perturbations has ignited concerns. Existing strategies typically reinforce their resilience against adversarial examples by enabling the image encoder to "see" these perturbed examples, often necessitating a complete retraining of the image encoder on both natural and adversarial samples. In this study, we propose a new method to enhance robustness solely through text augmentation, eliminating the need for retraining the image encoder on adversarial examples. Our motivation arises from the realization that text and image data inherently occupy a shared latent space, comprising latent content variables and style variables. This insight suggests the feasibility of learning to disentangle these latent content variables using text data exclusively. To accomplish this, we introduce an effective text augmentation method that focuses on modifying the style while preserving the content in the text data. By changing the style part of the text data, we empower the text encoder to emphasize latent content variables, ultimately enhancing the robustness of vision-language models. Our experiments across various datasets demonstrate substantial improvements in the robustness of the pre-trained CLIP model.
MindLLM: Pre-training Lightweight Large Language Model from Scratch, Evaluations and Domain Applications
Oct 29, 2023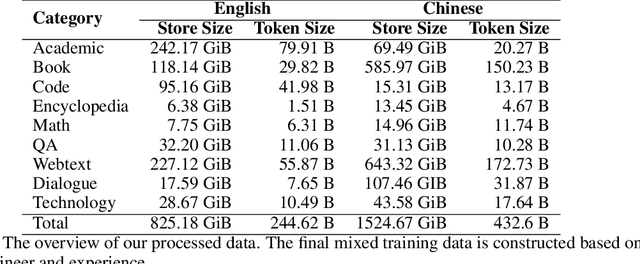
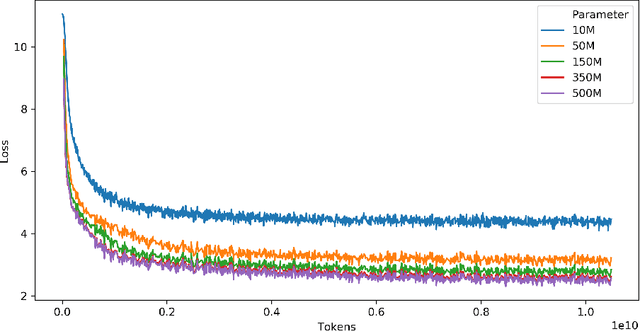
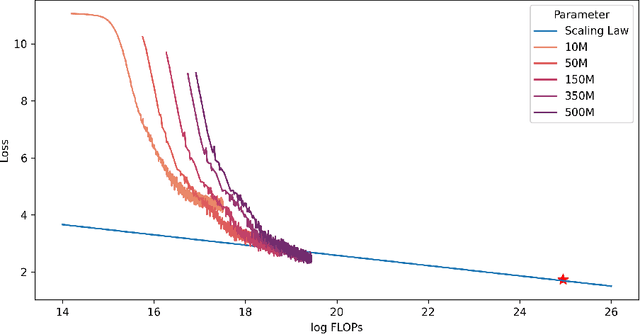

Large Language Models (LLMs) have demonstrated remarkable performance across various natural language tasks, marking significant strides towards general artificial intelligence. While general artificial intelligence is leveraged by developing increasingly large-scale models, there could be another branch to develop lightweight custom models that better serve certain domains, taking into account the high cost of training and deploying LLMs and the scarcity of resources. In this paper, we present MindLLM, a novel series of bilingual lightweight large language models, trained from scratch, alleviating such burdens by offering models with 1.3 billion and 3 billion parameters. A thorough account of experiences accrued during large model development is given, covering every step of the process, including data construction, model architecture, evaluation, and applications. Such insights are hopefully valuable for fellow academics and developers. MindLLM consistently matches or surpasses the performance of other open-source larger models on some public benchmarks. We also introduce an innovative instruction tuning framework tailored for smaller models to enhance their capabilities efficiently. Moreover, we explore the application of MindLLM in specific vertical domains such as law and finance, underscoring the agility and adaptability of our lightweight models.
Identifiable Latent Polynomial Causal Models Through the Lens of Change
Oct 24, 2023
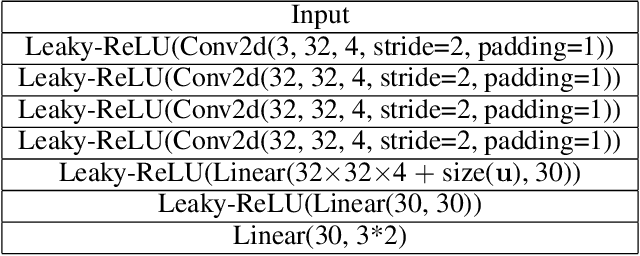
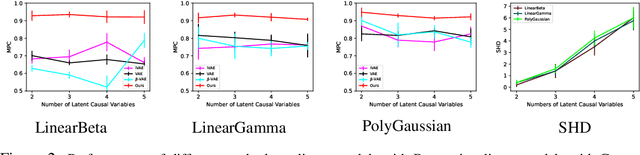
Causal representation learning aims to unveil latent high-level causal representations from observed low-level data. One of its primary tasks is to provide reliable assurance of identifying these latent causal models, known as identifiability. A recent breakthrough explores identifiability by leveraging the change of causal influences among latent causal variables across multiple environments \citep{liu2022identifying}. However, this progress rests on the assumption that the causal relationships among latent causal variables adhere strictly to linear Gaussian models. In this paper, we extend the scope of latent causal models to involve nonlinear causal relationships, represented by polynomial models, and general noise distributions conforming to the exponential family. Additionally, we investigate the necessity of imposing changes on all causal parameters and present partial identifiability results when part of them remains unchanged. Further, we propose a novel empirical estimation method, grounded in our theoretical finding, that enables learning consistent latent causal representations. Our experimental results, obtained from both synthetic and real-world data, validate our theoretical contributions concerning identifiability and consistency.
HPL-ViT: A Unified Perception Framework for Heterogeneous Parallel LiDARs in V2V
Sep 27, 2023

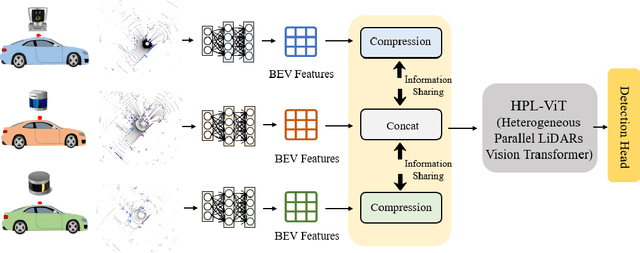
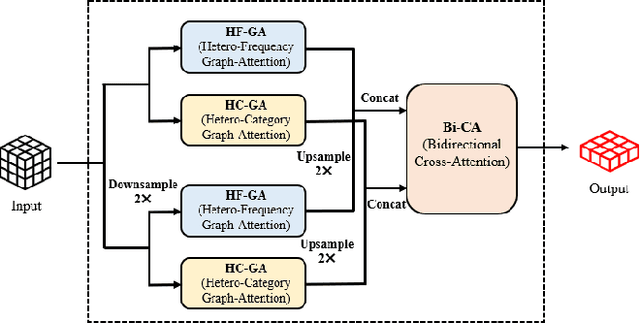
To develop the next generation of intelligent LiDARs, we propose a novel framework of parallel LiDARs and construct a hardware prototype in our experimental platform, DAWN (Digital Artificial World for Natural). It emphasizes the tight integration of physical and digital space in LiDAR systems, with networking being one of its supported core features. In the context of autonomous driving, V2V (Vehicle-to-Vehicle) technology enables efficient information sharing between different agents which significantly promotes the development of LiDAR networks. However, current research operates under an ideal situation where all vehicles are equipped with identical LiDAR, ignoring the diversity of LiDAR categories and operating frequencies. In this paper, we first utilize OpenCDA and RLS (Realistic LiDAR Simulation) to construct a novel heterogeneous LiDAR dataset named OPV2V-HPL. Additionally, we present HPL-ViT, a pioneering architecture designed for robust feature fusion in heterogeneous and dynamic scenarios. It uses a graph-attention Transformer to extract domain-specific features for each agent, coupled with a cross-attention mechanism for the final fusion. Extensive experiments on OPV2V-HPL demonstrate that HPL-ViT achieves SOTA (state-of-the-art) performance in all settings and exhibits outstanding generalization capabilities.
Topology-Preserving Automatic Labeling of Coronary Arteries via Anatomy-aware Connection Classifier
Jul 22, 2023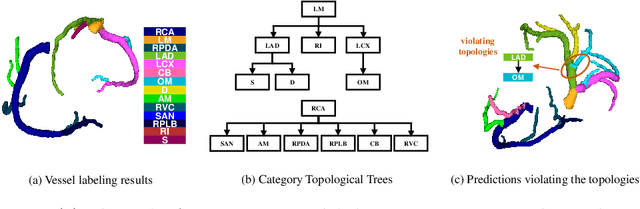
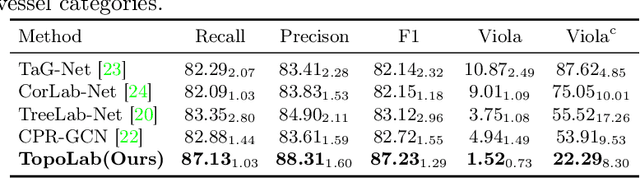
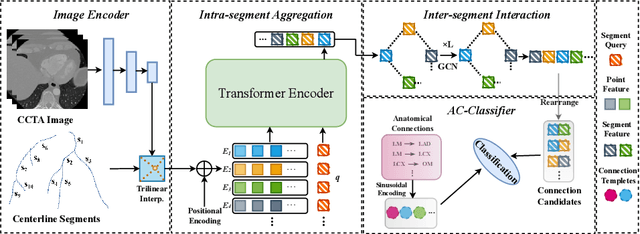
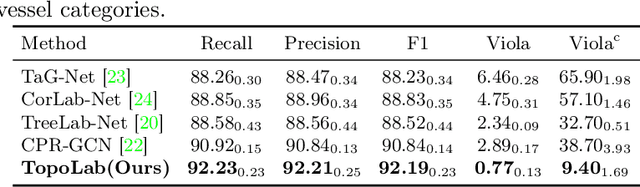
Automatic labeling of coronary arteries is an essential task in the practical diagnosis process of cardiovascular diseases. For experienced radiologists, the anatomically predetermined connections are important for labeling the artery segments accurately, while this prior knowledge is barely explored in previous studies. In this paper, we present a new framework called TopoLab which incorporates the anatomical connections into the network design explicitly. Specifically, the strategies of intra-segment feature aggregation and inter-segment feature interaction are introduced for hierarchical segment feature extraction. Moreover, we propose the anatomy-aware connection classifier to enable classification for each connected segment pair, which effectively exploits the prior topology among the arteries with different categories. To validate the effectiveness of our method, we contribute high-quality annotations of artery labeling to the public orCaScore dataset. The experimental results on both the orCaScore dataset and an in-house dataset show that our TopoLab has achieved state-of-the-art performance.
PointScatter: Point Set Representation for Tubular Structure Extraction
Sep 13, 2022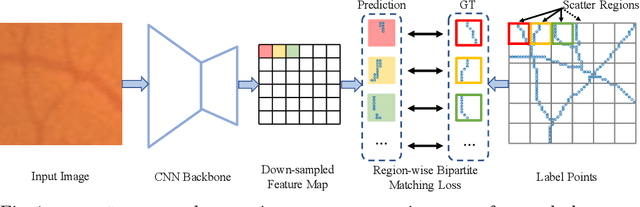
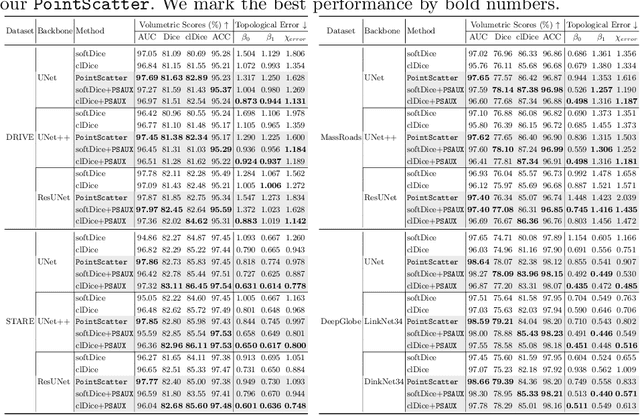
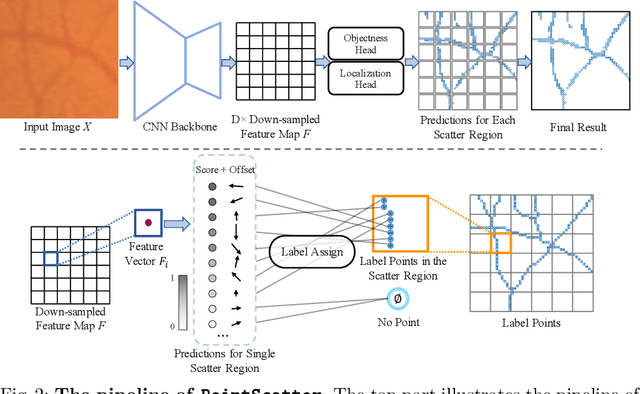
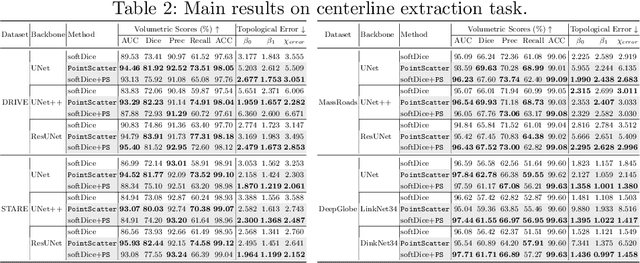
This paper explores the point set representation for tubular structure extraction tasks. Compared with the traditional mask representation, the point set representation enjoys its flexibility and representation ability, which would not be restricted by the fixed grid as the mask. Inspired by this, we propose PointScatter, an alternative to the segmentation models for the tubular structure extraction task. PointScatter splits the image into scatter regions and parallelly predicts points for each scatter region. We further propose the greedy-based region-wise bipartite matching algorithm to train the network end-to-end and efficiently. We benchmark the PointScatter on four public tubular datasets, and the extensive experiments on tubular structure segmentation and centerline extraction task demonstrate the effectiveness of our approach. Code is available at https://github.com/zhangzhao2022/pointscatter.