 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeiwen Sun
FlashSpeech: Efficient Zero-Shot Speech Synthesis
Apr 25, 2024
Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5\% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.
FusionINN: Invertible Image Fusion for Brain Tumor Monitoring
Apr 02, 2024Image fusion typically employs non-invertible neural networks to merge multiple source images into a single fused image. However, for clinical experts, solely relying on fused images may be insufficient for making diagnostic decisions, as the fusion mechanism blends features from source images, thereby making it difficult to interpret the underlying tumor pathology. We introduce FusionINN, a novel invertible image fusion framework, capable of efficiently generating fused images and also decomposing them back to the source images by solving the inverse of the fusion process. FusionINN guarantees lossless one-to-one pixel mapping by integrating a normally distributed latent image alongside the fused image to facilitate the generative modeling of the decomposition process. To the best of our knowledge, we are the first to investigate the decomposability of fused images, which is particularly crucial for life-sensitive applications such as medical image fusion compared to other tasks like multi-focus or multi-exposure image fusion. Our extensive experimentation validates FusionINN over existing discriminative and generative fusion methods, both subjectively and objectively. Moreover, compared to a recent denoising diffusion-based fusion model, our approach offers faster and qualitatively better fusion results. We also exhibit the clinical utility of our results in aiding disease prognosis.
More than Vanilla Fusion: a Simple, Decoupling-free, Attention Module for Multimodal Fusion Based on Signal Theory
Dec 12, 2023The vanilla fusion methods still dominate a large percentage of mainstream audio-visual tasks. However, the effectiveness of vanilla fusion from a theoretical perspective is still worth discussing. Thus, this paper reconsiders the signal fused in the multimodal case from a bionics perspective and proposes a simple, plug-and-play, attention module for vanilla fusion based on fundamental signal theory and uncertainty theory. In addition, previous work on multimodal dynamic gradient modulation still relies on decoupling the modalities. So, a decoupling-free gradient modulation scheme has been designed in conjunction with the aforementioned attention module, which has various advantages over the decoupled one. Experiment results show that just a few lines of code can achieve up to 2.0% performance improvements to several multimodal classification methods. Finally, quantitative evaluation of other fusion tasks reveals the potential for additional application scenarios.
Learning Audio-Visual embedding for Wild Person Verification
Sep 09, 2022
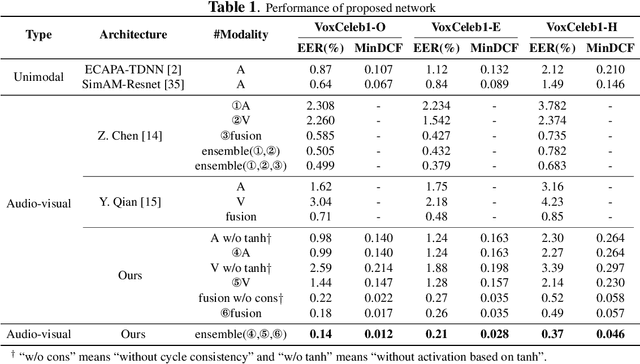
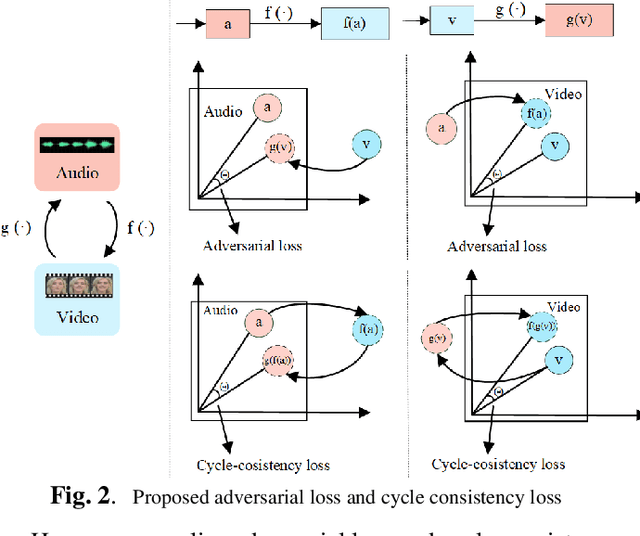
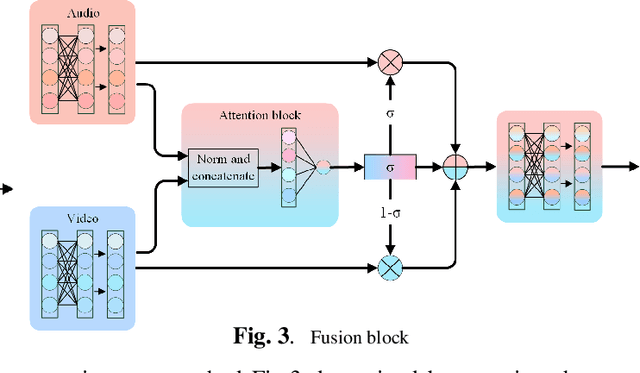
It has already been observed that audio-visual embedding can be extracted from these two modalities to gain robustness for person verification. However, the aggregator that used to generate a single utterance representation from each frame does not seem to be well explored. In this article, we proposed an audio-visual network that considers aggregator from a fusion perspective. We introduced improved attentive statistics pooling for the first time in face verification. Then we find that strong correlation exists between modalities during pooling, so joint attentive pooling is proposed which contains cycle consistency to learn the implicit inter-frame weight. Finally, fuse the modality with a gated attention mechanism. All the proposed models are trained on the VoxCeleb2 dev dataset and the best system obtains 0.18\%, 0.27\%, and 0.49\% EER on three official trail lists of VoxCeleb1 respectively, which is to our knowledge the best-published results for person verification. As an analysis, visualization maps are generated to explain how this system interact between modalities.