 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYiming Liang
MuPT: A Generative Symbolic Music Pretrained Transformer
Apr 10, 2024
In this paper, we explore the application of Large Language Models (LLMs) to the pre-training of music. While the prevalent use of MIDI in music modeling is well-established, our findings suggest that LLMs are inherently more compatible with ABC Notation, which aligns more closely with their design and strengths, thereby enhancing the model's performance in musical composition. To address the challenges associated with misaligned measures from different tracks during generation, we propose the development of a Synchronized Multi-Track ABC Notation (SMT-ABC Notation), which aims to preserve coherence across multiple musical tracks. Our contributions include a series of models capable of handling up to 8192 tokens, covering 90% of the symbolic music data in our training set. Furthermore, we explore the implications of the Symbolic Music Scaling Law (SMS Law) on model performance. The results indicate a promising direction for future research in music generation, offering extensive resources for community-led research through our open-source contributions.
COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning
Mar 26, 2024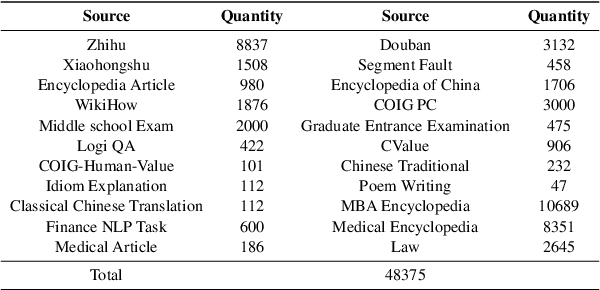
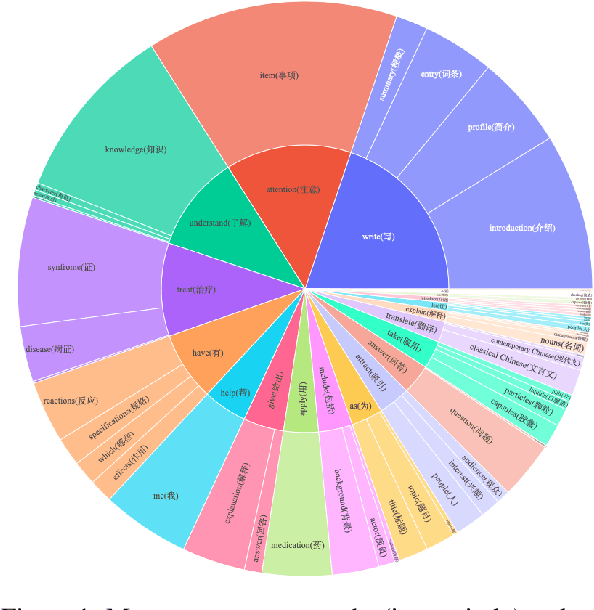
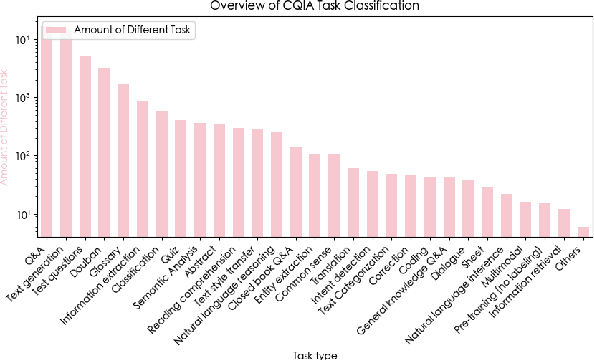
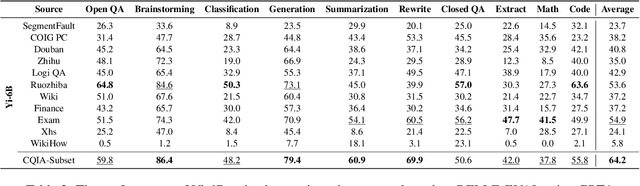
Recently, there have been significant advancements in large language models (LLMs), particularly focused on the English language. These advancements have enabled these LLMs to understand and execute complex instructions with unprecedented accuracy and fluency. However, despite these advancements, there remains a noticeable gap in the development of Chinese instruction tuning. The unique linguistic features and cultural depth of the Chinese language pose challenges for instruction tuning tasks. Existing datasets are either derived from English-centric LLMs or are ill-suited for aligning with the interaction patterns of real-world Chinese users. To bridge this gap, we introduce COIG-CQIA, a high-quality Chinese instruction tuning dataset. Our aim is to build a diverse, wide-ranging instruction-tuning dataset to better align model behavior with human interactions. To this end, we collect a high-quality human-written corpus from various sources on the Chinese Internet, including Q&A communities, Wikis, examinations, and existing NLP datasets. This corpus was rigorously filtered and carefully processed to form the COIG-CQIA dataset. Furthermore, we train models of various scales on different subsets of CQIA, following in-depth evaluation and analyses. The findings from our experiments offer valuable insights for selecting and developing Chinese instruction-tuning datasets. We also find that models trained on CQIA-Subset achieve competitive results in human assessment as well as knowledge and security benchmarks. Data are available at https://huggingface.co/datasets/m-a-p/COIG-CQIA
DEEP-ICL: Definition-Enriched Experts for Language Model In-Context Learning
Mar 07, 2024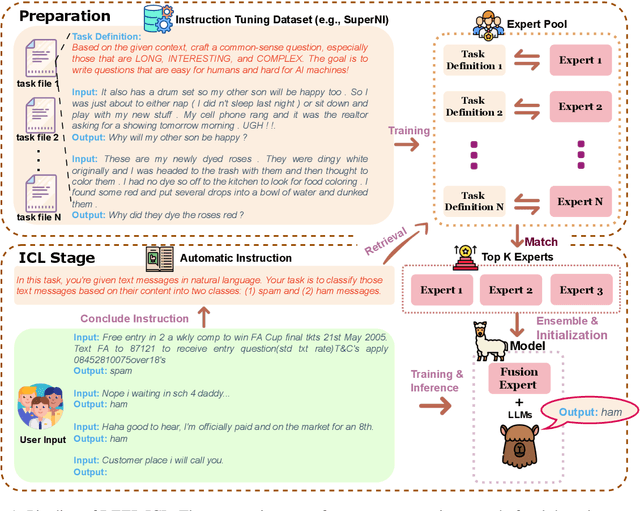
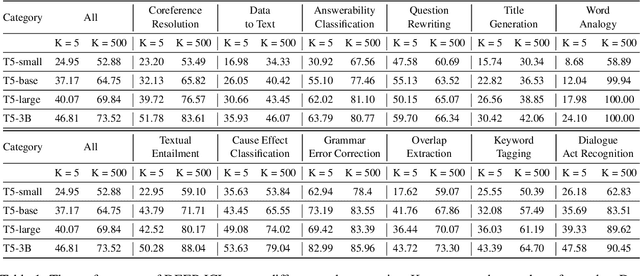
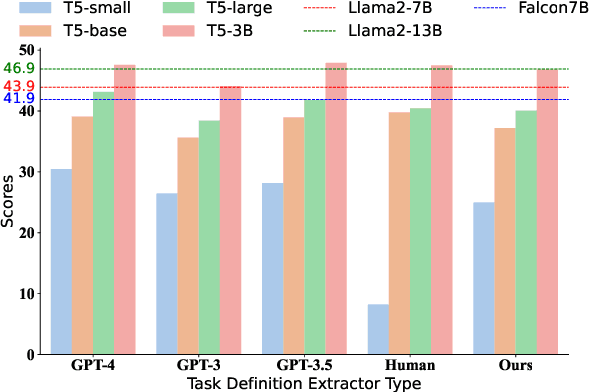
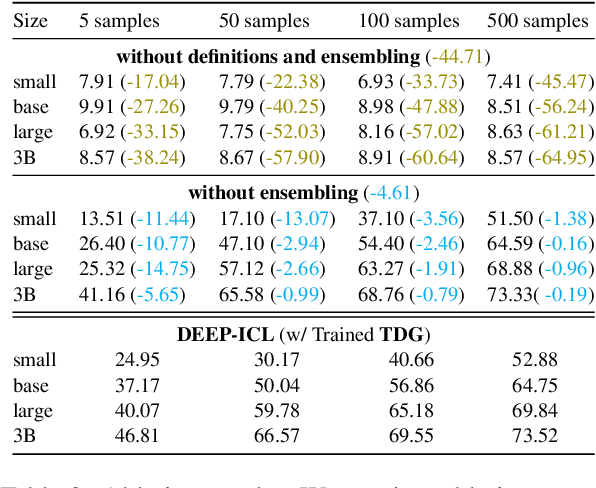
It has long been assumed that the sheer number of parameters in large language models (LLMs) drives in-context learning (ICL) capabilities, enabling remarkable performance improvements by leveraging task-specific demonstrations. Challenging this hypothesis, we introduce DEEP-ICL, a novel task Definition Enriched ExPert Ensembling methodology for ICL. DEEP-ICL explicitly extracts task definitions from given demonstrations and generates responses through learning task-specific examples. We argue that improvement from ICL does not directly rely on model size, but essentially stems from understanding task definitions and task-guided learning. Inspired by this, DEEP-ICL combines two 3B models with distinct roles (one for concluding task definitions and the other for learning task demonstrations) and achieves comparable performance to LLaMA2-13B. Furthermore, our framework outperforms conventional ICL by overcoming pretraining sequence length limitations, by supporting unlimited demonstrations. We contend that DEEP-ICL presents a novel alternative for achieving efficient few-shot learning, extending beyond the conventional ICL.
m2mKD: Module-to-Module Knowledge Distillation for Modular Transformers
Feb 26, 2024Modular neural architectures are gaining increasing attention due to their powerful capability for generalization and sample-efficient adaptation to new domains. However, training modular models, particularly in the early stages, poses challenges due to the optimization difficulties arising from their intrinsic sparse connectivity. Leveraging the knowledge from monolithic models, using techniques such as knowledge distillation, is likely to facilitate the training of modular models and enable them to integrate knowledge from multiple models pretrained on diverse sources. Nevertheless, conventional knowledge distillation approaches are not tailored to modular models and can fail when directly applied due to the unique architectures and the enormous number of parameters involved. Motivated by these challenges, we propose a general module-to-module knowledge distillation (m2mKD) method for transferring knowledge between modules. Our approach involves teacher modules split from a pretrained monolithic model, and student modules of a modular model. m2mKD separately combines these modules with a shared meta model and encourages the student module to mimic the behaviour of the teacher module. We evaluate the effectiveness of m2mKD on two distinct modular neural architectures: Neural Attentive Circuits (NACs) and Vision Mixture-of-Experts (V-MoE). By applying m2mKD to NACs, we achieve significant improvements in IID accuracy on Tiny-ImageNet (up to 5.6%) and OOD robustness on Tiny-ImageNet-R (up to 4.2%). On average, we observe a 1% gain in both ImageNet and ImageNet-R. The V-MoE-Base model trained using m2mKD also achieves 3.5% higher accuracy than end-to-end training on ImageNet. The experimental results demonstrate that our method offers a promising solution for connecting modular networks with pretrained monolithic models. Code is available at https://github.com/kamanphoebe/m2mKD.
ChatMusician: Understanding and Generating Music Intrinsically with LLM
Feb 25, 2024While Large Language Models (LLMs) demonstrate impressive capabilities in text generation, we find that their ability has yet to be generalized to music, humanity's creative language. We introduce ChatMusician, an open-source LLM that integrates intrinsic musical abilities. It is based on continual pre-training and finetuning LLaMA2 on a text-compatible music representation, ABC notation, and the music is treated as a second language. ChatMusician can understand and generate music with a pure text tokenizer without any external multi-modal neural structures or tokenizers. Interestingly, endowing musical abilities does not harm language abilities, even achieving a slightly higher MMLU score. Our model is capable of composing well-structured, full-length music, conditioned on texts, chords, melodies, motifs, musical forms, etc, surpassing GPT-4 baseline. On our meticulously curated college-level music understanding benchmark, MusicTheoryBench, ChatMusician surpasses LLaMA2 and GPT-3.5 on zero-shot setting by a noticeable margin. Our work reveals that LLMs can be an excellent compressor for music, but there remains significant territory to be conquered. We release our 4B token music-language corpora MusicPile, the collected MusicTheoryBench, code, model and demo in GitHub.
CIF-Bench: A Chinese Instruction-Following Benchmark for Evaluating the Generalizability of Large Language Models
Feb 20, 2024The advancement of large language models (LLMs) has enhanced the ability to generalize across a wide range of unseen natural language processing (NLP) tasks through instruction-following. Yet, their effectiveness often diminishes in low-resource languages like Chinese, exacerbated by biased evaluations from data leakage, casting doubt on their true generalizability to new linguistic territories. In response, we introduce the Chinese Instruction-Following Benchmark (CIF-Bench), designed to evaluate the zero-shot generalizability of LLMs to the Chinese language. CIF-Bench comprises 150 tasks and 15,000 input-output pairs, developed by native speakers to test complex reasoning and Chinese cultural nuances across 20 categories. To mitigate evaluation bias, we release only half of the dataset publicly, with the remainder kept private, and introduce diversified instructions to minimize score variance, totaling 45,000 data instances. Our evaluation of 28 selected LLMs reveals a noticeable performance gap, with the best model scoring only 52.9%, highlighting the limitations of LLMs in less familiar language and task contexts. This work aims to uncover the current limitations of LLMs in handling Chinese tasks, pushing towards the development of more culturally informed and linguistically diverse models with the released data and benchmark (https://yizhilll.github.io/CIF-Bench/).
SciMMIR: Benchmarking Scientific Multi-modal Information Retrieval
Jan 24, 2024Multi-modal information retrieval (MMIR) is a rapidly evolving field, where significant progress, particularly in image-text pairing, has been made through advanced representation learning and cross-modality alignment research. However, current benchmarks for evaluating MMIR performance in image-text pairing within the scientific domain show a notable gap, where chart and table images described in scholarly language usually do not play a significant role. To bridge this gap, we develop a specialised scientific MMIR (SciMMIR) benchmark by leveraging open-access paper collections to extract data relevant to the scientific domain. This benchmark comprises 530K meticulously curated image-text pairs, extracted from figures and tables with detailed captions in scientific documents. We further annotate the image-text pairs with two-level subset-subcategory hierarchy annotations to facilitate a more comprehensive evaluation of the baselines. We conducted zero-shot and fine-tuning evaluations on prominent multi-modal image-captioning and visual language models, such as CLIP and BLIP. Our analysis offers critical insights for MMIR in the scientific domain, including the impact of pre-training and fine-tuning settings and the influence of the visual and textual encoders. All our data and checkpoints are publicly available at https://github.com/Wusiwei0410/SciMMIR.
CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark
Jan 22, 2024As the capabilities of large multimodal models (LMMs) continue to advance, evaluating the performance of LMMs emerges as an increasing need. Additionally, there is an even larger gap in evaluating the advanced knowledge and reasoning abilities of LMMs in non-English contexts such as Chinese. We introduce CMMMU, a new Chinese Massive Multi-discipline Multimodal Understanding benchmark designed to evaluate LMMs on tasks demanding college-level subject knowledge and deliberate reasoning in a Chinese context. CMMMU is inspired by and strictly follows the annotation and analysis pattern of MMMU. CMMMU includes 12k manually collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering, like its companion, MMMU. These questions span 30 subjects and comprise 39 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. CMMMU focuses on complex perception and reasoning with domain-specific knowledge in the Chinese context. We evaluate 11 open-source LLMs and one proprietary GPT-4V(ision). Even GPT-4V only achieves accuracies of 42%, indicating a large space for improvement. CMMMU will boost the community to build the next-generation LMMs towards expert artificial intelligence and promote the democratization of LMMs by providing diverse language contexts.
Towards Practical Autonomous Flight Simulation for Flapping Wing Biomimetic Robots with Experimental Validation
Mar 08, 2023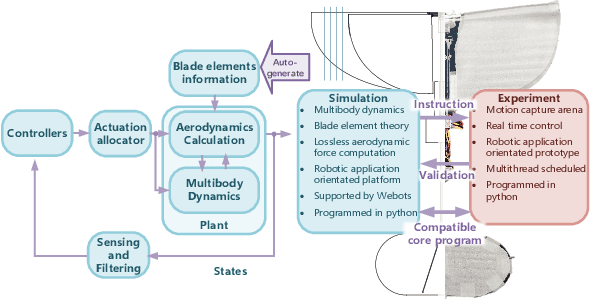
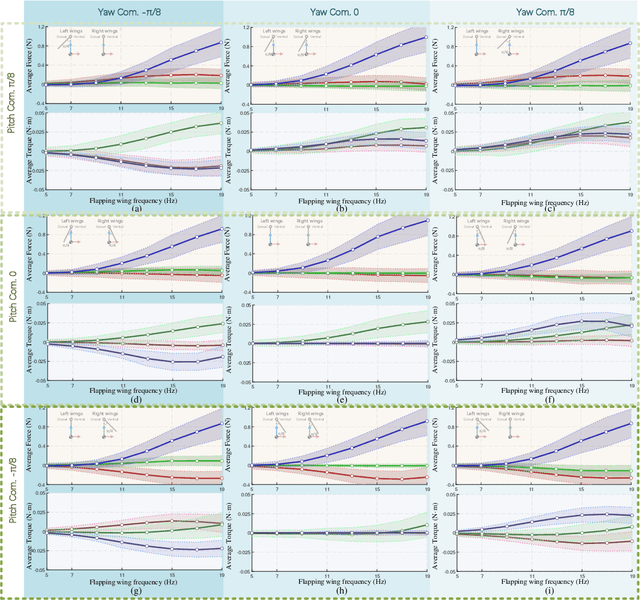
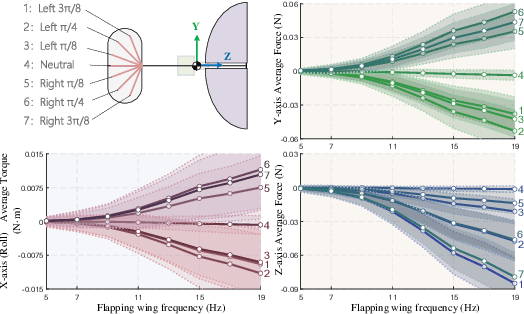
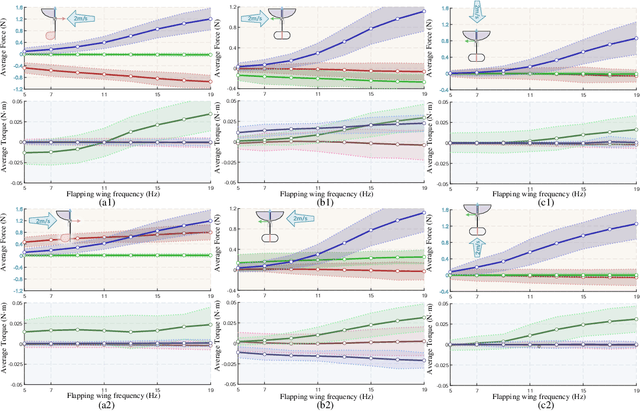
Tried-and-true flapping wing robot simulation is essential in developing flapping wing mechanisms and algorithms. This paper presents a novel application-oriented flapping wing platform, highly compatible with various mechanical designs and adaptable to different robotic tasks. First, the blade element theory and the quasi-steady model are put forward to compute the flapping wing aerodynamics based on wing kinematics. Translational lift, translational drag, rotational lift, and added mass force are all considered in the computation. Then we use the proposed simulation platform to investigate the passive wing rotation and the wing-tail interaction phenomena of a particular flapping-wing robot. With the help of the simulation tool and a novel statistic based on dynamic differences from the averaged system, several behaviors display their essence by investigating the flapping wing robot dynamic characteristics. After that, the attitude tracking control problem and the positional trajectory tracking problem are both overcome by robust control techniques. Further comparison simulations reveal that the proposed control algorithms compared with other existing ones show apparent superiority. What is more, with the same control algorithm and parameters tuned in simulation, we conduct real flight experiments on a self-made flapping wing robot, and obtain similar results from the proposed simulation platform. In contrast to existing simulation tools, the proposed one is compatible with most existing flapping wing robots, and can inherently drill into each subtle behavior in corresponding applications by observing aerodynamic forces and torques on each blade element.