 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQifeng Liu
FlashSpeech: Efficient Zero-Shot Speech Synthesis
Apr 25, 2024
Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5\% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.
ChatMusician: Understanding and Generating Music Intrinsically with LLM
Feb 25, 2024While Large Language Models (LLMs) demonstrate impressive capabilities in text generation, we find that their ability has yet to be generalized to music, humanity's creative language. We introduce ChatMusician, an open-source LLM that integrates intrinsic musical abilities. It is based on continual pre-training and finetuning LLaMA2 on a text-compatible music representation, ABC notation, and the music is treated as a second language. ChatMusician can understand and generate music with a pure text tokenizer without any external multi-modal neural structures or tokenizers. Interestingly, endowing musical abilities does not harm language abilities, even achieving a slightly higher MMLU score. Our model is capable of composing well-structured, full-length music, conditioned on texts, chords, melodies, motifs, musical forms, etc, surpassing GPT-4 baseline. On our meticulously curated college-level music understanding benchmark, MusicTheoryBench, ChatMusician surpasses LLaMA2 and GPT-3.5 on zero-shot setting by a noticeable margin. Our work reveals that LLMs can be an excellent compressor for music, but there remains significant territory to be conquered. We release our 4B token music-language corpora MusicPile, the collected MusicTheoryBench, code, model and demo in GitHub.
CoMoSVC: Consistency Model-based Singing Voice Conversion
Jan 03, 2024The diffusion-based Singing Voice Conversion (SVC) methods have achieved remarkable performances, producing natural audios with high similarity to the target timbre. However, the iterative sampling process results in slow inference speed, and acceleration thus becomes crucial. In this paper, we propose CoMoSVC, a consistency model-based SVC method, which aims to achieve both high-quality generation and high-speed sampling. A diffusion-based teacher model is first specially designed for SVC, and a student model is further distilled under self-consistency properties to achieve one-step sampling. Experiments on a single NVIDIA GTX4090 GPU reveal that although CoMoSVC has a significantly faster inference speed than the state-of-the-art (SOTA) diffusion-based SVC system, it still achieves comparable or superior conversion performance based on both subjective and objective metrics. Audio samples and codes are available at https://comosvc.github.io/.
Weakly-Supervised Emotion Transition Learning for Diverse 3D Co-speech Gesture Generation
Nov 29, 2023Generating vivid and emotional 3D co-speech gestures is crucial for virtual avatar animation in human-machine interaction applications. While the existing methods enable generating the gestures to follow a single emotion label, they overlook that long gesture sequence modeling with emotion transition is more practical in real scenes. In addition, the lack of large-scale available datasets with emotional transition speech and corresponding 3D human gestures also limits the addressing of this task. To fulfill this goal, we first incorporate the ChatGPT-4 and an audio inpainting approach to construct the high-fidelity emotion transition human speeches. Considering obtaining the realistic 3D pose annotations corresponding to the dynamically inpainted emotion transition audio is extremely difficult, we propose a novel weakly supervised training strategy to encourage authority gesture transitions. Specifically, to enhance the coordination of transition gestures w.r.t different emotional ones, we model the temporal association representation between two different emotional gesture sequences as style guidance and infuse it into the transition generation. We further devise an emotion mixture mechanism that provides weak supervision based on a learnable mixed emotion label for transition gestures. Last, we present a keyframe sampler to supply effective initial posture cues in long sequences, enabling us to generate diverse gestures. Extensive experiments demonstrate that our method outperforms the state-of-the-art models constructed by adapting single emotion-conditioned counterparts on our newly defined emotion transition task and datasets.
ChatIllusion: Efficient-Aligning Interleaved Generation ability with Visual Instruction Model
Nov 29, 2023As the capabilities of Large-Language Models (LLMs) become widely recognized, there is an increasing demand for human-machine chat applications. Human interaction with text often inherently invokes mental imagery, an aspect that existing LLM-based chatbots like GPT-4 do not currently emulate, as they are confined to generating text-only content. To bridge this gap, we introduce ChatIllusion, an advanced Generative multimodal large language model (MLLM) that combines the capabilities of LLM with not only visual comprehension but also creativity. Specifically, ChatIllusion integrates Stable Diffusion XL and Llama, which have been fine-tuned on modest image-caption data, to facilitate multiple rounds of illustrated chats. The central component of ChatIllusion is the "GenAdapter," an efficient approach that equips the multimodal language model with capabilities for visual representation, without necessitating modifications to the foundational model. Extensive experiments validate the efficacy of our approach, showcasing its ability to produce diverse and superior-quality image outputs Simultaneously, it preserves semantic consistency and control over the dialogue, significantly enhancing the overall user's quality of experience (QoE). The code is available at https://github.com/litwellchi/ChatIllusion.
Continual Learning with Dirichlet Generative-based Rehearsal
Sep 13, 2023
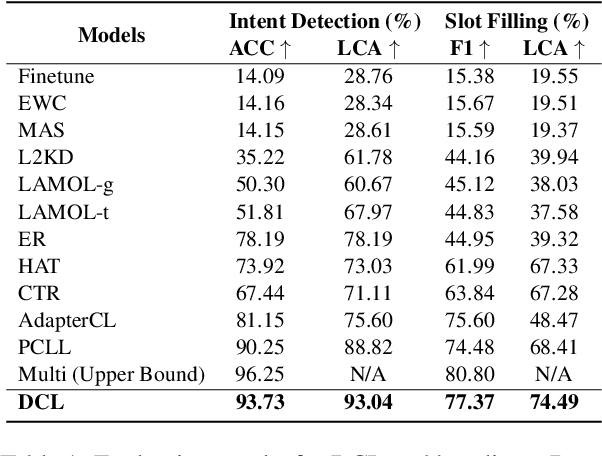


Recent advancements in data-driven task-oriented dialogue systems (ToDs) struggle with incremental learning due to computational constraints and time-consuming issues. Continual Learning (CL) attempts to solve this by avoiding intensive pre-training, but it faces the problem of catastrophic forgetting (CF). While generative-based rehearsal CL methods have made significant strides, generating pseudo samples that accurately reflect the underlying task-specific distribution is still a challenge. In this paper, we present Dirichlet Continual Learning (DCL), a novel generative-based rehearsal strategy for CL. Unlike the traditionally used Gaussian latent variable in the Conditional Variational Autoencoder (CVAE), DCL leverages the flexibility and versatility of the Dirichlet distribution to model the latent prior variable. This enables it to efficiently capture sentence-level features of previous tasks and effectively guide the generation of pseudo samples. In addition, we introduce Jensen-Shannon Knowledge Distillation (JSKD), a robust logit-based knowledge distillation method that enhances knowledge transfer during pseudo sample generation. Our experiments confirm the efficacy of our approach in both intent detection and slot-filling tasks, outperforming state-of-the-art methods.
NAS-FM: Neural Architecture Search for Tunable and Interpretable Sound Synthesis based on Frequency Modulation
May 22, 2023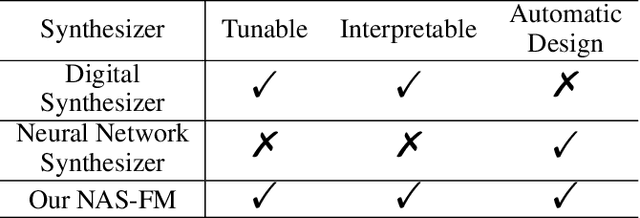

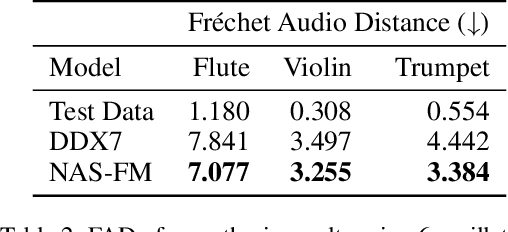
Developing digital sound synthesizers is crucial to the music industry as it provides a low-cost way to produce high-quality sounds with rich timbres. Existing traditional synthesizers often require substantial expertise to determine the overall framework of a synthesizer and the parameters of submodules. Since expert knowledge is hard to acquire, it hinders the flexibility to quickly design and tune digital synthesizers for diverse sounds. In this paper, we propose ``NAS-FM'', which adopts neural architecture search (NAS) to build a differentiable frequency modulation (FM) synthesizer. Tunable synthesizers with interpretable controls can be developed automatically from sounds without any prior expert knowledge and manual operating costs. In detail, we train a supernet with a specifically designed search space, including predicting the envelopes of carriers and modulators with different frequency ratios. An evolutionary search algorithm with adaptive oscillator size is then developed to find the optimal relationship between oscillators and the frequency ratio of FM. Extensive experiments on recordings of different instrument sounds show that our algorithm can build a synthesizer fully automatically, achieving better results than handcrafted synthesizers. Audio samples are available at https://nas-fm.github.io/.
CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model
May 11, 2023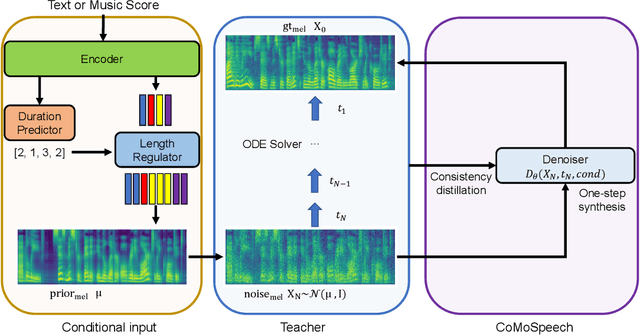
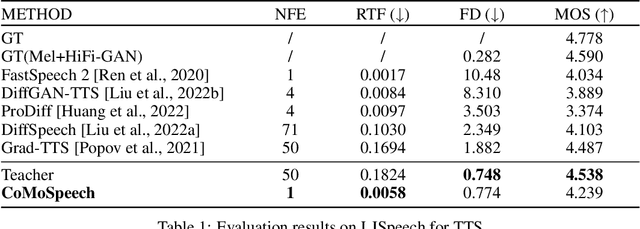
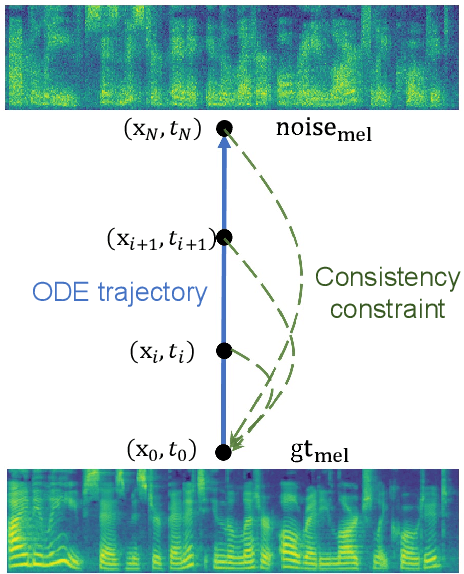
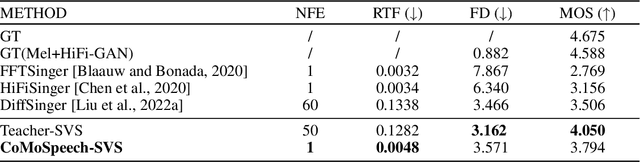
Denoising diffusion probabilistic models (DDPMs) have shown promising performance for speech synthesis. However, a large number of iterative steps are required to achieve high sample quality, which restricts the inference speed. Maintaining sample quality while increasing sampling speed has become a challenging task. In this paper, we propose a "Co"nsistency "Mo"del-based "Speech" synthesis method, CoMoSpeech, which achieve speech synthesis through a single diffusion sampling step while achieving high audio quality. The consistency constraint is applied to distill a consistency model from a well-designed diffusion-based teacher model, which ultimately yields superior performances in the distilled CoMoSpeech. Our experiments show that by generating audio recordings by a single sampling step, the CoMoSpeech achieves an inference speed more than 150 times faster than real-time on a single NVIDIA A100 GPU, which is comparable to FastSpeech2, making diffusion-sampling based speech synthesis truly practical. Meanwhile, objective and subjective evaluations on text-to-speech and singing voice synthesis show that the proposed teacher models yield the best audio quality, and the one-step sampling based CoMoSpeech achieves the best inference speed with better or comparable audio quality to other conventional multi-step diffusion model baselines. Audio samples are available at https://comospeech.github.io/.
Learn to Sing by Listening: Building Controllable Virtual Singer by Unsupervised Learning from Voice Recordings
May 09, 2023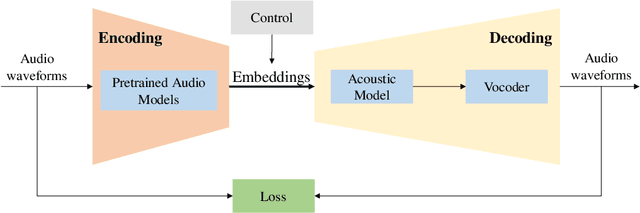

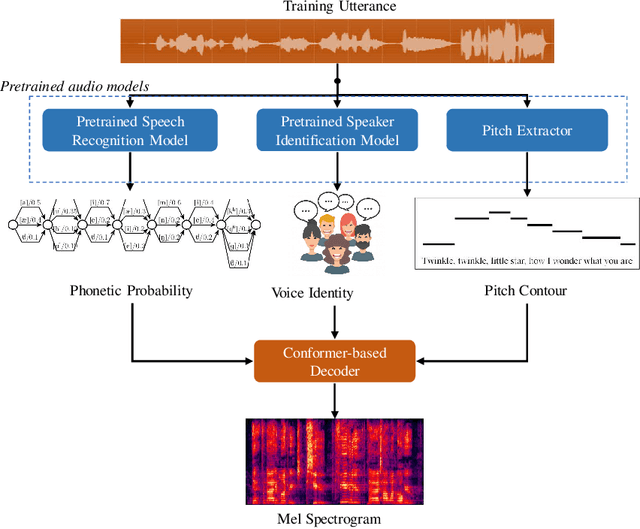
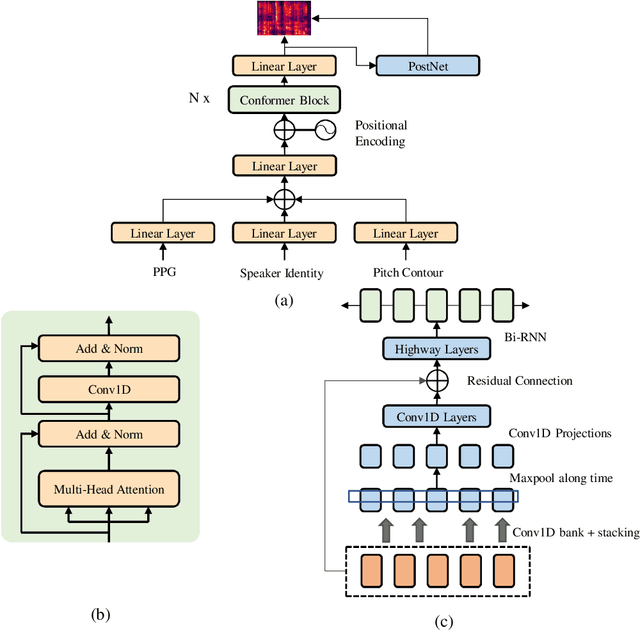
The virtual world is being established in which digital humans are created indistinguishable from real humans. Producing their audio-related capabilities is crucial since voice conveys extensive personal characteristics. We aim to create a controllable audio-form virtual singer; however, supervised modeling and controlling all different factors of the singing voice, such as timbre, tempo, pitch, and lyrics, is extremely difficult since accurately labeling all such information needs enormous labor work. In this paper, we propose a framework that could digitize a person's voice by simply "listening" to the clean voice recordings of any content in a fully unsupervised manner and predict singing voices even only using speaking recordings. A variational auto-encoder (VAE) based framework is developed, which leverages a set of pre-trained models to encode the audio as various hidden embeddings representing different factors of the singing voice, and further decodes the embeddings into raw audio. By manipulating the hidden embeddings for different factors, the resulting singing voices can be controlled, and new virtual singers can also be further generated by interpolating between timbres. Evaluations of different types of experiments demonstrate the proposed method's effectiveness. The proposed method is the critical technique for producing the AI choir, which empowered the human-AI symbiotic orchestra in Hong Kong in July 2022.