 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLianghao Xia
A Comprehensive Survey on Self-Supervised Learning for Recommendation
Apr 07, 2024
Recommender systems play a crucial role in tackling the challenge of information overload by delivering personalized recommendations based on individual user preferences. Deep learning techniques, such as RNNs, GNNs, and Transformer architectures, have significantly propelled the advancement of recommender systems by enhancing their comprehension of user behaviors and preferences. However, supervised learning methods encounter challenges in real-life scenarios due to data sparsity, resulting in limitations in their ability to learn representations effectively. To address this, self-supervised learning (SSL) techniques have emerged as a solution, leveraging inherent data structures to generate supervision signals without relying solely on labeled data. By leveraging unlabeled data and extracting meaningful representations, recommender systems utilizing SSL can make accurate predictions and recommendations even when confronted with data sparsity. In this paper, we provide a comprehensive review of self-supervised learning frameworks designed for recommender systems, encompassing a thorough analysis of over 170 papers. We conduct an exploration of nine distinct scenarios, enabling a comprehensive understanding of SSL-enhanced recommenders in different contexts. For each domain, we elaborate on different self-supervised learning paradigms, namely contrastive learning, generative learning, and adversarial learning, so as to present technical details of how SSL enhances recommender systems in various contexts. We consistently maintain the related open-source materials at https://github.com/HKUDS/Awesome-SSLRec-Papers.
Graph Augmentation for Recommendation
Mar 25, 2024Graph augmentation with contrastive learning has gained significant attention in the field of recommendation systems due to its ability to learn expressive user representations, even when labeled data is limited. However, directly applying existing GCL models to real-world recommendation environments poses challenges. There are two primary issues to address. Firstly, the lack of consideration for data noise in contrastive learning can result in noisy self-supervised signals, leading to degraded performance. Secondly, many existing GCL approaches rely on graph neural network (GNN) architectures, which can suffer from over-smoothing problems due to non-adaptive message passing. To address these challenges, we propose a principled framework called GraphAug. This framework introduces a robust data augmentor that generates denoised self-supervised signals, enhancing recommender systems. The GraphAug framework incorporates a graph information bottleneck (GIB)-regularized augmentation paradigm, which automatically distills informative self-supervision information and adaptively adjusts contrastive view generation. Through rigorous experimentation on real-world datasets, we thoroughly assessed the performance of our novel GraphAug model. The outcomes consistently unveil its superiority over existing baseline methods. The source code for our model is publicly available at: https://github.com/HKUDS/GraphAug.
* 13 pages and accepted by ICDE 2024
PromptMM: Multi-Modal Knowledge Distillation for Recommendation with Prompt-Tuning
Mar 10, 2024Multimedia online platforms (e.g., Amazon, TikTok) have greatly benefited from the incorporation of multimedia (e.g., visual, textual, and acoustic) content into their personal recommender systems. These modalities provide intuitive semantics that facilitate modality-aware user preference modeling. However, two key challenges in multi-modal recommenders remain unresolved: i) The introduction of multi-modal encoders with a large number of additional parameters causes overfitting, given high-dimensional multi-modal features provided by extractors (e.g., ViT, BERT). ii) Side information inevitably introduces inaccuracies and redundancies, which skew the modality-interaction dependency from reflecting true user preference. To tackle these problems, we propose to simplify and empower recommenders through Multi-modal Knowledge Distillation (PromptMM) with the prompt-tuning that enables adaptive quality distillation. Specifically, PromptMM conducts model compression through distilling u-i edge relationship and multi-modal node content from cumbersome teachers to relieve students from the additional feature reduction parameters. To bridge the semantic gap between multi-modal context and collaborative signals for empowering the overfitting teacher, soft prompt-tuning is introduced to perform student task-adaptive. Additionally, to adjust the impact of inaccuracies in multimedia data, a disentangled multi-modal list-wise distillation is developed with modality-aware re-weighting mechanism. Experiments on real-world data demonstrate PromptMM's superiority over existing techniques. Ablation tests confirm the effectiveness of key components. Additional tests show the efficiency and effectiveness.
GraphEdit: Large Language Models for Graph Structure Learning
Mar 05, 2024Graph Structure Learning (GSL) focuses on capturing intrinsic dependencies and interactions among nodes in graph-structured data by generating novel graph structures. Graph Neural Networks (GNNs) have emerged as promising GSL solutions, utilizing recursive message passing to encode node-wise inter-dependencies. However, many existing GSL methods heavily depend on explicit graph structural information as supervision signals, leaving them susceptible to challenges such as data noise and sparsity. In this work, we propose GraphEdit, an approach that leverages large language models (LLMs) to learn complex node relationships in graph-structured data. By enhancing the reasoning capabilities of LLMs through instruction-tuning over graph structures, we aim to overcome the limitations associated with explicit graph structural information and enhance the reliability of graph structure learning. Our approach not only effectively denoises noisy connections but also identifies node-wise dependencies from a global perspective, providing a comprehensive understanding of the graph structure. We conduct extensive experiments on multiple benchmark datasets to demonstrate the effectiveness and robustness of GraphEdit across various settings. We have made our model implementation available at: https://github.com/HKUDS/GraphEdit.
OpenGraph: Towards Open Graph Foundation Models
Mar 02, 2024
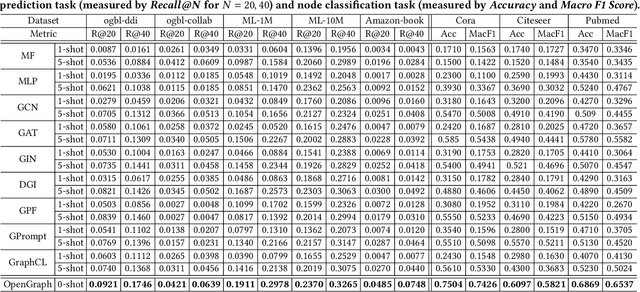
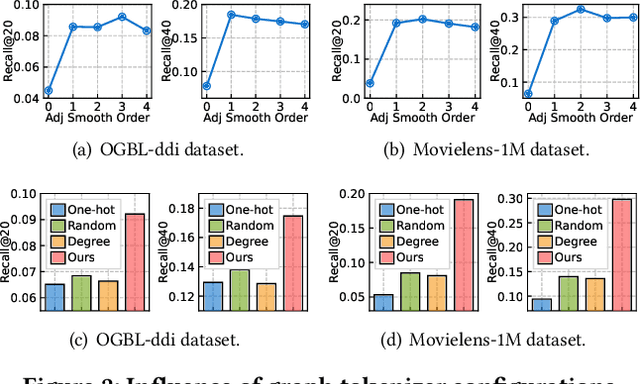
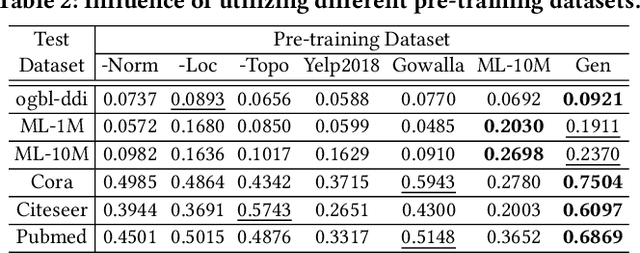
Graph learning has become indispensable for interpreting and harnessing relational data in diverse fields, ranging from recommendation systems to social network analysis. In this context, a variety of GNNs have emerged as promising methodologies for encoding the structural information of graphs. By effectively capturing the graph's underlying structure, these GNNs have shown great potential in enhancing performance in graph learning tasks, such as link prediction and node classification. However, despite their successes, a significant challenge persists: these advanced methods often face difficulties in generalizing to unseen graph data that significantly differs from the training instances. In this work, our aim is to advance the graph learning paradigm by developing a general graph foundation model. This model is designed to understand the complex topological patterns present in diverse graph data, enabling it to excel in zero-shot graph learning tasks across different downstream datasets. To achieve this goal, we address several key technical challenges in our OpenGraph model. Firstly, we propose a unified graph tokenizer to adapt our graph model to generalize well on unseen graph data, even when the underlying graph properties differ significantly from those encountered during training. Secondly, we develop a scalable graph transformer as the foundational encoder, which effectively captures node-wise dependencies within the global topological context. Thirdly, we introduce a data augmentation mechanism enhanced by a LLM to alleviate the limitations of data scarcity in real-world scenarios. Extensive experiments validate the effectiveness of our framework. By adapting our OpenGraph to new graph characteristics and comprehending the nuances of diverse graphs, our approach achieves remarkable zero-shot graph learning performance across various settings and domains.
UrbanGPT: Spatio-Temporal Large Language Models
Feb 25, 2024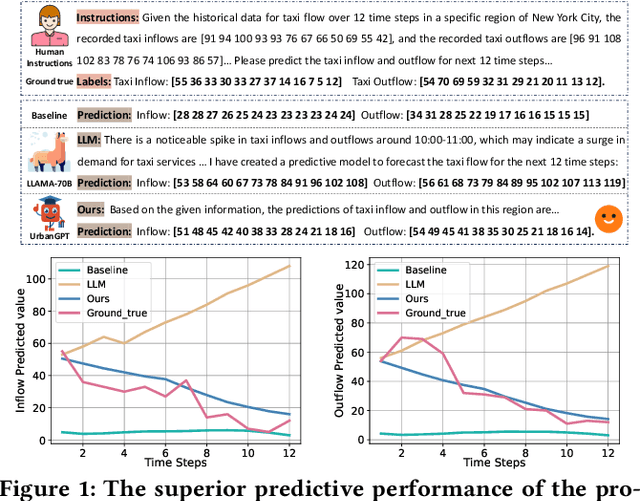
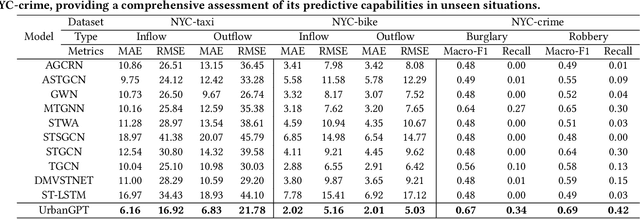
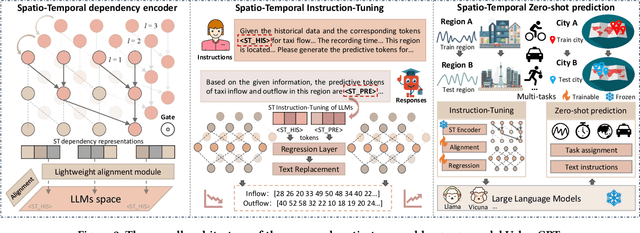
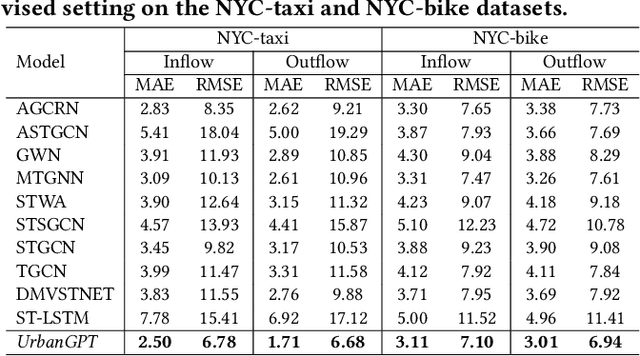
Spatio-temporal prediction aims to forecast and gain insights into the ever-changing dynamics of urban environments across both time and space. Its purpose is to anticipate future patterns, trends, and events in diverse facets of urban life, including transportation, population movement, and crime rates. Although numerous efforts have been dedicated to developing neural network techniques for accurate predictions on spatio-temporal data, it is important to note that many of these methods heavily depend on having sufficient labeled data to generate precise spatio-temporal representations. Unfortunately, the issue of data scarcity is pervasive in practical urban sensing scenarios. Consequently, it becomes necessary to build a spatio-temporal model with strong generalization capabilities across diverse spatio-temporal learning scenarios. Taking inspiration from the remarkable achievements of large language models (LLMs), our objective is to create a spatio-temporal LLM that can exhibit exceptional generalization capabilities across a wide range of downstream urban tasks. To achieve this objective, we present the UrbanGPT, which seamlessly integrates a spatio-temporal dependency encoder with the instruction-tuning paradigm. This integration enables LLMs to comprehend the complex inter-dependencies across time and space, facilitating more comprehensive and accurate predictions under data scarcity. To validate the effectiveness of our approach, we conduct extensive experiments on various public datasets, covering different spatio-temporal prediction tasks. The results consistently demonstrate that our UrbanGPT, with its carefully designed architecture, consistently outperforms state-of-the-art baselines. These findings highlight the potential of building large language models for spatio-temporal learning, particularly in zero-shot scenarios where labeled data is scarce.
DiffKG: Knowledge Graph Diffusion Model for Recommendation
Dec 28, 2023Knowledge Graphs (KGs) have emerged as invaluable resources for enriching recommendation systems by providing a wealth of factual information and capturing semantic relationships among items. Leveraging KGs can significantly enhance recommendation performance. However, not all relations within a KG are equally relevant or beneficial for the target recommendation task. In fact, certain item-entity connections may introduce noise or lack informative value, thus potentially misleading our understanding of user preferences. To bridge this research gap, we propose a novel knowledge graph diffusion model for recommendation, referred to as DiffKG. Our framework integrates a generative diffusion model with a data augmentation paradigm, enabling robust knowledge graph representation learning. This integration facilitates a better alignment between knowledge-aware item semantics and collaborative relation modeling. Moreover, we introduce a collaborative knowledge graph convolution mechanism that incorporates collaborative signals reflecting user-item interaction patterns, guiding the knowledge graph diffusion process. We conduct extensive experiments on three publicly available datasets, consistently demonstrating the superiority of our DiffKG compared to various competitive baselines. We provide the source code repository of our proposed DiffKG model at the following link: https://github.com/HKUDS/DiffKG.
Graph Pre-training and Prompt Learning for Recommendation
Nov 28, 2023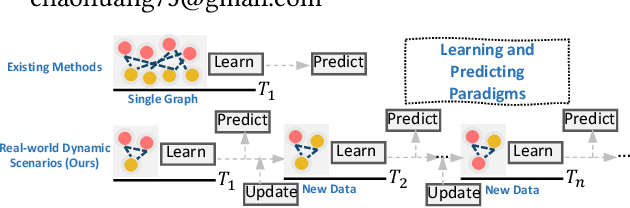
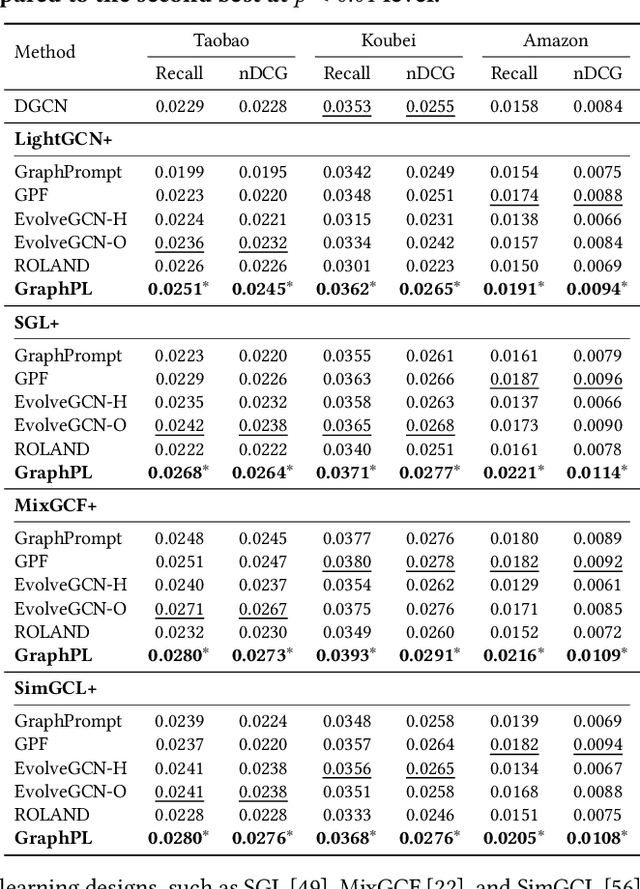
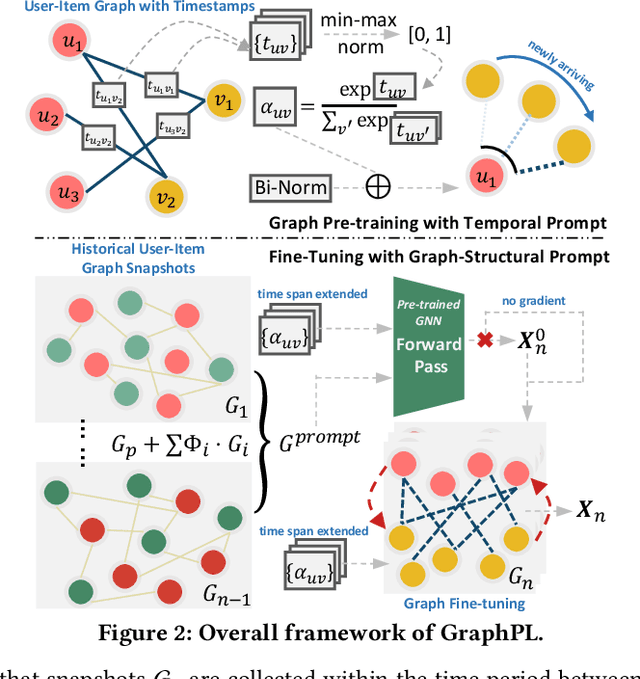
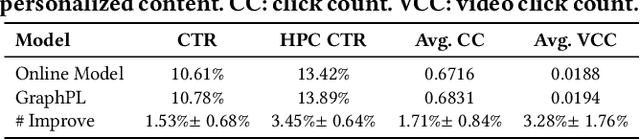
GNN-based recommenders have excelled in modeling intricate user-item interactions through multi-hop message passing. However, existing methods often overlook the dynamic nature of evolving user-item interactions, which impedes the adaption to changing user preferences and distribution shifts in newly arriving data. Thus, their scalability and performances in real-world dynamic environments are limited. In this study, we propose GraphPL, a framework that incorporates parameter-efficient and dynamic graph pre-training with prompt learning. This novel combination empowers GNNs to effectively capture both long-term user preferences and short-term behavior dynamics, enabling the delivery of accurate and timely recommendations. Our GraphPL framework addresses the challenge of evolving user preferences by seamlessly integrating a temporal prompt mechanism and a graph-structural prompt learning mechanism into the pre-trained GNN model. The temporal prompt mechanism encodes time information on user-item interaction, allowing the model to naturally capture temporal context, while the graph-structural prompt learning mechanism enables the transfer of pre-trained knowledge to adapt to behavior dynamics without the need for continuous incremental training. We further bring in a dynamic evaluation setting for recommendation to mimic real-world dynamic scenarios and bridge the offline-online gap to a better level. Our extensive experiments including a large-scale industrial deployment showcases the lightweight plug-in scalability of our GraphPL when integrated with various state-of-the-art recommenders, emphasizing the advantages of GraphPL in terms of effectiveness, robustness and efficiency.
GPT-ST: Generative Pre-Training of Spatio-Temporal Graph Neural Networks
Nov 07, 2023



In recent years, there has been a rapid development of spatio-temporal prediction techniques in response to the increasing demands of traffic management and travel planning. While advanced end-to-end models have achieved notable success in improving predictive performance, their integration and expansion pose significant challenges. This work aims to address these challenges by introducing a spatio-temporal pre-training framework that seamlessly integrates with downstream baselines and enhances their performance. The framework is built upon two key designs: (i) We propose a spatio-temporal mask autoencoder as a pre-training model for learning spatio-temporal dependencies. The model incorporates customized parameter learners and hierarchical spatial pattern encoding networks. These modules are specifically designed to capture spatio-temporal customized representations and intra- and inter-cluster region semantic relationships, which have often been neglected in existing approaches. (ii) We introduce an adaptive mask strategy as part of the pre-training mechanism. This strategy guides the mask autoencoder in learning robust spatio-temporal representations and facilitates the modeling of different relationships, ranging from intra-cluster to inter-cluster, in an easy-to-hard training manner. Extensive experiments conducted on representative benchmarks demonstrate the effectiveness of our proposed method. We have made our model implementation publicly available at https://github.com/HKUDS/GPT-ST.
* This paper has been accepted by NeurIPS 2023
Explainable Spatio-Temporal Graph Neural Networks
Oct 26, 2023



Spatio-temporal graph neural networks (STGNNs) have gained popularity as a powerful tool for effectively modeling spatio-temporal dependencies in diverse real-world urban applications, including intelligent transportation and public safety. However, the black-box nature of STGNNs limits their interpretability, hindering their application in scenarios related to urban resource allocation and policy formulation. To bridge this gap, we propose an Explainable Spatio-Temporal Graph Neural Networks (STExplainer) framework that enhances STGNNs with inherent explainability, enabling them to provide accurate predictions and faithful explanations simultaneously. Our framework integrates a unified spatio-temporal graph attention network with a positional information fusion layer as the STG encoder and decoder, respectively. Furthermore, we propose a structure distillation approach based on the Graph Information Bottleneck (GIB) principle with an explainable objective, which is instantiated by the STG encoder and decoder. Through extensive experiments, we demonstrate that our STExplainer outperforms state-of-the-art baselines in terms of predictive accuracy and explainability metrics (i.e., sparsity and fidelity) on traffic and crime prediction tasks. Furthermore, our model exhibits superior representation ability in alleviating data missing and sparsity issues. The implementation code is available at: https://github.com/HKUDS/STExplainer.