 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYaochen Zhu
Usable XAI: 10 Strategies Towards Exploiting Explainability in the LLM Era
Mar 13, 2024
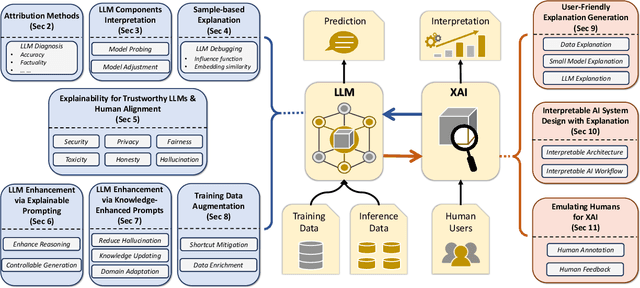

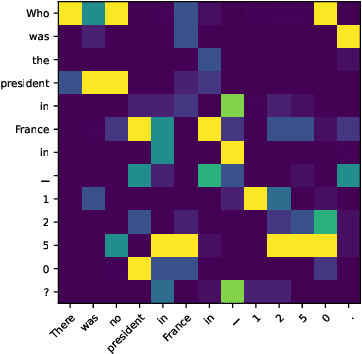
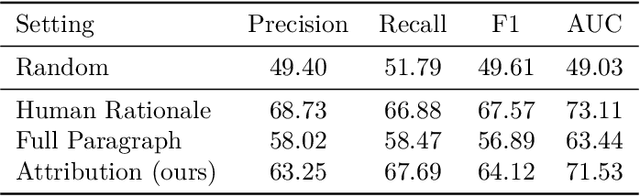
Explainable AI (XAI) refers to techniques that provide human-understandable insights into the workings of AI models. Recently, the focus of XAI is being extended towards Large Language Models (LLMs) which are often criticized for their lack of transparency. This extension calls for a significant transformation in XAI methodologies because of two reasons. First, many existing XAI methods cannot be directly applied to LLMs due to their complexity advanced capabilities. Second, as LLMs are increasingly deployed across diverse industry applications, the role of XAI shifts from merely opening the "black box" to actively enhancing the productivity and applicability of LLMs in real-world settings. Meanwhile, unlike traditional machine learning models that are passive recipients of XAI insights, the distinct abilities of LLMs can reciprocally enhance XAI. Therefore, in this paper, we introduce Usable XAI in the context of LLMs by analyzing (1) how XAI can benefit LLMs and AI systems, and (2) how LLMs can contribute to the advancement of XAI. We introduce 10 strategies, introducing the key techniques for each and discussing their associated challenges. We also provide case studies to demonstrate how to obtain and leverage explanations. The code used in this paper can be found at: https://github.com/JacksonWuxs/UsableXAI_LLM.
DPPA: Pruning Method for Large Language Model to Model Merging
Mar 05, 2024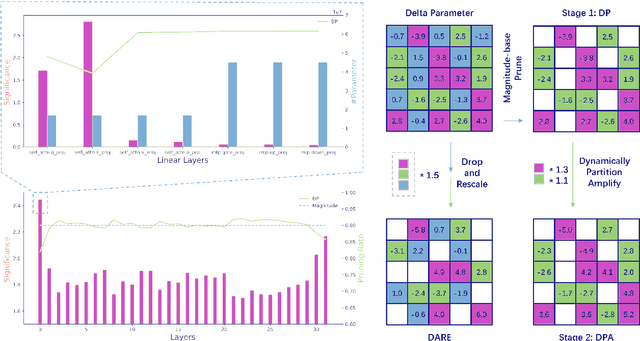
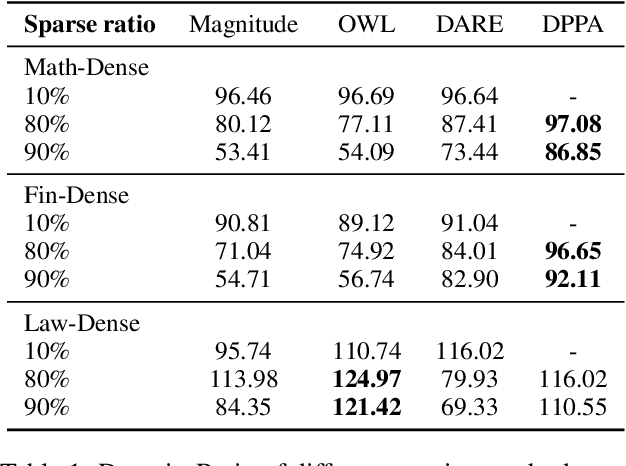
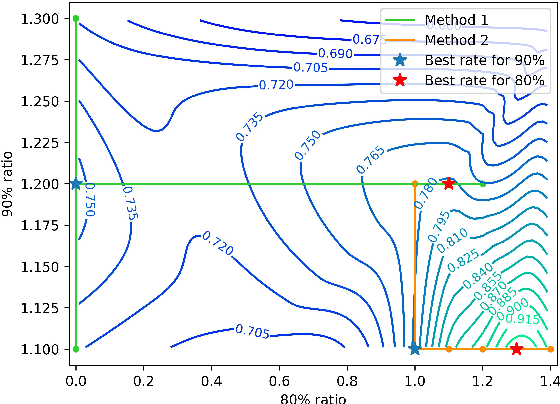
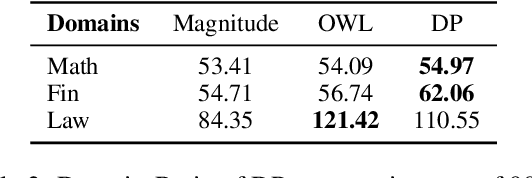
Model merging is to combine fine-tuned models derived from multiple domains, with the intent of enhancing the model's proficiency across various domains. The principal concern is the resolution of parameter conflicts. A substantial amount of existing research remedy this issue during the merging stage, with the latest study focusing on resolving this issue throughout the pruning stage. The DARE approach has exhibited promising outcomes when applied to a simplistic fine-tuned model. However, the efficacy of this method tends to wane when employed on complex fine-tuned models that show a significant parameter bias relative to the baseline model. In this paper, we introduce a dual-stage method termed Dynamic Pruning Partition Amplification (DPPA), devised to tackle the challenge of merging complex fine-tuned models. Initially, we introduce Dynamically Pruning (DP), an improved approach based on magnitude pruning, which aim is to enhance performance at higher pruning rates. Subsequently, we propose Dynamically Partition Amplification (DPA), a rescaling strategy, is designed to dynamically amplify parameter partitions in relation to their significance levels. The experimental results show that our method maintains a mere 20% of domain-specific parameters and yet delivers a performance comparable to other methodologies that preserve up to 90% of parameters. Furthermore, our method displays outstanding performance post-pruning, leading to a significant improvement of nearly 20% performance in model merging. We make our code on Github.
Collaborative Large Language Model for Recommender Systems
Nov 08, 2023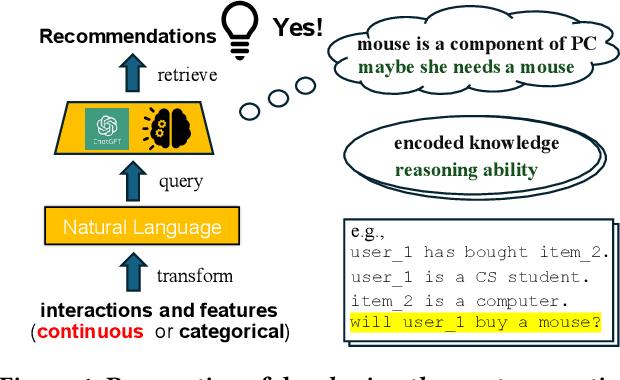
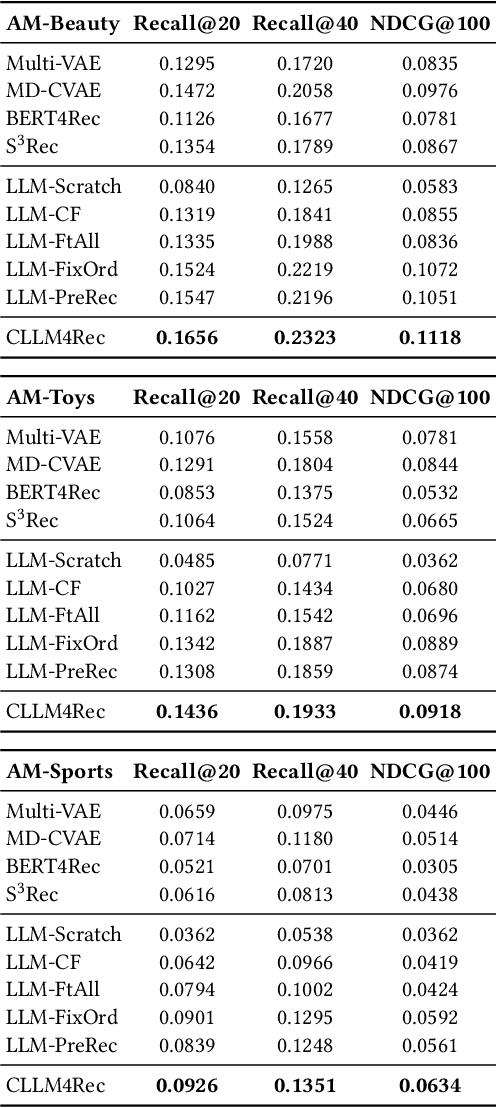

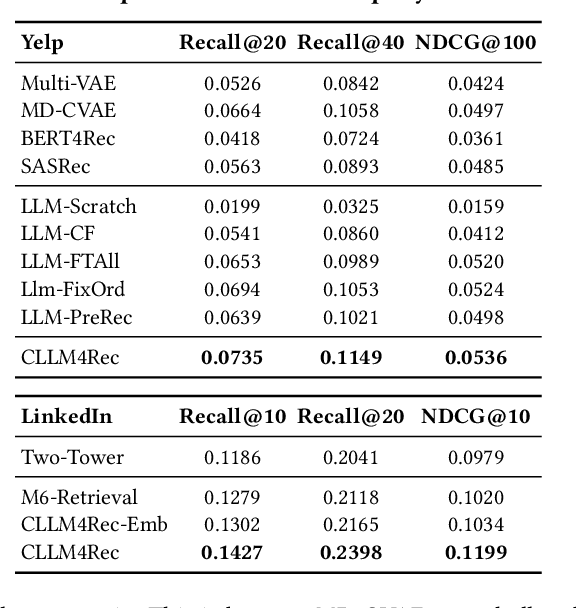
Recently, there is a growing interest in developing next-generation recommender systems (RSs) based on pretrained large language models (LLMs), fully utilizing their encoded knowledge and reasoning ability. However, the semantic gap between natural language and recommendation tasks is still not well addressed, leading to multiple issues such as spuriously-correlated user/item descriptors, ineffective language modeling on user/item contents, and inefficient recommendations via auto-regression, etc. In this paper, we propose CLLM4Rec, the first generative RS that tightly integrates the LLM paradigm and ID paradigm of RS, aiming to address the above challenges simultaneously. We first extend the vocabulary of pretrained LLMs with user/item ID tokens to faithfully model the user/item collaborative and content semantics. Accordingly, in the pretraining stage, a novel soft+hard prompting strategy is proposed to effectively learn user/item collaborative/content token embeddings via language modeling on RS-specific corpora established from user-item interactions and user/item features, where each document is split into a prompt consisting of heterogeneous soft (user/item) tokens and hard (vocab) tokens and a main text consisting of homogeneous item tokens or vocab tokens that facilitates stable and effective language modeling. In addition, a novel mutual regularization strategy is introduced to encourage the CLLM4Rec to capture recommendation-oriented information from user/item contents. Finally, we propose a novel recommendation-oriented finetuning strategy for CLLM4Rec, where an item prediction head with multinomial likelihood is added to the pretrained CLLM4Rec backbone to predict hold-out items based on the soft+hard prompts established from masked user-item interaction history, where recommendations of multiple items can be generated efficiently.
Knowledge Editing for Large Language Models: A Survey
Oct 26, 2023
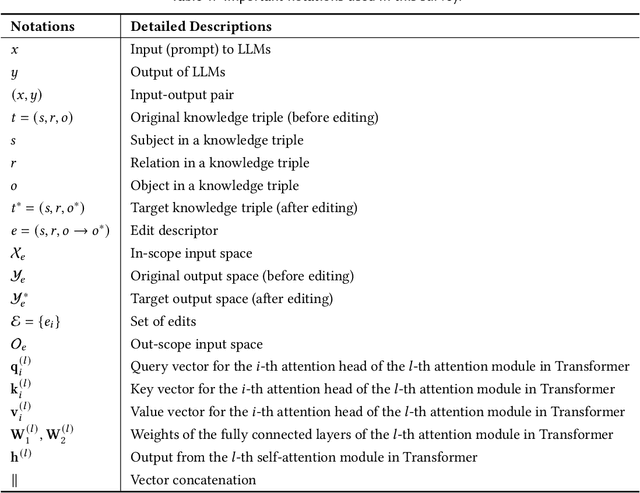
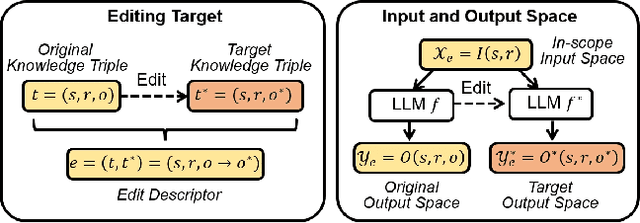

Large language models (LLMs) have recently transformed both the academic and industrial landscapes due to their remarkable capacity to understand, analyze, and generate texts based on their vast knowledge and reasoning ability. Nevertheless, one major drawback of LLMs is their substantial computational cost for pre-training due to their unprecedented amounts of parameters. The disadvantage is exacerbated when new knowledge frequently needs to be introduced into the pre-trained model. Therefore, it is imperative to develop effective and efficient techniques to update pre-trained LLMs. Traditional methods encode new knowledge in pre-trained LLMs through direct fine-tuning. However, naively re-training LLMs can be computationally intensive and risks degenerating valuable pre-trained knowledge irrelevant to the update in the model. Recently, Knowledge-based Model Editing (KME) has attracted increasing attention, which aims to precisely modify the LLMs to incorporate specific knowledge, without negatively influencing other irrelevant knowledge. In this survey, we aim to provide a comprehensive and in-depth overview of recent advances in the field of KME. We first introduce a general formulation of KME to encompass different KME strategies. Afterward, we provide an innovative taxonomy of KME techniques based on how the new knowledge is introduced into pre-trained LLMs, and investigate existing KME strategies while analyzing key insights, advantages, and limitations of methods from each category. Moreover, representative metrics, datasets, and applications of KME are introduced accordingly. Finally, we provide an in-depth analysis regarding the practicality and remaining challenges of KME and suggest promising research directions for further advancement in this field.
Path-Specific Counterfactual Fairness for Recommender Systems
Jun 05, 2023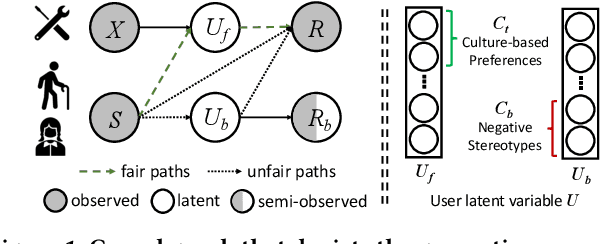
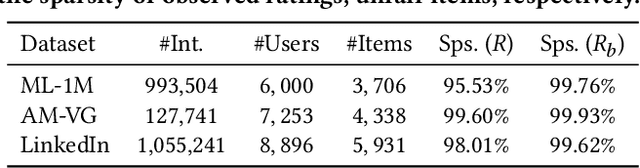
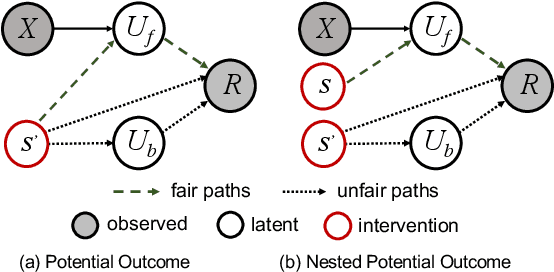
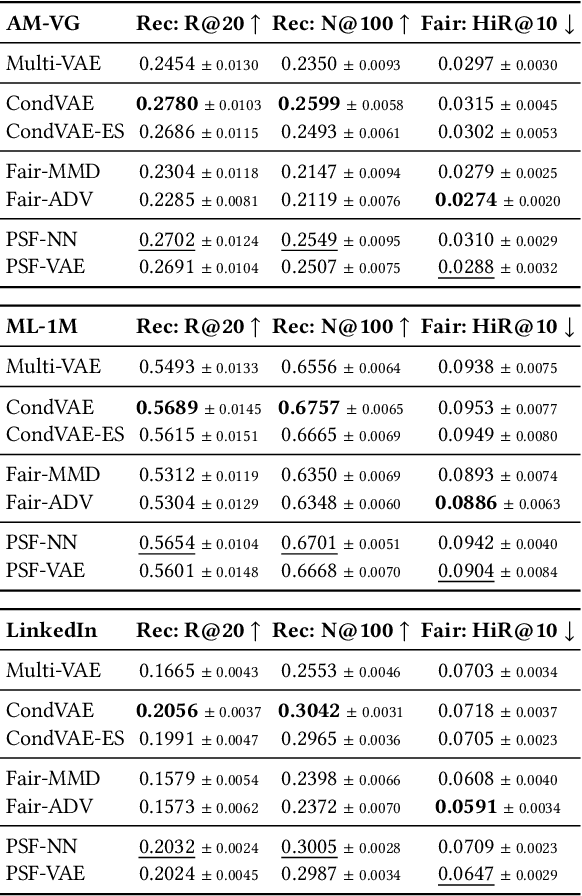
Recommender systems (RSs) have become an indispensable part of online platforms. With the growing concerns of algorithmic fairness, RSs are not only expected to deliver high-quality personalized content, but are also demanded not to discriminate against users based on their demographic information. However, existing RSs could capture undesirable correlations between sensitive features and observed user behaviors, leading to biased recommendations. Most fair RSs tackle this problem by completely blocking the influences of sensitive features on recommendations. But since sensitive features may also affect user interests in a fair manner (e.g., race on culture-based preferences), indiscriminately eliminating all the influences of sensitive features inevitably degenerate the recommendations quality and necessary diversities. To address this challenge, we propose a path-specific fair RS (PSF-RS) for recommendations. Specifically, we summarize all fair and unfair correlations between sensitive features and observed ratings into two latent proxy mediators, where the concept of path-specific bias (PS-Bias) is defined based on path-specific counterfactual inference. Inspired by Pearl's minimal change principle, we address the PS-Bias by minimally transforming the biased factual world into a hypothetically fair world, where a fair RS model can be learned accordingly by solving a constrained optimization problem. For the technical part, we propose a feasible implementation of PSF-RS, i.e., PSF-VAE, with weakly-supervised variational inference, which robustly infers the latent mediators such that unfairness can be mitigated while necessary recommendation diversities can be maximally preserved simultaneously. Experiments conducted on semi-simulated and real-world datasets demonstrate the effectiveness of PSF-RS.
Personality-aware Human-centric Multimodal Reasoning: A New Task
Apr 05, 2023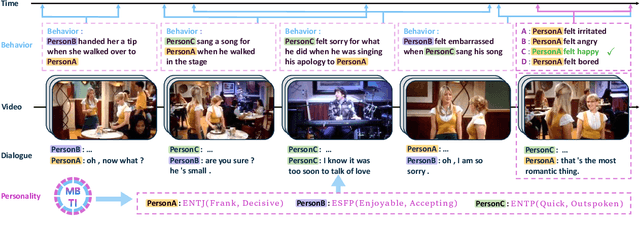
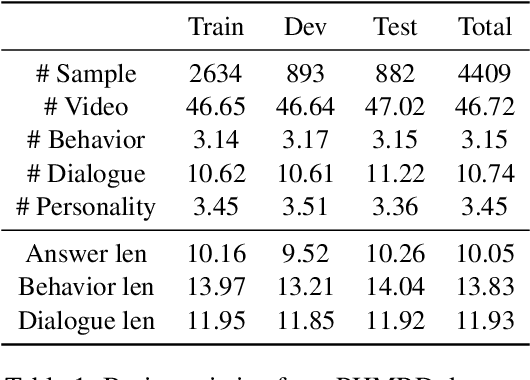


Multimodal reasoning, an area of artificial intelligence that aims at make inferences from multimodal signals such as vision, language and speech, has drawn more and more attention in recent years. People with different personalities may respond differently to the same situation. However, such individual personalities were ignored in the previous studies. In this work, we introduce a new Personality-aware Human-centric Multimodal Reasoning (Personality-aware HMR) task, and accordingly construct a new dataset based on The Big Bang Theory television shows, to predict the behavior of a specific person at a specific moment, given the multimodal information of its past and future moments. The Myers-Briggs Type Indicator (MBTI) was annotated and utilized in the task to represent individuals' personalities. We benchmark the task by proposing three baseline methods, two were adapted from the related tasks and one was newly proposed for our task. The experimental results demonstrate that personality can effectively improve the performance of human-centric multimodal reasoning. To further solve the lack of personality annotation in real-life scenes, we introduce an extended task called Personality-predicted HMR, and propose the corresponding methods, to predict the MBTI personality at first, and then use the predicted personality to help multimodal reasoning. The experimental results show that our method can accurately predict personality and achieves satisfactory multimodal reasoning performance without relying on personality annotations.
Causal Inference in Recommender Systems: A Survey of Strategies for Bias Mitigation, Explanation, and Generalization
Jan 03, 2023

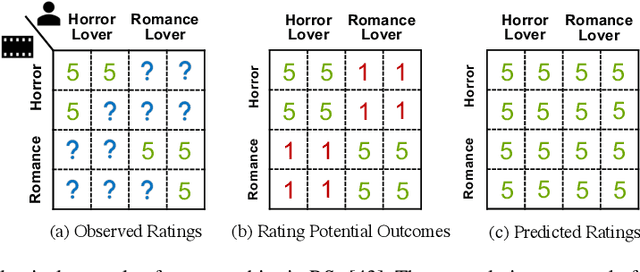
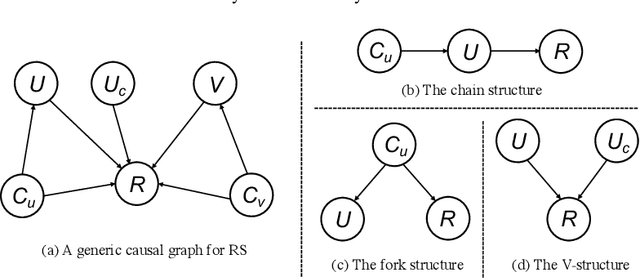
In the era of information overload, recommender systems (RSs) have become an indispensable part of online service platforms. Traditional RSs estimate user interests and predict their future behaviors by utilizing correlations in the observational historical activities, their profiles, and the content of interacted items. However, since the inherent causal reasons that lead to the observed users' behaviors are not considered, multiple types of biases could exist in the generated recommendations. In addition, the causal motives that drive user activities are usually entangled in these RSs, where the explainability and generalization abilities of recommendations cannot be guaranteed. To address these drawbacks, recent years have witnessed an upsurge of interest in enhancing traditional RSs with causal inference techniques. In this survey, we provide a systematic overview of causal RSs and help readers gain a comprehensive understanding of this promising area. We start with the basic concepts of traditional RSs and their limitations due to the lack of causal reasoning ability. We then discuss how different causal inference techniques can be introduced to address these challenges, with an emphasis on debiasing, explainability promotion, and generalization improvement. Furthermore, we thoroughly analyze various evaluation strategies for causal RSs, focusing especially on how to reliably estimate their performance with biased data if the causal effects of interests are unavailable. Finally, we provide insights into potential directions for future causal RS research.
Mutually-Regularized Dual Collaborative Variational Auto-encoder for Recommendation Systems
Nov 21, 2022
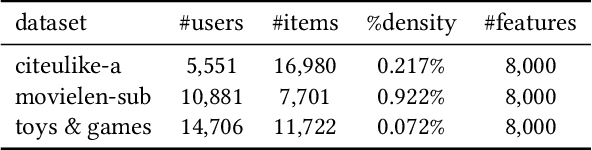
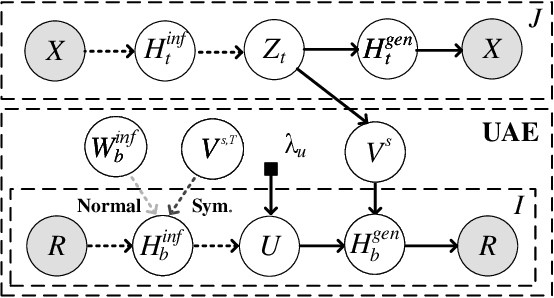
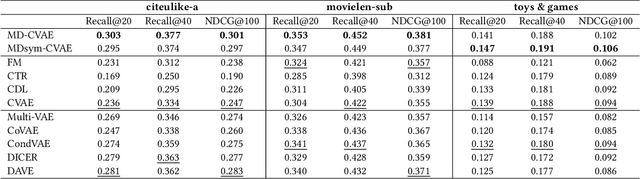
Recently, user-oriented auto-encoders (UAEs) have been widely used in recommender systems to learn semantic representations of users based on their historical ratings. However, since latent item variables are not modeled in UAE, it is difficult to utilize the widely available item content information when ratings are sparse. In addition, whenever new items arrive, we need to wait for collecting rating data for these items and retrain the UAE from scratch, which is inefficient in practice. Aiming to address the above two problems simultaneously, we propose a mutually-regularized dual collaborative variational auto-encoder (MD-CVAE) for recommendation. First, by replacing randomly initialized last layer weights of the vanilla UAE with stacked latent item embeddings, MD-CVAE integrates two heterogeneous information sources, i.e., item content and user ratings, into the same principled variational framework where the weights of UAE are regularized by item content such that convergence to a non-optima due to data sparsity can be avoided. In addition, the regularization is mutual in that user ratings can also help the dual item content module learn more recommendation-oriented item content embeddings. Finally, we propose a symmetric inference strategy for MD-CVAE where the first layer weights of the UAE encoder are tied to the latent item embeddings of the UAE decoder. Through this strategy, no retraining is required to recommend newly introduced items. Empirical studies show the effectiveness of MD-CVAE in both normal and cold-start scenarios. Codes are available at https://github.com/yaochenzhu/MD-CVAE.
Deep Deconfounded Content-based Tag Recommendation for UGC with Causal Intervention
May 28, 2022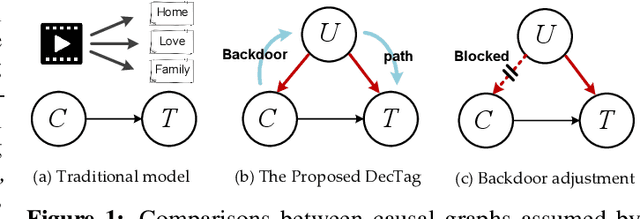
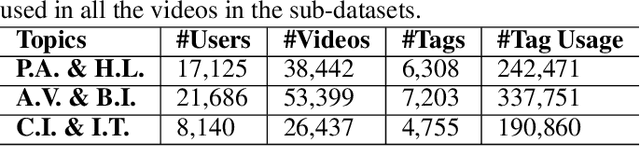


Traditional content-based tag recommender systems directly learn the association between user-generated content (UGC) and tags based on collected UGC-tag pairs. However, since a UGC uploader simultaneously creates the UGC and selects the corresponding tags, her personal preference inevitably biases the tag selections, which prevents these recommenders from learning the causal influence of UGCs' content features on tags. In this paper, we propose a deep deconfounded content-based tag recommender system, namely, DecTag, to address the above issues. We first establish a causal graph to represent the relations among uploader, UGC, and tag, where the uploaders are identified as confounders that spuriously correlate UGC and tag selections. Specifically, to eliminate the confounding bias, causal intervention is conducted on the UGC node in the graph via backdoor adjustment, where uploaders' influence on tags leaked through backdoor paths can be eliminated for causal effect estimation. Observing that adjusting the causal graph with do-calculus requires integrating the entire uploader space, which is infeasible, we design a novel Monte Carlo (MC)-based estimator with bootstrap, which can achieve asymptotic unbiasedness provided that uploaders for the collected UGCs are i.i.d. samples from the population. In addition, the MC estimator has the intuition of substituting the biased uploaders with a hypothetical random uploader from the population in the training phase, where deconfounding can be achieved in an interpretable manner. Finally, we establish a YT-8M-Causal dataset based on the widely used YouTube-8M dataset with causal intervention and propose an evaluation strategy accordingly to unbiasedly evaluate causal tag recommenders. Extensive experiments show that DecTag is more robust to confounding bias than state-of-the-art causal recommenders.
Deep Causal Reasoning for Recommendations
Jan 06, 2022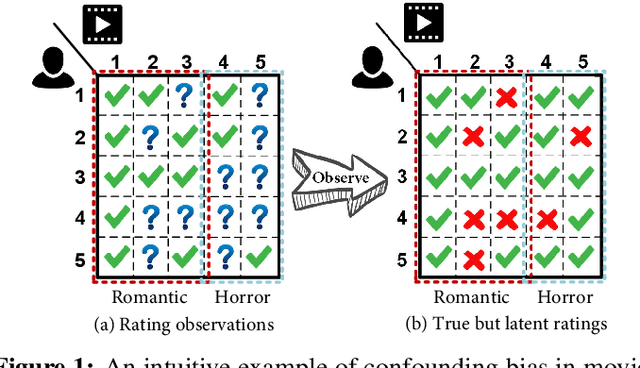
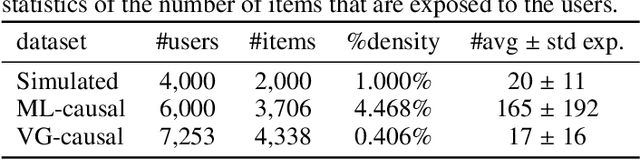
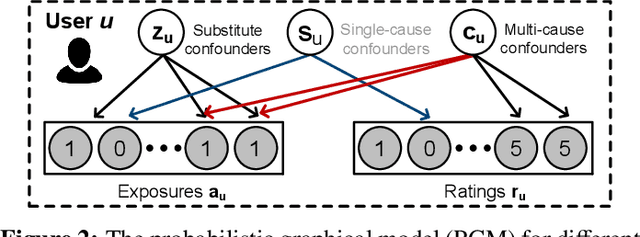
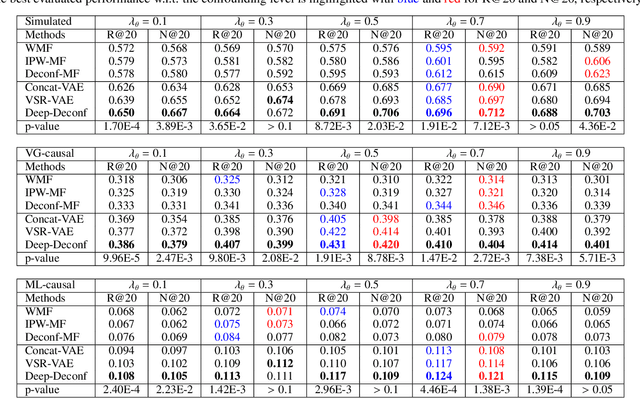
Traditional recommender systems aim to estimate a user's rating to an item based on observed ratings from the population. As with all observational studies, hidden confounders, which are factors that affect both item exposures and user ratings, lead to a systematic bias in the estimation. Consequently, a new trend in recommender system research is to negate the influence of confounders from a causal perspective. Observing that confounders in recommendations are usually shared among items and are therefore multi-cause confounders, we model the recommendation as a multi-cause multi-outcome (MCMO) inference problem. Specifically, to remedy confounding bias, we estimate user-specific latent variables that render the item exposures independent Bernoulli trials. The generative distribution is parameterized by a DNN with factorized logistic likelihood and the intractable posteriors are estimated by variational inference. Controlling these factors as substitute confounders, under mild assumptions, can eliminate the bias incurred by multi-cause confounders. Furthermore, we show that MCMO modeling may lead to high variance due to scarce observations associated with the high-dimensional causal space. Fortunately, we theoretically demonstrate that introducing user features as pre-treatment variables can substantially improve sample efficiency and alleviate overfitting. Empirical studies on simulated and real-world datasets show that the proposed deep causal recommender shows more robustness to unobserved confounders than state-of-the-art causal recommenders. Codes and datasets are released at https://github.com/yaochenzhu/deep-deconf.