 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Wei
A Comprehensive Survey on Self-Supervised Learning for Recommendation
Apr 07, 2024
Recommender systems play a crucial role in tackling the challenge of information overload by delivering personalized recommendations based on individual user preferences. Deep learning techniques, such as RNNs, GNNs, and Transformer architectures, have significantly propelled the advancement of recommender systems by enhancing their comprehension of user behaviors and preferences. However, supervised learning methods encounter challenges in real-life scenarios due to data sparsity, resulting in limitations in their ability to learn representations effectively. To address this, self-supervised learning (SSL) techniques have emerged as a solution, leveraging inherent data structures to generate supervision signals without relying solely on labeled data. By leveraging unlabeled data and extracting meaningful representations, recommender systems utilizing SSL can make accurate predictions and recommendations even when confronted with data sparsity. In this paper, we provide a comprehensive review of self-supervised learning frameworks designed for recommender systems, encompassing a thorough analysis of over 170 papers. We conduct an exploration of nine distinct scenarios, enabling a comprehensive understanding of SSL-enhanced recommenders in different contexts. For each domain, we elaborate on different self-supervised learning paradigms, namely contrastive learning, generative learning, and adversarial learning, so as to present technical details of how SSL enhances recommender systems in various contexts. We consistently maintain the related open-source materials at https://github.com/HKUDS/Awesome-SSLRec-Papers.
AdaptSFL: Adaptive Split Federated Learning in Resource-constrained Edge Networks
Mar 19, 2024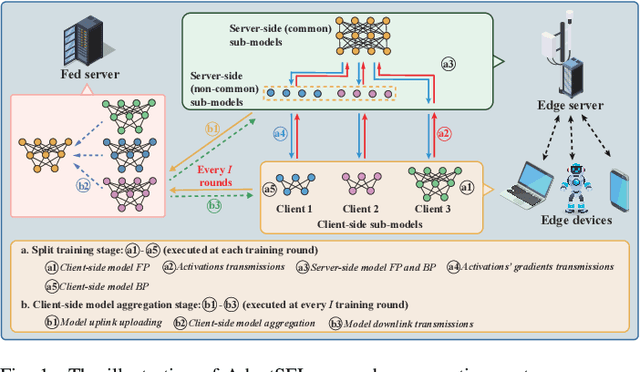
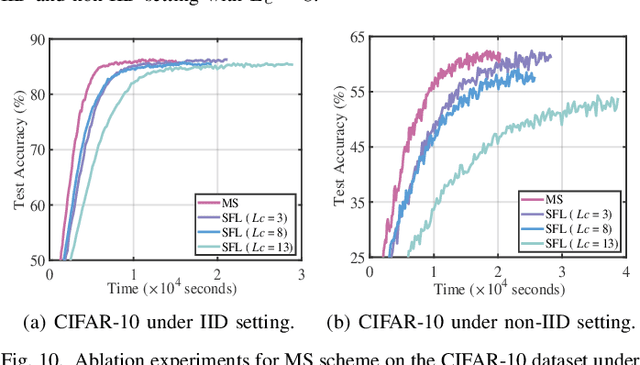
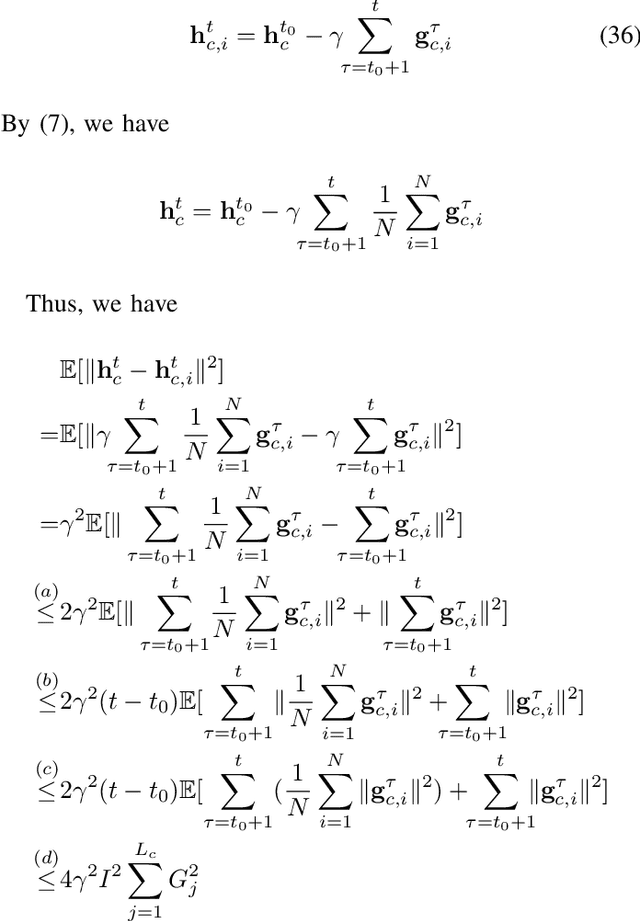
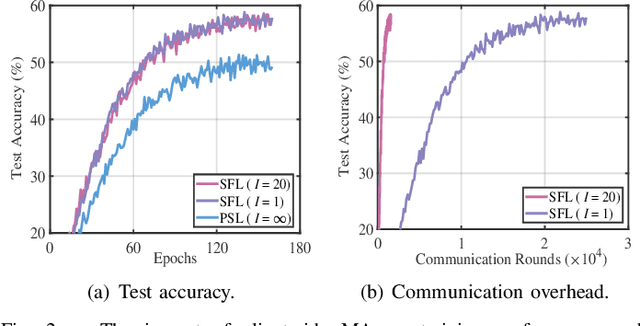
The increasing complexity of deep neural networks poses significant barriers to democratizing them to resource-limited edge devices. To address this challenge, split federated learning (SFL) has emerged as a promising solution by of floading the primary training workload to a server via model partitioning while enabling parallel training among edge devices. However, although system optimization substantially influences the performance of SFL under resource-constrained systems, the problem remains largely uncharted. In this paper, we provide a convergence analysis of SFL which quantifies the impact of model splitting (MS) and client-side model aggregation (MA) on the learning performance, serving as a theoretical foundation. Then, we propose AdaptSFL, a novel resource-adaptive SFL framework, to expedite SFL under resource-constrained edge computing systems. Specifically, AdaptSFL adaptively controls client-side MA and MS to balance communication-computing latency and training convergence. Extensive simulations across various datasets validate that our proposed AdaptSFL framework takes considerably less time to achieve a target accuracy than benchmarks, demonstrating the effectiveness of the proposed strategies.
Reinforcement Learning with Token-level Feedback for Controllable Text Generation
Mar 18, 2024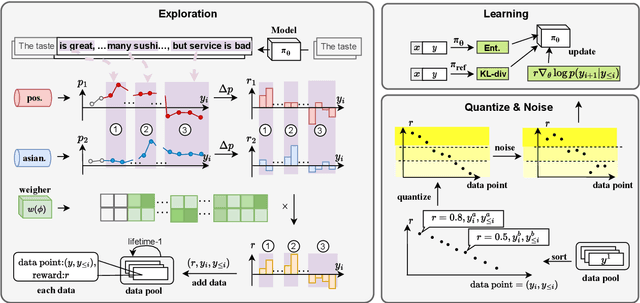
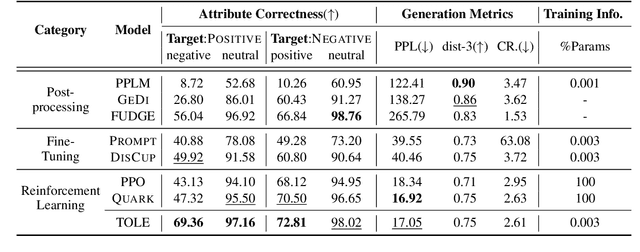
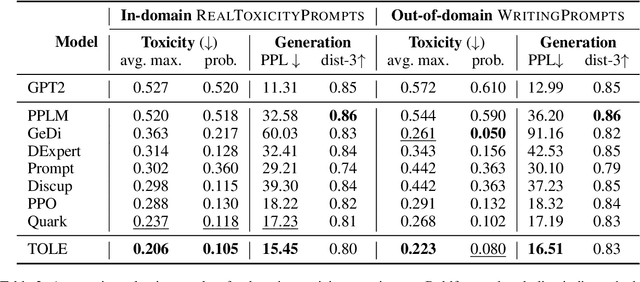
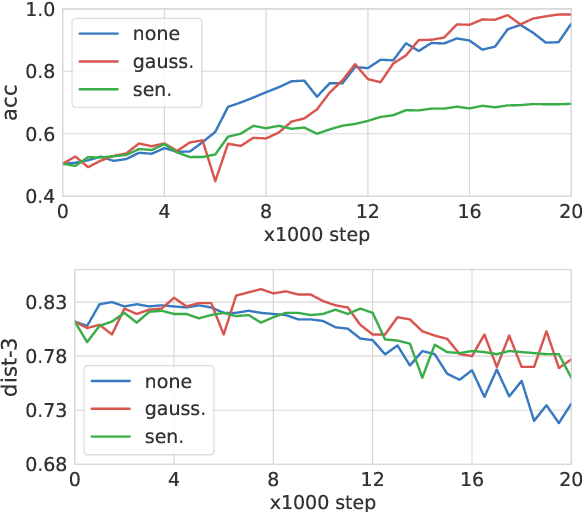
To meet the requirements of real-world applications, it is essential to control generations of large language models (LLMs). Prior research has tried to introduce reinforcement learning (RL) into controllable text generation while most existing methods suffer from overfitting issues (finetuning-based methods) or semantic collapse (post-processing methods). However, current RL methods are generally guided by coarse-grained (sentence/paragraph-level) feedback, which may lead to suboptimal performance owing to semantic twists or progressions within sentences. To tackle that, we propose a novel reinforcement learning algorithm named TOLE which formulates TOken-LEvel rewards for controllable text generation, and employs a "first-quantize-then-noise" paradigm to enhance the robustness of the RL algorithm.Furthermore, TOLE can be flexibly extended to multiple constraints with little computational expense. Experimental results show that our algorithm can achieve superior performance on both single-attribute and multi-attribute control tasks. We have released our codes at https://github.com/WindyLee0822/CTG
PromptMM: Multi-Modal Knowledge Distillation for Recommendation with Prompt-Tuning
Mar 10, 2024Multimedia online platforms (e.g., Amazon, TikTok) have greatly benefited from the incorporation of multimedia (e.g., visual, textual, and acoustic) content into their personal recommender systems. These modalities provide intuitive semantics that facilitate modality-aware user preference modeling. However, two key challenges in multi-modal recommenders remain unresolved: i) The introduction of multi-modal encoders with a large number of additional parameters causes overfitting, given high-dimensional multi-modal features provided by extractors (e.g., ViT, BERT). ii) Side information inevitably introduces inaccuracies and redundancies, which skew the modality-interaction dependency from reflecting true user preference. To tackle these problems, we propose to simplify and empower recommenders through Multi-modal Knowledge Distillation (PromptMM) with the prompt-tuning that enables adaptive quality distillation. Specifically, PromptMM conducts model compression through distilling u-i edge relationship and multi-modal node content from cumbersome teachers to relieve students from the additional feature reduction parameters. To bridge the semantic gap between multi-modal context and collaborative signals for empowering the overfitting teacher, soft prompt-tuning is introduced to perform student task-adaptive. Additionally, to adjust the impact of inaccuracies in multimedia data, a disentangled multi-modal list-wise distillation is developed with modality-aware re-weighting mechanism. Experiments on real-world data demonstrate PromptMM's superiority over existing techniques. Ablation tests confirm the effectiveness of key components. Additional tests show the efficiency and effectiveness.
GraphEdit: Large Language Models for Graph Structure Learning
Mar 05, 2024Graph Structure Learning (GSL) focuses on capturing intrinsic dependencies and interactions among nodes in graph-structured data by generating novel graph structures. Graph Neural Networks (GNNs) have emerged as promising GSL solutions, utilizing recursive message passing to encode node-wise inter-dependencies. However, many existing GSL methods heavily depend on explicit graph structural information as supervision signals, leaving them susceptible to challenges such as data noise and sparsity. In this work, we propose GraphEdit, an approach that leverages large language models (LLMs) to learn complex node relationships in graph-structured data. By enhancing the reasoning capabilities of LLMs through instruction-tuning over graph structures, we aim to overcome the limitations associated with explicit graph structural information and enhance the reliability of graph structure learning. Our approach not only effectively denoises noisy connections but also identifies node-wise dependencies from a global perspective, providing a comprehensive understanding of the graph structure. We conduct extensive experiments on multiple benchmark datasets to demonstrate the effectiveness and robustness of GraphEdit across various settings. We have made our model implementation available at: https://github.com/HKUDS/GraphEdit.
HiGPT: Heterogeneous Graph Language Model
Feb 25, 2024Heterogeneous graph learning aims to capture complex relationships and diverse relational semantics among entities in a heterogeneous graph to obtain meaningful representations for nodes and edges. Recent advancements in heterogeneous graph neural networks (HGNNs) have achieved state-of-the-art performance by considering relation heterogeneity and using specialized message functions and aggregation rules. However, existing frameworks for heterogeneous graph learning have limitations in generalizing across diverse heterogeneous graph datasets. Most of these frameworks follow the "pre-train" and "fine-tune" paradigm on the same dataset, which restricts their capacity to adapt to new and unseen data. This raises the question: "Can we generalize heterogeneous graph models to be well-adapted to diverse downstream learning tasks with distribution shifts in both node token sets and relation type heterogeneity?'' To tackle those challenges, we propose HiGPT, a general large graph model with Heterogeneous graph instruction-tuning paradigm. Our framework enables learning from arbitrary heterogeneous graphs without the need for any fine-tuning process from downstream datasets. To handle distribution shifts in heterogeneity, we introduce an in-context heterogeneous graph tokenizer that captures semantic relationships in different heterogeneous graphs, facilitating model adaptation. We incorporate a large corpus of heterogeneity-aware graph instructions into our HiGPT, enabling the model to effectively comprehend complex relation heterogeneity and distinguish between various types of graph tokens. Furthermore, we introduce the Mixture-of-Thought (MoT) instruction augmentation paradigm to mitigate data scarcity by generating diverse and informative instructions. Through comprehensive evaluations, our proposed framework demonstrates exceptional performance in terms of generalization performance.
PRDP: Proximal Reward Difference Prediction for Large-Scale Reward Finetuning of Diffusion Models
Feb 13, 2024Reward finetuning has emerged as a promising approach to aligning foundation models with downstream objectives. Remarkable success has been achieved in the language domain by using reinforcement learning (RL) to maximize rewards that reflect human preference. However, in the vision domain, existing RL-based reward finetuning methods are limited by their instability in large-scale training, rendering them incapable of generalizing to complex, unseen prompts. In this paper, we propose Proximal Reward Difference Prediction (PRDP), enabling stable black-box reward finetuning for diffusion models for the first time on large-scale prompt datasets with over 100K prompts. Our key innovation is the Reward Difference Prediction (RDP) objective that has the same optimal solution as the RL objective while enjoying better training stability. Specifically, the RDP objective is a supervised regression objective that tasks the diffusion model with predicting the reward difference of generated image pairs from their denoising trajectories. We theoretically prove that the diffusion model that obtains perfect reward difference prediction is exactly the maximizer of the RL objective. We further develop an online algorithm with proximal updates to stably optimize the RDP objective. In experiments, we demonstrate that PRDP can match the reward maximization ability of well-established RL-based methods in small-scale training. Furthermore, through large-scale training on text prompts from the Human Preference Dataset v2 and the Pick-a-Pic v1 dataset, PRDP achieves superior generation quality on a diverse set of complex, unseen prompts whereas RL-based methods completely fail.