 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYun Wang
Gen4DS: Workshop on Data Storytelling in an Era of Generative AI
Apr 06, 2024
Storytelling is an ancient and precious human ability that has been rejuvenated in the digital age. Over the last decade, there has been a notable surge in the recognition and application of data storytelling, both in academia and industry. Recently, the rapid development of generative AI has brought new opportunities and challenges to this field, sparking numerous new questions. These questions may not necessarily be quickly transformed into papers, but we believe it is necessary to promptly discuss them to help the community better clarify important issues and research agendas for the future. We thus invite you to join our workshop (Gen4DS) to discuss questions such as: How can generative AI facilitate the creation of data stories? How might generative AI alter the workflow of data storytellers? What are the pitfalls and risks of incorporating AI in storytelling? We have designed both paper presentations and interactive activities (including hands-on creation, group discussion pods, and debates on controversial issues) for the workshop. We hope that participants will learn about the latest advances and pioneering work in data storytelling, engage in critical conversations with each other, and have an enjoyable, unforgettable, and meaningful experience at the event.
NeuroPictor: Refining fMRI-to-Image Reconstruction via Multi-individual Pretraining and Multi-level Modulation
Mar 27, 2024Recent fMRI-to-image approaches mainly focused on associating fMRI signals with specific conditions of pre-trained diffusion models. These approaches, while producing high-quality images, capture only a limited aspect of the complex information in fMRI signals and offer little detailed control over image creation. In contrast, this paper proposes to directly modulate the generation process of diffusion models using fMRI signals. Our approach, NeuroPictor, divides the fMRI-to-image process into three steps: i) fMRI calibrated-encoding, to tackle multi-individual pre-training for a shared latent space to minimize individual difference and enable the subsequent cross-subject training; ii) fMRI-to-image cross-subject pre-training, perceptually learning to guide diffusion model with high- and low-level conditions across different individuals; iii) fMRI-to-image single-subject refining, similar with step ii but focus on adapting to particular individual. NeuroPictor extracts high-level semantic features from fMRI signals that characterizing the visual stimulus and incrementally fine-tunes the diffusion model with a low-level manipulation network to provide precise structural instructions. By training with over 60,000 fMRI-image pairs from various individuals, our model enjoys superior fMRI-to-image decoding capacity, particularly in the within-subject setting, as evidenced in benchmark datasets. Project page: https://jingyanghuo.github.io/neuropictor/.
A Sampling-based Framework for Hypothesis Testing on Large Attributed Graphs
Mar 20, 2024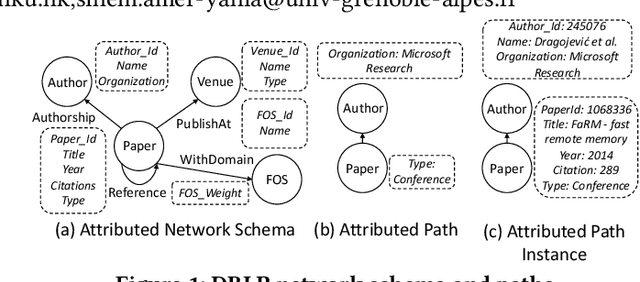
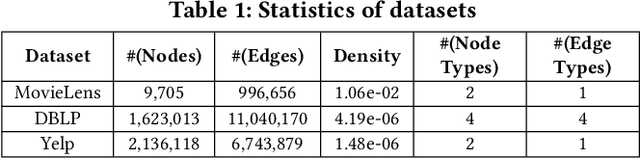

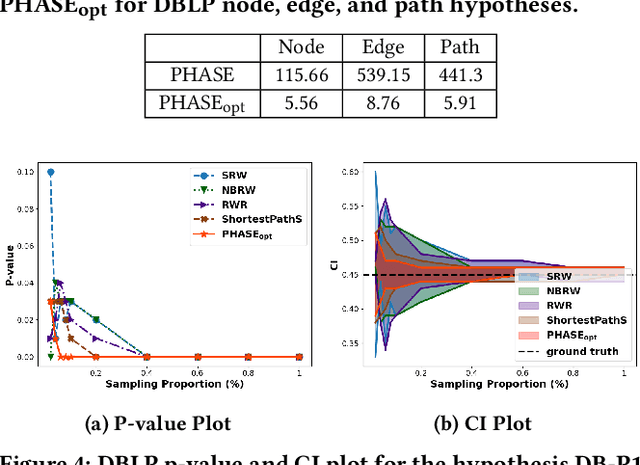
Hypothesis testing is a statistical method used to draw conclusions about populations from sample data, typically represented in tables. With the prevalence of graph representations in real-life applications, hypothesis testing in graphs is gaining importance. In this work, we formalize node, edge, and path hypotheses in attributed graphs. We develop a sampling-based hypothesis testing framework, which can accommodate existing hypothesis-agnostic graph sampling methods. To achieve accurate and efficient sampling, we then propose a Path-Hypothesis-Aware SamplEr, PHASE, an m- dimensional random walk that accounts for the paths specified in a hypothesis. We further optimize its time efficiency and propose PHASEopt. Experiments on real datasets demonstrate the ability of our framework to leverage common graph sampling methods for hypothesis testing, and the superiority of hypothesis-aware sampling in terms of accuracy and time efficiency.
Tree-Regularized Tabular Embeddings
Mar 01, 2024

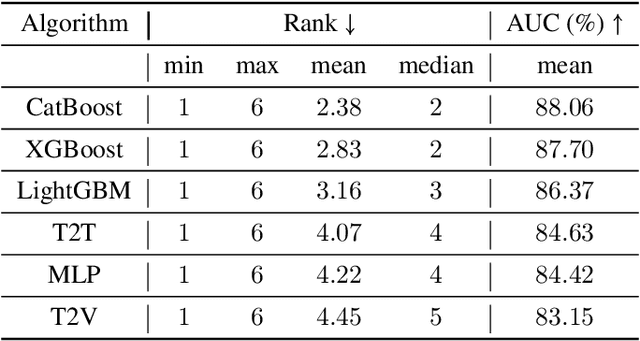
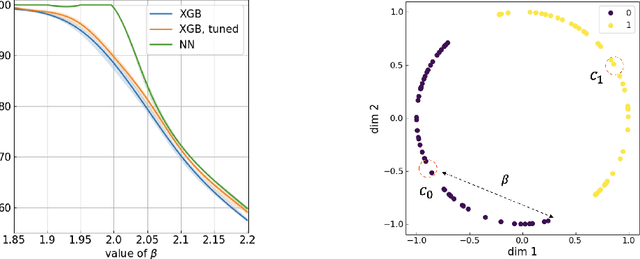
Tabular neural network (NN) has attracted remarkable attentions and its recent advances have gradually narrowed the performance gap with respect to tree-based models on many public datasets. While the mainstreams focus on calibrating NN to fit tabular data, we emphasize the importance of homogeneous embeddings and alternately concentrate on regularizing tabular inputs through supervised pretraining. Specifically, we extend a recent work (DeepTLF) and utilize the structure of pretrained tree ensembles to transform raw variables into a single vector (T2V), or an array of tokens (T2T). Without loss of space efficiency, these binarized embeddings can be consumed by canonical tabular NN with fully-connected or attention-based building blocks. Through quantitative experiments on 88 OpenML datasets with binary classification task, we validated that the proposed tree-regularized representation not only tapers the difference with respect to tree-based models, but also achieves on-par and better performance when compared with advanced NN models. Most importantly, it possesses better robustness and can be easily scaled and generalized as standalone encoder for tabular modality. Codes: https://github.com/milanlx/tree-regularized-embedding.
A Literature Review on Fetus Brain Motion Correction in MRI
Jan 30, 2024This paper provides a comprehensive review of the latest advancements in fetal motion correction in MRI. We delve into various contemporary methodologies and technological advancements aimed at overcoming these challenges. It includes traditional 3D fetal MRI correction methods like Slice to Volume Registration (SVR), deep learning-based techniques such as Convolutional Neural Networks (CNNs), Long Short-Term Memory (LSTM) Networks, Transformers, Generative Adversarial Networks (GANs) and most recent advancements of Diffusion Models. The insights derived from this literature review reflect a thorough understanding of both the technical intricacies and practical implications of fetal motion in MRI studies, offering a reasoned perspective on potential solutions and future improvements in this field.
Multi-Task Learning for Front-End Text Processing in TTS
Jan 12, 2024We propose a multi-task learning (MTL) model for jointly performing three tasks that are commonly solved in a text-to-speech (TTS) front-end: text normalization (TN), part-of-speech (POS) tagging, and homograph disambiguation (HD). Our framework utilizes a tree-like structure with a trunk that learns shared representations, followed by separate task-specific heads. We further incorporate a pre-trained language model to utilize its built-in lexical and contextual knowledge, and study how to best use its embeddings so as to most effectively benefit our multi-task model. Through task-wise ablations, we show that our full model trained on all three tasks achieves the strongest overall performance compared to models trained on individual or sub-combinations of tasks, confirming the advantages of our MTL framework. Finally, we introduce a new HD dataset containing a balanced number of sentences in diverse contexts for a variety of homographs and their pronunciations. We demonstrate that incorporating this dataset into training significantly improves HD performance over only using a commonly used, but imbalanced, pre-existing dataset.
PanGu-$π$: Enhancing Language Model Architectures via Nonlinearity Compensation
Dec 27, 2023The recent trend of large language models (LLMs) is to increase the scale of both model size (\aka the number of parameters) and dataset to achieve better generative ability, which is definitely proved by a lot of work such as the famous GPT and Llama. However, large models often involve massive computational costs, and practical applications cannot afford such high prices. However, the method of constructing a strong model architecture for LLMs is rarely discussed. We first analyze the state-of-the-art language model architectures and observe the feature collapse problem. Based on the theoretical analysis, we propose that the nonlinearity is also very important for language models, which is usually studied in convolutional neural networks for vision tasks. The series informed activation function is then introduced with tiny calculations that can be ignored, and an augmented shortcut is further used to enhance the model nonlinearity. We then demonstrate that the proposed approach is significantly effective for enhancing the model nonlinearity through carefully designed ablations; thus, we present a new efficient model architecture for establishing modern, namely, PanGu-$\pi$. Experiments are then conducted using the same dataset and training strategy to compare PanGu-$\pi$ with state-of-the-art LLMs. The results show that PanGu-$\pi$-7B can achieve a comparable performance to that of benchmarks with about 10\% inference speed-up, and PanGu-$\pi$-1B can achieve state-of-the-art performance in terms of accuracy and efficiency. In addition, we have deployed PanGu-$\pi$-7B in the high-value domains of finance and law, developing an LLM named YunShan for practical application. The results show that YunShan can surpass other models with similar scales on benchmarks.
MinD-3D: Reconstruct High-quality 3D objects in Human Brain
Dec 12, 2023In this paper, we introduce Recon3DMind, a groundbreaking task focused on reconstructing 3D visuals from Functional Magnetic Resonance Imaging (fMRI) signals. This represents a major step forward in cognitive neuroscience and computer vision. To support this task, we present the fMRI-Shape dataset, utilizing 360-degree view videos of 3D objects for comprehensive fMRI signal capture. Containing 55 categories of common objects from daily life, this dataset will bolster future research endeavors. We also propose MinD-3D, a novel and effective three-stage framework that decodes and reconstructs the brain's 3D visual information from fMRI signals. This method starts by extracting and aggregating features from fMRI frames using a neuro-fusion encoder, then employs a feature bridge diffusion model to generate corresponding visual features, and ultimately recovers the 3D object through a generative transformer decoder. Our experiments demonstrate that this method effectively extracts features that are valid and highly correlated with visual regions of interest (ROIs) in fMRI signals. Notably, it not only reconstructs 3D objects with high semantic relevance and spatial similarity but also significantly deepens our understanding of the human brain's 3D visual processing capabilities. Project page at: https://jianxgao.github.io/MinD-3D.
Human Still Wins over LLM: An Empirical Study of Active Learning on Domain-Specific Annotation Tasks
Nov 16, 2023Large Language Models (LLMs) have demonstrated considerable advances, and several claims have been made about their exceeding human performance. However, in real-world tasks, domain knowledge is often required. Low-resource learning methods like Active Learning (AL) have been proposed to tackle the cost of domain expert annotation, raising this question: Can LLMs surpass compact models trained with expert annotations in domain-specific tasks? In this work, we conduct an empirical experiment on four datasets from three different domains comparing SOTA LLMs with small models trained on expert annotations with AL. We found that small models can outperform GPT-3.5 with a few hundreds of labeled data, and they achieve higher or similar performance with GPT-4 despite that they are hundreds time smaller. Based on these findings, we posit that LLM predictions can be used as a warmup method in real-world applications and human experts remain indispensable in tasks involving data annotation driven by domain-specific knowledge.
fMRI-PTE: A Large-scale fMRI Pretrained Transformer Encoder for Multi-Subject Brain Activity Decoding
Nov 01, 2023The exploration of brain activity and its decoding from fMRI data has been a longstanding pursuit, driven by its potential applications in brain-computer interfaces, medical diagnostics, and virtual reality. Previous approaches have primarily focused on individual subject analysis, highlighting the need for a more universal and adaptable framework, which is the core motivation behind our work. In this work, we propose fMRI-PTE, an innovative auto-encoder approach for fMRI pre-training, with a focus on addressing the challenges of varying fMRI data dimensions due to individual brain differences. Our approach involves transforming fMRI signals into unified 2D representations, ensuring consistency in dimensions and preserving distinct brain activity patterns. We introduce a novel learning strategy tailored for pre-training 2D fMRI images, enhancing the quality of reconstruction. fMRI-PTE's adaptability with image generators enables the generation of well-represented fMRI features, facilitating various downstream tasks, including within-subject and cross-subject brain activity decoding. Our contributions encompass introducing fMRI-PTE, innovative data transformation, efficient training, a novel learning strategy, and the universal applicability of our approach. Extensive experiments validate and support our claims, offering a promising foundation for further research in this domain.