 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToby Jia-Jun Li
EyeTrans: Merging Human and Machine Attention for Neural Code Summarization
Feb 29, 2024




Neural code summarization leverages deep learning models to automatically generate brief natural language summaries of code snippets. The development of Transformer models has led to extensive use of attention during model design. While existing work has primarily and almost exclusively focused on static properties of source code and related structural representations like the Abstract Syntax Tree (AST), few studies have considered human attention, that is, where programmers focus while examining and comprehending code. In this paper, we develop a method for incorporating human attention into machine attention to enhance neural code summarization. To facilitate this incorporation and vindicate this hypothesis, we introduce EyeTrans, which consists of three steps: (1) we conduct an extensive eye-tracking human study to collect and pre-analyze data for model training, (2) we devise a data-centric approach to integrate human attention with machine attention in the Transformer architecture, and (3) we conduct comprehensive experiments on two code summarization tasks to demonstrate the effectiveness of incorporating human attention into Transformers. Integrating human attention leads to an improvement of up to 29.91% in Functional Summarization and up to 6.39% in General Code Summarization performance, demonstrating the substantial benefits of this combination. We further explore performance in terms of robustness and efficiency by creating challenging summarization scenarios in which EyeTrans exhibits interesting properties. We also visualize the attention map to depict the simplifying effect of machine attention in the Transformer by incorporating human attention. This work has the potential to propel AI research in software engineering by introducing more human-centered approaches and data.
Human Still Wins over LLM: An Empirical Study of Active Learning on Domain-Specific Annotation Tasks
Nov 16, 2023Large Language Models (LLMs) have demonstrated considerable advances, and several claims have been made about their exceeding human performance. However, in real-world tasks, domain knowledge is often required. Low-resource learning methods like Active Learning (AL) have been proposed to tackle the cost of domain expert annotation, raising this question: Can LLMs surpass compact models trained with expert annotations in domain-specific tasks? In this work, we conduct an empirical experiment on four datasets from three different domains comparing SOTA LLMs with small models trained on expert annotations with AL. We found that small models can outperform GPT-3.5 with a few hundreds of labeled data, and they achieve higher or similar performance with GPT-4 despite that they are hundreds time smaller. Based on these findings, we posit that LLM predictions can be used as a warmup method in real-world applications and human experts remain indispensable in tasks involving data annotation driven by domain-specific knowledge.
UI Layout Generation with LLMs Guided by UI Grammar
Oct 24, 2023The recent advances in Large Language Models (LLMs) have stimulated interest among researchers and industry professionals, particularly in their application to tasks concerning mobile user interfaces (UIs). This position paper investigates the use of LLMs for UI layout generation. Central to our exploration is the introduction of UI grammar -- a novel approach we proposed to represent the hierarchical structure inherent in UI screens. The aim of this approach is to guide the generative capacities of LLMs more effectively and improve the explainability and controllability of the process. Initial experiments conducted with GPT-4 showed the promising capability of LLMs to produce high-quality user interfaces via in-context learning. Furthermore, our preliminary comparative study suggested the potential of the grammar-based approach in improving the quality of generative results in specific aspects.
Structured Generation and Exploration of Design Space with Large Language Models for Human-AI Co-Creation
Oct 23, 2023Thanks to their generative capabilities, large language models (LLMs) have become an invaluable tool for creative processes. These models have the capacity to produce hundreds and thousands of visual and textual outputs, offering abundant inspiration for creative endeavors. But are we harnessing their full potential? We argue that current interaction paradigms fall short, guiding users towards rapid convergence on a limited set of ideas, rather than empowering them to explore the vast latent design space in generative models. To address this limitation, we propose a framework that facilitates the structured generation of design space in which users can seamlessly explore, evaluate, and synthesize a multitude of responses. We demonstrate the feasibility and usefulness of this framework through the design and development of an interactive system, Luminate, and a user study with 8 professional writers. Our work advances how we interact with LLMs for creative tasks, introducing a way to harness the creative potential of LLMs.
Empowering LLM to use Smartphone for Intelligent Task Automation
Sep 09, 2023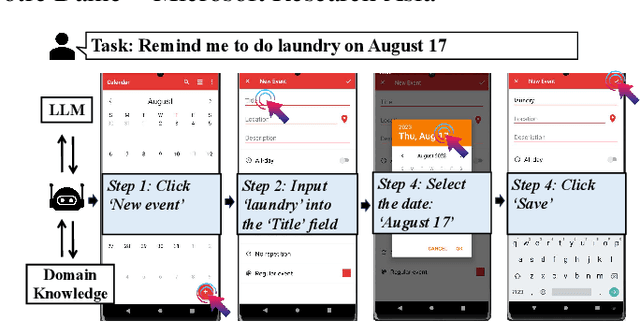

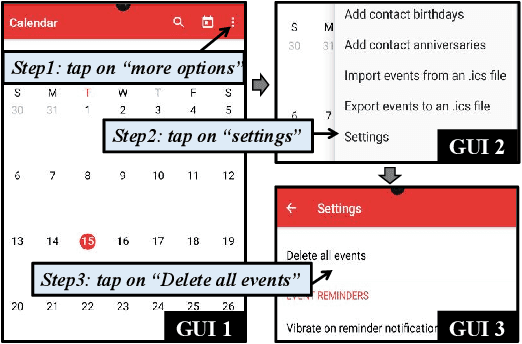
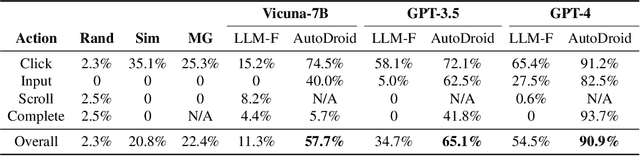
Mobile task automation is an attractive technique that aims to enable voice-based hands-free user interaction with smartphones. However, existing approaches suffer from poor scalability due to the limited language understanding ability and the non-trivial manual efforts required from developers or end-users. The recent advance of large language models (LLMs) in language understanding and reasoning inspires us to rethink the problem from a model-centric perspective, where task preparation, comprehension, and execution are handled by a unified language model. In this work, we introduce AutoDroid, a mobile task automation system that can handle arbitrary tasks on any Android application without manual efforts. The key insight is to combine the commonsense knowledge of LLMs and domain-specific knowledge of apps through automated dynamic analysis. The main components include a functionality-aware UI representation method that bridges the UI with the LLM, exploration-based memory injection techniques that augment the app-specific domain knowledge of LLM, and a multi-granularity query optimization module that reduces the cost of model inference. We integrate AutoDroid with off-the-shelf LLMs including online GPT-4/GPT-3.5 and on-device Vicuna, and evaluate its performance on a new benchmark for memory-augmented Android task automation with 158 common tasks. The results demonstrated that AutoDroid is able to precisely generate actions with an accuracy of 90.9%, and complete tasks with a success rate of 71.3%, outperforming the GPT-4-powered baselines by 36.4% and 39.7%. The demo, benchmark suites, and source code of AutoDroid will be released at url{https://autodroid-sys.github.io/}.
Interactive Text-to-SQL Generation via Editable Step-by-Step Explanations
May 12, 2023



Relational databases play an important role in this Big Data era. However, it is challenging for non-experts to fully unleash the analytical power of relational databases, since they are not familiar with database languages such as SQL. Many techniques have been proposed to automatically generate SQL from natural language, but they suffer from two issues: (1) they still make many mistakes, particularly for complex queries, and (2) they do not provide a flexible way for non-expert users to validate and refine the incorrect queries. To address these issues, we introduce a new interaction mechanism that allows users directly edit a step-by-step explanation of an incorrect SQL to fix SQL errors. Experiments on the Spider benchmark show that our approach outperforms three SOTA approaches by at least 31.6% in terms of execution accuracy. A user study with 24 participants further shows that our approach helped users solve significantly more SQL tasks with less time and higher confidence, demonstrating its potential to expand access to databases, particularly for non-experts.
VISAR: A Human-AI Argumentative Writing Assistant with Visual Programming and Rapid Draft Prototyping
Apr 16, 2023



In argumentative writing, writers must brainstorm hierarchical writing goals, ensure the persuasiveness of their arguments, and revise and organize their plans through drafting. Recent advances in large language models (LLMs) have made interactive text generation through a chat interface (e.g., ChatGPT) possible. However, this approach often neglects implicit writing context and user intent, lacks support for user control and autonomy, and provides limited assistance for sensemaking and revising writing plans. To address these challenges, we introduce VISAR, an AI-enabled writing assistant system designed to help writers brainstorm and revise hierarchical goals within their writing context, organize argument structures through synchronized text editing and visual programming, and enhance persuasiveness with argumentation spark recommendations. VISAR allows users to explore, experiment with, and validate their writing plans using automatic draft prototyping. A controlled lab study confirmed the usability and effectiveness of VISAR in facilitating the argumentative writing planning process.
A Bottom-Up End-User Intelligent Assistant Approach to Empower Gig Workers against AI Inequality
Apr 29, 2022

The growing inequality in gig work between workers and platforms has become a critical social issue as gig work plays an increasingly prominent role in the future of work. The AI inequality is caused by (1) the technology divide in who has access to AI technologies in gig work; and (2) the data divide in who owns the data in gig work leads to unfair working conditions, growing pay gap, neglect of workers' diverse preferences, and workers' lack of trust in the platforms. In this position paper, we argue that a bottom-up approach that empowers individual workers to access AI-enabled work planning support and share data among a group of workers through a network of end-user-programmable intelligent assistants is a practical way to bridge AI inequality in gig work under the current paradigm of privately owned platforms. This position paper articulates a set of research challenges, potential approaches, and community engagement opportunities, seeking to start a dialogue on this important research topic in the interdisciplinary CHIWORK community.
Fantastic Questions and Where to Find Them: FairytaleQA -- An Authentic Dataset for Narrative Comprehension
Mar 26, 2022



Question answering (QA) is a fundamental means to facilitate assessment and training of narrative comprehension skills for both machines and young children, yet there is scarcity of high-quality QA datasets carefully designed to serve this purpose. In particular, existing datasets rarely distinguish fine-grained reading skills, such as the understanding of varying narrative elements. Drawing on the reading education research, we introduce FairytaleQA, a dataset focusing on narrative comprehension of kindergarten to eighth-grade students. Generated by educational experts based on an evidence-based theoretical framework, FairytaleQA consists of 10,580 explicit and implicit questions derived from 278 children-friendly stories, covering seven types of narrative elements or relations. Our dataset is valuable in two folds: First, we ran existing QA models on our dataset and confirmed that this annotation helps assess models' fine-grained learning skills. Second, the dataset supports question generation (QG) task in the education domain. Through benchmarking with QG models, we show that the QG model trained on FairytaleQA is capable of asking high-quality and more diverse questions.
StoryBuddy: A Human-AI Collaborative Chatbot for Parent-Child Interactive Storytelling with Flexible Parental Involvement
Feb 13, 2022



Despite its benefits for children's skill development and parent-child bonding, many parents do not often engage in interactive storytelling by having story-related dialogues with their child due to limited availability or challenges in coming up with appropriate questions. While recent advances made AI generation of questions from stories possible, the fully-automated approach excludes parent involvement, disregards educational goals, and underoptimizes for child engagement. Informed by need-finding interviews and participatory design (PD) results, we developed StoryBuddy, an AI-enabled system for parents to create interactive storytelling experiences. StoryBuddy's design highlighted the need for accommodating dynamic user needs between the desire for parent involvement and parent-child bonding and the goal of minimizing parent intervention when busy. The PD revealed varied assessment and educational goals of parents, which StoryBuddy addressed by supporting configuring question types and tracking child progress. A user study validated StoryBuddy's usability and suggested design insights for future parent-AI collaboration systems.