 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiajun Zhang
Bridging the Gap between Different Vocabularies for LLM Ensemble
Apr 15, 2024
Ensembling different large language models (LLMs) to unleash their complementary potential and harness their individual strengths is highly valuable. Nevertheless, vocabulary discrepancies among various LLMs have constrained previous studies to either selecting or blending completely generated outputs. This limitation hinders the dynamic correction and enhancement of outputs during the generation process, resulting in a limited capacity for effective ensemble. To address this issue, we propose a novel method to Ensemble LLMs via Vocabulary Alignment (EVA). EVA bridges the lexical gap among various LLMs, enabling meticulous ensemble at each generation step. Specifically, we first learn mappings between the vocabularies of different LLMs with the assistance of overlapping tokens. Subsequently, these mappings are employed to project output distributions of LLMs into a unified space, facilitating a fine-grained ensemble. Finally, we design a filtering strategy to exclude models that generate unfaithful tokens. Experimental results on commonsense reasoning, arithmetic reasoning, machine translation, and data-to-text generation tasks demonstrate the superiority of our approach compared with individual LLMs and previous ensemble methods conducted on complete outputs. Further analyses confirm that our approach can leverage knowledge from different language models and yield consistent improvement.
COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning
Mar 26, 2024Recently, there have been significant advancements in large language models (LLMs), particularly focused on the English language. These advancements have enabled these LLMs to understand and execute complex instructions with unprecedented accuracy and fluency. However, despite these advancements, there remains a noticeable gap in the development of Chinese instruction tuning. The unique linguistic features and cultural depth of the Chinese language pose challenges for instruction tuning tasks. Existing datasets are either derived from English-centric LLMs or are ill-suited for aligning with the interaction patterns of real-world Chinese users. To bridge this gap, we introduce COIG-CQIA, a high-quality Chinese instruction tuning dataset. Our aim is to build a diverse, wide-ranging instruction-tuning dataset to better align model behavior with human interactions. To this end, we collect a high-quality human-written corpus from various sources on the Chinese Internet, including Q&A communities, Wikis, examinations, and existing NLP datasets. This corpus was rigorously filtered and carefully processed to form the COIG-CQIA dataset. Furthermore, we train models of various scales on different subsets of CQIA, following in-depth evaluation and analyses. The findings from our experiments offer valuable insights for selecting and developing Chinese instruction-tuning datasets. We also find that models trained on CQIA-Subset achieve competitive results in human assessment as well as knowledge and security benchmarks. Data are available at https://huggingface.co/datasets/m-a-p/COIG-CQIA
DEEP-ICL: Definition-Enriched Experts for Language Model In-Context Learning
Mar 07, 2024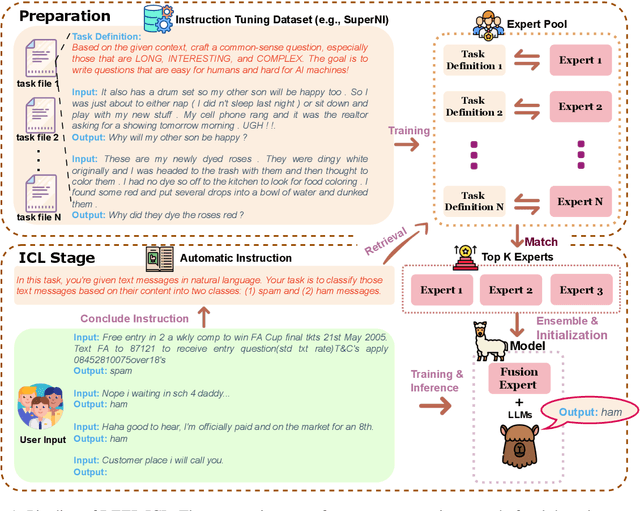
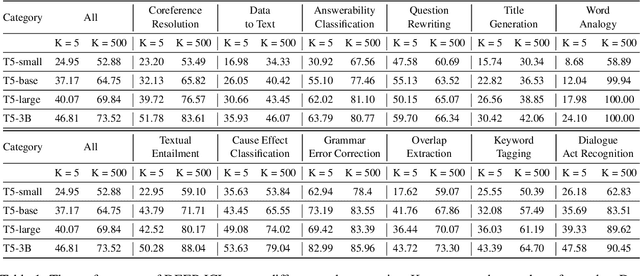
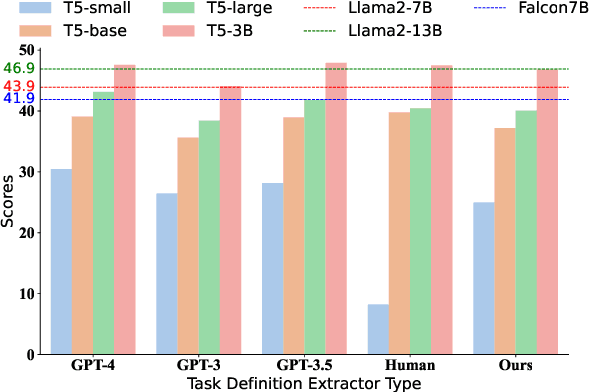
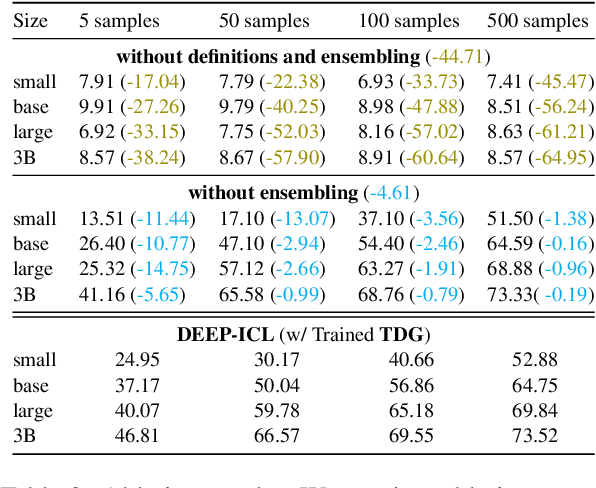
It has long been assumed that the sheer number of parameters in large language models (LLMs) drives in-context learning (ICL) capabilities, enabling remarkable performance improvements by leveraging task-specific demonstrations. Challenging this hypothesis, we introduce DEEP-ICL, a novel task Definition Enriched ExPert Ensembling methodology for ICL. DEEP-ICL explicitly extracts task definitions from given demonstrations and generates responses through learning task-specific examples. We argue that improvement from ICL does not directly rely on model size, but essentially stems from understanding task definitions and task-guided learning. Inspired by this, DEEP-ICL combines two 3B models with distinct roles (one for concluding task definitions and the other for learning task demonstrations) and achieves comparable performance to LLaMA2-13B. Furthermore, our framework outperforms conventional ICL by overcoming pretraining sequence length limitations, by supporting unlimited demonstrations. We contend that DEEP-ICL presents a novel alternative for achieving efficient few-shot learning, extending beyond the conventional ICL.
DPPA: Pruning Method for Large Language Model to Model Merging
Mar 05, 2024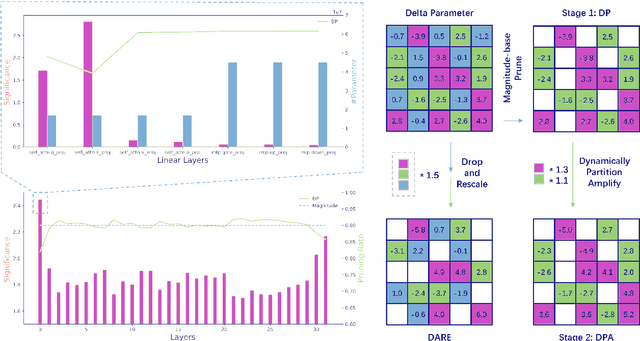
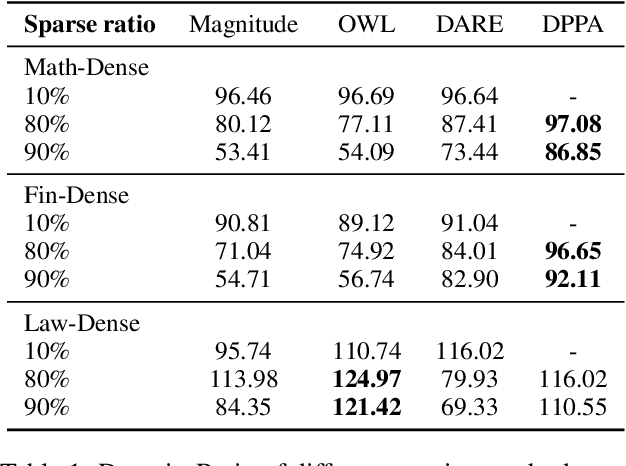
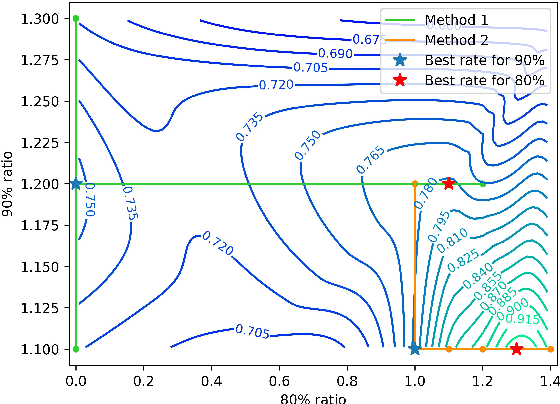
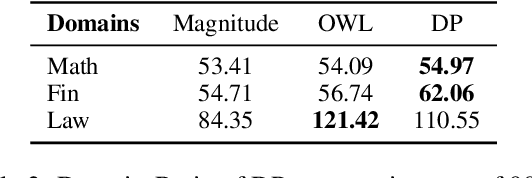
Model merging is to combine fine-tuned models derived from multiple domains, with the intent of enhancing the model's proficiency across various domains. The principal concern is the resolution of parameter conflicts. A substantial amount of existing research remedy this issue during the merging stage, with the latest study focusing on resolving this issue throughout the pruning stage. The DARE approach has exhibited promising outcomes when applied to a simplistic fine-tuned model. However, the efficacy of this method tends to wane when employed on complex fine-tuned models that show a significant parameter bias relative to the baseline model. In this paper, we introduce a dual-stage method termed Dynamic Pruning Partition Amplification (DPPA), devised to tackle the challenge of merging complex fine-tuned models. Initially, we introduce Dynamically Pruning (DP), an improved approach based on magnitude pruning, which aim is to enhance performance at higher pruning rates. Subsequently, we propose Dynamically Partition Amplification (DPA), a rescaling strategy, is designed to dynamically amplify parameter partitions in relation to their significance levels. The experimental results show that our method maintains a mere 20% of domain-specific parameters and yet delivers a performance comparable to other methodologies that preserve up to 90% of parameters. Furthermore, our method displays outstanding performance post-pruning, leading to a significant improvement of nearly 20% performance in model merging. We make our code on Github.
Evolving to the Future: Unseen Event Adaptive Fake News Detection on Social Media
Feb 29, 2024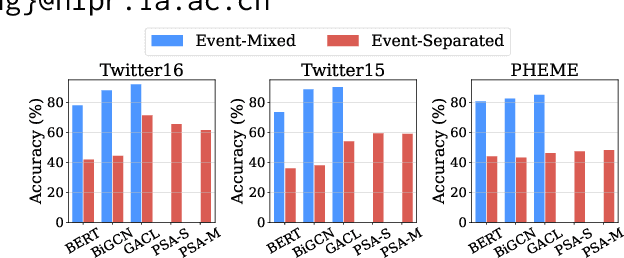
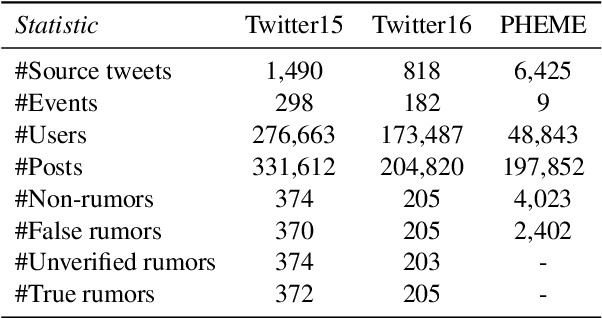
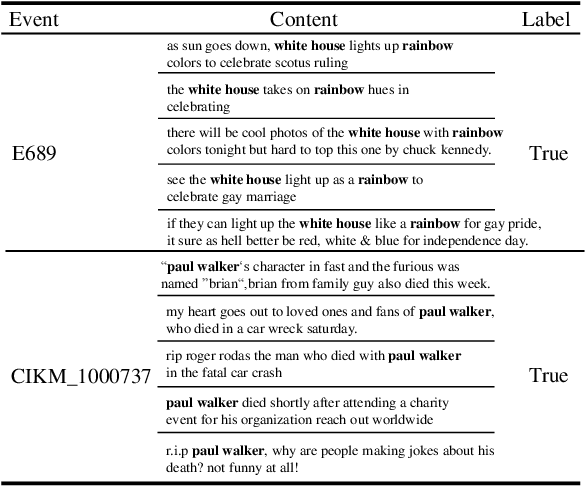
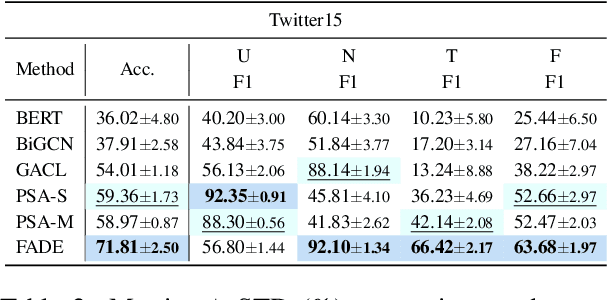
With the rapid development of social media, the wide dissemination of fake news on social media is increasingly threatening both individuals and society. In the dynamic landscape of social media, fake news detection aims to develop a model trained on news reporting past events. The objective is to predict and identify fake news about future events, which often relate to subjects entirely different from those in the past. However, existing fake detection methods exhibit a lack of robustness and cannot generalize to unseen events. To address this, we introduce Future ADaptive Event-based Fake news Detection (FADE) framework. Specifically, we train a target predictor through an adaptive augmentation strategy and graph contrastive learning to make more robust overall predictions. Simultaneously, we independently train an event-only predictor to obtain biased predictions. Then we further mitigate event bias by obtaining the final prediction by subtracting the output of the event-only predictor from the output of the target predictor. Encouraging results from experiments designed to emulate real-world social media conditions validate the effectiveness of our method in comparison to existing state-of-the-art approaches.
CIF-Bench: A Chinese Instruction-Following Benchmark for Evaluating the Generalizability of Large Language Models
Feb 20, 2024The advancement of large language models (LLMs) has enhanced the ability to generalize across a wide range of unseen natural language processing (NLP) tasks through instruction-following. Yet, their effectiveness often diminishes in low-resource languages like Chinese, exacerbated by biased evaluations from data leakage, casting doubt on their true generalizability to new linguistic territories. In response, we introduce the Chinese Instruction-Following Benchmark (CIF-Bench), designed to evaluate the zero-shot generalizability of LLMs to the Chinese language. CIF-Bench comprises 150 tasks and 15,000 input-output pairs, developed by native speakers to test complex reasoning and Chinese cultural nuances across 20 categories. To mitigate evaluation bias, we release only half of the dataset publicly, with the remainder kept private, and introduce diversified instructions to minimize score variance, totaling 45,000 data instances. Our evaluation of 28 selected LLMs reveals a noticeable performance gap, with the best model scoring only 52.9%, highlighting the limitations of LLMs in less familiar language and task contexts. This work aims to uncover the current limitations of LLMs in handling Chinese tasks, pushing towards the development of more culturally informed and linguistically diverse models with the released data and benchmark (https://yizhilll.github.io/CIF-Bench/).
A Survey on Data Selection for LLM Instruction Tuning
Feb 04, 2024Instruction tuning is a vital step of training large language models (LLM), so how to enhance the effect of instruction tuning has received increased attention. Existing works indicate that the quality of the dataset is more crucial than the quantity during instruction tuning of LLM. Therefore, recently a lot of studies focus on exploring the methods of selecting high-quality subset from instruction datasets, aiming to reduce training costs and enhance the instruction-following capabilities of LLMs. This paper presents a comprehensive survey on data selection for LLM instruction tuning. Firstly, we introduce the wildly used instruction datasets. Then, we propose a new taxonomy of the data selection methods and provide a detailed introduction of recent advances,and the evaluation strategies and results of data selection methods are also elaborated in detail. Finally, we emphasize the open challenges and present new frontiers of this task.
Ins-HOI: Instance Aware Human-Object Interactions Recovery
Dec 15, 2023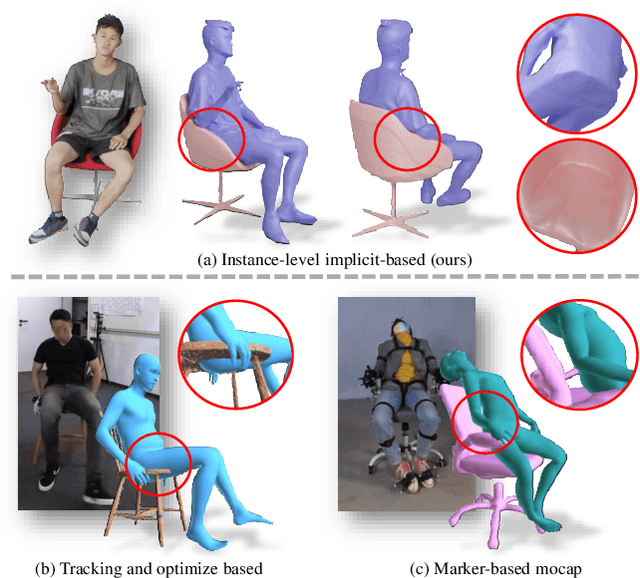
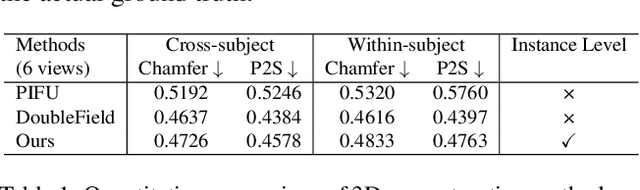


Recovering detailed interactions between humans/hands and objects is an appealing yet challenging task. Existing methods typically use template-based representations to track human/hand and objects in interactions. Despite the progress, they fail to handle the invisible contact surfaces. In this paper, we propose Ins-HOI, an end-to-end solution to recover human/hand-object reconstruction via instance-level implicit reconstruction. To this end, we introduce an instance-level occupancy field to support simultaneous human/hand and object representation, and a complementary training strategy to handle the lack of instance-level ground truths. Such a representation enables learning a contact prior implicitly from sparse observations. During the complementary training, we augment the real-captured data with synthesized data by randomly composing individual scans of humans/hands and objects and intentionally allowing for penetration. In this way, our network learns to recover individual shapes as completely as possible from the synthesized data, while being aware of the contact constraints and overall reasonability based on real-captured scans. As demonstrated in experiments, our method Ins-HOI can produce reasonable and realistic non-visible contact surfaces even in cases of extremely close interaction. To facilitate the research of this task, we collect a large-scale, high-fidelity 3D scan dataset, including 5.2k high-quality scans with real-world human-chair and hand-object interactions. We will release our dataset and source codes. Data examples and the video results of our method can be found on the project page.
BiPFT: Binary Pre-trained Foundation Transformer with Low-rank Estimation of Binarization Residual Polynomials
Dec 14, 2023Pretrained foundation models offer substantial benefits for a wide range of downstream tasks, which can be one of the most potential techniques to access artificial general intelligence. However, scaling up foundation transformers for maximal task-agnostic knowledge has brought about computational challenges, especially on resource-limited devices such as mobiles. This work proposes the first Binary Pretrained Foundation Transformer (BiPFT) for natural language understanding (NLU) tasks, which remarkably saves 56 times operations and 28 times memory. In contrast to previous task-specific binary transformers, BiPFT exhibits a substantial enhancement in the learning capabilities of binary neural networks (BNNs), promoting BNNs into the era of pre-training. Benefiting from extensive pretraining data, we further propose a data-driven binarization method. Specifically, we first analyze the binarization error in self-attention operations and derive the polynomials of binarization error. To simulate full-precision self-attention, we define binarization error as binarization residual polynomials, and then introduce low-rank estimators to model these polynomials. Extensive experiments validate the effectiveness of BiPFTs, surpassing task-specific baseline by 15.4% average performance on the GLUE benchmark. BiPFT also demonstrates improved robustness to hyperparameter changes, improved optimization efficiency, and reduced reliance on downstream distillation, which consequently generalize on various NLU tasks and simplify the downstream pipeline of BNNs. Our code and pretrained models are publicly available at https://github.com/Xingrun-Xing/BiPFT.
Toward Real World Stereo Image Super-Resolution via Hybrid Degradation Model and Discriminator for Implied Stereo Image Information
Dec 13, 2023Real-world stereo image super-resolution has a significant influence on enhancing the performance of computer vision systems. Although existing methods for single-image super-resolution can be applied to improve stereo images, these methods often introduce notable modifications to the inherent disparity, resulting in a loss in the consistency of disparity between the original and the enhanced stereo images. To overcome this limitation, this paper proposes a novel approach that integrates a implicit stereo information discriminator and a hybrid degradation model. This combination ensures effective enhancement while preserving disparity consistency. The proposed method bridges the gap between the complex degradations in real-world stereo domain and the simpler degradations in real-world single-image super-resolution domain. Our results demonstrate impressive performance on synthetic and real datasets, enhancing visual perception while maintaining disparity consistency. The complete code is available at the following \href{https://github.com/fzuzyb/SCGLANet}{link}.