 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXubin Ren
A Comprehensive Survey on Self-Supervised Learning for Recommendation
Apr 07, 2024
Recommender systems play a crucial role in tackling the challenge of information overload by delivering personalized recommendations based on individual user preferences. Deep learning techniques, such as RNNs, GNNs, and Transformer architectures, have significantly propelled the advancement of recommender systems by enhancing their comprehension of user behaviors and preferences. However, supervised learning methods encounter challenges in real-life scenarios due to data sparsity, resulting in limitations in their ability to learn representations effectively. To address this, self-supervised learning (SSL) techniques have emerged as a solution, leveraging inherent data structures to generate supervision signals without relying solely on labeled data. By leveraging unlabeled data and extracting meaningful representations, recommender systems utilizing SSL can make accurate predictions and recommendations even when confronted with data sparsity. In this paper, we provide a comprehensive review of self-supervised learning frameworks designed for recommender systems, encompassing a thorough analysis of over 170 papers. We conduct an exploration of nine distinct scenarios, enabling a comprehensive understanding of SSL-enhanced recommenders in different contexts. For each domain, we elaborate on different self-supervised learning paradigms, namely contrastive learning, generative learning, and adversarial learning, so as to present technical details of how SSL enhances recommender systems in various contexts. We consistently maintain the related open-source materials at https://github.com/HKUDS/Awesome-SSLRec-Papers.
LLMRec: Large Language Models with Graph Augmentation for Recommendation
Nov 17, 2023



The problem of data sparsity has long been a challenge in recommendation systems, and previous studies have attempted to address this issue by incorporating side information. However, this approach often introduces side effects such as noise, availability issues, and low data quality, which in turn hinder the accurate modeling of user preferences and adversely impact recommendation performance. In light of the recent advancements in large language models (LLMs), which possess extensive knowledge bases and strong reasoning capabilities, we propose a novel framework called LLMRec that enhances recommender systems by employing three simple yet effective LLM-based graph augmentation strategies. Our approach leverages the rich content available within online platforms (e.g., Netflix, MovieLens) to augment the interaction graph in three ways: (i) reinforcing user-item interaction egde, (ii) enhancing the understanding of item node attributes, and (iii) conducting user node profiling, intuitively from the natural language perspective. By employing these strategies, we address the challenges posed by sparse implicit feedback and low-quality side information in recommenders. Besides, to ensure the quality of the augmentation, we develop a denoised data robustification mechanism that includes techniques of noisy implicit feedback pruning and MAE-based feature enhancement that help refine the augmented data and improve its reliability. Furthermore, we provide theoretical analysis to support the effectiveness of LLMRec and clarify the benefits of our method in facilitating model optimization. Experimental results on benchmark datasets demonstrate the superiority of our LLM-based augmentation approach over state-of-the-art techniques. To ensure reproducibility, we have made our code and augmented data publicly available at: https://github.com/HKUDS/LLMRec.git
Representation Learning with Large Language Models for Recommendation
Oct 24, 2023



Recommender systems have seen significant advancements with the influence of deep learning and graph neural networks, particularly in capturing complex user-item relationships. However, these graph-based recommenders heavily depend on ID-based data, potentially disregarding valuable textual information associated with users and items, resulting in less informative learned representations. Moreover, the utilization of implicit feedback data introduces potential noise and bias, posing challenges for the effectiveness of user preference learning. While the integration of large language models (LLMs) into traditional ID-based recommenders has gained attention, challenges such as scalability issues, limitations in text-only reliance, and prompt input constraints need to be addressed for effective implementation in practical recommender systems. To address these challenges, we propose a model-agnostic framework RLMRec that aims to enhance existing recommenders with LLM-empowered representation learning. It proposes a recommendation paradigm that integrates representation learning with LLMs to capture intricate semantic aspects of user behaviors and preferences. RLMRec incorporates auxiliary textual signals, develops a user/item profiling paradigm empowered by LLMs, and aligns the semantic space of LLMs with the representation space of collaborative relational signals through a cross-view alignment framework. This work further establish a theoretical foundation demonstrating that incorporating textual signals through mutual information maximization enhances the quality of representations. In our evaluation, we integrate RLMRec with state-of-the-art recommender models, while also analyzing its efficiency and robustness to noise data. Our implementation codes are available at https://github.com/HKUDS/RLMRec.
How Expressive are Graph Neural Networks in Recommendation?
Sep 05, 2023



Graph Neural Networks (GNNs) have demonstrated superior performance on various graph learning tasks, including recommendation, where they leverage user-item collaborative filtering signals in graphs. However, theoretical formulations of their capability are scarce, despite their empirical effectiveness in state-of-the-art recommender models. Recently, research has explored the expressiveness of GNNs in general, demonstrating that message passing GNNs are at most as powerful as the Weisfeiler-Lehman test, and that GNNs combined with random node initialization are universal. Nevertheless, the concept of "expressiveness" for GNNs remains vaguely defined. Most existing works adopt the graph isomorphism test as the metric of expressiveness, but this graph-level task may not effectively assess a model's ability in recommendation, where the objective is to distinguish nodes of different closeness. In this paper, we provide a comprehensive theoretical analysis of the expressiveness of GNNs in recommendation, considering three levels of expressiveness metrics: graph isomorphism (graph-level), node automorphism (node-level), and topological closeness (link-level). We propose the topological closeness metric to evaluate GNNs' ability to capture the structural distance between nodes, which aligns closely with the objective of recommendation. To validate the effectiveness of this new metric in evaluating recommendation performance, we introduce a learning-less GNN algorithm that is optimal on the new metric and can be optimal on the node-level metric with suitable modification. We conduct extensive experiments comparing the proposed algorithm against various types of state-of-the-art GNN models to explore the explainability of the new metric in the recommendation task. For reproducibility, implementation codes are available at https://github.com/HKUDS/GTE.
SSLRec: A Self-Supervised Learning Library for Recommendation
Aug 10, 2023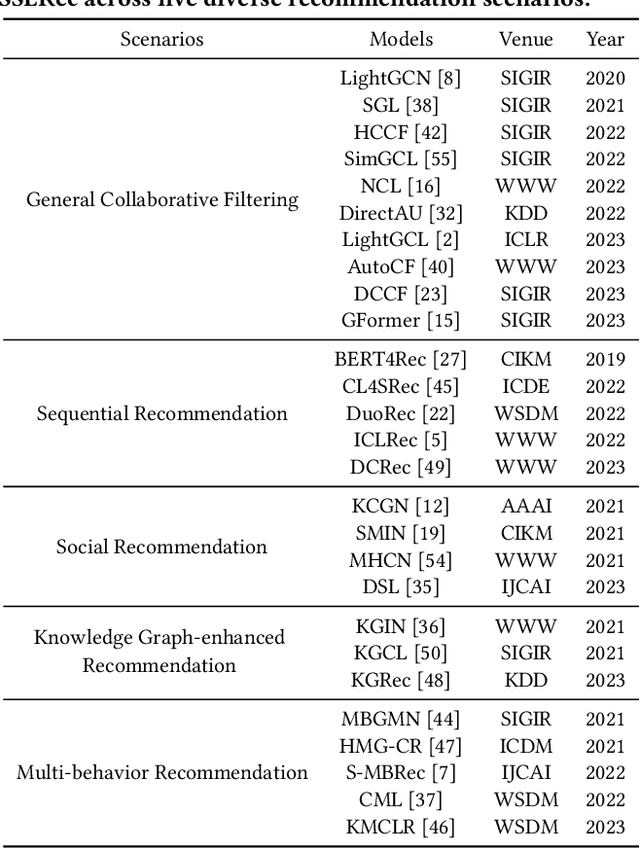
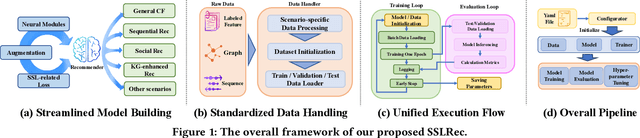
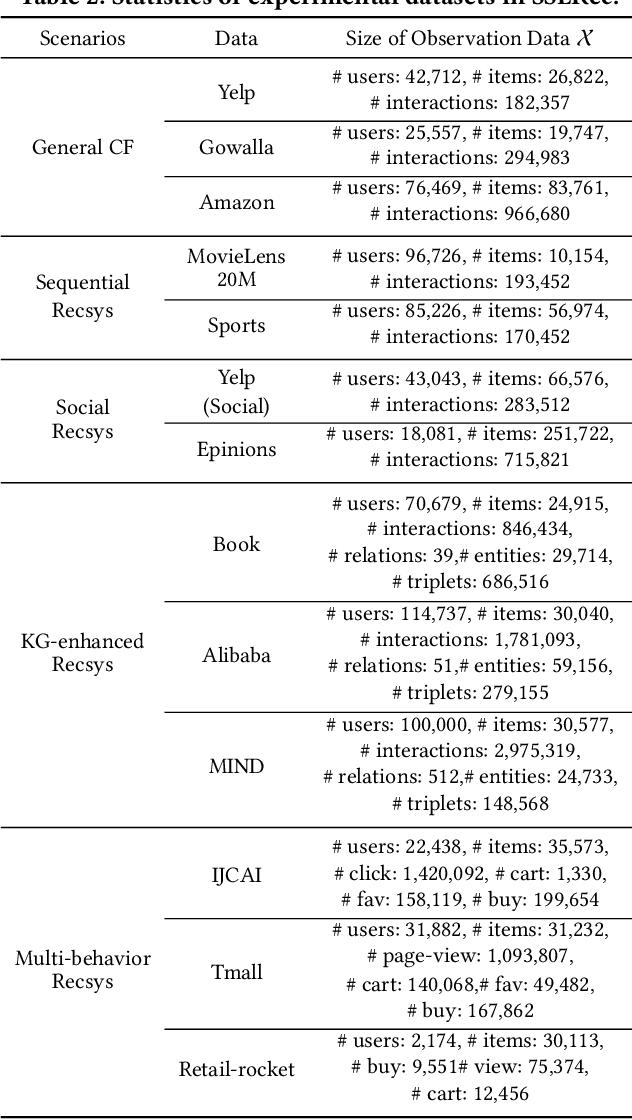
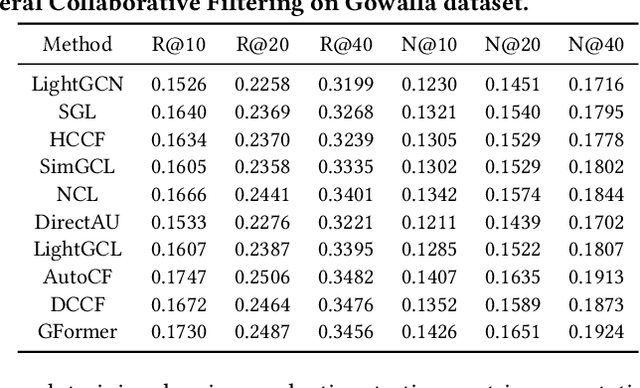
Self-supervised learning (SSL) has gained significant interest in recent years as a solution to address the challenges posed by sparse and noisy data in recommender systems. Despite the growing number of SSL algorithms designed to provide state-of-the-art performance in various recommendation scenarios (e.g., graph collaborative filtering, sequential recommendation, social recommendation, KG-enhanced recommendation), there is still a lack of unified frameworks that integrate recommendation algorithms across different domains. Such a framework could serve as the cornerstone for self-supervised recommendation algorithms, unifying the validation of existing methods and driving the design of new ones. To address this gap, we introduce SSLRec, a novel benchmark platform that provides a standardized, flexible, and comprehensive framework for evaluating various SSL-enhanced recommenders. The SSLRec library features a modular architecture that allows users to easily evaluate state-of-the-art models and a complete set of data augmentation and self-supervised toolkits to help create SSL recommendation models with specific needs. Furthermore, SSLRec simplifies the process of training and evaluating different recommendation models with consistent and fair settings. Our SSLRec platform covers a comprehensive set of state-of-the-art SSL-enhanced recommendation models across different scenarios, enabling researchers to evaluate these cutting-edge models and drive further innovation in the field. Our implemented SSLRec framework is available at the source code repository https://github.com/HKUDS/SSLRec.
Graph Transformer for Recommendation
Jun 04, 2023



This paper presents a novel approach to representation learning in recommender systems by integrating generative self-supervised learning with graph transformer architecture. We highlight the importance of high-quality data augmentation with relevant self-supervised pretext tasks for improving performance. Towards this end, we propose a new approach that automates the self-supervision augmentation process through a rationale-aware generative SSL that distills informative user-item interaction patterns. The proposed recommender with Graph TransFormer (GFormer) that offers parameterized collaborative rationale discovery for selective augmentation while preserving global-aware user-item relationships. In GFormer, we allow the rationale-aware SSL to inspire graph collaborative filtering with task-adaptive invariant rationalization in graph transformer. The experimental results reveal that our GFormer has the capability to consistently improve the performance over baselines on different datasets. Several in-depth experiments further investigate the invariant rationale-aware augmentation from various aspects. The source code for this work is publicly available at: https://github.com/HKUDS/GFormer.
Disentangled Contrastive Collaborative Filtering
May 07, 2023



Recent studies show that graph neural networks (GNNs) are prevalent to model high-order relationships for collaborative filtering (CF). Towards this research line, graph contrastive learning (GCL) has exhibited powerful performance in addressing the supervision label shortage issue by learning augmented user and item representations. While many of them show their effectiveness, two key questions still remain unexplored: i) Most existing GCL-based CF models are still limited by ignoring the fact that user-item interaction behaviors are often driven by diverse latent intent factors (e.g., shopping for family party, preferred color or brand of products); ii) Their introduced non-adaptive augmentation techniques are vulnerable to noisy information, which raises concerns about the model's robustness and the risk of incorporating misleading self-supervised signals. In light of these limitations, we propose a Disentangled Contrastive Collaborative Filtering framework (DCCF) to realize intent disentanglement with self-supervised augmentation in an adaptive fashion. With the learned disentangled representations with global context, our DCCF is able to not only distill finer-grained latent factors from the entangled self-supervision signals but also alleviate the augmentation-induced noise. Finally, the cross-view contrastive learning task is introduced to enable adaptive augmentation with our parameterized interaction mask generator. Experiments on various public datasets demonstrate the superiority of our method compared to existing solutions. Our model implementation is released at the link https://github.com/HKUDS/DCCF.
LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation
Feb 17, 2023



Graph neural network (GNN) is a powerful learning approach for graph-based recommender systems. Recently, GNNs integrated with contrastive learning have shown superior performance in recommendation with their data augmentation schemes, aiming at dealing with highly sparse data. Despite their success, most existing graph contrastive learning methods either perform stochastic augmentation (e.g., node/edge perturbation) on the user-item interaction graph, or rely on the heuristic-based augmentation techniques (e.g., user clustering) for generating contrastive views. We argue that these methods cannot well preserve the intrinsic semantic structures and are easily biased by the noise perturbation. In this paper, we propose a simple yet effective graph contrastive learning paradigm LightGCL that mitigates these issues impairing the generality and robustness of CL-based recommenders. Our model exclusively utilizes singular value decomposition for contrastive augmentation, which enables the unconstrained structural refinement with global collaborative relation modeling. Experiments conducted on several benchmark datasets demonstrate the significant improvement in performance of our model over the state-of-the-arts. Further analyses demonstrate the superiority of LightGCL's robustness against data sparsity and popularity bias. The source code of our model is available at https://github.com/HKUDS/LightGCL.
Deep Deconfounded Content-based Tag Recommendation for UGC with Causal Intervention
May 28, 2022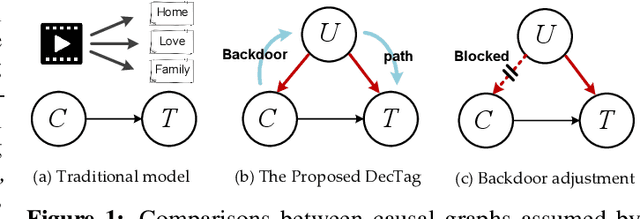


Traditional content-based tag recommender systems directly learn the association between user-generated content (UGC) and tags based on collected UGC-tag pairs. However, since a UGC uploader simultaneously creates the UGC and selects the corresponding tags, her personal preference inevitably biases the tag selections, which prevents these recommenders from learning the causal influence of UGCs' content features on tags. In this paper, we propose a deep deconfounded content-based tag recommender system, namely, DecTag, to address the above issues. We first establish a causal graph to represent the relations among uploader, UGC, and tag, where the uploaders are identified as confounders that spuriously correlate UGC and tag selections. Specifically, to eliminate the confounding bias, causal intervention is conducted on the UGC node in the graph via backdoor adjustment, where uploaders' influence on tags leaked through backdoor paths can be eliminated for causal effect estimation. Observing that adjusting the causal graph with do-calculus requires integrating the entire uploader space, which is infeasible, we design a novel Monte Carlo (MC)-based estimator with bootstrap, which can achieve asymptotic unbiasedness provided that uploaders for the collected UGCs are i.i.d. samples from the population. In addition, the MC estimator has the intuition of substituting the biased uploaders with a hypothetical random uploader from the population in the training phase, where deconfounding can be achieved in an interpretable manner. Finally, we establish a YT-8M-Causal dataset based on the widely used YouTube-8M dataset with causal intervention and propose an evaluation strategy accordingly to unbiasedly evaluate causal tag recommenders. Extensive experiments show that DecTag is more robust to confounding bias than state-of-the-art causal recommenders.
Multi-Auxiliary Augmented Collaborative Variational Auto-encoder for Tag Recommendation
Apr 20, 2022



Recommending appropriate tags to items can facilitate content organization, retrieval, consumption and other applications, where hybrid tag recommender systems have been utilized to integrate collaborative information and content information for better recommendations. In this paper, we propose a multi-auxiliary augmented collaborative variational auto-encoder (MA-CVAE) for tag recommendation, which couples item collaborative information and item multi-auxiliary information, i.e., content and social graph, by defining a generative process. Specifically, the model learns deep latent embeddings from different item auxiliary information using variational auto-encoders (VAE), which could form a generative distribution over each auxiliary information by introducing a latent variable parameterized by deep neural network. Moreover, to recommend tags for new items, item multi-auxiliary latent embeddings are utilized as a surrogate through the item decoder for predicting recommendation probabilities of each tag, where reconstruction losses are added in the training phase to constrict the generation for feedback predictions via different auxiliary embeddings. In addition, an inductive variational graph auto-encoder is designed where new item nodes could be inferred in the test phase, such that item social embeddings could be exploited for new items. Extensive experiments on MovieLens and citeulike datasets demonstrate the effectiveness of our method.