 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYifan Zhang
PATE-TripleGAN: Privacy-Preserving Image Synthesis with Gaussian Differential Privacy
Apr 19, 2024
Conditional Generative Adversarial Networks (CGANs) exhibit significant potential in supervised learning model training by virtue of their ability to generate realistic labeled images. However, numerous studies have indicated the privacy leakage risk in CGANs models. The solution DPCGAN, incorporating the differential privacy framework, faces challenges such as heavy reliance on labeled data for model training and potential disruptions to original gradient information due to excessive gradient clipping, making it difficult to ensure model accuracy. To address these challenges, we present a privacy-preserving training framework called PATE-TripleGAN. This framework incorporates a classifier to pre-classify unlabeled data, establishing a three-party min-max game to reduce dependence on labeled data. Furthermore, we present a hybrid gradient desensitization algorithm based on the Private Aggregation of Teacher Ensembles (PATE) framework and Differential Private Stochastic Gradient Descent (DPSGD) method. This algorithm allows the model to retain gradient information more effectively while ensuring privacy protection, thereby enhancing the model's utility. Privacy analysis and extensive experiments affirm that the PATE-TripleGAN model can generate a higher quality labeled image dataset while ensuring the privacy of the training data.
A Progressive Framework of Vision-language Knowledge Distillation and Alignment for Multilingual Scene
Apr 17, 2024Pre-trained vision-language (V-L) models such as CLIP have shown excellent performance in many downstream cross-modal tasks. However, most of them are only applicable to the English context. Subsequent research has focused on this problem and proposed improved models, such as CN-CLIP and AltCLIP, to facilitate their applicability to Chinese and even other languages. Nevertheless, these models suffer from high latency and a large memory footprint in inference, which limits their further deployment on resource-constrained edge devices. In this work, we propose a conceptually simple yet effective multilingual CLIP Compression framework and train a lightweight multilingual vision-language model, called DC-CLIP, for both Chinese and English context. In this framework, we collect high-quality Chinese and English text-image pairs and design two training stages, including multilingual vision-language feature distillation and alignment. During the first stage, lightweight image/text student models are designed to learn robust visual/multilingual textual feature representation ability from corresponding teacher models, respectively. Subsequently, the multilingual vision-language alignment stage enables effective alignment of visual and multilingual textual features to further improve the model's multilingual performance. Comprehensive experiments in zero-shot image classification, conducted based on the ELEVATER benchmark, showcase that DC-CLIP achieves superior performance in the English context and competitive performance in the Chinese context, even with less training data, when compared to existing models of similar parameter magnitude. The evaluation demonstrates the effectiveness of our designed training mechanism.
MEEL: Multi-Modal Event Evolution Learning
Apr 16, 2024Multi-modal Event Reasoning (MMER) endeavors to endow machines with the ability to comprehend intricate event relations across diverse data modalities. MMER is fundamental and underlies a wide broad of applications. Despite extensive instruction fine-tuning, current multi-modal large language models still fall short in such ability. The disparity stems from that existing models are insufficient to capture underlying principles governing event evolution in various scenarios. In this paper, we introduce Multi-Modal Event Evolution Learning (MEEL) to enable the model to grasp the event evolution mechanism, yielding advanced MMER ability. Specifically, we commence with the design of event diversification to gather seed events from a rich spectrum of scenarios. Subsequently, we employ ChatGPT to generate evolving graphs for these seed events. We propose an instruction encapsulation process that formulates the evolving graphs into instruction-tuning data, aligning the comprehension of event reasoning to humans. Finally, we observe that models trained in this way are still struggling to fully comprehend event evolution. In such a case, we propose the guiding discrimination strategy, in which models are trained to discriminate the improper evolution direction. We collect and curate a benchmark M-EV2 for MMER. Extensive experiments on M-EV2 validate the effectiveness of our approach, showcasing competitive performance in open-source multi-modal LLMs.
Practical Applications of Advanced Cloud Services and Generative AI Systems in Medical Image Analysis
Mar 26, 2024The medical field is one of the important fields in the application of artificial intelligence technology. With the explosive growth and diversification of medical data, as well as the continuous improvement of medical needs and challenges, artificial intelligence technology is playing an increasingly important role in the medical field. Artificial intelligence technologies represented by computer vision, natural language processing, and machine learning have been widely penetrated into diverse scenarios such as medical imaging, health management, medical information, and drug research and development, and have become an important driving force for improving the level and quality of medical services.The article explores the transformative potential of generative AI in medical imaging, emphasizing its ability to generate syntheticACM-2 data, enhance images, aid in anomaly detection, and facilitate image-to-image translation. Despite challenges like model complexity, the applications of generative models in healthcare, including Med-PaLM 2 technology, show promising results. By addressing limitations in dataset size and diversity, these models contribute to more accurate diagnoses and improved patient outcomes. However, ethical considerations and collaboration among stakeholders are essential for responsible implementation. Through experiments leveraging GANs to augment brain tumor MRI datasets, the study demonstrates how generative AI can enhance image quality and diversity, ultimately advancing medical diagnostics and patient care.
Dynamic Resource Allocation for Virtual Machine Migration Optimization using Machine Learning
Mar 20, 2024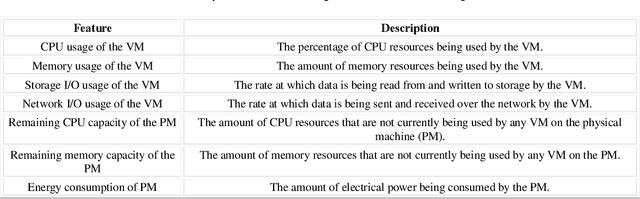
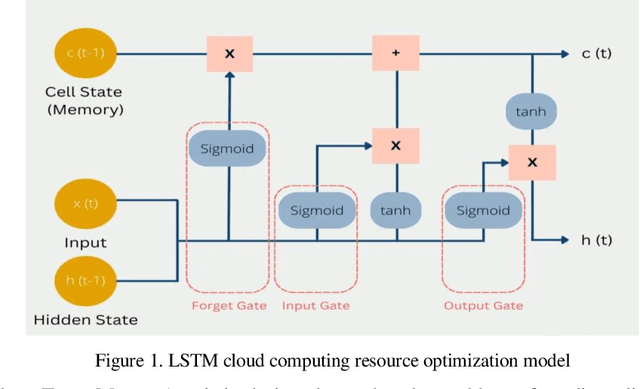
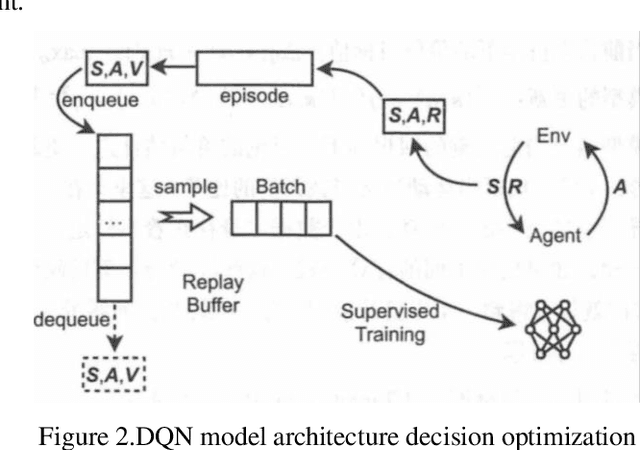
The paragraph is grammatically correct and logically coherent. It discusses the importance of mobile terminal cloud computing migration technology in meeting the demands of evolving computer and cloud computing technologies. It emphasizes the need for efficient data access and storage, as well as the utilization of cloud computing migration technology to prevent additional time delays. The paragraph also highlights the contributions of cloud computing migration technology to expanding cloud computing services. Additionally, it acknowledges the role of virtualization as a fundamental capability of cloud computing while emphasizing that cloud computing and virtualization are not inherently interconnected. Finally, it introduces machine learning-based virtual machine migration optimization and dynamic resource allocation as a critical research direction in cloud computing, citing the limitations of static rules or manual settings in traditional cloud computing environments. Overall, the paragraph effectively communicates the importance of machine learning technology in addressing resource allocation and virtual machine migration challenges in cloud computing.
Uncertainty-Calibrated Test-Time Model Adaptation without Forgetting
Mar 18, 2024
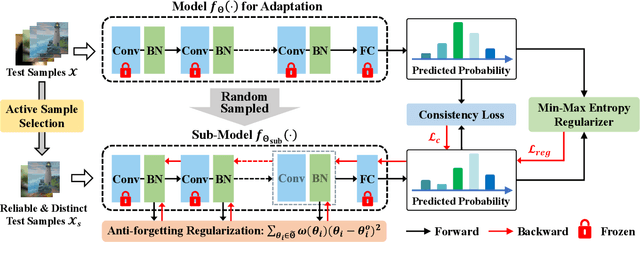
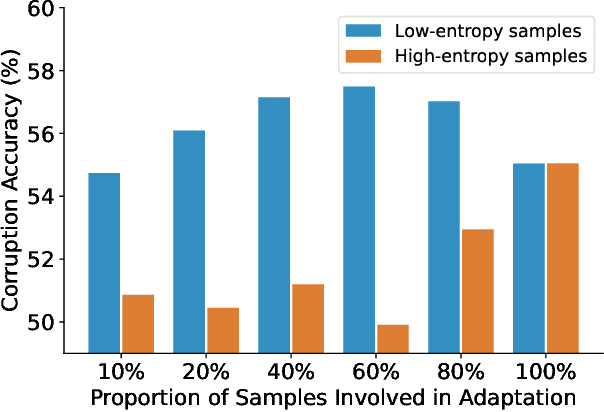
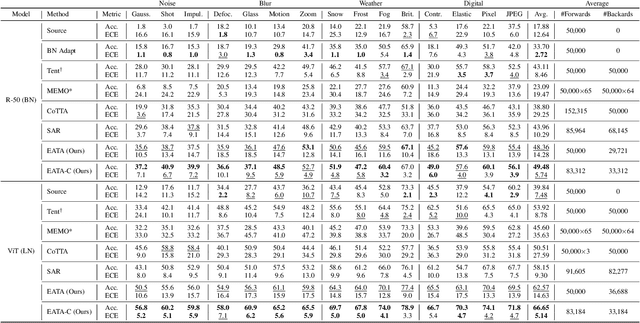
Test-time adaptation (TTA) seeks to tackle potential distribution shifts between training and test data by adapting a given model w.r.t. any test sample. Although recent TTA has shown promising performance, we still face two key challenges: 1) prior methods perform backpropagation for each test sample, resulting in unbearable optimization costs to many applications; 2) while existing TTA can significantly improve the test performance on out-of-distribution data, they often suffer from severe performance degradation on in-distribution data after TTA (known as forgetting). To this end, we have proposed an Efficient Anti-Forgetting Test-Time Adaptation (EATA) method which develops an active sample selection criterion to identify reliable and non-redundant samples for test-time entropy minimization. To alleviate forgetting, EATA introduces a Fisher regularizer estimated from test samples to constrain important model parameters from drastic changes. However, in EATA, the adopted entropy loss consistently assigns higher confidence to predictions even for samples that are underlying uncertain, leading to overconfident predictions. To tackle this, we further propose EATA with Calibration (EATA-C) to separately exploit the reducible model uncertainty and the inherent data uncertainty for calibrated TTA. Specifically, we measure the model uncertainty by the divergence between predictions from the full network and its sub-networks, on which we propose a divergence loss to encourage consistent predictions instead of overconfident ones. To further recalibrate prediction confidence, we utilize the disagreement among predicted labels as an indicator of the data uncertainty, and then devise a min-max entropy regularizer to selectively increase and decrease prediction confidence for different samples. Experiments on image classification and semantic segmentation verify the effectiveness of our methods.
EyeTrans: Merging Human and Machine Attention for Neural Code Summarization
Feb 29, 2024Neural code summarization leverages deep learning models to automatically generate brief natural language summaries of code snippets. The development of Transformer models has led to extensive use of attention during model design. While existing work has primarily and almost exclusively focused on static properties of source code and related structural representations like the Abstract Syntax Tree (AST), few studies have considered human attention, that is, where programmers focus while examining and comprehending code. In this paper, we develop a method for incorporating human attention into machine attention to enhance neural code summarization. To facilitate this incorporation and vindicate this hypothesis, we introduce EyeTrans, which consists of three steps: (1) we conduct an extensive eye-tracking human study to collect and pre-analyze data for model training, (2) we devise a data-centric approach to integrate human attention with machine attention in the Transformer architecture, and (3) we conduct comprehensive experiments on two code summarization tasks to demonstrate the effectiveness of incorporating human attention into Transformers. Integrating human attention leads to an improvement of up to 29.91% in Functional Summarization and up to 6.39% in General Code Summarization performance, demonstrating the substantial benefits of this combination. We further explore performance in terms of robustness and efficiency by creating challenging summarization scenarios in which EyeTrans exhibits interesting properties. We also visualize the attention map to depict the simplifying effect of machine attention in the Transformer by incorporating human attention. This work has the potential to propel AI research in software engineering by introducing more human-centered approaches and data.
Application of Machine Learning Optimization in Cloud Computing Resource Scheduling and Management
Feb 27, 2024In recent years, cloud computing has been widely used. Cloud computing refers to the centralized computing resources, users through the access to the centralized resources to complete the calculation, the cloud computing center will return the results of the program processing to the user. Cloud computing is not only for individual users, but also for enterprise users. By purchasing a cloud server, users do not have to buy a large number of computers, saving computing costs. According to a report by China Economic News Network, the scale of cloud computing in China has reached 209.1 billion yuan. At present, the more mature cloud service providers in China are Ali Cloud, Baidu Cloud, Huawei Cloud and so on. Therefore, this paper proposes an innovative approach to solve complex problems in cloud computing resource scheduling and management using machine learning optimization techniques. Through in-depth study of challenges such as low resource utilization and unbalanced load in the cloud environment, this study proposes a comprehensive solution, including optimization methods such as deep learning and genetic algorithm, to improve system performance and efficiency, and thus bring new breakthroughs and progress in the field of cloud computing resource management.Rational allocation of resources plays a crucial role in cloud computing. In the resource allocation of cloud computing, the cloud computing center has limited cloud resources, and users arrive in sequence. Each user requests the cloud computing center to use a certain number of cloud resources at a specific time.
Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization
Feb 22, 2024Recent language models have demonstrated proficiency in summarizing source code. However, as in many other domains of machine learning, language models of code lack sufficient explainability. Informally, we lack a formulaic or intuitive understanding of what and how models learn from code. Explainability of language models can be partially provided if, as the models learn to produce higher-quality code summaries, they also align in deeming the same code parts important as those identified by human programmers. In this paper, we report negative results from our investigation of explainability of language models in code summarization through the lens of human comprehension. We measure human focus on code using eye-tracking metrics such as fixation counts and duration in code summarization tasks. To approximate language model focus, we employ a state-of-the-art model-agnostic, black-box, perturbation-based approach, SHAP (SHapley Additive exPlanations), to identify which code tokens influence that generation of summaries. Using these settings, we find no statistically significant relationship between language models' focus and human programmers' attention. Furthermore, alignment between model and human foci in this setting does not seem to dictate the quality of the LLM-generated summaries. Our study highlights an inability to align human focus with SHAP-based model focus measures. This result calls for future investigation of multiple open questions for explainable language models for code summarization and software engineering tasks in general, including the training mechanisms of language models for code, whether there is an alignment between human and model attention on code, whether human attention can improve the development of language models, and what other model focus measures are appropriate for improving explainability.