 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShun Zhang
RoNID: New Intent Discovery with Generated-Reliable Labels and Cluster-friendly Representations
Apr 13, 2024
New Intent Discovery (NID) strives to identify known and reasonably deduce novel intent groups in the open-world scenario. But current methods face issues with inaccurate pseudo-labels and poor representation learning, creating a negative feedback loop that degrades overall model performance, including accuracy and the adjusted rand index. To address the aforementioned challenges, we propose a Robust New Intent Discovery (RoNID) framework optimized by an EM-style method, which focuses on constructing reliable pseudo-labels and obtaining cluster-friendly discriminative representations. RoNID comprises two main modules: reliable pseudo-label generation module and cluster-friendly representation learning module. Specifically, the pseudo-label generation module assigns reliable synthetic labels by solving an optimal transport problem in the E-step, which effectively provides high-quality supervised signals for the input of the cluster-friendly representation learning module. To learn cluster-friendly representation with strong intra-cluster compactness and large inter-cluster separation, the representation learning module combines intra-cluster and inter-cluster contrastive learning in the M-step to feed more discriminative features into the generation module. RoNID can be performed iteratively to ultimately yield a robust model with reliable pseudo-labels and cluster-friendly representations. Experimental results on multiple benchmarks demonstrate our method brings substantial improvements over previous state-of-the-art methods by a large margin of +1~+4 points.
New Intent Discovery with Attracting and Dispersing Prototype
Mar 25, 2024New Intent Discovery (NID) aims to recognize known and infer new intent categories with the help of limited labeled and large-scale unlabeled data. The task is addressed as a feature-clustering problem and recent studies augment instance representation. However, existing methods fail to capture cluster-friendly representations, since they show less capability to effectively control and coordinate within-cluster and between-cluster distances. Tailored to the NID problem, we propose a Robust and Adaptive Prototypical learning (RAP) framework for globally distinct decision boundaries for both known and new intent categories. Specifically, a robust prototypical attracting learning (RPAL) method is designed to compel instances to gravitate toward their corresponding prototype, achieving greater within-cluster compactness. To attain larger between-cluster separation, another adaptive prototypical dispersing learning (APDL) method is devised to maximize the between-cluster distance from the prototype-to-prototype perspective. Experimental results evaluated on three challenging benchmarks (CLINC, BANKING, and StackOverflow) of our method with better cluster-friendly representation demonstrate that RAP brings in substantial improvements over the current state-of-the-art methods (even large language model) by a large margin (average +5.5% improvement).
STAR-RIS Aided Integrated Sensing and Communication over High Mobility Scenario
Mar 18, 2024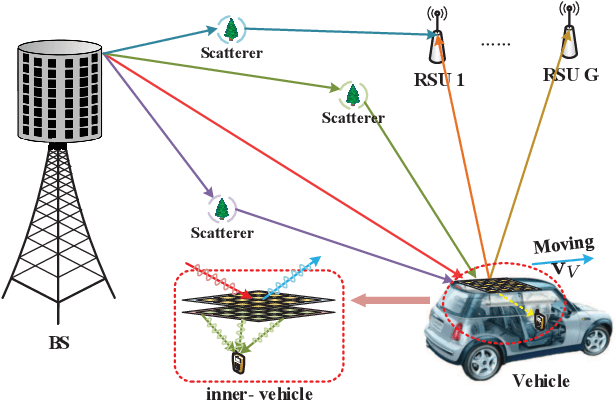
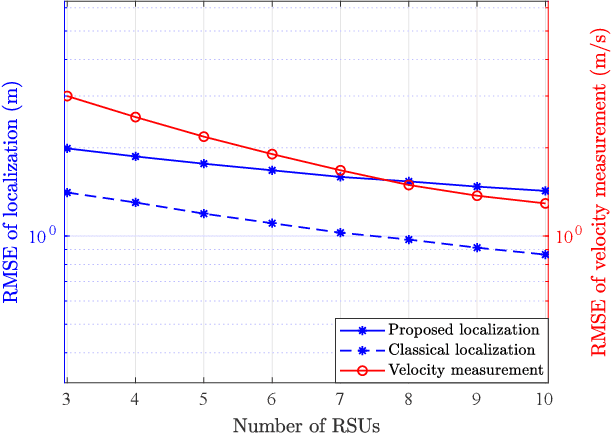
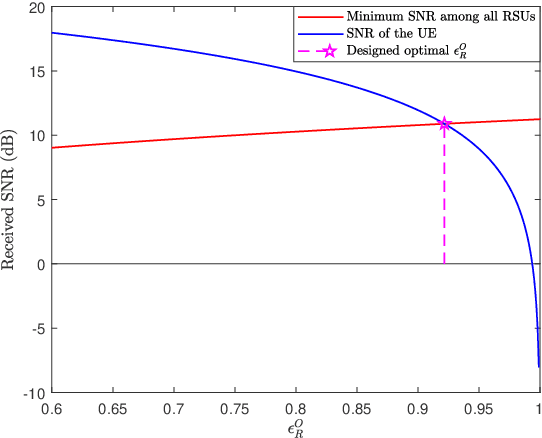
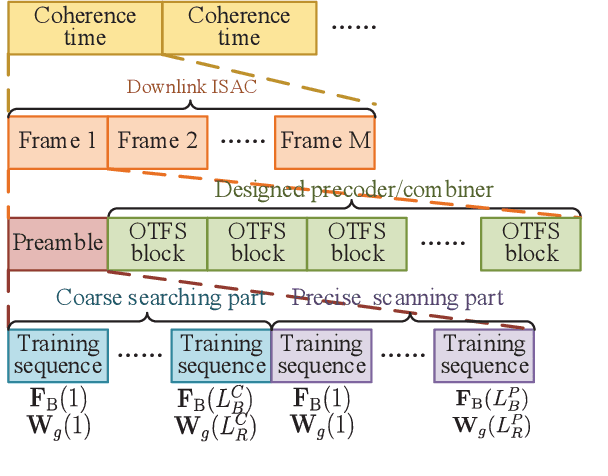
Integrated sensing and communication (ISAC) has become a promising technology for future communication system. In this paper, we consider a millimeter wave system over high mobility scenario, and propose a novel simultaneous transmission and reflection reconfigurable intelligent surface (STAR-RIS) aided ISAC scheme. To improve the communication service of the in-vehicle user equipment (UE) and simultaneously track and sense the vehicle with the help of nearby roadside units (RSUs), a STAR-RIS is equipped on the outside surface of the vehicle. Firstly, an efficient transmission structure is developed, where a number of training sequences with orthogonal precoders and combiners are respectively utilized at BS and RSUs for channel parameter extraction. Then, the near-field static channel model between the STAR-RIS and in-vehicle UE as well as the far-field time-frequency selective BS-RIS-RSUs channel model are characterized. By utilizing the multidimensional orthogonal matching pursuit (MOMP) algorithm, the cascaded channel parameters of the BS-RIS-RSUs links can be obtained at the RSUs. Thus, the vehicle localization and its velocity measurement can be acquired by jointly utilizing these extracted cascaded channel parameters of all RSUs. Note that the MOMP algorithm can be further utilized to extract the channel parameters of the BS-RIS-UE link for communication. With the help of sensing results, the phase shifts of the STAR-RIS are delicately designed, which can significantly improve the received signal strength for both the RSUs and the in-vehicle UE, and can finally enhance the sensing and communication performance. Moreover, the trade-off for sensing and communication is designed by optimizing the energy splitting factors of the STAR-RIS. Finally, simulation results are provided to validate the feasibility and effectiveness of our proposed STAR-RIS aided ISAC scheme.
C-ICL: Contrastive In-context Learning for Information Extraction
Feb 17, 2024Recently, there has been increasing interest in exploring the capabilities of advanced large language models (LLMs) in the field of information extraction (IE), specifically focusing on tasks related to named entity recognition (NER) and relation extraction (RE). Although researchers are exploring the use of few-shot information extraction through in-context learning with LLMs, they tend to focus only on using correct or positive examples for demonstration, neglecting the potential value of incorporating incorrect or negative examples into the learning process. In this paper, we present c-ICL, a novel few-shot technique that leverages both correct and incorrect sample constructions to create in-context learning demonstrations. This approach enhances the ability of LLMs to extract entities and relations by utilizing prompts that incorporate not only the positive samples but also the reasoning behind them. This method allows for the identification and correction of potential interface errors. Specifically, our proposed method taps into the inherent contextual information and valuable information in hard negative samples and the nearest positive neighbors to the test and then applies the in-context learning demonstrations based on LLMs. Our experiments on various datasets indicate that c-ICL outperforms previous few-shot in-context learning methods, delivering substantial enhancements in performance across a broad spectrum of related tasks. These improvements are noteworthy, showcasing the versatility of our approach in miscellaneous scenarios.
Improving Reinforcement Learning from Human Feedback with Efficient Reward Model Ensemble
Jan 30, 2024Reinforcement Learning from Human Feedback (RLHF) is a widely adopted approach for aligning large language models with human values. However, RLHF relies on a reward model that is trained with a limited amount of human preference data, which could lead to inaccurate predictions. As a result, RLHF may produce outputs that are misaligned with human values. To mitigate this issue, we contribute a reward ensemble method that allows the reward model to make more accurate predictions. As using an ensemble of large language model-based reward models can be computationally and resource-expensive, we explore efficient ensemble methods including linear-layer ensemble and LoRA-based ensemble. Empirically, we run Best-of-$n$ and Proximal Policy Optimization with our ensembled reward models, and verify that our ensemble methods help improve the alignment performance of RLHF outputs.
Multi-Task Learning for Front-End Text Processing in TTS
Jan 12, 2024We propose a multi-task learning (MTL) model for jointly performing three tasks that are commonly solved in a text-to-speech (TTS) front-end: text normalization (TN), part-of-speech (POS) tagging, and homograph disambiguation (HD). Our framework utilizes a tree-like structure with a trunk that learns shared representations, followed by separate task-specific heads. We further incorporate a pre-trained language model to utilize its built-in lexical and contextual knowledge, and study how to best use its embeddings so as to most effectively benefit our multi-task model. Through task-wise ablations, we show that our full model trained on all three tasks achieves the strongest overall performance compared to models trained on individual or sub-combinations of tasks, confirming the advantages of our MTL framework. Finally, we introduce a new HD dataset containing a balanced number of sentences in diverse contexts for a variety of homographs and their pronunciations. We demonstrate that incorporating this dataset into training significantly improves HD performance over only using a commonly used, but imbalanced, pre-existing dataset.
Adaptive Online Replanning with Diffusion Models
Oct 14, 2023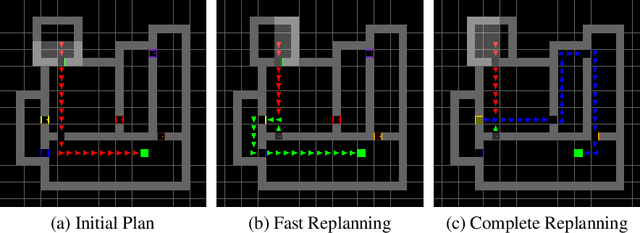
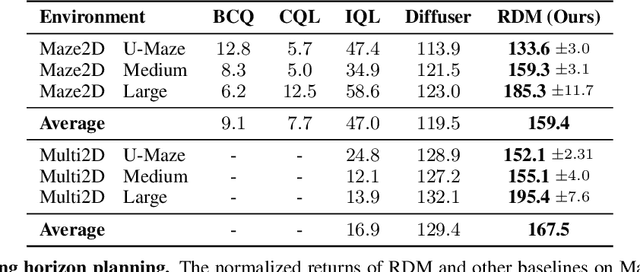
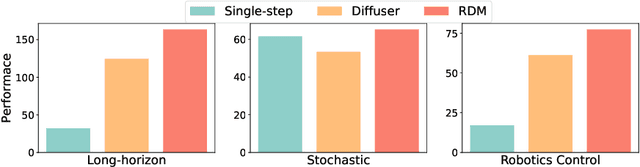
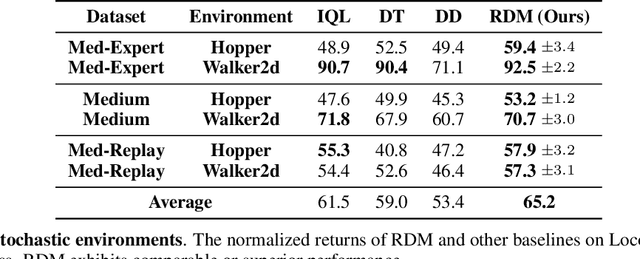
Diffusion models have risen as a promising approach to data-driven planning, and have demonstrated impressive robotic control, reinforcement learning, and video planning performance. Given an effective planner, an important question to consider is replanning -- when given plans should be regenerated due to both action execution error and external environment changes. Direct plan execution, without replanning, is problematic as errors from individual actions rapidly accumulate and environments are partially observable and stochastic. Simultaneously, replanning at each timestep incurs a substantial computational cost, and may prevent successful task execution, as different generated plans prevent consistent progress to any particular goal. In this paper, we explore how we may effectively replan with diffusion models. We propose a principled approach to determine when to replan, based on the diffusion model's estimated likelihood of existing generated plans. We further present an approach to replan existing trajectories to ensure that new plans follow the same goal state as the original trajectory, which may efficiently bootstrap off previously generated plans. We illustrate how a combination of our proposed additions significantly improves the performance of diffusion planners leading to 38\% gains over past diffusion planning approaches on Maze2D, and further enables the handling of stochastic and long-horizon robotic control tasks. Videos can be found on the anonymous website: \url{https://vis-www.cs.umass.edu/replandiffuser/}.
Beam Squint Assisted User Localization in Near-Field Integrated Sensing and Communications Systems
Sep 25, 2023Integrated sensing and communication (ISAC) has been regarded as a key technology for 6G wireless communications, in which large-scale multiple input and multiple output (MIMO) array with higher and wider frequency bands will be adopted. However, recent studies show that the beam squint phenomenon can not be ignored in wideband MIMO system, which generally deteriorates the communications performance. In this paper, we find that with the aid of true-time-delay lines (TTDs), the range and trajectory of the beam squint in near-field communications systems can be freely controlled, and hence it is possible to reversely utilize the beam squint for user localization. We derive the trajectory equation for near-field beam squint points and design a way to control such trajectory. With the proposed design, beamforming from different subcarriers would purposely point to different angles and different distances, such that users from different positions would receive the maximum power at different subcarriers. Hence, one can simply localize multiple users from the beam squint effect in frequency domain, and thus reduce the beam sweeping overhead as compared to the conventional time domain beam search based approach. Furthermore, we utilize the phase difference of the maximum power subcarriers received by the user at different frequencies in several times beam sweeping to obtain a more accurate distance estimation result, ultimately realizing high accuracy and low beam sweeping overhead user localization. Simulation results demonstrate the effectiveness of the proposed schemes.
M$^3$CS: Multi-Target Masked Point Modeling with Learnable Codebook and Siamese Decoders
Sep 23, 2023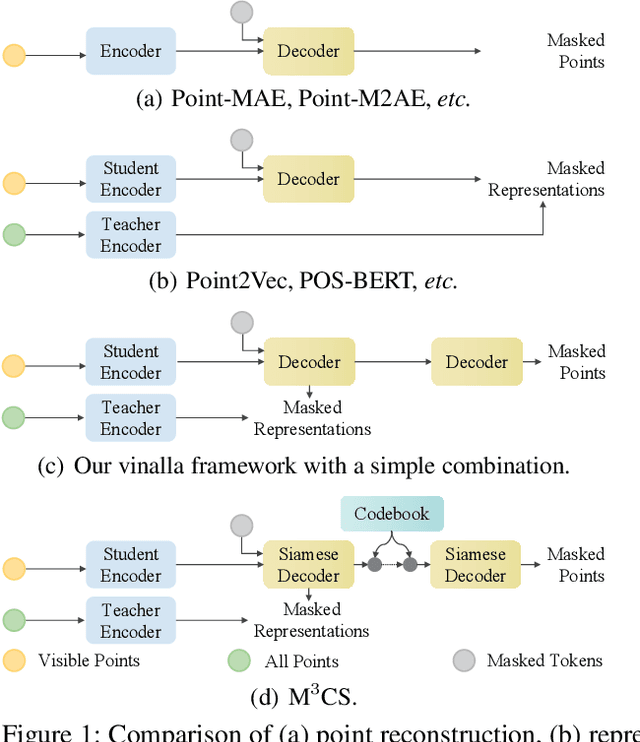

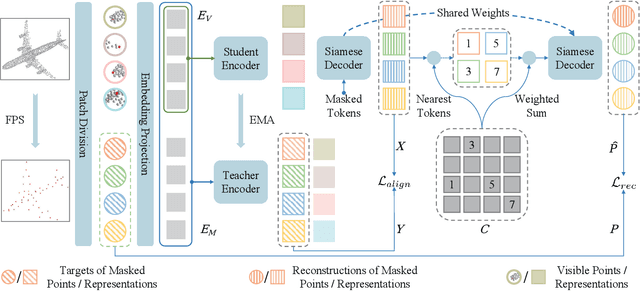
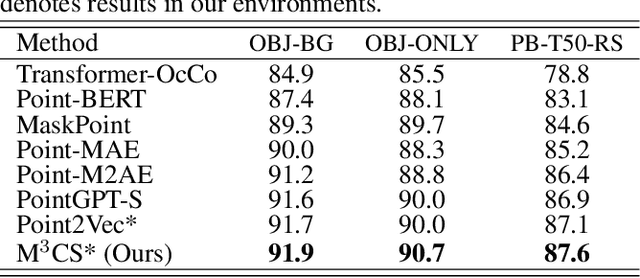
Masked point modeling has become a promising scheme of self-supervised pre-training for point clouds. Existing methods reconstruct either the original points or related features as the objective of pre-training. However, considering the diversity of downstream tasks, it is necessary for the model to have both low- and high-level representation modeling capabilities to capture geometric details and semantic contexts during pre-training. To this end, M$^3$CS is proposed to enable the model with the above abilities. Specifically, with masked point cloud as input, M$^3$CS introduces two decoders to predict masked representations and the original points simultaneously. While an extra decoder doubles parameters for the decoding process and may lead to overfitting, we propose siamese decoders to keep the amount of learnable parameters unchanged. Further, we propose an online codebook projecting continuous tokens into discrete ones before reconstructing masked points. In such way, we can enforce the decoder to take effect through the combinations of tokens rather than remembering each token. Comprehensive experiments show that M$^3$CS achieves superior performance at both classification and segmentation tasks, outperforming existing methods.
Two-Bit RIS-Aided Communications at 3.5GHz: Some Insights from the Measurement Results Under Multiple Practical Scenes
May 19, 2023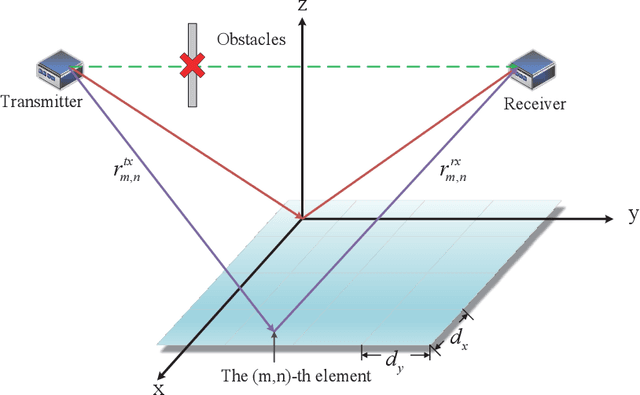
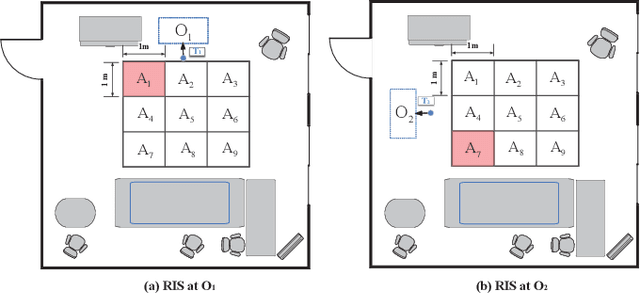
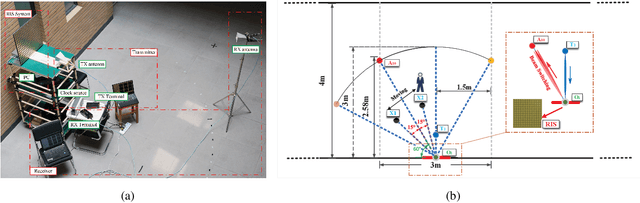

In this paper, we propose a two-bit reconfigurable intelligent surface (RIS)-aided communication system, which mainly consists of a two-bit RIS, a transmitter and a receiver. A corresponding prototype verification system is designed to perform experimental tests in practical environments. The carrier frequency is set as 3.5GHz, and the RIS array possesses 256 units, each of which adopts two-bit phase quantization. In particular, we adopt a self-developed broadband intelligent communication system 40MHz-Net (BICT-40N) terminal in order to fully acquire the channel information. The terminal mainly includes a baseband board and a radio frequency (RF) front-end board, where the latter can achieve 26 dB transmitting link gain and 33 dB receiving link gain. The orthogonal frequency division multiplexing (OFDM) signal is used for the terminal, where the bandwidth is 40MHz and the subcarrier spacing is 625KHz. Also, the terminal supports a series of modulation modes, including QPSK, QAM, etc.Through experimental tests, we validate a few functions and properties of the RIS as follows. First, we validate a novel RIS power consumption model, which considers both the static and the dynamic power consumption. Besides, we demonstrate the existence of the imaging interference and find that two-bit RIS can lower the imaging interference about 10 dBm. Moreover, we verify that the RIS can outperform the metal plate in terms of the beam focusing performance. In addition, we find that the RIS has the ability to improve the channel stationarity. Then, we realize the multi-beam reflection of the RIS utilizing the pattern addition (PA) algorithm. Lastly, we validate the existence of the mutual coupling between different RIS units.